생성형 AI를 활용한 RAG(Retrieval-Augmented Generation) 시스템을 구축할 때, 가장 중요한 요소 중 하나는 데이터를 어떻게 벡터 데이터베이스에 효과적으로 저장하고 검색하느냐입니다. 특히 FAQ, 팁, 짧은 가이드라인과 같이 이미 간결하게 정리된 텍스트 데이터를 다룰 때는 기존의 문서 청킹(chunking) 전략이 오히려 검색 성능을 저해할 수 있습니다.
많은 고객들이 Amazon Bedrock Knowledge Bases를 활용하여 대량의 짧은 텍스트를 벡터 데이터베이스에 적재할 때 다음과 같은 문제에 직면합니다.
- 기존 청킹 전략의 한계: 이미 짧은 텍스트를 더 작은 조각으로 나누면서 맥락이 손실됨
- 검색 정확도 저하: 관련 정보가 여러 청크로 분산되어 완전한 답변을 얻기 어려움
- 토큰 효율성 문제: 중복되는 내용이 포함된 여러 청크를 처리하면서 불필요한 토큰 소비 발생
- 디버깅의 어려움: 적재된 데이터가 어떻게 저장되고 검색되는지 확인하기 어려움
이러한 문제들로 인해 고객들은 RAG 시스템의 성능 최적화에 어려움을 겪고 있으며, 특히 정확한 참조(reference) 제공이 중요한 애플리케이션에서는 이러한 문제가 더욱 중요해집니다.
이 블로그에서 다룰 내용
이 블로그에서는 CSV 파일과 No Chunking 전략을 활용하여 Amazon Bedrock Knowledge Bases에서 짧은 텍스트(FAQ, 팁, 가이드라인 등)를 효과적으로 처리하는 방법을 소개합니다.
핵심 접근 방식
구조화된 데이터 특성 활용한 청킹 전략
- FAQ, Tip과 같이 이미 특정 단위로 분절된 텍스트들을 CSV로 재구조화
- CSV 파일에서 특정 컬럼을
contentFields로 지정하고, No Chunking 전략을 적용하여 각 행의 텍스트를 온전한 하나의 청크로 유지
- CSV 내 다른 컬럼들을 통해 카테고리, 태그, 우선순위 등 각 텍스트 단위별 메타데이터 추가하여 검색 시 풍부한 맥락 정보 제공
OpenSearch Dashboard를 통한 데이터 검증
- 실제 인덱싱된 데이터의 구조 확인
- 텍스트 분절 및 메타데이터 연결 상태 디버깅
- 검색 결과의 정확성 검증 및 최적화
실습 내용
- CSV 데이터 구조화 및 No Chunking 전략 적용
- Amazon OpenSearch Dashboard를 통한 기존 방식 vs 새로운 방식 검증
- 실무 적용을 위한 최적화 팁
사전 준비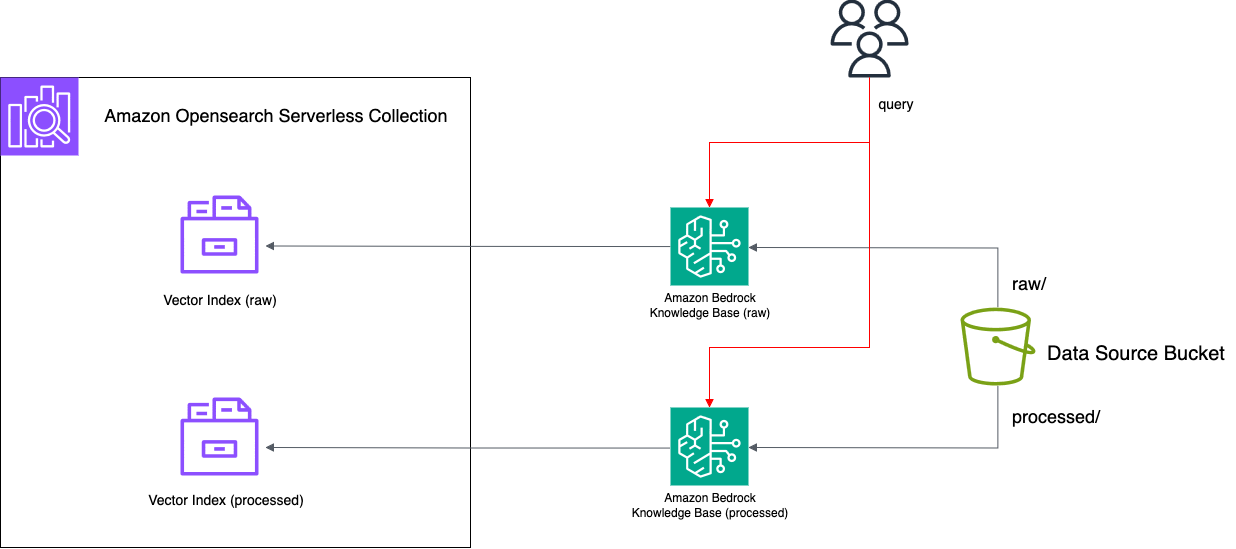
두 청킹 전략의 비교를 위하여 지식 기반을 두개 생성하여 비교합니다. 예를 들어 아래와 같은 최종 구성 형태를 참조하여 준비하실 수 있습니다.
Step 1. S3 버킷 : 원본 데이터와 처리된 데이터를 저장하는 데이터 소스
버킷 이름: faq-data-source-{계정ID}
폴더 구조:
faq-data-source-123456789012/
├── raw/
│ └── (원본 문서 파일들)
└── processed/
└── (전처리된 문서 파일들)
Step 2. IAM 역할: Bedrock Knowledge Base에서 사용할 Service Role
역할 이름: faq-bedrock-kb-role
신뢰 관계 (Trust Relationship)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
필요한 권한 정책들
관리형 정책:
인라인 정책 예 (S3 및 OpenSearch 접근):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::faq-data-source-{Account ID}",
"arn:aws:s3:::faq-data-source-{Account ID}/*"
]
},
{
"Effect": "Allow",
"Action": [
"aoss:APIAccessAll"
],
"Resource": "arn:aws:aoss:{Region}:{Account ID}:collection/*"
}
]
}
Step 3. OpenSearch Serverless Collection: 벡터 검색을 위한 서버리스 검색 엔진
- 컬렉션 이름:
faq-collection
- 타입: Vector search
- 보안 정책:
- 암호화 정책: faq-enc-policy (AWS owned key)
- 네트워크 정책: faq-net-policy (Public access, Opensearch endpoint/dasboard 활성화)
- 데이터 액세스 정책: faq-da-policy (Bedrock 역할 + 콘솔 사용자 권한)
생성된 인덱스:
- faq-index-raw, faq-index-processed
- Vector fields
- Name:
bedrock-knowledge-base-default-vector
- Engine: faiss
- Precision: FP16
- Dimension: 1024
- Distance type: euclidiean
- Metadata
AMAZON_BEDROCK_METADATA
- Data Type: text
- Filterable: True
AMAZON_BEDROCK_TEXT_CHUNK
- Data Type: text
- Filterable: True
ex. faq-index-raw (faq-index-processed도 동일하게 설정)

Step 4. Bedrock Knowledge Base: 각각 다른 청킹 전략을 적용한 지식기반
Knowledge Base A (Raw 파일용)
- 이름: faq-kb-raw
- 벡터 스토어: OpenSearch Serverless (faq-collection)
- 인덱스: faq-index-raw
- Vector field name:
bedrock-knowledge-base-default-vector
- Text field name:
AMAZON_BEDROCK_TEXT_CHUNK
- Metadata field name:
AMAZON_BEDROCK_METADATA
- 임베딩 모델: Titan Text Embeddings v2 (1024차원)
- 데이터 소스
- 이름: faq-datasource-raw
- 경로:
s3://faq-data-source-{계정ID}/raw/
- 청킹: 기본 설정
Knowledge Base B (Processed 파일용)
- 이름: faq-kb-processed
- 벡터 스토어: OpenSearch Serverless (faq-collection)
- 인덱스: faq-index-processed
- Vector field name:
bedrock-knowledge-base-default-vector
- Text field name:
AMAZON_BEDROCK_TEXT_CHUNK
- Metadata field name:
AMAZON_BEDROCK_METADATA
- 임베딩 모델: Titan Text Embeddings v2 (1024차원)
- 데이터 소스
- 이름: faq-datasource-processed
- 경로: s3://faq-data-source-{계정ID}/processed/
- 청킹: No chunking
1. 청킹 전략에 따른 성능 비교
Knowledge Bases 데이터 소스 동기화
앞서 준비한 두 가지 Knowledge Bases 중 faq-kb-processed는 metadata.json 파일과 함께 가공된 csv 파일을 동기화 하기 위한 Knowledge Bases이며, faq-kb-raw는 원본 csv 파일을 동기화 하기 위한 Knowledge Bases입니다.
1. 각각의 Knowledge Bases에 대한 정확도 비교를 위해 관련된 데이터를 가지고 동기화하는 작업을 진행하도록 하겠습니다. 먼저 faq-kb-raw 리소스의 동기화 작업을 진행하기 위해 해당 리소스 이름을 클릭하여 이동합니다.
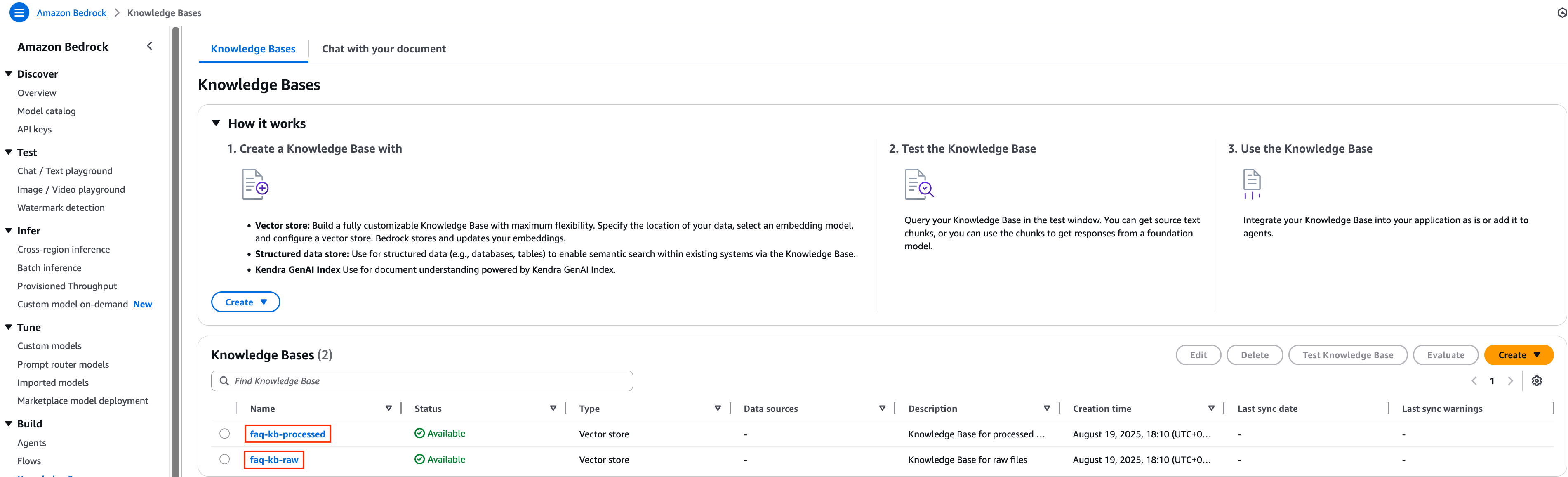
2. 각각의 Knowledge Bases에 대해 데이터 동기화를 하기 위하여 먼저 faq-kb-raw Knowledge Bases의 데이터 소스 S3 경로를 확인합니다.
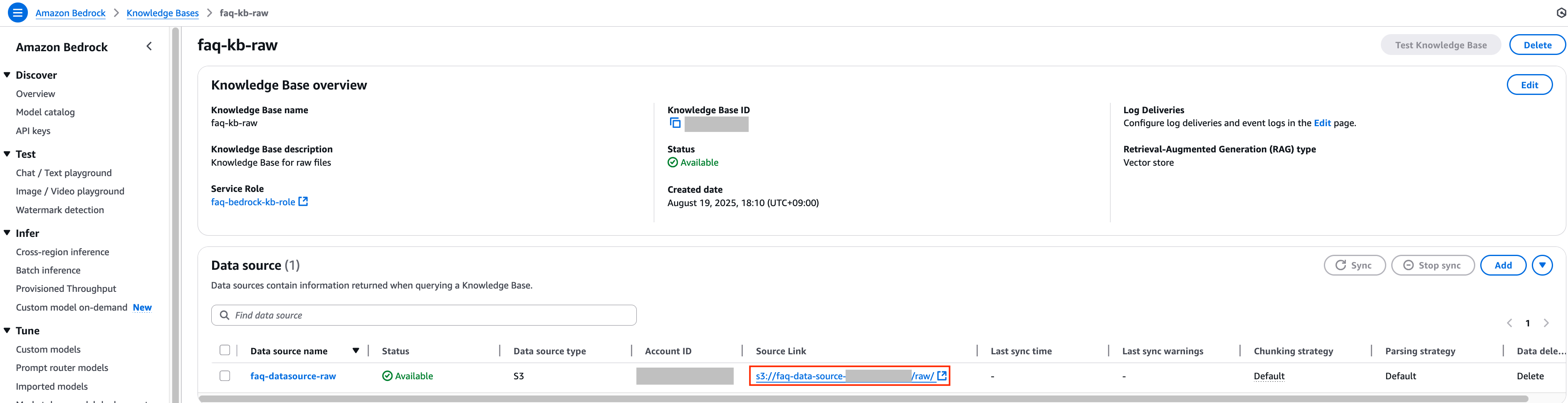
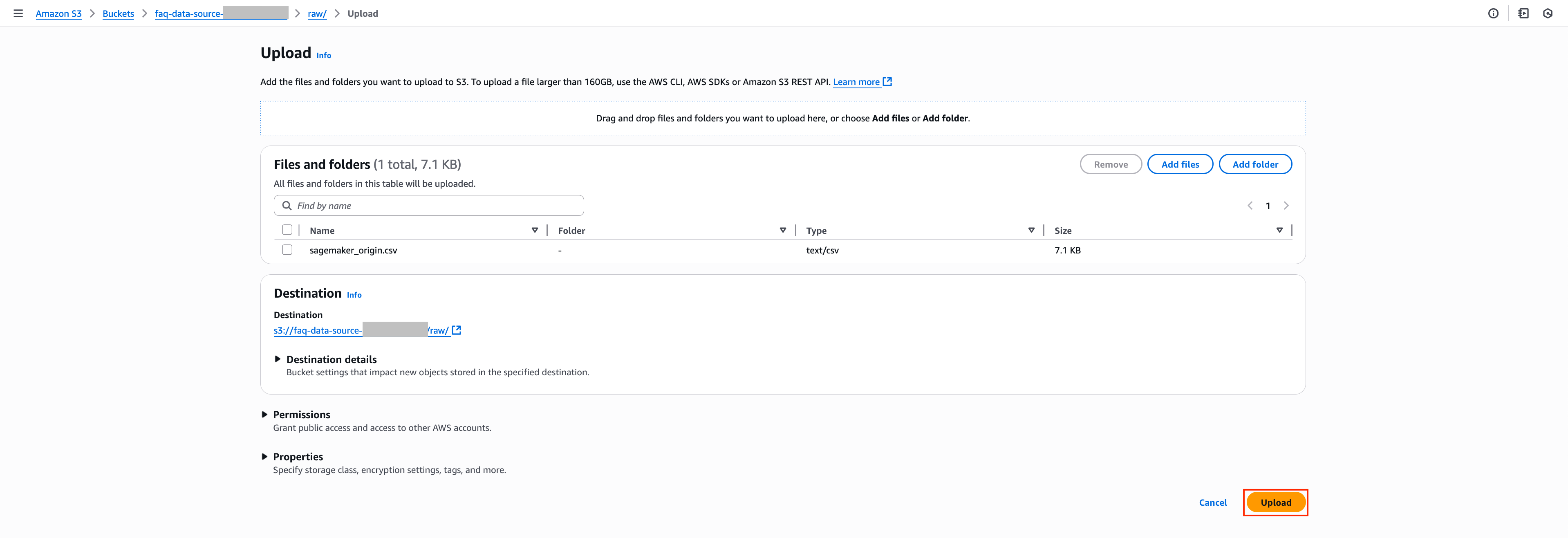
3. 데이터 소스의 Source Link를 클릭하여 데이터 소스로 지정된 S3 경로로 이동합니다. 이후 해당 경로에 원본인 sagemaker_origin.csv 파일을 첨부하여 Upload 버튼을 눌러 추가합니다. sagemaker_origin.csv와 관련된 문서는 해당 링크를 통해 확인하실 수 있습니다.
sagemaker_origin.csv
no,service,question,answer
"1","sagemaker","SageMaker 사용 요금은 어떻게 부과되나요?","노트북을 호스팅하고 모델을 훈련하고 예측을 수행하며 출력을 로깅하는 데 사용하는 ML 컴퓨팅, 스토리지 및 데이터 처리 리소스에 대한 요금이 부과됩니다. SageMaker를 사용할 때는 호스팅된 노트북, 훈련 및 모델 호스팅에 사용되는 인스턴스 수 및 유형을 선택할 수 있습니다. 서비스를 사용하면서 사용한 만큼만 비용을 지불하며 최소 요금 및 사전 약정은 없습니다. 자세한 내용은 Amazon SageMaker 요금 및 Amazon SageMaker 요금 계산기를 참조하세요."
"2","sagemaker","유휴 리소스를 검색하고 중지하여 불필요한 요금을 방지하는 것과 같이 SageMaker 비용을 최적화하려면 어떻게 해야 하나요?","SageMaker 리소스 사용량을 최적화하는 데 사용할 수 있는 여러 모범 사례가 있습니다. 구성 최적화를 수행하는 것과 관련된 접근 방식이 있고 프로그래밍 방식 솔루션을 제공하는 접근 방식도 있습니다. 이 블로그 게시물에서 시각적 자습서 및 코드 샘플과 함께 이 개념에 대한 전체 가이드를 확인할 수 있습니다."
"3","sagemaker","자체 노트북, 훈련 또는 호스팅 환경이 있는 경우는 어떻게 되나요?","SageMaker는 완전한 전체 워크플로를 제공하지만, SageMaker에서 기존 도구를 계속 사용할 수 있습니다. 비즈니스 요구 사항에 따라 필요한 대로 SageMaker에서 각 단계의 결과를 손쉽게 송수신할 수 있습니다."
"4","sagemaker","추론 최적화 도구 키트가 무엇인가요?","추론 최적화 도구 키트를 사용하면 최신 추론 최적화 기법을 쉽게 구현하여 Amazon SageMaker에서 최첨단(SOTA) 비용 대비 성능을 달성하는 동시에 몇 개월의 개발자 시간을 절약할 수 있습니다. SageMaker가 제공하는 인기 최적화 기법 메뉴에서 선택하여 최적화 작업을 미리 실행하고, 성능 및 정확도 지표에 대한 모델을 벤치마킹한 다음 추론을 위해 최적화된 모델을 SageMaker 엔드포인트에 배포할 수 있습니다. 도구 키트가 모델 최적화의 모든 측면을 처리하므로 비즈니스 목표에 더 집중할 수 있습니다."
"5","sagemaker","SageMaker에서 공유 공간이란 무엇인가요?","ML 실무자는 팀원이 SageMaker Studio 노트북을 함께 읽고 편집할 수 있는 작업 공간을 만들 수 있습니다. 팀원들은 공유 공간을 사용하여 동일한 노트북 파일을 공동 편집하고, 노트북 코드를 동시에 실행하며, 결과를 함께 검토하여 반복 작업을 줄이고 협업을 간소화할 수 있습니다. 공유 공간에서는 BitBucket 및 AWS CodeCommit과 같은 서비스가 기본적으로 지원되기 때문에 여러 버전의 노트북을 손쉽게 관리하고 변경 사항을 지속적으로 비교할 수 있습니다. 실험 및 ML 모델과 같이 노트북 내에서 생성되는 모든 리소스가 자동으로 저장되고, 생성된 특정 작업 공간에 연결되므로 팀 작업을 보다 체계적으로 유지하고 ML 모델 개발을 가속화할 수 있습니다."
"6","sagemaker","SageMaker Studio 노트북 요금은 어떻게 적용되나요?","Studio IDE에서 SageMaker 노트북을 사용할 때는 컴퓨팅과 스토리지 비용을 모두 지불해야 합니다. 컴퓨팅 인스턴스 유형별 요금은 Amazon SageMaker 요금을 참조하세요. 노트북과 데이터 파일 및 스크립트와 같은 관련 아티팩트는 Amazon Elastic File System(Amazon EFS)에 보존됩니다. 스토리지 요금은 Amazon EFS 요금을 참조하세요. AWS 프리 티어의 일부로 SageMaker Studio에서 노트북을 무료로 시작할 수 있습니다."
"7","sagemaker","SageMaker Studio 노트북 또는 기타 SageMaker 서비스에 대한 항목별 요금은 어떻게 확인하나요?","관리자는 AWS 빌링 콘솔에서 SageMaker Studio를 포함하여 SageMaker에 대한 항목별 요금 목록을 확인할 수 있습니다. SageMaker용 AWS Management Console의 상단 메뉴에서 ‘서비스’를 선택하고, 검색 상자에 ‘billing(결제)’을 입력하고, 드롭다운 메뉴에서 결제를 선택한 다음 왼쪽 패널에서 ‘청구서’를 선택합니다. Details(세부 정보) 섹션에서 SageMaker를 선택하여 리전 목록을 확장하고 항목별 요금으로 드릴다운할 수 있습니다."
"8","sagemaker","Amazon SageMaker Studio Lab이란 무엇인가요?","SageMaker Studio Lab은 누구나 ML을 배우고 실험할 수 있도록 컴퓨팅, 스토리지(최대 15GB) 및 보안을 모두 무료로 제공하는 무료 기계 학습 개발 환경입니다. 시작하려면 유효한 이메일 ID만 있으면 됩니다. 인프라를 구성하거나 ID 및 액세스를 관리하거나 AWS 계정에 가입할 필요가 없습니다. SageMaker Studio Lab은 GitHub 통합을 통해 모델 구축을 가속화하고 가장 인기 있는 ML 도구, 프레임워크 및 라이브러리로 사전 구성되어 제공되므로 즉시 시작할 수 있습니다. SageMaker Studio Lab은 작업을 자동으로 저장하므로 세션 사이에 다시 시작할 필요가 없습니다. 노트북을 닫았다가 나중에 다시 열고 작업하는 것처럼 쉽습니다."
"9","sagemaker","Amazon SageMaker 절감형 플랜이란 무엇인가요?","SageMaker 절감형 플랜은 1년 또는 3년의 일정 사용량 약정(시간당 USD 요금으로 측정)을 조건으로 SageMaker에서 유연한 사용량 기반 요금 모델을 제공합니다. SageMaker 절감형 플랜은 최대 64%까지 비용을 절감할 수 있는 가장 유연한 요금 모델입니다. 이 요금은 인스턴스 패밀리, 크기 또는 리전과 관계없이 SageMaker Studio 노트북, SageMaker 온디맨드 노트북, SageMaker 처리, SageMaker Data Wrangler, SageMaker 훈련, SageMaker 실시간 추론 및 SageMaker 배치 변환을 포함하여 적격 SageMaker ML 인스턴스 사용량에 자동으로 적용됩니다. 예를 들어 추론 워크로드를 위해 미국 동부(오하이오)에서 실행되는 CPU 인스턴스 ml.c5.xlarge에서 미국 서부(오레곤)의 ml.Inf1 인스턴스로 언제든지 변경할 수 있으며, 절감형 플랜 요금이 자동으로 계속 적용됩니다."
"10","sagemaker","SageMaker 절감형 플랜을 사용해야 하는 이유는 무엇인가요?","SageMaker 인스턴스 사용량이 일정한 크기이고(시간당 USD 요금으로 측정됨), 여러 SageMaker 구성 요소를 사용하거나 시간이 지남에 따라 기술 구성(예: 인스턴스 패밀리, 리전)이 변경될 것으로 예상되는 경우 SageMaker 절감형 플랜을 사용하면 절감 효과를 극대화하면서 애플리케이션 요구 사항 또는 새로운 혁신에 따라 기본적인 기술 구성을 유연하게 변경할 수 있습니다. 절감형 플랜 요금은 수동으로 수정하지 않고도 모든 적격 기계 학습 인스턴스 사용량에 자동으로 적용됩니다."
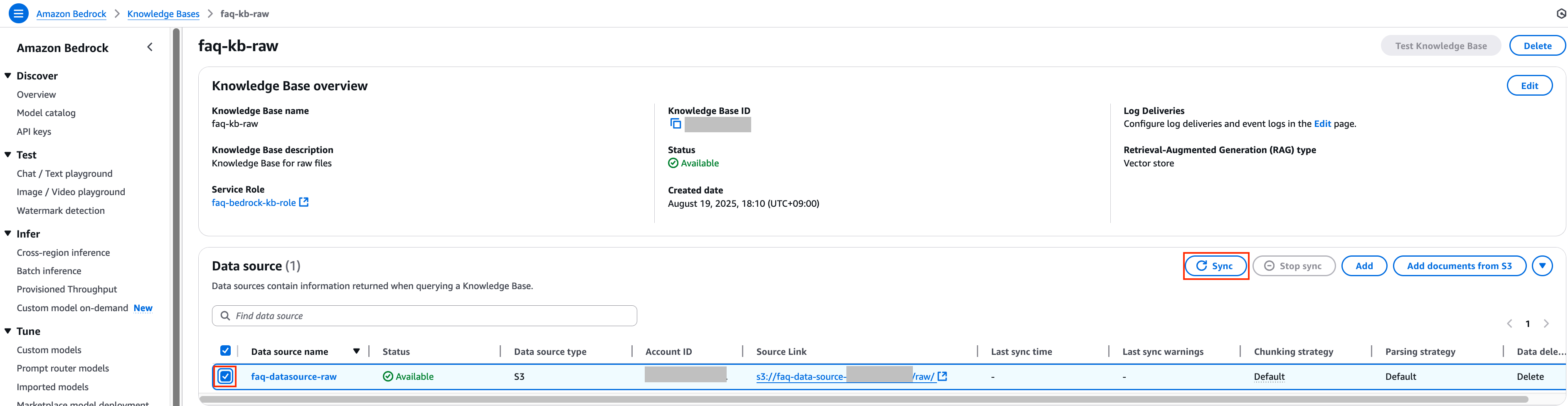
4. 다시 이전 Knowledge Bases 콘솔로 돌아간 뒤 sagemaker_origin.csv 파일을 추가한 데이터 소스의 체크 박스를 선택한 후 Sync 버튼을 클릭하여 데이터 동기화 작업을 진행합니다.
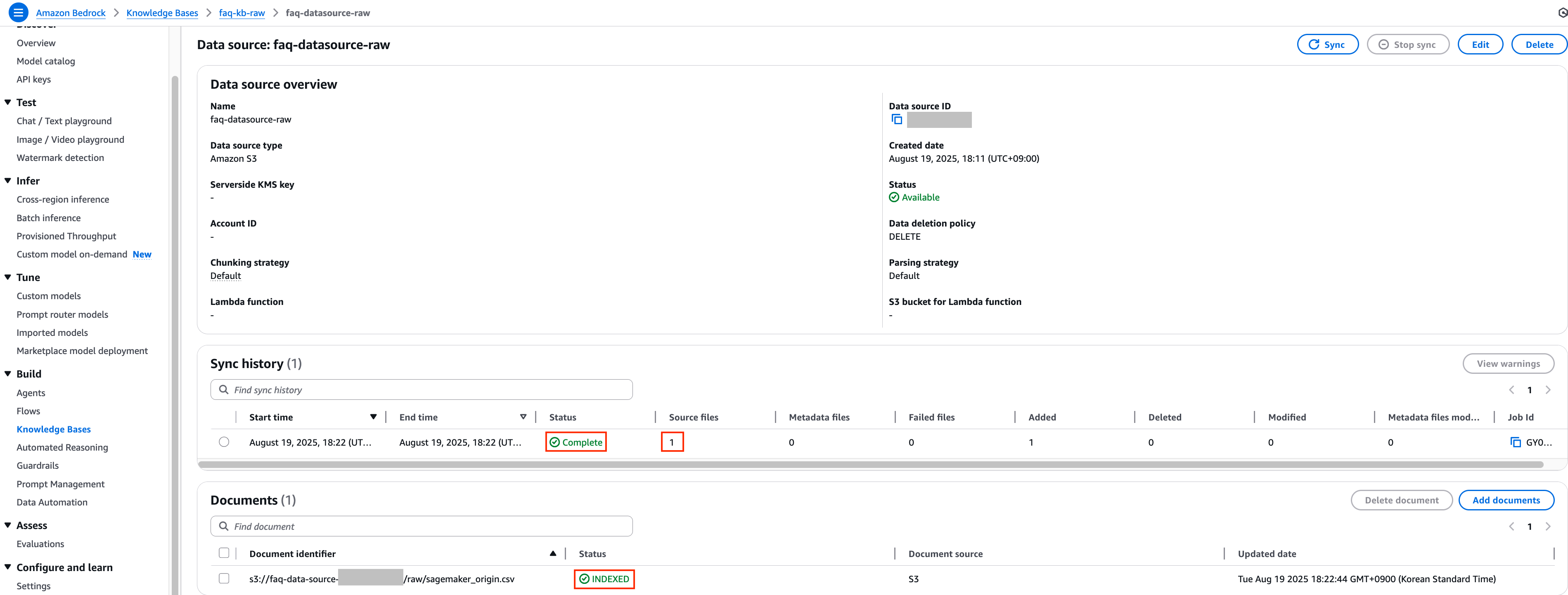
5. 일정 시간이 지난 후 해당 데이터 소스의 데이터 동기화 작업이 정상적으로 수행이 되었는지 확인합니다.
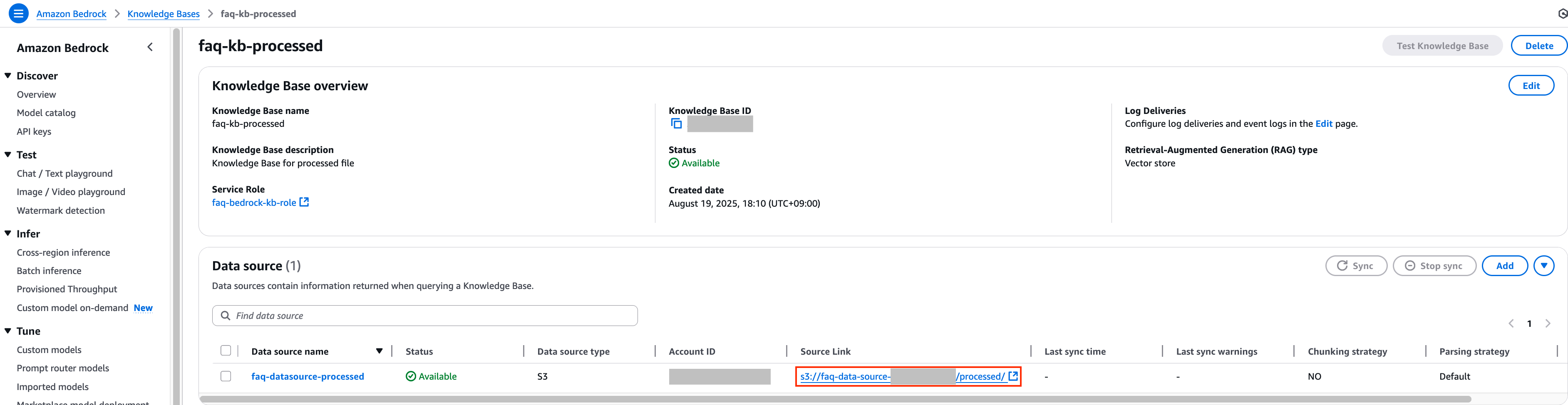
6. 정상적으로 동기화가 완료 되었다면 이제 faq-kb-processed Knowledge Bases의 데이터 소스 S3 경로를 확인하여 지정된 S3 경로로 이동합니다.
7. 이번에는 해당 경로에 원본 파일이 아닌 가공된 processed_sagemaker.csv파일들과 metadata.json파일을 첨부하여 Upload 버튼을 눌러 추가합니다.
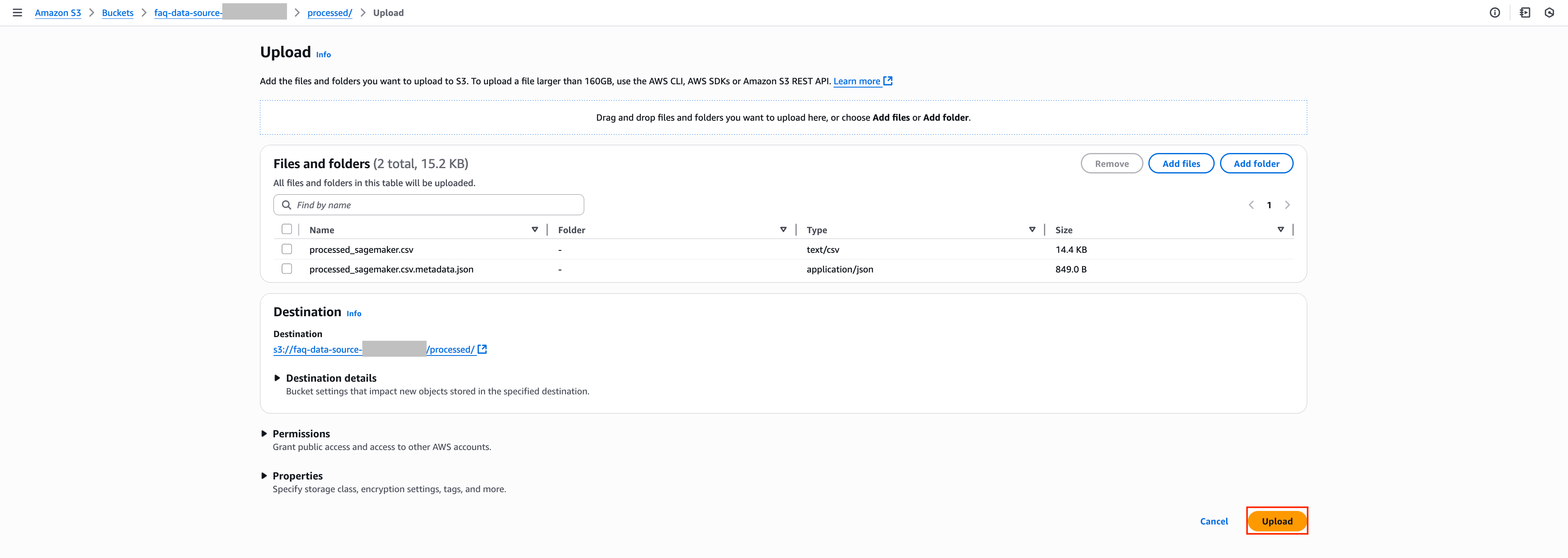
processed_sagemaker.csv
no,service,question,answer,content
"1","sagemaker","SageMaker 사용 요금은 어떻게 부과되나요?","노트북을 호스팅하고 모델을 훈련하고 예측을 수행하며 출력을 로깅하는 데 사용하는 ML 컴퓨팅, 스토리지 및 데이터 처리 리소스에 대한 요금이 부과됩니다. SageMaker를 사용할 때는 호스팅된 노트북, 훈련 및 모델 호스팅에 사용되는 인스턴스 수 및 유형을 선택할 수 있습니다. 서비스를 사용하면서 사용한 만큼만 비용을 지불하며 최소 요금 및 사전 약정은 없습니다. 자세한 내용은 Amazon SageMaker 요금 및 Amazon SageMaker 요금 계산기를 참조하세요.","no: 1, service: sagemaker, question: SageMaker 사용 요금은 어떻게 부과되나요?, answer: 노트북을 호스팅하고 모델을 훈련하고 예측을 수행하며 출력을 로깅하는 데 사용하는 ML 컴퓨팅, 스토리지 및 데이터 처리 리소스에 대한 요금이 부과됩니다. SageMaker를 사용할 때는 호스팅된 노트북, 훈련 및 모델 호스팅에 사용되는 인스턴스 수 및 유형을 선택할 수 있습니다. 서비스를 사용하면서 사용한 만큼만 비용을 지불하며 최소 요금 및 사전 약정은 없습니다. 자세한 내용은 Amazon SageMaker 요금 및 Amazon SageMaker 요금 계산기를 참조하세요."
"2","sagemaker","유휴 리소스를 검색하고 중지하여 불필요한 요금을 방지하는 것과 같이 SageMaker 비용을 최적화하려면 어떻게 해야 하나요?","SageMaker 리소스 사용량을 최적화하는 데 사용할 수 있는 여러 모범 사례가 있습니다. 구성 최적화를 수행하는 것과 관련된 접근 방식이 있고 프로그래밍 방식 솔루션을 제공하는 접근 방식도 있습니다. 이 블로그 게시물에서 시각적 자습서 및 코드 샘플과 함께 이 개념에 대한 전체 가이드를 확인할 수 있습니다.","no: 2, service: sagemaker, question: 유휴 리소스를 검색하고 중지하여 불필요한 요금을 방지하는 것과 같이 SageMaker 비용을 최적화하려면 어떻게 해야 하나요?, answer: SageMaker 리소스 사용량을 최적화하는 데 사용할 수 있는 여러 모범 사례가 있습니다. 구성 최적화를 수행하는 것과 관련된 접근 방식이 있고 프로그래밍 방식 솔루션을 제공하는 접근 방식도 있습니다. 이 블로그 게시물에서 시각적 자습서 및 코드 샘플과 함께 이 개념에 대한 전체 가이드를 확인할 수 있습니다."
"3","sagemaker","자체 노트북, 훈련 또는 호스팅 환경이 있는 경우는 어떻게 되나요?","SageMaker는 완전한 전체 워크플로를 제공하지만, SageMaker에서 기존 도구를 계속 사용할 수 있습니다. 비즈니스 요구 사항에 따라 필요한 대로 SageMaker에서 각 단계의 결과를 손쉽게 송수신할 수 있습니다.","no: 3, service: sagemaker, question: 자체 노트북, 훈련 또는 호스팅 환경이 있는 경우는 어떻게 되나요?, answer: SageMaker는 완전한 전체 워크플로를 제공하지만, SageMaker에서 기존 도구를 계속 사용할 수 있습니다. 비즈니스 요구 사항에 따라 필요한 대로 SageMaker에서 각 단계의 결과를 손쉽게 송수신할 수 있습니다."
"4","sagemaker","추론 최적화 도구 키트가 무엇인가요?","추론 최적화 도구 키트를 사용하면 최신 추론 최적화 기법을 쉽게 구현하여 Amazon SageMaker에서 최첨단(SOTA) 비용 대비 성능을 달성하는 동시에 몇 개월의 개발자 시간을 절약할 수 있습니다. SageMaker가 제공하는 인기 최적화 기법 메뉴에서 선택하여 최적화 작업을 미리 실행하고, 성능 및 정확도 지표에 대한 모델을 벤치마킹한 다음 추론을 위해 최적화된 모델을 SageMaker 엔드포인트에 배포할 수 있습니다. 도구 키트가 모델 최적화의 모든 측면을 처리하므로 비즈니스 목표에 더 집중할 수 있습니다.","no: 4, service: sagemaker, question: 추론 최적화 도구 키트가 무엇인가요?, answer: 추론 최적화 도구 키트를 사용하면 최신 추론 최적화 기법을 쉽게 구현하여 Amazon SageMaker에서 최첨단(SOTA) 비용 대비 성능을 달성하는 동시에 몇 개월의 개발자 시간을 절약할 수 있습니다. SageMaker가 제공하는 인기 최적화 기법 메뉴에서 선택하여 최적화 작업을 미리 실행하고, 성능 및 정확도 지표에 대한 모델을 벤치마킹한 다음 추론을 위해 최적화된 모델을 SageMaker 엔드포인트에 배포할 수 있습니다. 도구 키트가 모델 최적화의 모든 측면을 처리하므로 비즈니스 목표에 더 집중할 수 있습니다."
"5","sagemaker","SageMaker에서 공유 공간이란 무엇인가요?","ML 실무자는 팀원이 SageMaker Studio 노트북을 함께 읽고 편집할 수 있는 작업 공간을 만들 수 있습니다. 팀원들은 공유 공간을 사용하여 동일한 노트북 파일을 공동 편집하고, 노트북 코드를 동시에 실행하며, 결과를 함께 검토하여 반복 작업을 줄이고 협업을 간소화할 수 있습니다. 공유 공간에서는 BitBucket 및 AWS CodeCommit과 같은 서비스가 기본적으로 지원되기 때문에 여러 버전의 노트북을 손쉽게 관리하고 변경 사항을 지속적으로 비교할 수 있습니다. 실험 및 ML 모델과 같이 노트북 내에서 생성되는 모든 리소스가 자동으로 저장되고, 생성된 특정 작업 공간에 연결되므로 팀 작업을 보다 체계적으로 유지하고 ML 모델 개발을 가속화할 수 있습니다.","no: 5, service: sagemaker, question: SageMaker에서 공유 공간이란 무엇인가요?, answer: ML 실무자는 팀원이 SageMaker Studio 노트북을 함께 읽고 편집할 수 있는 작업 공간을 만들 수 있습니다. 팀원들은 공유 공간을 사용하여 동일한 노트북 파일을 공동 편집하고, 노트북 코드를 동시에 실행하며, 결과를 함께 검토하여 반복 작업을 줄이고 협업을 간소화할 수 있습니다. 공유 공간에서는 BitBucket 및 AWS CodeCommit과 같은 서비스가 기본적으로 지원되기 때문에 여러 버전의 노트북을 손쉽게 관리하고 변경 사항을 지속적으로 비교할 수 있습니다. 실험 및 ML 모델과 같이 노트북 내에서 생성되는 모든 리소스가 자동으로 저장되고, 생성된 특정 작업 공간에 연결되므로 팀 작업을 보다 체계적으로 유지하고 ML 모델 개발을 가속화할 수 있습니다."
"6","sagemaker","SageMaker Studio 노트북 요금은 어떻게 적용되나요?","Studio IDE에서 SageMaker 노트북을 사용할 때는 컴퓨팅과 스토리지 비용을 모두 지불해야 합니다. 컴퓨팅 인스턴스 유형별 요금은 Amazon SageMaker 요금을 참조하세요. 노트북과 데이터 파일 및 스크립트와 같은 관련 아티팩트는 Amazon Elastic File System(Amazon EFS)에 보존됩니다. 스토리지 요금은 Amazon EFS 요금을 참조하세요. AWS 프리 티어의 일부로 SageMaker Studio에서 노트북을 무료로 시작할 수 있습니다.","no: 6, service: sagemaker, question: SageMaker Studio 노트북 요금은 어떻게 적용되나요?, answer: Studio IDE에서 SageMaker 노트북을 사용할 때는 컴퓨팅과 스토리지 비용을 모두 지불해야 합니다. 컴퓨팅 인스턴스 유형별 요금은 Amazon SageMaker 요금을 참조하세요. 노트북과 데이터 파일 및 스크립트와 같은 관련 아티팩트는 Amazon Elastic File System(Amazon EFS)에 보존됩니다. 스토리지 요금은 Amazon EFS 요금을 참조하세요. AWS 프리 티어의 일부로 SageMaker Studio에서 노트북을 무료로 시작할 수 있습니다."
"7","sagemaker","SageMaker Studio 노트북 또는 기타 SageMaker 서비스에 대한 항목별 요금은 어떻게 확인하나요?","관리자는 AWS 빌링 콘솔에서 SageMaker Studio를 포함하여 SageMaker에 대한 항목별 요금 목록을 확인할 수 있습니다. SageMaker용 AWS Management Console의 상단 메뉴에서 ‘서비스’를 선택하고, 검색 상자에 ‘billing(결제)’을 입력하고, 드롭다운 메뉴에서 결제를 선택한 다음 왼쪽 패널에서 ‘청구서’를 선택합니다. Details(세부 정보) 섹션에서 SageMaker를 선택하여 리전 목록을 확장하고 항목별 요금으로 드릴다운할 수 있습니다.","no: 7, service: sagemaker, question: SageMaker Studio 노트북 또는 기타 SageMaker 서비스에 대한 항목별 요금은 어떻게 확인하나요?, answer: 관리자는 AWS 빌링 콘솔에서 SageMaker Studio를 포함하여 SageMaker에 대한 항목별 요금 목록을 확인할 수 있습니다. SageMaker용 AWS Management Console의 상단 메뉴에서 ‘서비스’를 선택하고, 검색 상자에 ‘billing(결제)’을 입력하고, 드롭다운 메뉴에서 결제를 선택한 다음 왼쪽 패널에서 ‘청구서’를 선택합니다. Details(세부 정보) 섹션에서 SageMaker를 선택하여 리전 목록을 확장하고 항목별 요금으로 드릴다운할 수 있습니다."
"8","sagemaker","Amazon SageMaker Studio Lab이란 무엇인가요?","SageMaker Studio Lab은 누구나 ML을 배우고 실험할 수 있도록 컴퓨팅, 스토리지(최대 15GB) 및 보안을 모두 무료로 제공하는 무료 기계 학습 개발 환경입니다. 시작하려면 유효한 이메일 ID만 있으면 됩니다. 인프라를 구성하거나 ID 및 액세스를 관리하거나 AWS 계정에 가입할 필요가 없습니다. SageMaker Studio Lab은 GitHub 통합을 통해 모델 구축을 가속화하고 가장 인기 있는 ML 도구, 프레임워크 및 라이브러리로 사전 구성되어 제공되므로 즉시 시작할 수 있습니다. SageMaker Studio Lab은 작업을 자동으로 저장하므로 세션 사이에 다시 시작할 필요가 없습니다. 노트북을 닫았다가 나중에 다시 열고 작업하는 것처럼 쉽습니다.","no: 8, service: sagemaker, question: Amazon SageMaker Studio Lab이란 무엇인가요?, answer: SageMaker Studio Lab은 누구나 ML을 배우고 실험할 수 있도록 컴퓨팅, 스토리지(최대 15GB) 및 보안을 모두 무료로 제공하는 무료 기계 학습 개발 환경입니다. 시작하려면 유효한 이메일 ID만 있으면 됩니다. 인프라를 구성하거나 ID 및 액세스를 관리하거나 AWS 계정에 가입할 필요가 없습니다. SageMaker Studio Lab은 GitHub 통합을 통해 모델 구축을 가속화하고 가장 인기 있는 ML 도구, 프레임워크 및 라이브러리로 사전 구성되어 제공되므로 즉시 시작할 수 있습니다. SageMaker Studio Lab은 작업을 자동으로 저장하므로 세션 사이에 다시 시작할 필요가 없습니다. 노트북을 닫았다가 나중에 다시 열고 작업하는 것처럼 쉽습니다."
"9","sagemaker","Amazon SageMaker 절감형 플랜이란 무엇인가요?","SageMaker 절감형 플랜은 1년 또는 3년의 일정 사용량 약정(시간당 USD 요금으로 측정)을 조건으로 SageMaker에서 유연한 사용량 기반 요금 모델을 제공합니다. SageMaker 절감형 플랜은 최대 64%까지 비용을 절감할 수 있는 가장 유연한 요금 모델입니다. 이 요금은 인스턴스 패밀리, 크기 또는 리전과 관계없이 SageMaker Studio 노트북, SageMaker 온디맨드 노트북, SageMaker 처리, SageMaker Data Wrangler, SageMaker 훈련, SageMaker 실시간 추론 및 SageMaker 배치 변환을 포함하여 적격 SageMaker ML 인스턴스 사용량에 자동으로 적용됩니다. 예를 들어 추론 워크로드를 위해 미국 동부(오하이오)에서 실행되는 CPU 인스턴스 ml.c5.xlarge에서 미국 서부(오레곤)의 ml.Inf1 인스턴스로 언제든지 변경할 수 있으며, 절감형 플랜 요금이 자동으로 계속 적용됩니다.","no: 9, service: sagemaker, question: Amazon SageMaker 절감형 플랜이란 무엇인가요?, answer: SageMaker 절감형 플랜은 1년 또는 3년의 일정 사용량 약정(시간당 USD 요금으로 측정)을 조건으로 SageMaker에서 유연한 사용량 기반 요금 모델을 제공합니다. SageMaker 절감형 플랜은 최대 64%까지 비용을 절감할 수 있는 가장 유연한 요금 모델입니다. 이 요금은 인스턴스 패밀리, 크기 또는 리전과 관계없이 SageMaker Studio 노트북, SageMaker 온디맨드 노트북, SageMaker 처리, SageMaker Data Wrangler, SageMaker 훈련, SageMaker 실시간 추론 및 SageMaker 배치 변환을 포함하여 적격 SageMaker ML 인스턴스 사용량에 자동으로 적용됩니다. 예를 들어 추론 워크로드를 위해 미국 동부(오하이오)에서 실행되는 CPU 인스턴스 ml.c5.xlarge에서 미국 서부(오레곤)의 ml.Inf1 인스턴스로 언제든지 변경할 수 있으며, 절감형 플랜 요금이 자동으로 계속 적용됩니다."
"10","sagemaker","SageMaker 절감형 플랜을 사용해야 하는 이유는 무엇인가요?","SageMaker 인스턴스 사용량이 일정한 크기이고(시간당 USD 요금으로 측정됨), 여러 SageMaker 구성 요소를 사용하거나 시간이 지남에 따라 기술 구성(예: 인스턴스 패밀리, 리전)이 변경될 것으로 예상되는 경우 SageMaker 절감형 플랜을 사용하면 절감 효과를 극대화하면서 애플리케이션 요구 사항 또는 새로운 혁신에 따라 기본적인 기술 구성을 유연하게 변경할 수 있습니다. 절감형 플랜 요금은 수동으로 수정하지 않고도 모든 적격 기계 학습 인스턴스 사용량에 자동으로 적용됩니다.","no: 10, service: sagemaker, question: SageMaker 절감형 플랜을 사용해야 하는 이유는 무엇인가요?, answer: SageMaker 인스턴스 사용량이 일정한 크기이고(시간당 USD 요금으로 측정됨), 여러 SageMaker 구성 요소를 사용하거나 시간이 지남에 따라 기술 구성(예: 인스턴스 패밀리, 리전)이 변경될 것으로 예상되는 경우 SageMaker 절감형 플랜을 사용하면 절감 효과를 극대화하면서 애플리케이션 요구 사항 또는 새로운 혁신에 따라 기본적인 기술 구성을 유연하게 변경할 수 있습니다. 절감형 플랜 요금은 수동으로 수정하지 않고도 모든 적격 기계 학습 인스턴스 사용량에 자동으로 적용됩니다."
processed_sagemaker.csv.metadata.json
{
"metadataAttributes": {
"language": "ko"
},
"documentStructureConfiguration": {
"type": "RECORD_BASED_STRUCTURE_METADATA",
"recordBasedStructureMetadata": {
"contentFields": [
{
"fieldName": "content"
}
],
"metadataFieldsSpecification": {
"fieldsToInclude": [
{
"fieldName": "no"
},
{
"fieldName": "service"
},
{
"fieldName": "question"
},
{
"fieldName": "answer"
}
]
}
}
}
}
Amazon Bedrock 지식 기반이 이 CSV 파일을 처리할 때, 각 행(레코드)이 하나의 청크가 되며 다음과 같은 메타데이터가 자동으로 생성됩니다.
전역 메타데이터
모든 청크에 공통 적용되는 메타데이터:
레코드별 메타데이터
각 CSV 행에서 추출되는 개별 청크 메타데이터:
{
"no": "1",
"service": "sagemaker",
"question": "SageMaker 사용 요금은 어떻게 부과되나요?",
"answer": "노트북을 호스팅하고 모델을 훈련하고 예측을 수행하며..."
}
벡터화 대상 콘텐츠
content 필드: 실제 임베딩되어 검색되는 텍스트
8. 이후 다시 이전 Knowledge Bases 콘솔로 돌아가서 processed_sagemaker.csv 파일들과 metadata.json 파일을 추가한 데이터 소스의 체크 박스를 선택한 후 Sync 버튼을 클릭하여 데이터 동기화 작업을 진행합니다.
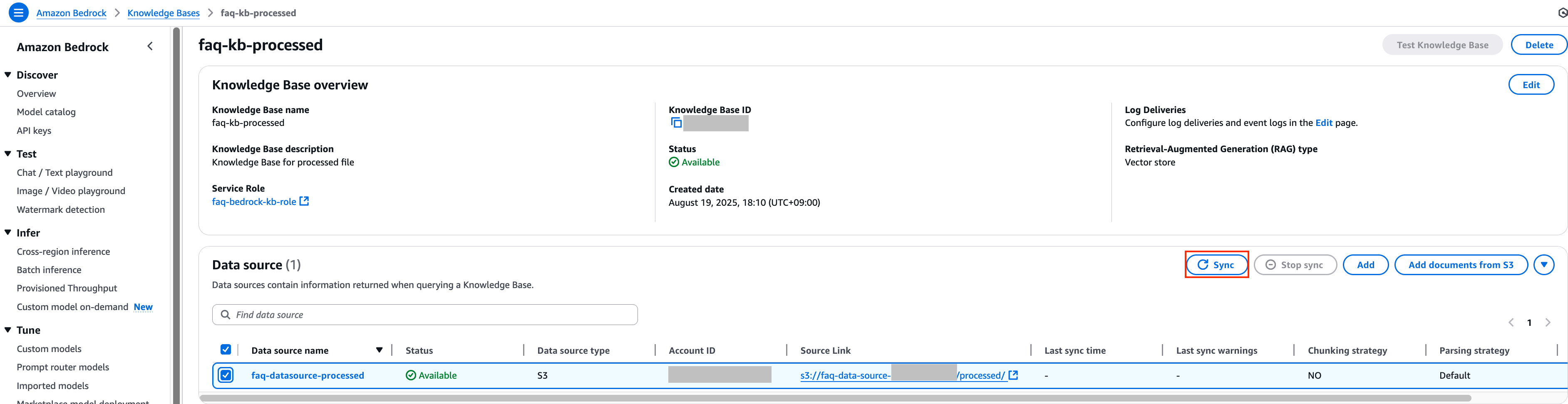
9. 동일하게 일정 시간이 지난 후 데이터 동기화 작업이 정상적으로 수행이 되었는지 확인합니다.
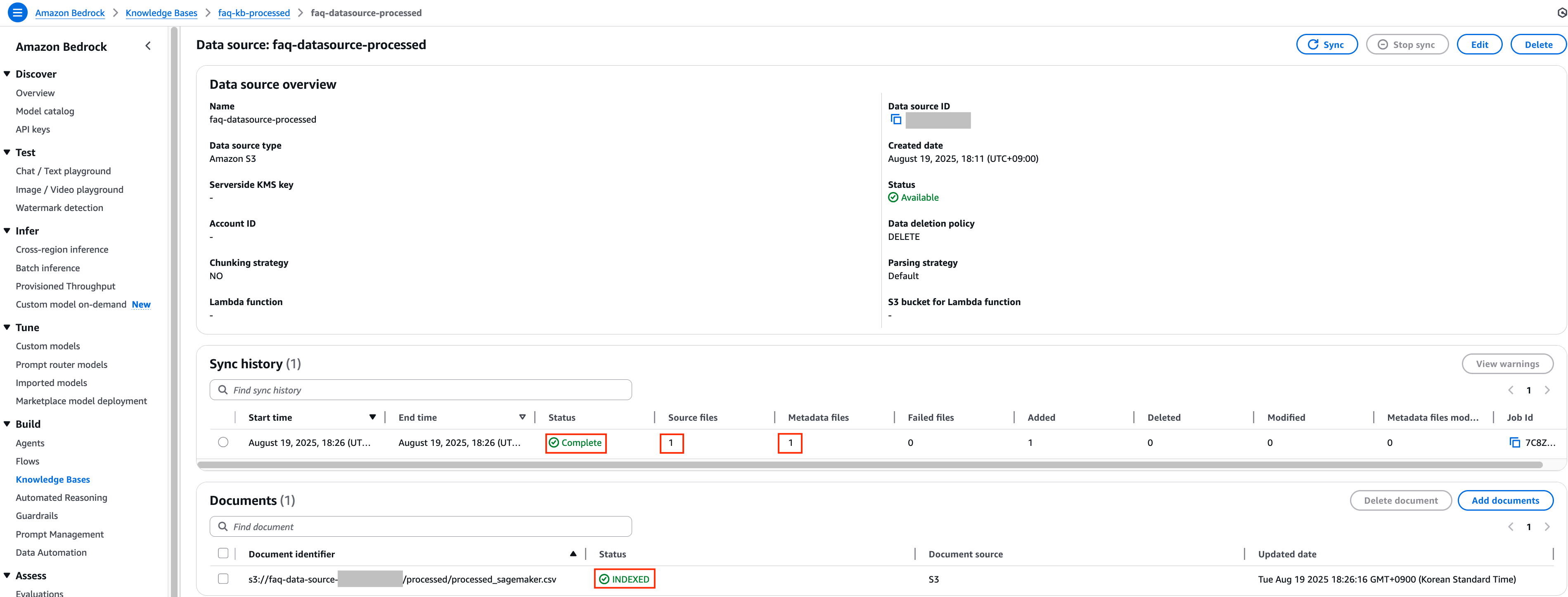
두 Knowledge Bases 모두 정상적으로 동기화가 완료된 것을 확인 후 각각의 Knowledge Bases에 대해 테스트를 진행하여 청크의 정확도 차이를 비교 분석 해보도록 하겠습니다.
각 Knowledge Base의 응답 성능 비교
1. 먼저 원본 데이터로 동기화 한 faq-kb-raw Knowledge Bases에 대해 테스트를 진행하기 위해 Test Knowledge Base 버튼을 클릭합니다.

Amazon Bedrock Knowledge Bases는 두 가지 주요 API를 통해 접근할 수 있습니다. 먼저 Retrieve API는 Knowledge Bases에서 관련 정보만 직접 검색하여 반환하며, LLM 처리 없이 순수한 검색 결과를 제공합니다. 반면 RetrieveAndGenerate API는 Knowledge Bases 검색과 LLM 생성을 하나의 과정으로 통합하여, 검색된 정보를 바탕으로 자연스러운 응답을 자동으로 생성해 줍니다.
이번 데모에서는 Knowledge Bases의 API 중 RetrieveAndGenerate API를 활용하여 지식 베이스 검색 결과를 바탕으로 LLM이 응답을 자동 생성하는 방식을 사용하도록 하겠습니다. 응답 생성을 위해서는 Select model 버튼을 클릭하여 사용할 모델을 지정해야 하며, 지정 모델로 Claude 3.7 Sonnet 모델을 사용하도록 하겠습니다.
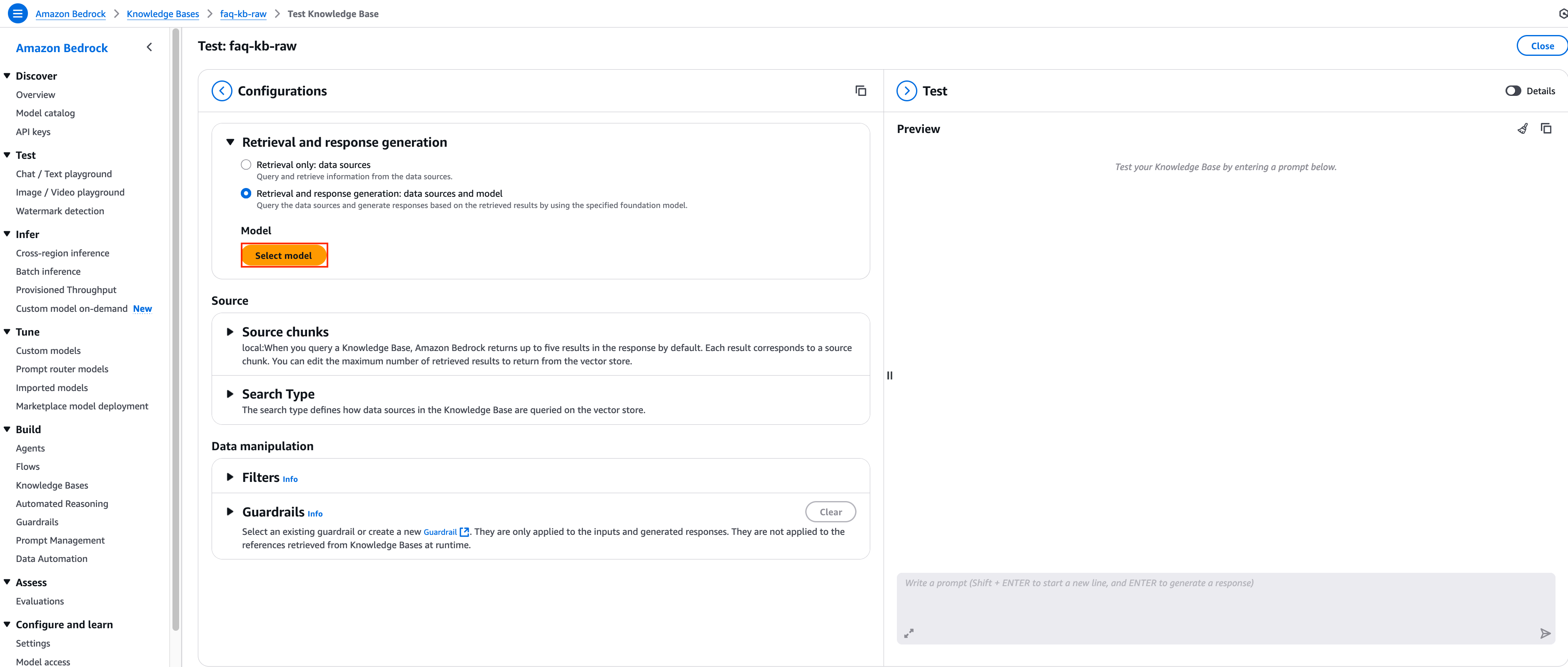
2. Claude 3.7 Sonnet 모델을 선택한 뒤 아래와 같은 질문 예시를 통해 어떤 응답이 반환되는 지 확인해보도록 하겠습니다. 아래 프롬프트를 대화창에 입력 후 Enter를 눌러주세요.
SageMaker의 비용 최적화 방법들을 모두 설명해주세요.
3. 답변이 화면에 표시되면 하단 Details를 클릭하여 답변을 생성하기 위하여 어떤 청크들이 벡터 저장소로부터 반환되었는지 확인하실 수 있습니다.
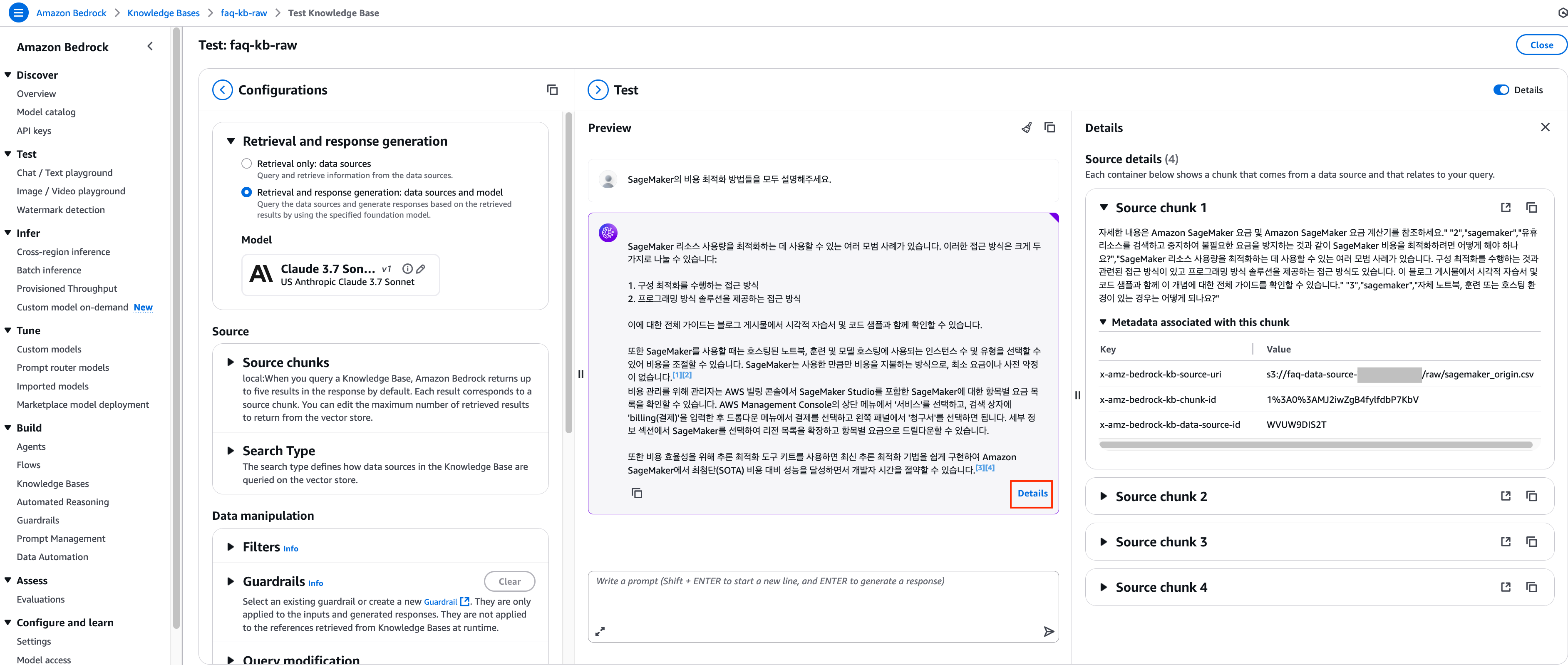
[반환된 Source chunk]
자세한 내용은 Amazon SageMaker 요금 및 Amazon SageMaker 요금 계산기를 참조하세요.” “2”,”sagemaker”,”유휴 리소스를 검색하고 중지하여 불필요한 요금을 방지하는 것과 같이 SageMaker 비용을 최적화하려면 어떻게 해야 하나요?”,”SageMaker 리소스 사용량을 최적화하는 데 사용할 수 있는 여러 모범 사례가 있습니다. 구성 최적화를 수행하는 것과 관련된 접근 방식이 있고 프로그래밍 방식 솔루션을 제공하는 접근 방식도 있습니다. 이 블로그 게시물에서 시각적 자습서 및 코드 샘플과 함께 이 개념에 대한 전체 가이드를 확인할 수 있습니다.” “3”,”sagemaker”,”자체 노트북, 훈련 또는 호스팅 환경이 있는 경우는 어떻게 되나요?”
no,service,question,answer “1”,”sagemaker”,”SageMaker 사용 요금은 어떻게 부과되나요?”,”노트북을 호스팅하고 모델을 훈련하고 예측을 수행하며 출력을 로깅하는 데 사용하는 ML 컴퓨팅, 스토리지 및 데이터 처리 리소스에 대한 요금이 부과됩니다. SageMaker를 사용할 때는 호스팅된 노트북, 훈련 및 모델 호스팅에 사용되는 인스턴스 수 및 유형을 선택할 수 있습니다. 서비스를 사용하면서 사용한 만큼만 비용을 지불하며 최소 요금 및 사전 약정은 없습니다. 자세한 내용은 Amazon SageMaker 요금 및 Amazon SageMaker 요금 계산기를 참조하세요.” “2”,”sagemaker”,”유휴 리소스를 검색하고 중지하여 불필요한 요금을 방지하는 것과 같이 SageMaker 비용을 최적화하려면 어떻게 해야 하나요?”
,”관리자는 AWS 빌링 콘솔에서 SageMaker Studio를 포함하여 SageMaker에 대한 항목별 요금 목록을 확인할 수 있습니다. SageMaker용 AWS Management Console의 상단 메뉴에서 ‘서비스’를 선택하고, 검색 상자에 ‘billing(결제)’을 입력하고, 드롭다운 메뉴에서 결제를 선택한 다음 왼쪽 패널에서 ‘청구서’를 선택합니다. Details(세부 정보) 섹션에서 SageMaker를 선택하여 리전 목록을 확장하고 항목별 요금으로 드릴다운할 수 있습니다.” “8”,”sagemaker”,”Amazon SageMaker Studio Lab이란 무엇인가요?”,”SageMaker Studio Lab은 누구나 ML을 배우고 실험할 수 있도록 컴퓨팅, 스토리지(최대 15GB) 및 보안을 모두 무료로 제공하는 무료 기계 학습 개발 환경입니다. 시작하려면 유효한 이메일 ID만 있으면 됩니다.
,”SageMaker는 완전한 전체 워크플로를 제공하지만, SageMaker에서 기존 도구를 계속 사용할 수 있습니다. 비즈니스 요구 사항에 따라 필요한 대로 SageMaker에서 각 단계의 결과를 손쉽게 송수신할 수 있습니다.” “4”,”sagemaker”,”추론 최적화 도구 키트가 무엇인가요?”,”추론 최적화 도구 키트를 사용하면 최신 추론 최적화 기법을 쉽게 구현하여 Amazon SageMaker에서 최첨단(SOTA) 비용 대비 성능을 달성하는 동시에 몇 개월의 개발자 시간을 절약할 수 있습니다.
해당 질문에 대한 답변으로 아래와 같은 응답을 반환받을 수 있었지만, 연관된 청크는 하나의 질의응답으로 구성된 행이 아닌 여러 행이 겹쳐서 만들어진 청크가 반환되는 걸 확인할 수 있습니다. 이는 default chunking 방식이 내용의 의미적 구조를 고려하지 않고 단순히 300토큰씩 자르기 때문에 발생하는 현상입니다. 이러한 방식으로 인해 아래와 같이 하나의 질의응답이 여러 청크로 분할되거나 서로 다른 질의응답이 하나의 청크로 합쳐지는 경우가 발생할 수 있습니다.
4. 이제 가공된 데이터로 동기화 한 faq-kb-processed Knowledge Bases에 대해 테스트를 진행하기 위해 해당 리소스의 콘솔 페이지로 이동한 후 Test Knowledge Base 버튼을 클릭합니다.

5. 이전과 동일하게 Claude 3.7 Sonnet 모델을 선택하고, 동일한 질문을 하여 어떤 응답이 반환되는 지 확인해보도록 하겠습니다. 이전과 동일한 프롬프트를 입력 후 Enter를 눌러주세요.
SageMaker의 비용 최적화 방법들을 모두 설명해주세요.
6. 답변이 화면에 표시되면 하단 Details를 클릭하여 답변을 생성하기 위하여 어떤 청크들이 벡터 저장소로부터 반환되었는지 확인하실 수 있습니다.
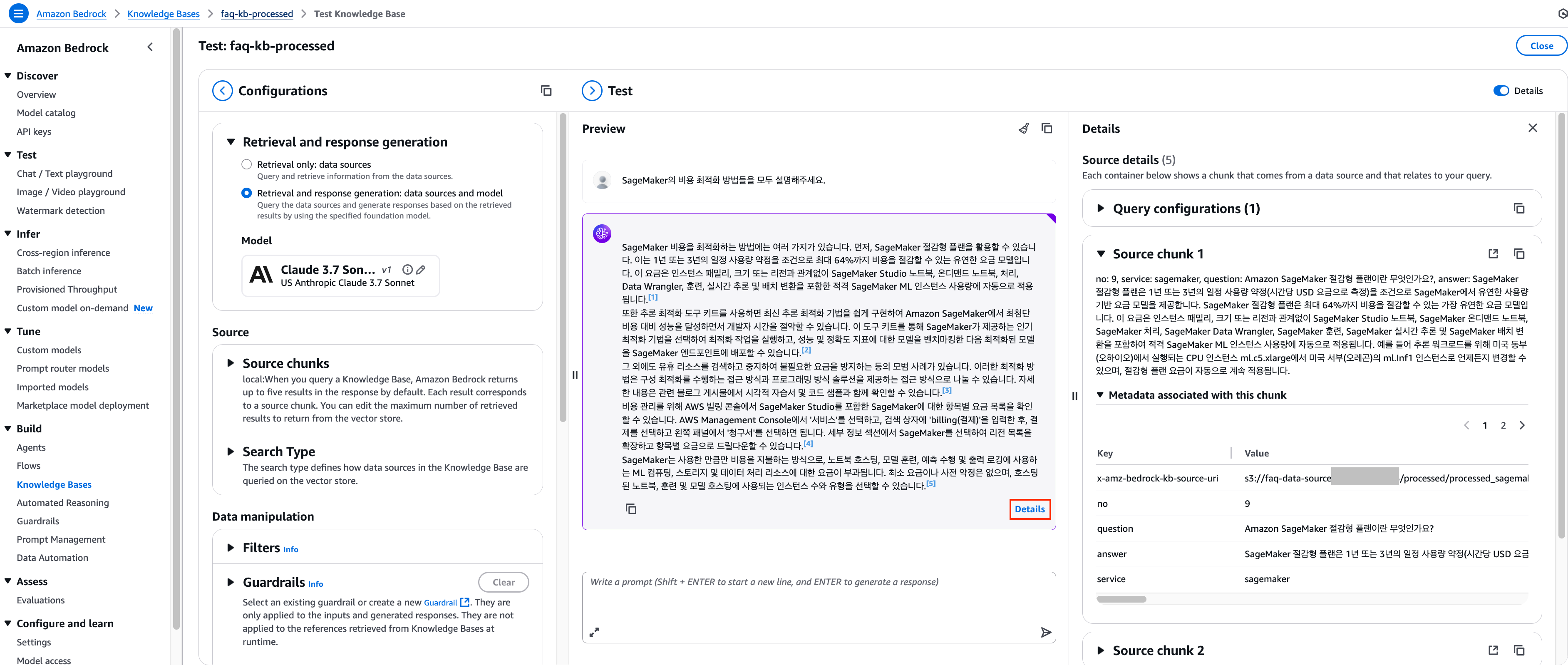
[반환된 Source chunk]
no: 9, service: sagemaker, question: Amazon SageMaker 절감형 플랜이란 무엇인가요?, answer: SageMaker 절감형 플랜은 1년 또는 3년의 일정 사용량 약정(시간당 USD 요금으로 측정)을 조건으로 SageMaker에서 유연한 사용량 기반 요금 모델을 제공합니다. SageMaker 절감형 플랜은 최대 64%까지 비용을 절감할 수 있는 가장 유연한 요금 모델입니다. 이 요금은 인스턴스 패밀리, 크기 또는 리전과 관계없이 SageMaker Studio 노트북, SageMaker 온디맨드 노트북, SageMaker 처리, SageMaker Data Wrangler, SageMaker 훈련, SageMaker 실시간 추론 및 SageMaker 배치 변환을 포함하여 적격 SageMaker ML 인스턴스 사용량에 자동으로 적용됩니다. 예를 들어 추론 워크로드를 위해 미국 동부(오하이오)에서 실행되는 CPU 인스턴스 ml.c5.xlarge에서 미국 서부(오레곤)의 ml.Inf1 인스턴스로 언제든지 변경할 수 있으며, 절감형 플랜 요금이 자동으로 계속 적용됩니다.
no: 4, service: sagemaker, question: 추론 최적화 도구 키트가 무엇인가요?, answer: 추론 최적화 도구 키트를 사용하면 최신 추론 최적화 기법을 쉽게 구현하여 Amazon SageMaker에서 최첨단(SOTA) 비용 대비 성능을 달성하는 동시에 몇 개월의 개발자 시간을 절약할 수 있습니다. SageMaker가 제공하는 인기 최적화 기법 메뉴에서 선택하여 최적화 작업을 미리 실행하고, 성능 및 정확도 지표에 대한 모델을 벤치마킹한 다음 추론을 위해 최적화된 모델을 SageMaker 엔드포인트에 배포할 수 있습니다. 도구 키트가 모델 최적화의 모든 측면을 처리하므로 비즈니스 목표에 더 집중할 수 있습니다.
no: 2, service: sagemaker, question: 유휴 리소스를 검색하고 중지하여 불필요한 요금을 방지하는 것과 같이 SageMaker 비용을 최적화하려면 어떻게 해야 하나요?, answer: SageMaker 리소스 사용량을 최적화하는 데 사용할 수 있는 여러 모범 사례가 있습니다. 구성 최적화를 수행하는 것과 관련된 접근 방식이 있고 프로그래밍 방식 솔루션을 제공하는 접근 방식도 있습니다. 이 블로그 게시물에서 시각적 자습서 및 코드 샘플과 함께 이 개념에 대한 전체 가이드를 확인할 수 있습니다.
no: 7, service: sagemaker, question: SageMaker Studio 노트북 또는 기타 SageMaker 서비스에 대한 항목별 요금은 어떻게 확인하나요?, answer: 관리자는 AWS 빌링 콘솔에서 SageMaker Studio를 포함하여 SageMaker에 대한 항목별 요금 목록을 확인할 수 있습니다. SageMaker용 AWS Management Console의 상단 메뉴에서 ‘서비스’를 선택하고, 검색 상자에 ‘billing(결제)’을 입력하고, 드롭다운 메뉴에서 결제를 선택한 다음 왼쪽 패널에서 ‘청구서’를 선택합니다. Details(세부 정보) 섹션에서 SageMaker를 선택하여 리전 목록을 확장하고 항목별 요금으로 드릴다운할 수 있습니다.
no: 1, service: sagemaker, question: SageMaker 사용 요금은 어떻게 부과되나요?, answer: 노트북을 호스팅하고 모델을 훈련하고 예측을 수행하며 출력을 로깅하는 데 사용하는 ML 컴퓨팅, 스토리지 및 데이터 처리 리소스에 대한 요금이 부과됩니다. SageMaker를 사용할 때는 호스팅된 노트북, 훈련 및 모델 호스팅에 사용되는 인스턴스 수 및 유형을 선택할 수 있습니다. 서비스를 사용하면서 사용한 만큼만 비용을 지불하며 최소 요금 및 사전 약정은 없습니다. 자세한 내용은 Amazon SageMaker 요금 및 Amazon SageMaker 요금 계산기를 참조하세요.
이전에 원본 데이터로 조회한 결과보다 가공된 데이터로 조회했을 때 SageMaker 비용 최적화 정보를 명확한 카테고리로 구조화하고, 구체적인 수치(최대 64% 절감)와 적용 서비스를 명시하며, 분산된 정보를 통합하여 사용자가 더 효율적으로 정보를 파악하고 실제 적용할 수 있도록 응답을 반환하고 있습니다. 이 외에도 원본 데이터의 Knowledge Bases는 한 청크 안에 대략 300토큰 정도 들어가기 때문에 의미적으로 동일하지 않은 내용들이 한 청크 안에 혼재될 수 있지만, 가공된 데이터의 Knowledge Bases는 연관된 정보만 들어가게 되어 검색 정확도와 정보 활용도가 크게 향상됨을 확인할 수 있습니다.
이러한 향상된 결과는 가공된 데이터에 metadata.json 파일을 추가하여 CSV 파일 처리 방식을 최적화했기 때문입니다. metadata.json을 통해 documentStructureConfiguration 속성을 이용하여 특정 열을 콘텐츠 필드로 지정하고, “no chunking” 옵션을 선택함으로써 Knowledge Base가 CSV 파일의 각 행을 분할하지 않고 온전히 하나의 청크로 처리하도록 설정할 수 있습니다. 이를 통해 질의응답 쌍과 같은 논리적 단위가 여러 청크로 나뉘지 않고 완전한 형태로 보존되어, 보다 정확하고 유용한 정보 검색이 가능하게 됩니다.
메타데이터를 활용한 고급 검색 기능
가공된 데이터의 또 다른 장점은 구조화된 메타데이터를 활용한 정밀한 검색 필터링이 가능하다는 점입니다. CSV 파일의 각 열이 메타데이터 필드로 자동 매핑되어 다양한 검색 조건을 적용할 수 있습니다.
예를 들어 SageMaker뿐만 아니라 Glue에 대한 FAQ도 함께 문서에 포함되어 있다고 가정해보겠습니다.
no,service,question,answer,content
...(SageMaker FAQ)
"1","glue","AWS Glue는 요금이 어떻게 부과됩니까","AWS Glue 데이터 카탈로그에 저장되어 액세스되는 메타데이터에 대해서는 AWS Glue 데이터 카탈로그 프리 티어를 초과하는 부분에 한해 월별 요금을 지불합니다. 크롤러 실행에 대해서는 초 단위로 청구되는 시간당 요금을 지불하며 최소 시간은 10분입니다. 개발 엔드포인트를 사용하여 ETL 코드를 대화식으로 개발하는 경우, 개발 엔드포인트가 프로비저닝된 시간에 대해 초 단위로 청구되는 시간당 요금을 지불하며 최소 시간은 10분입니다. 또한 ETL 작업에 대해서는 초 단위로 청구되는 시간당 요금을 지불하며, 선택한 Glue 버전에 따라 최소 시간은 1분 또는 10분입니다. 자세한 내용은 요금 페이지를 참조하세요.","no: 1, service: glue, question: AWS Glue는 요금이 어떻게 부과됩니까, answer: AWS Glue 데이터 카탈로그에 저장되어 액세스되는 메타데이터에 대해서는 AWS Glue 데이터 카탈로그 프리 티어를 초과하는 부분에 한해 월별 요금을 지불합니다. 크롤러 실행에 대해서는 초 단위로 청구되는 시간당 요금을 지불하며 최소 시간은 10분입니다. 개발 엔드포인트를 사용하여 ETL 코드를 대화식으로 개발하는 경우, 개발 엔드포인트가 프로비저닝된 시간에 대해 초 단위로 청구되는 시간당 요금을 지불하며 최소 시간은 10분입니다. 또한 ETL 작업에 대해서는 초 단위로 청구되는 시간당 요금을 지불하며, 선택한 Glue 버전에 따라 최소 시간은 1분 또는 10분입니다. 자세한 내용은 요금 페이지를 참조하세요."
"2","glue","AWS Glue 작업에 대한 청구는 언제 시작되고 언제 종료됩니까","청구는 작업 실행 일정이 예약되는 대로 시작되고 전체 작업이 완료될 때까지 계속됩니다. AWS Glue에서는 작업이 실행된 시간에 대해서만 비용을 지불하며 환경 프로비저닝이나 가동 중단 시간에 대해서는 지불하지 않습니다.","no: 2, service: glue, question: AWS Glue 작업에 대한 청구는 언제 시작되고 언제 종료됩니까, answer: 청구는 작업 실행 일정이 예약되는 대로 시작되고 전체 작업이 완료될 때까지 계속됩니다. AWS Glue에서는 작업이 실행된 시간에 대해서만 비용을 지불하며 환경 프로비저닝이나 가동 중단 시간에 대해서는 지불하지 않습니다."
"3","glue","AWS Glue DataBrew를 무료로 사용해 볼 수 있습니까","예. AWS 프리 티어 계정에 가입한 다음, AWS Glue DataBrew Management Console에서 무료로 즉시 시작할 수 있습니다. Glue DataBrew를 처음 사용하는 경우 처음 40개의 대화형 세션이 무료입니다. 자세한 내용은 AWS Glue 요금 페이지를 참조하십시오.","no: 3, service: glue, question: AWS Glue DataBrew를 무료로 사용해 볼 수 있습니까, answer: 예. AWS 프리 티어 계정에 가입한 다음, AWS Glue DataBrew Management Console에서 무료로 즉시 시작할 수 있습니다. Glue DataBrew를 처음 사용하는 경우 처음 40개의 대화형 세션이 무료입니다. 자세한 내용은 AWS Glue 요금 페이지를 참조하십시오."
"4","glue","Glue Flex란 무엇인가요","AWS Glue Flex는 긴급하지 않은 데이터 통합 워크로드(예: 사전 프로덕션 작업, 테스트, 데이터 로드 등)의 비용을 최대 35% 절감할 수 있는 탄력적인 실행 작업 클래스입니다. Glue에는 표준 및 유연과 같은 두 가지 작업 실행 클래스가 있습니다. 표준 실행 클래스는 빠른 작업 시작과 전용 리소스를 요구하는 시간에 민감한 워크로드에 적합합니다. 탄력 실행 클래스는 시작 및 완료 시간이 달라질 수 있는 긴급하지 않은 작업에 적합합니다. AWS Glue Flex는 시간에 민감하지 않은 워크로드(예: 야간 배치 ETL 작업, 주말 작업, 일회성 대량 데이터 모으기 작업 등) 비용을 절감할 수 있습니다.","no: 4, service: glue, question: Glue Flex란 무엇인가요, answer: AWS Glue Flex는 긴급하지 않은 데이터 통합 워크로드(예: 사전 프로덕션 작업, 테스트, 데이터 로드 등)의 비용을 최대 35% 절감할 수 있는 탄력적인 실행 작업 클래스입니다. Glue에는 표준 및 유연과 같은 두 가지 작업 실행 클래스가 있습니다. 표준 실행 클래스는 빠른 작업 시작과 전용 리소스를 요구하는 시간에 민감한 워크로드에 적합합니다. 탄력 실행 클래스는 시작 및 완료 시간이 달라질 수 있는 긴급하지 않은 작업에 적합합니다. AWS Glue Flex는 시간에 민감하지 않은 워크로드(예: 야간 배치 ETL 작업, 주말 작업, 일회성 대량 데이터 모으기 작업 등) 비용을 절감할 수 있습니다."
"5","glue","AWS Glue의 표준 및 탄력 실행 클래스는 어떻게 다릅니까","AWS Glue의 표준 및 탄력 실행 클래스의 실행 속성은 서로 다릅니다. 표준 실행 클래스에서 작업은 바로 시작되고 실행 중에 전용 리소스가 제공됩니다. 탄력 실행 클래스 작업은 AWS에서 비전용 컴퓨팅 리소스에서 실행됩니다. 이러한 리소스는 작업 실행 중에 회수 가능하며, 시작 시간과 완료 시간은 상황에 따라 달라집니다. 결과적으로 두 실행 클래스가 적합한 워크로드는 서로 다릅니다. 표준 실행 클래스는 빠른 작업 시작과 전용 리소스를 요구하는 시간에 민감한 워크로드에 적합합니다. 탄력 실행 클래스는 시작 시간 및 완료 시간의 변화가 허용될 수 있는 긴급하지 않은 작업에 더 적합하고 비용이 더 저렴합니다.","no: 5, service: glue, question: AWS Glue의 표준 및 탄력 실행 클래스는 어떻게 다릅니까, answer: AWS Glue의 표준 및 탄력 실행 클래스의 실행 속성은 서로 다릅니다. 표준 실행 클래스에서 작업은 바로 시작되고 실행 중에 전용 리소스가 제공됩니다. 탄력 실행 클래스 작업은 AWS에서 비전용 컴퓨팅 리소스에서 실행됩니다. 이러한 리소스는 작업 실행 중에 회수 가능하며, 시작 시간과 완료 시간은 상황에 따라 달라집니다. 결과적으로 두 실행 클래스가 적합한 워크로드는 서로 다릅니다. 표준 실행 클래스는 빠른 작업 시작과 전용 리소스를 요구하는 시간에 민감한 워크로드에 적합합니다. 탄력 실행 클래스는 시작 시간 및 완료 시간의 변화가 허용될 수 있는 긴급하지 않은 작업에 더 적합하고 비용이 더 저렴합니다."
"6","glue","AWS Glue Flex 탄력 실행 클래스 작업을 시작하려면 어떻게 해야 합니까","탄력 실행 클래스는 Glue Spark 작업에서 사용할 수 있습니다. 탄력 실행 클래스를 사용하려는 경우 'STANDARD'에서 'FLEX'로 실행 클래스 파라미터의 기본 설정을 변경하면 됩니다. Glue Studio 또는 CLI에서 변경할 수 있습니다. 자세한 내용은 AWS Glue _사용 설명서_를 참조하세요.","no: 6, service: glue, question: AWS Glue Flex 탄력 실행 클래스 작업을 시작하려면 어떻게 해야 합니까, answer: 탄력 실행 클래스는 Glue Spark 작업에서 사용할 수 있습니다. 탄력 실행 클래스를 사용하려는 경우 'STANDARD'에서 'FLEX'로 실행 클래스 파라미터의 기본 설정을 변경하면 됩니다. Glue Studio 또는 CLI에서 변경할 수 있습니다. 자세한 내용은 AWS Glue _사용 설명서_를 참조하세요."
"7","glue","개발 엔드포인트에는 몇 개의 DPU(데이터 처리 유닛)가 할당되어 있습니까","개발 엔드포인트에는 기본적으로 5개의 DPU가 프로비저닝됩니다. 최소 2개의 DPU와 최대 5개의 DPU로 개발 엔드포인트를 구성할 수 있습니다.","no: 7, service: glue, question: 개발 엔드포인트에는 몇 개의 DPU(데이터 처리 유닛)가 할당되어 있습니까, answer: 개발 엔드포인트에는 기본적으로 5개의 DPU가 프로비저닝됩니다. 최소 2개의 DPU와 최대 5개의 DPU로 개발 엔드포인트를 구성할 수 있습니다."
"8","glue","내 AWS Glue ETL 작업 규모와 성능을 조정하려면 어떻게 해야 합니까","ETL 작업에 할당하고자 하는 DPU(데이터 처리 유닛) 수를 지정하기만 하면 됩니다. Glue ETL 작업에는 최소 2개의 DPU가 필요합니다. 기본적으로 AWS Glue는 각 ETL 작업에 10개의 DPU를 할당합니다.","no: 8, service: glue, question: 내 AWS Glue ETL 작업 규모와 성능을 조정하려면 어떻게 해야 합니까, answer: ETL 작업에 할당하고자 하는 DPU(데이터 처리 유닛) 수를 지정하기만 하면 됩니다. Glue ETL 작업에는 최소 2개의 DPU가 필요합니다. 기본적으로 AWS Glue는 각 ETL 작업에 10개의 DPU를 할당합니다."
"9","glue","AWS Glue 스키마 레지스트리란 무엇인가요","AWS Glue의 서버리스 기능인 AWS Glue 스키마 레지스트리를 통해 추가 요금 없이 Apache Avro에 등록 스키마 및 JSON 스키마 데이터 형식을 사용하여 스트리밍 데이터의 변화를 검증하고 제어할 수 있습니다.","no: 9, service: glue, question: AWS Glue 스키마 레지스트리란 무엇인가요, answer: AWS Glue의 서버리스 기능인 AWS Glue 스키마 레지스트리를 통해 추가 요금 없이 Apache Avro에 등록 스키마 및 JSON 스키마 데이터 형식을 사용하여 스트리밍 데이터의 변화를 검증하고 제어할 수 있습니다."
"10","glue","AWS Glue 스키마 레지스터리 사용량을 어떻게 모니터링하나요","AWS CloudWatch 지표는 CloudWatch 프리 티어의 일환으로 사용할 수 있습니다. CloudWatch 콘솔에서 이 지표에 액세스할 수 있습니다. 자세한 내용은 AWS Glue 스키마 레지스트리 사용 설명서를 참조하십시오.","no: 10, service: glue, question: AWS Glue 스키마 레지스터리 사용량을 어떻게 모니터링하나요, answer: AWS CloudWatch 지표는 CloudWatch 프리 티어의 일환으로 사용할 수 있습니다. CloudWatch 콘솔에서 이 지표에 액세스할 수 있습니다. 자세한 내용은 AWS Glue 스키마 레지스트리 사용 설명서를 참조하십시오."
*metadata.json 파일은 동일
메타데이터 필터링 테스트
1. faq-kb-processed Knowledge Base의 Test 화면을 열고 Filter가 없는 상태에서 다음과 같이 질의합니다.
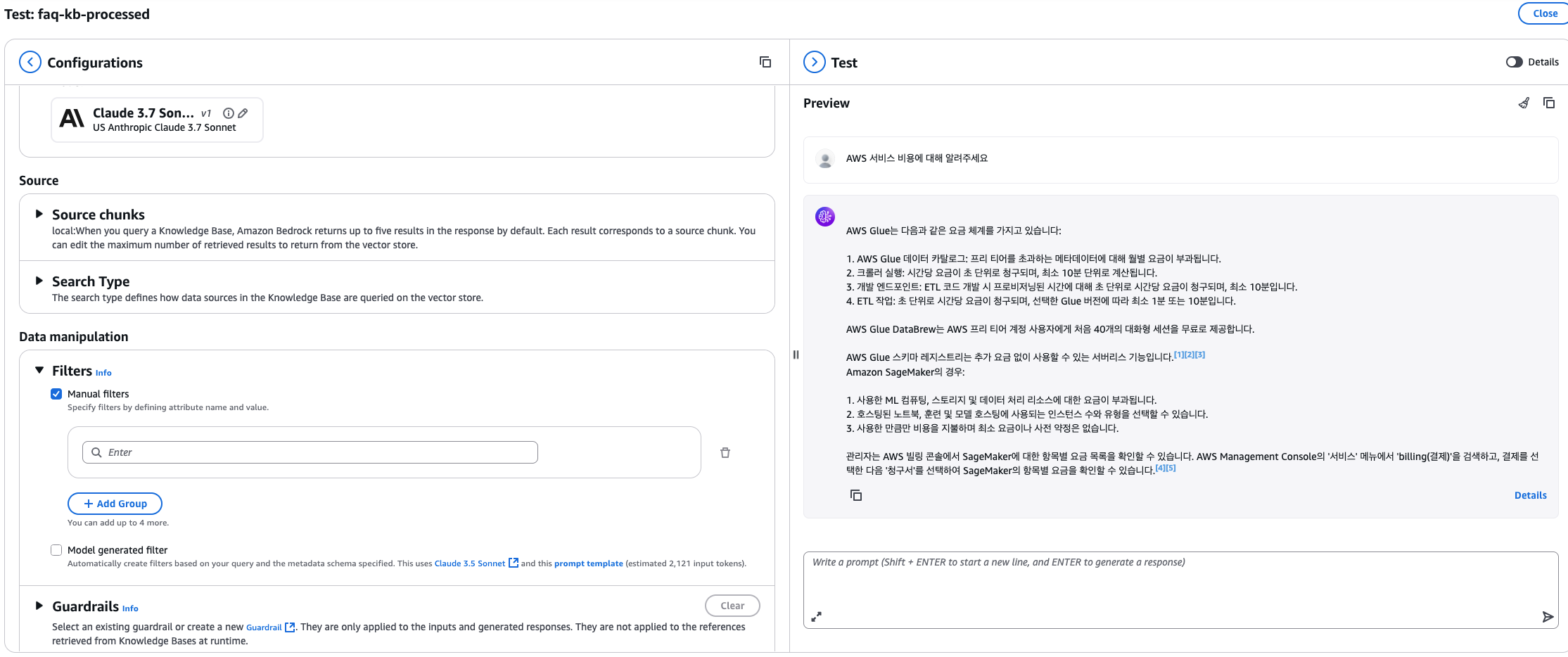
- SageMaker 및 Glue에 대한 문서를 기반으로 답변합니다.
2. 서비스별 필터링 적용
- Add filter 버튼을 클릭하여 필터를 추가합니다.
- Key:
service, Operator: Equals, Value: sagemaker를 입력합니다.
- 이제 SageMaker 관련 FAQ만 검색 대상이 됩니다.
- 기존 세션을 정리하고 동일하게 질의합니다.
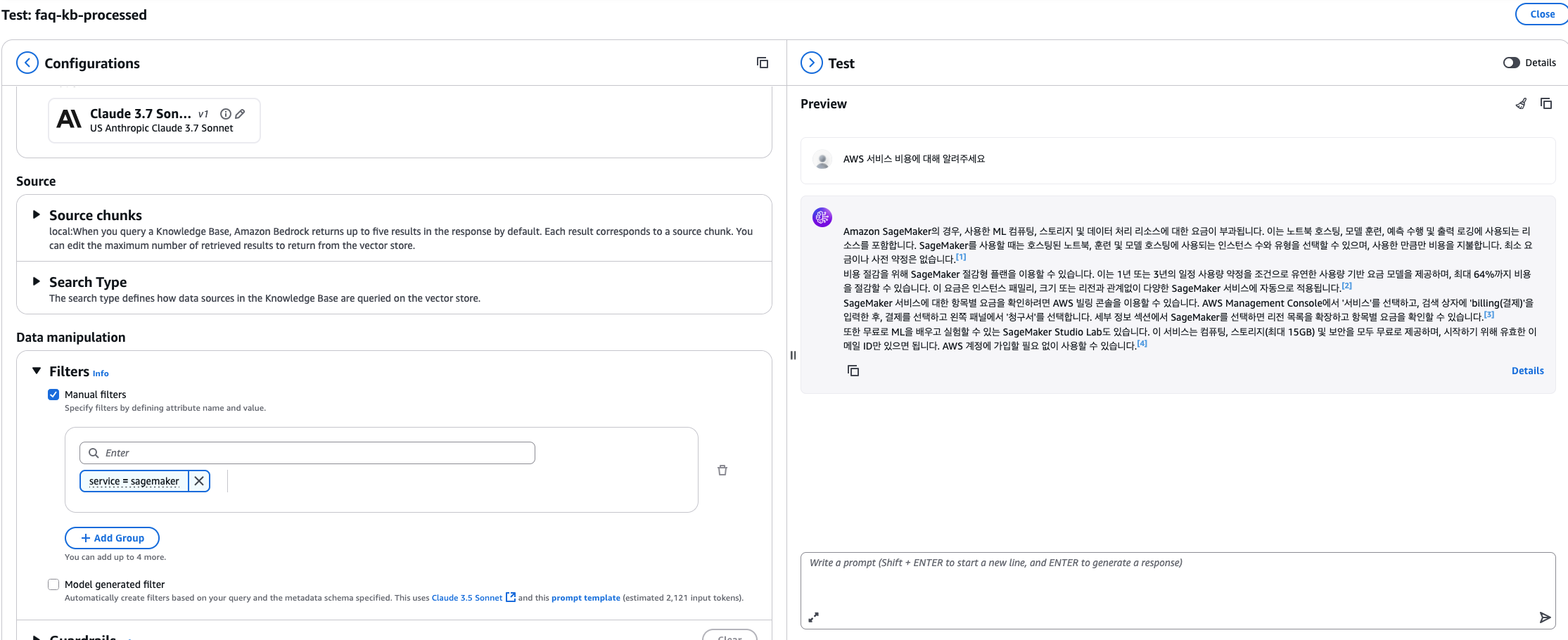
3. 복합 필터 적용 (Optional)
- 여러 필터를 조합하여 더욱 정밀한 검색이 가능합니다
- 예: 특정 서비스 + 특정 질문 번호 범위
- AND/OR 연산자를 통한 복잡한 조건 구성
메타데이터 활용의 이점
- 정확도 향상: 관련 없는 서비스의 정보가 섞이지 않아 응답 품질이 개선됩니다.
- 성능 최적화: 검색 범위를 사전에 제한하여 처리 속도가 향상됩니다.
- 동적 필터링: 사용자 컨텍스트에 따라 실시간으로 검색 범위를 조정할 수 있습니다.
- 멀티테넌시 지원: 동일한 Knowledge Base에서 서로 다른 팀이나 서비스별로 격리된 검색이 가능합니다.
이러한 메타데이터 기반 필터링은 원본 데이터(faq-kb-raw)에서는 구현이 어렵거나 불가능한 기능으로, 데이터 전처리와 metadata.json 설정을 통해서만 활용할 수 있는 기능입니다.
2. OpenSearch Dashboard를 통한 인덱스 데이터 검증
Amazon OpenSearch Serverless collection 확인
이번 섹션에서는 Data source의 chunking 전략에 따라 Amazon OpenSearch Serverless에 데이터가 어떻게 저장되는지 확인 하도록 하겠습니다. Amazon OpenSearch의 Dashboard를 이용하여 index에 저장된 내용을 확인 하고, 데이터 포맷에 따른 적절한 chunking 전략 선택을 고민하면 Amazon Bedrock Knowledge base의 응답 정확도 향상에 도움이 될 것입니다.
기존에 생성한 Knowledge base와 Data source는 아래와 같습니다.
- faq-kb-raw
- faq-kb-processed
Knowledge Base는 2개로 분리 되어 있지만, vector store로 사용하는 Amazon OpenSearch Serverless collection은 동일합니다. 하지만, index는 2개로 분리 되어 있습니다.
- Amazon OpenSearch collection
- Collection name : faq-collection
- Vector index name
- faq-index-raw
- faq-index-processed
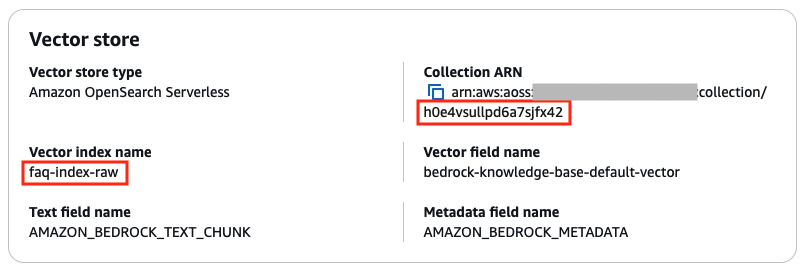
faq-kb-raw의 Vector store 정보
faq-kb-processed의 Vector store 정보

1. 아래의 명령어를 이용하여 생성한 Amazon OpenSearch Serverless collection의 이름을 확인 합니다.
$ aws opensearchserverless list-collections --region <region> --query "collectionSummaries[?id=='<your-collection-id>']"
[
{
"arn": "arn:aws:aoss:<region>:<account-id>:collection/<your-collection-id>",
"id": "<your-collection-id>",
"name": "faq-collection",
"status": "ACTIVE"
}
]
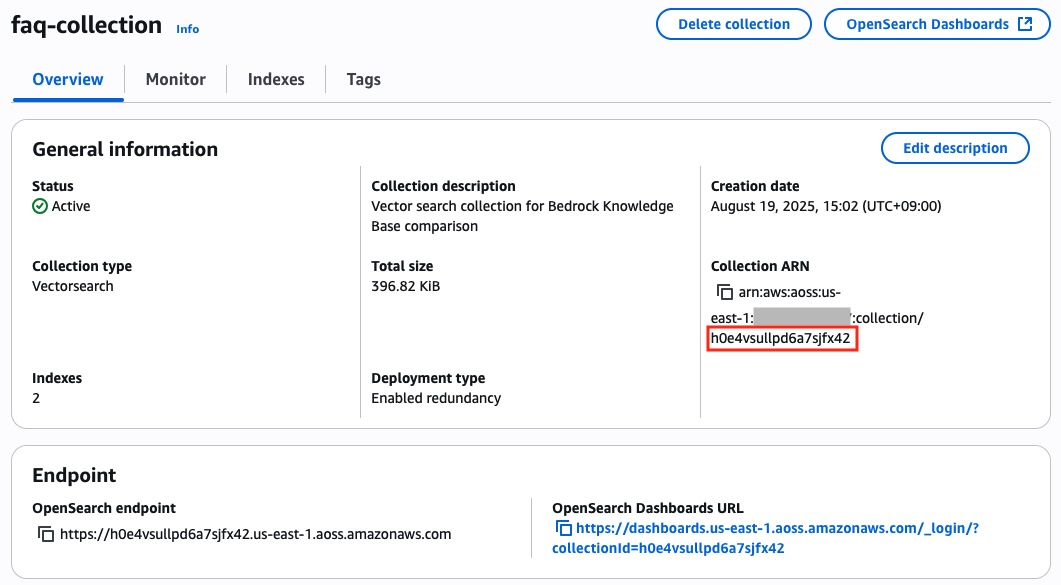
2. Amazon OpenSearch Service > Collections에서 해당 이름을 조회하면, 아래와 같은 Collection 이름과 OpenSearch Dashboard 링크를 확인 할 수 있습니다.

3. 해당 collection을 선택하면, 아래와 같이 General information 정보와 endpoint의 OpenSearch Dashboards URL을 확인 할 수 있습니다. 해당 URL로 접속하면 OpenSearch Dashboard에 접속이 가능합니다.
4. Indexes 탭에서는 해당 collection에 존재하는 Index 확인이 가능합니다.
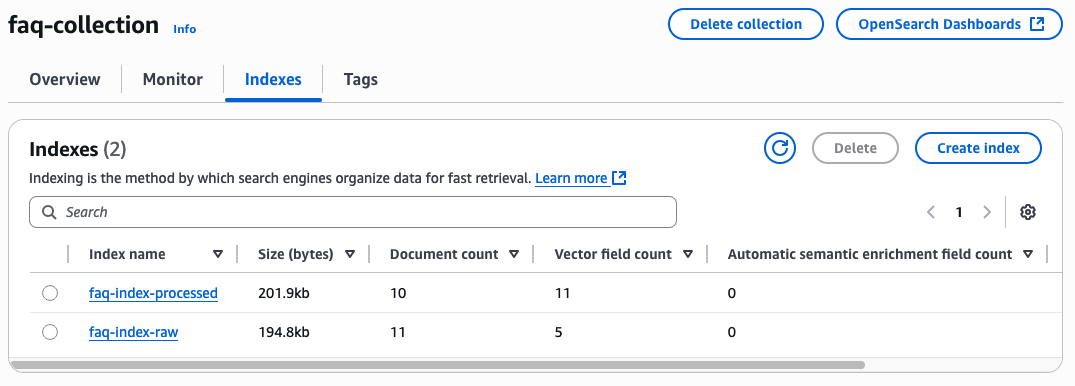
Document count 차이가 나는 이유는 faq-index-raw는 default chunk를 이용하여 임의로 300 token의 길이로 chunk를 나눈것이고, faq-index-processed는 no-chunk와 metadata를 이용하여 csv 파일의 1개 row가 1개의 chunk가 되도록 처리되어 결과가 다른 것입니다.
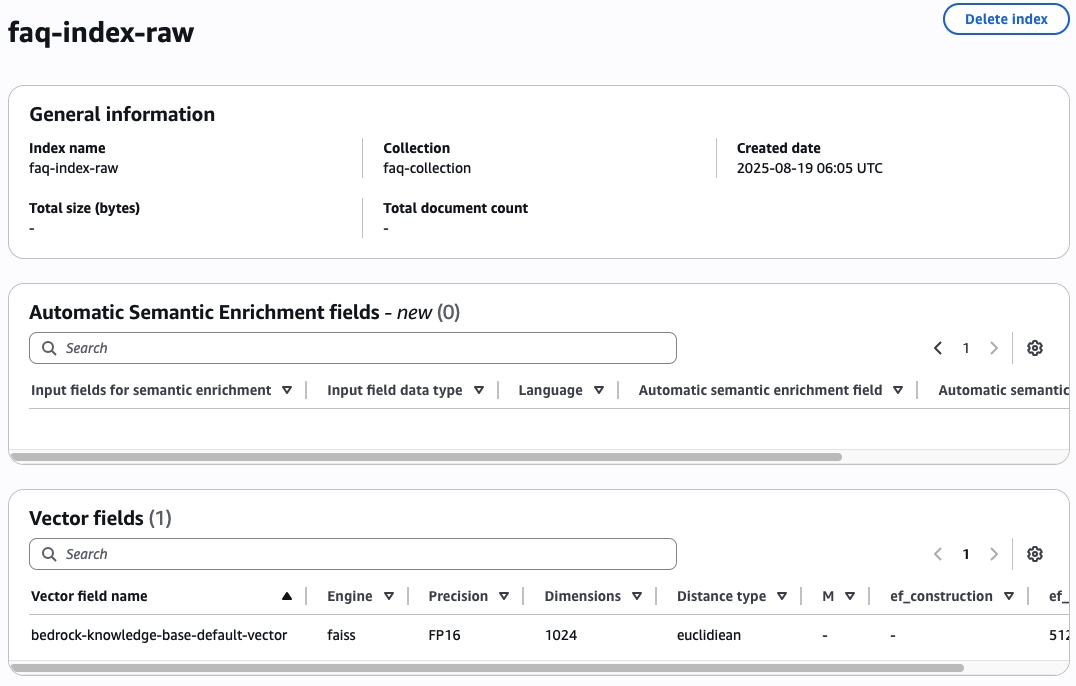
각 index를 선택하면 아래와 같이 vector fields와 metadata를 확인 할 수 있습니다. Vector fields의 bedrock-knowledge-base-default-vector는 문서의 vector embedding이 실제로 저장되는 field 입니다.
아래의 metadata에서 AMAZON_BEDROCK_METADATA 는 해당 chunk의 레퍼런스 파일의 s3 경로와 같은 metadata 데이터가 포함되고, AMAZON_BEDROCK_TEXT_CHUNK는 chunk text가 저장됩니다.
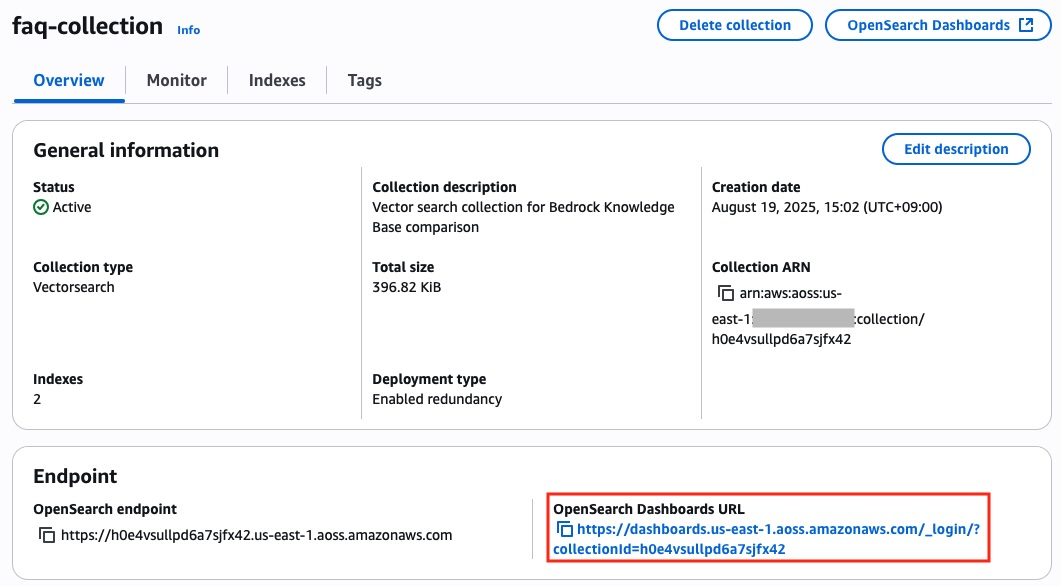
Amazon OpenSearch Dashboard 접속
1. Amazon OpenSearch collection에 저장된 내용을 보기 위해, OpenSearch Dashboard로 접속 해야 합니다. collection 상세페이지의 OpenSearch Dashboards 버튼 또는 OpenSearch Dashboards URL 을 클릭합니다.
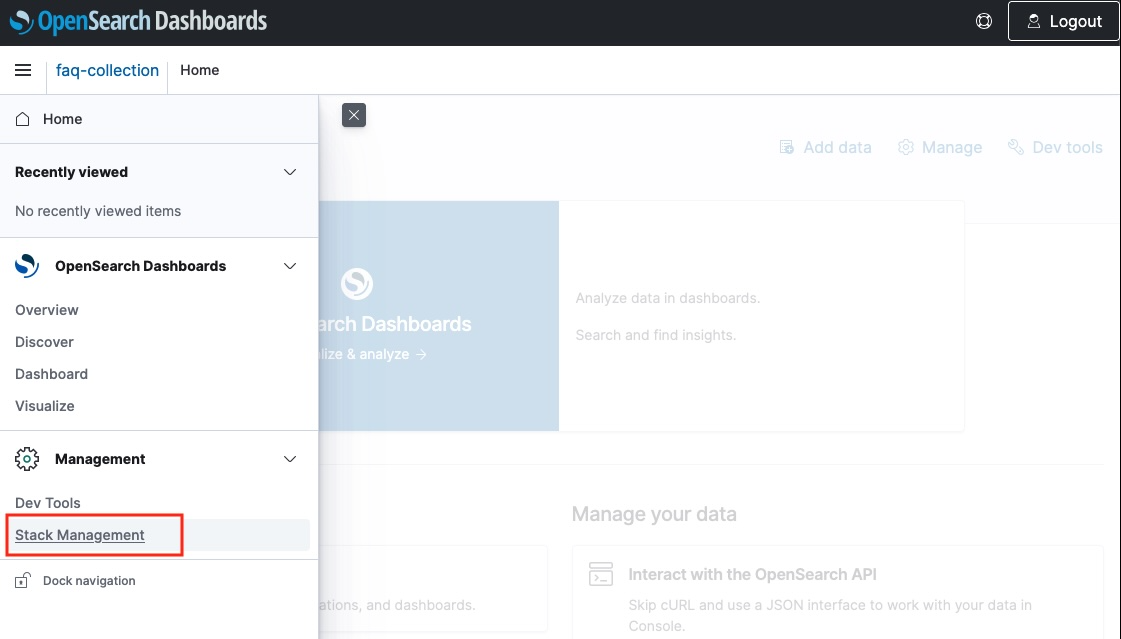
2. Dashboard에 접속 후, index 데이터를 조회를 하기 위해 index patterns을 등록해야 합니다. 왼쪽 사이드 메뉴의 Stack Management > Index Patterns > Create index pattern 을 클릭합니다.
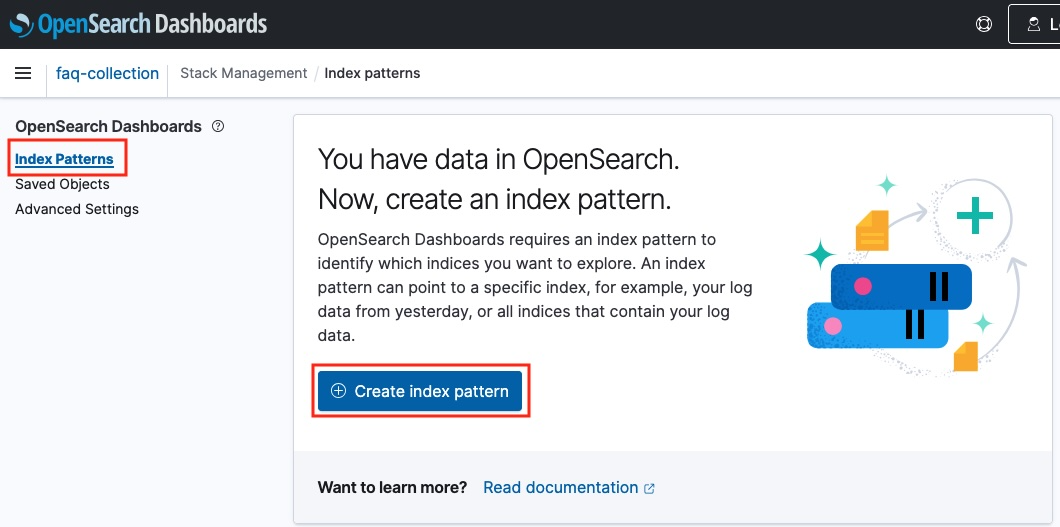
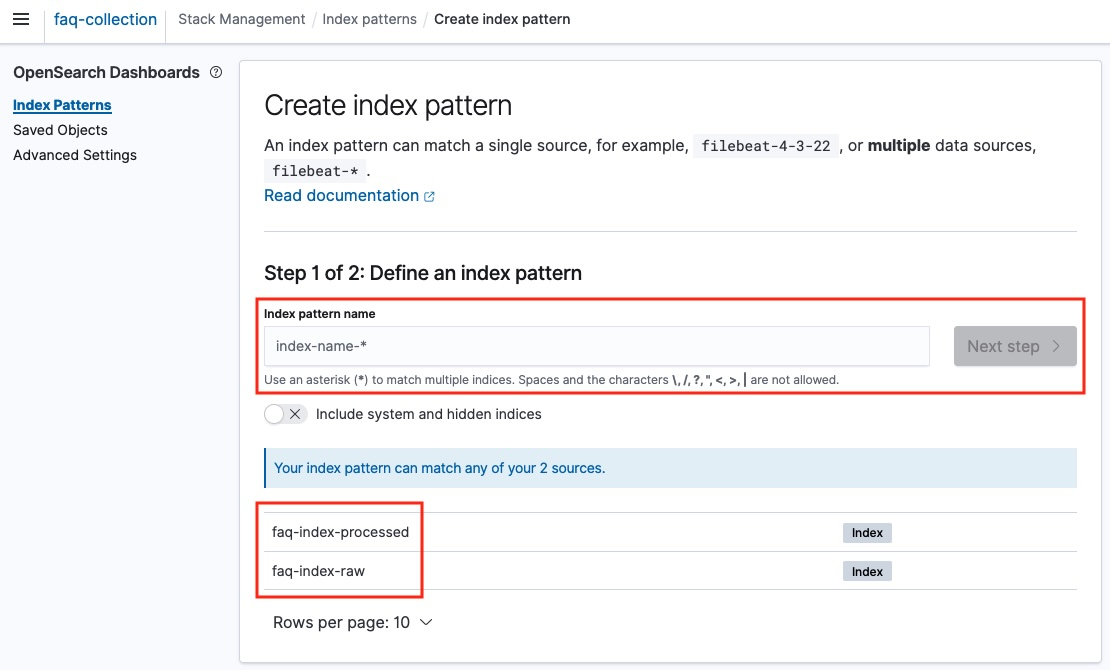
3. Create index pattern 페이지에 접속하면, 기존에 생성한 index를 확인 할 수 있습니다. 해당 index의 이름을 복사하여 index pattern name 에 입력 후, index pattern을 생성합니다.
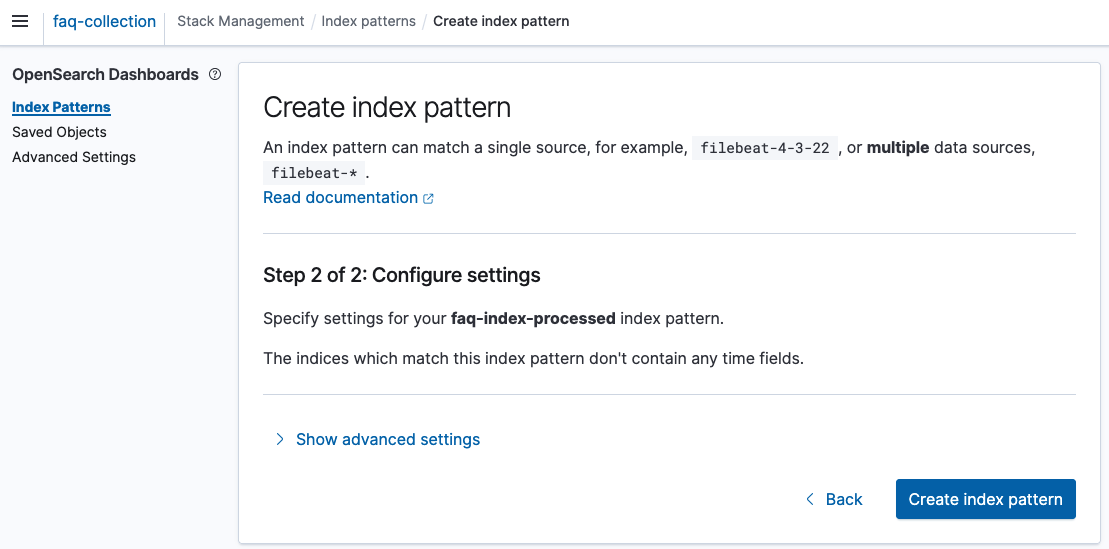
4. 2개의 index pattern을 모두 생성하면, 아래와 같이 2개의 index pattern을 화면에서 조회가 가능합니다.
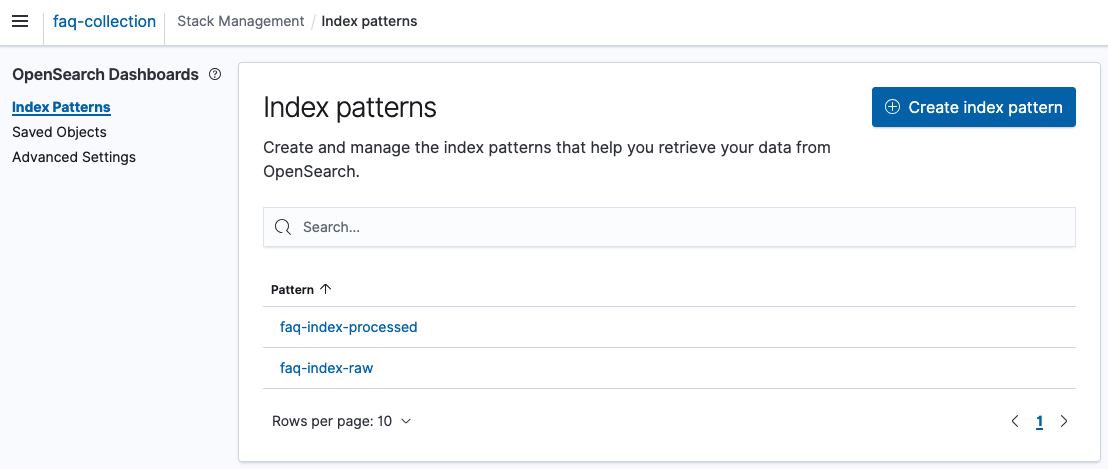
또한, 해당 pattern을 선택하면 index의 field의 정보를 확인 할 수 있습니다.
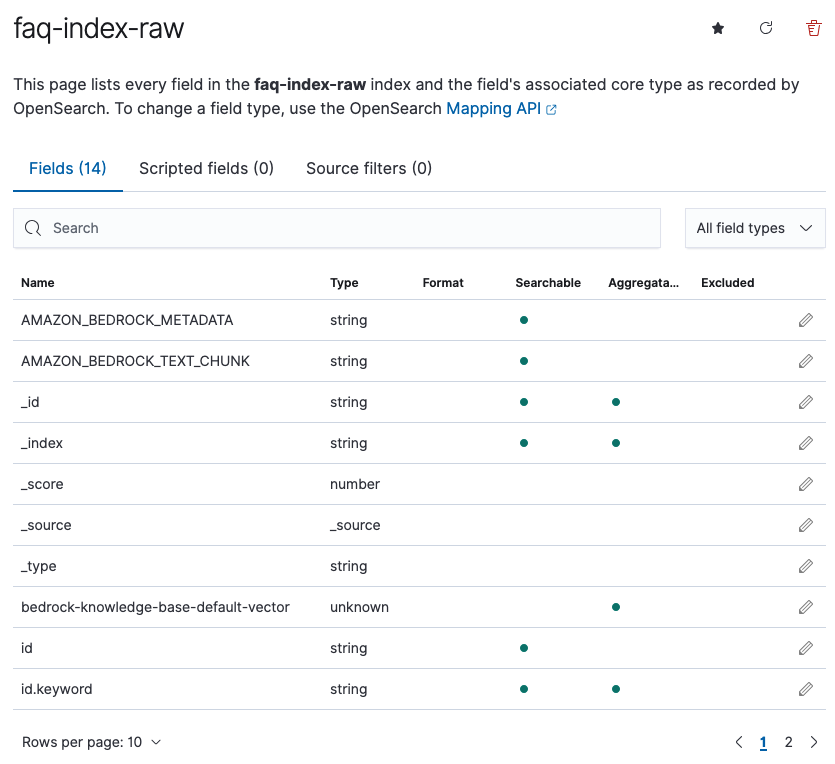
Discover로 index 데이터 확인
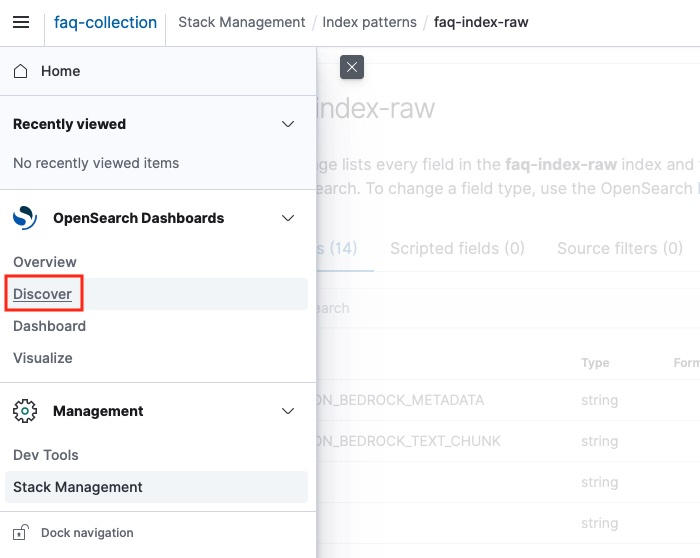
1. index pattern을 생성 후, 왼쪽 사이드 메뉴의 Discover 에 접속 합니다. Discover에서는 index pattern으로 등록한 index의 데이터를 조회 할 수 있습니다.
2. Discover 화면에서, index pattern을 변경하여 index별 데이터를 조회 할 수 있습니다. 왼쪽에는 field 명이 존재하고, 메인화면에서는 데이터를 확인 할 수 있습니다.
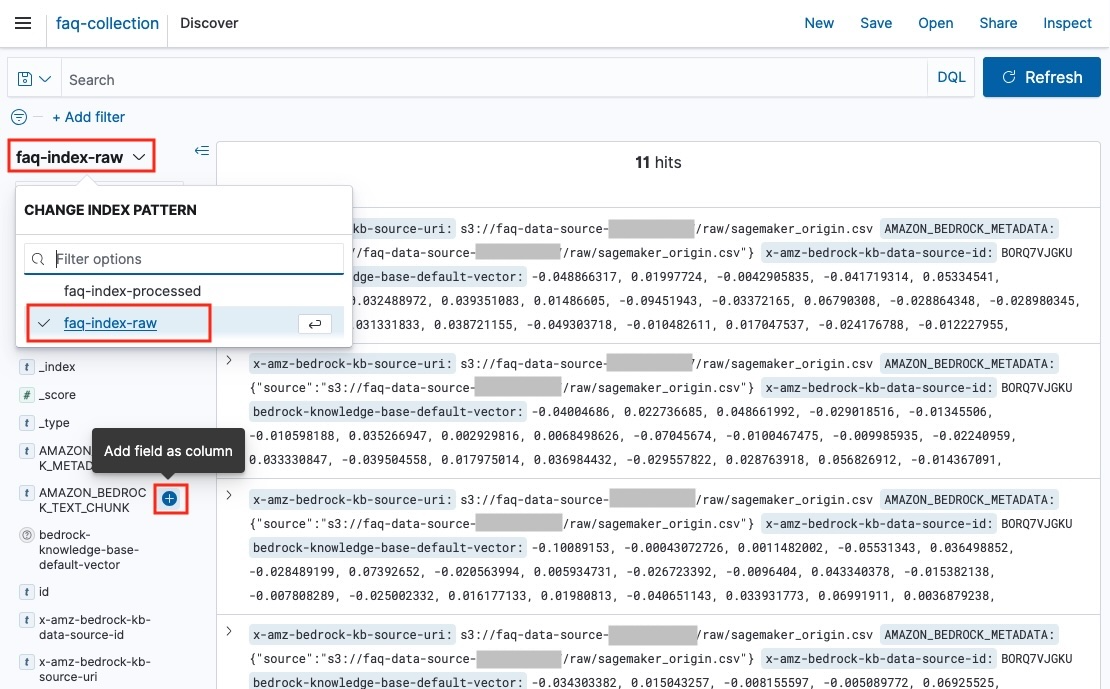
3. 왼쪽의 Available fields에서 특정 field를 선택하면, 메인화면에서 선택한 field를 테이블 형식으로 확인할 수 있습니다. 아래의 field를 선택하여 테이블 형식으로 데이터를 확인 하겠습니다.
AMAZON_BEDROCK_METADATA (metadata 정보 s3 경로 등)AMAOZN_BEDROCK_TEXT_CHUNK (chunk 텍스트)bedrock-knowledge-base-default-vector (임베딩된 벡터)
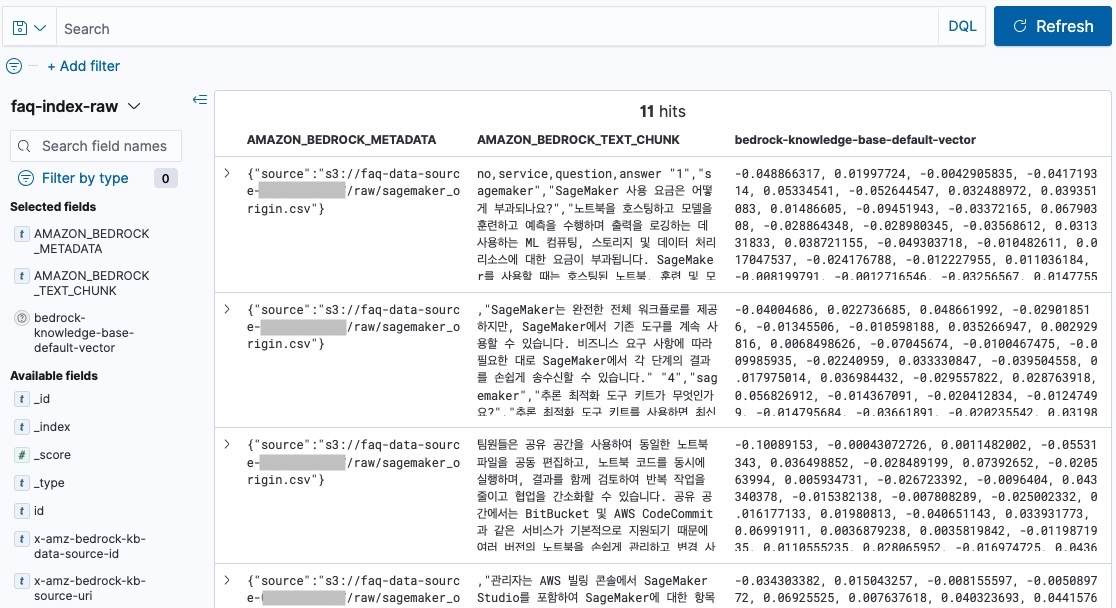
각 문서에 있는 > 버튼을 누르면, Expanded document 창이 추가되어 Table 또는 JSON 포맷으로 해당 문서를 확인 가능합니다.

4. 아래의 화면처럼 검색어를 입력하여 관련 문서를 검색 할 수 있습니다.
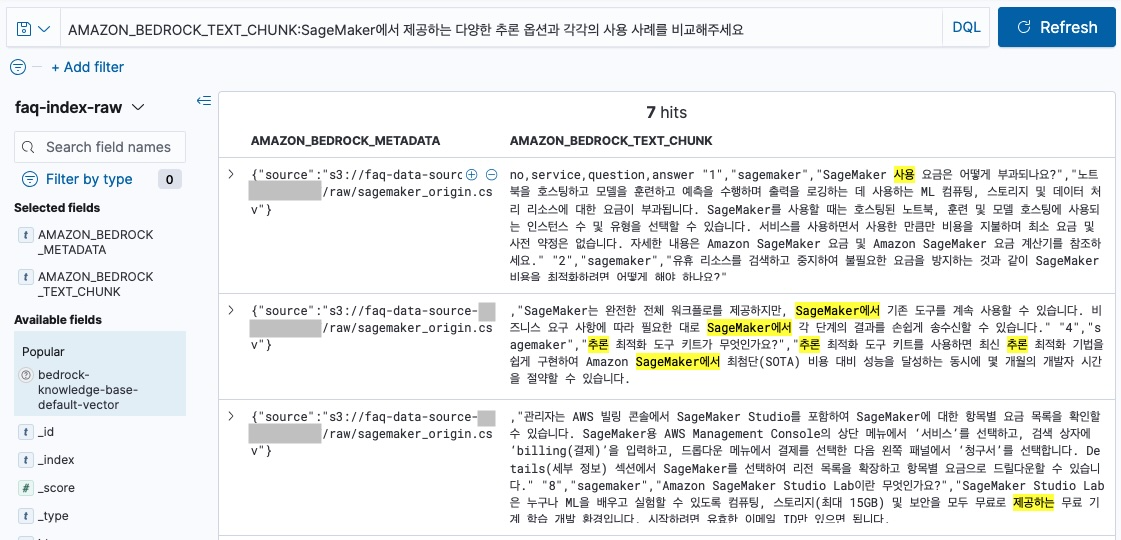
AMAZON_BEDROCK_TEXT_CHUNK:SageMaker에서 제공하는 다양한 추론 옵션과 각각의 사용 사례를 비교해주세요
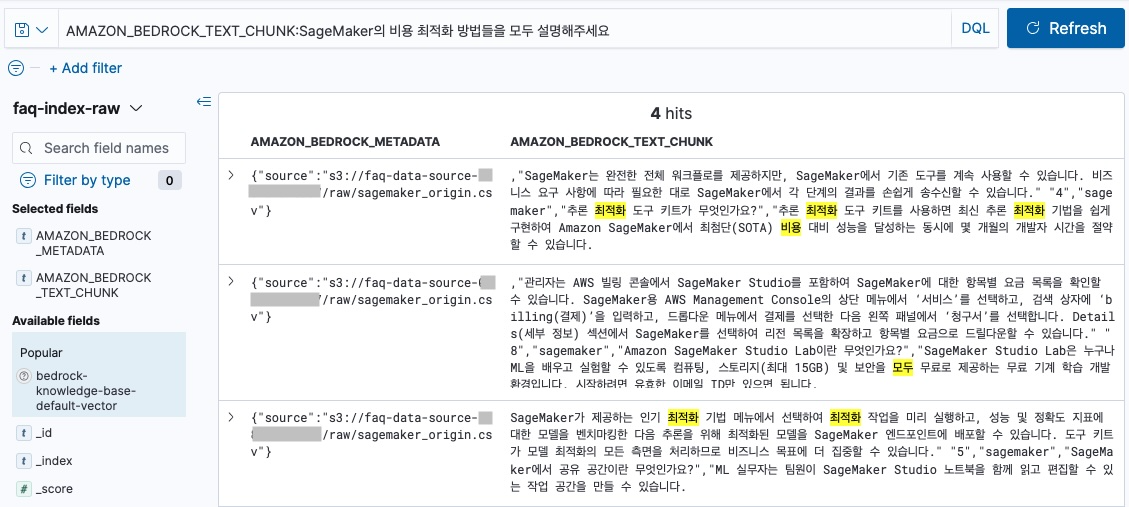
AMAZON_BEDROCK_TEXT_CHUNK:SageMaker의 비용 최적화 방법들을 모두 설명해주세요
참고로, OpenSearch Dashboard의 텍스트 검색결과와 Amazon Bedrock Knowledge Base의 벡터 임베딩 검색 결과는 다릅니다.
Knowledge Base로 query시 input 텍스트는 embedding model에 의해, vector embedding 되어 index의 vector와 비교를 하기 때문입니다.
OpenSearch Dashboard에서는 chunk 전략에 따라, 어떻게 문장이 저장 되는지 확인 하는 용도로 사용할 수 있습니다.
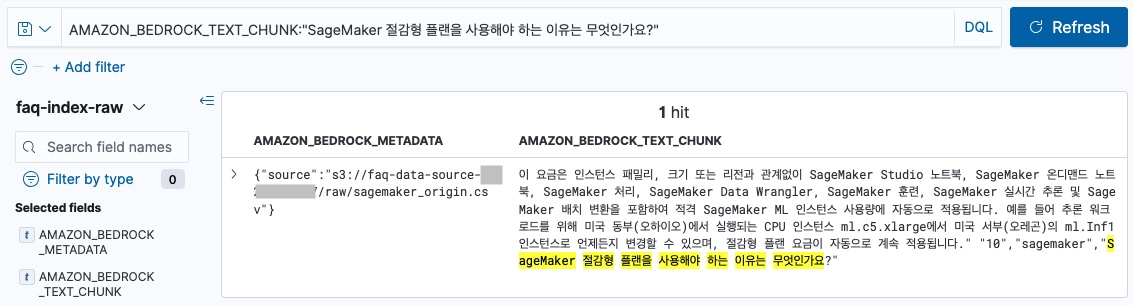
data source와 sync한 파일의 10번 질문인 “SageMaker 절감형 플랜을 사용해야 하는 이유는 무엇인가요?” 을 default chunk를 적용한 faq-index-raw 에서 검색하면 아래와 같습니다.
AMAZON_BEDROCK_TEXT_CHUNK:"SageMaker 절감형 플랜을 사용해야 하는 이유는 무엇인가요?"
faq-index-raw 검색
이 요금은 인스턴스 패밀리, 크기 또는 리전과 관계없이 SageMaker Studio 노트북, SageMaker 온디맨드 노트북, SageMaker 처리, SageMaker Data Wrangler, SageMaker 훈련, SageMaker 실시간 추론 및 SageMaker 배치 변환을 포함하여 적격 SageMaker ML 인스턴스 사용량에 자동으로 적용됩니다. 예를 들어 추론 워크로드를 위해 미국 동부(오하이오)에서 실행되는 CPU 인스턴스 ml.c5.xlarge에서 미국 서부(오레곤)의 ml.Inf1 인스턴스로 언제든지 변경할 수 있으며, 절감형 플랜 요금이 자동으로 계속 적용됩니다.” “10”,”sagemaker”,”SageMaker 절감형 플랜을 사용해야 하는 이유는 무엇인가요?”
10번 Q&A 문장의 문의와 답변의 내용이 짤려 있습니다. 고정된 사이즈 (300 tokens)로 문서를 chunk 하기 때문에, 문맥과 상관없이 문서를 나누게 됩니다. default chunk를 사용한 index의 chunk에는 질문과 답변 일부만 포함되어 있습니다. 따라서, 10번 Q&A의 경우 질문과 답변이 다른 chunk에 존재하기 때문에, Knowledge Base에서 질문관련 검색시 해당 답변이 포함된 일부만 가져올수 있습니다. 이러한 동작은 Amazon Bedrock Knowledge Base 사용시 질의에 대한 답변을 일부만 검색하여 답변을 생성하기 때문에, 답변의 정확도가 떨어질 수 있습니다.
하지만, No chunk 전략과 metadata의 documentStructureConfiguration 를 적용한 faq-index-processed에는 csv의 1개의 row가 1개의 chunk로 분리되기 때문에, 아래와 같이 질의와 답변이 온전히 1개의 문서에 포함 됩니다.
faq-index-processed 검색
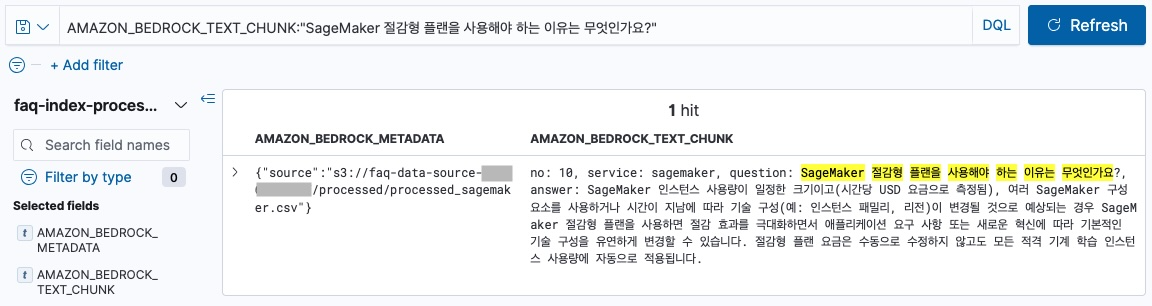
no: 10, service: sagemaker, question: SageMaker 절감형 플랜을 사용해야 하는 이유는 무엇인가요?, answer: SageMaker 인스턴스 사용량이 일정한 크기이고(시간당 USD 요금으로 측정됨), 여러 SageMaker 구성 요소를 사용하거나 시간이 지남에 따라 기술 구성(예: 인스턴스 패밀리, 리전)이 변경될 것으로 예상되는 경우 SageMaker 절감형 플랜을 사용하면 절감 효과를 극대화하면서 애플리케이션 요구 사항 또는 새로운 혁신에 따라 기본적인 기술 구성을 유연하게 변경할 수 있습니다. 절감형 플랜 요금은 수동으로 수정하지 않고도 모든 적격 기계 학습 인스턴스 사용량에 자동으로 적용됩니다.
OpenSearch Dashboard의 Discover 기능을 이용하여 chunking 전략에 따라 index에 저장되는 문서를 직접 확인 할 수 있었습니다. index의 문서를 직접 확인 하는 방법은 Data Source의 Sync가 정상적으로 진행되고 있는지, 변경한 파일이 정상적으로 업데이트 되었는지 확인 하는데 유용합니다. 또한, 문서의 포맷에 따라 적절한 chunking 전략을 테스트하며, Knowledge Base 응답의 정확도를 높일 수 있습니다.
리소스 정리하기
실습 환경을 구축하신 경우, 다음과 같은 순서로 삭제하시기를 권장드립니다.
- 지식 기반 삭제
- S3 버킷 삭제
- OpenSearch Serverless Collection 삭제
- 보안 정책 & IAM Role 삭제
만약 OpenSearch Collection을 먼저 삭제하면 Knowledge Base 삭제가 실패할 수 있습니다. 삭제 실패 시 해결방법은 아래와 같습니다.
- 각 데이터 소스의 deletion policy를
DELETE로 변경
- 지식 기반 삭제 재시도
결론
Amazon Bedrock Knowledge Bases를 활용한 RAG 시스템 구축에서 데이터 특성에 맞는 청킹 전략 선택이 검색 성능에 미치는 영향을 실습을 통해 확인했습니다.
핵심 발견사항
기존 청킹 방식의 한계
- 고정 청킹(default: 300 토큰 단위)으로 인해 FAQ와 같은 구조화된 데이터에서 질문-답변 쌍이 분리되어 맥락 손실 발생
- 서로 다른 질의응답이 하나의 청크로 합쳐지거나, 하나의 완전한 답변이 여러 청크로 분산되는 문제
- 불완전한 정보 검색으로 인한 응답 품질 저하
metadata.json + No Chunking 전략의 효과
- CSV 파일의 각 행을 온전한 하나의 청크로 유지하여 질의응답 단위의 완전성 보장
documentStructureConfiguration을 통한 구조화된 메타데이터 활용으로 검색 정확도 향상- 관련 정보의 통합적 제공으로 더 구체적이고 실용적인 응답 생성
실무 적용 가이드
데이터 특성별 청킹 전략
- FAQ, 팁, 가이드라인: No Chunking + metadata.json으로 논리적 단위 보존
- 긴 문서, 매뉴얼: 기존 청킹 방식으로 적절한 크기 분할
- 구조화된 데이터: CSV + contentFields 지정으로 메타데이터 활용
성능 최적화 방법
- OpenSearch Dashboard를 통한 실제 저장 데이터 구조 검증
- 청킹 전략별 검색 결과 비교 분석
- 메타데이터 필드 활용으로 검색 맥락 풍부화
기대 효과
이러한 데이터 특성 기반 청킹 전략을 통해 다음과 같은 개선을 달성할 수 있습니다.
- 검색 정확도 향상: 완전한 정보 단위 보존으로 관련성 높은 결과 제공
- 토큰 효율성: 중복 처리 최소화로 비용 최적화
- 디버깅 용이성: OpenSearch Dashboard를 통한 투명한 데이터 검증
- 사용자 경험 개선: 구체적이고 실용적인 답변 생성
Amazon Bedrock Knowledge Bases의 다양한 청킹 옵션과 메타데이터 구성 기능을 적절히 활용하면, 데이터 특성에 최적화된 RAG 시스템을 구축하여 생성형 AI 애플리케이션의 성능을 크게 향상시킬 수 있습니다.