Amazon Web Services 한국 블로그
Amazon S3 Vectors 소개: 대규모 벡터를 지원하는 최초 클라우드 스토리지 (미리 보기)
오늘 AWS는 벡터 업로드, 저장 및 쿼리에 드는 총 비용을 최대 90% 절감할 수 있고 내구성이 뛰어난 목적별 벡터 스토리지 솔루션인 Amazon S3 Vectors의 평가판을 발표합니다. Amazon S3 Vectors는 대규모 벡터 데이터세트를 저장하고 1초 미만의 쿼리 성능을 기본적으로 지원하는 최초의 클라우드 객체 저장소로, 기업이 합리적인 비용으로 AI 지원 데이터를 대규모로 저장하는 데 활용할 수 있습니다.
벡터 검색은 생성형 AI 애플리케이션에서 거리 또는 유사성 메트릭을 사용하여 벡터 표현을 비교해 주어진 데이터와 유사한 데이터 포인트를 찾는 새로운 기술입니다. 벡터는 임베딩 모델에서 생성된 비정형 데이터를 수치로 표현합니다. 문서 내 필드의 임베딩 모델을 사용하여 벡터를 생성하고, 벡터를 S3 Vectors에 저장하여 의미론적으로 검색합니다.
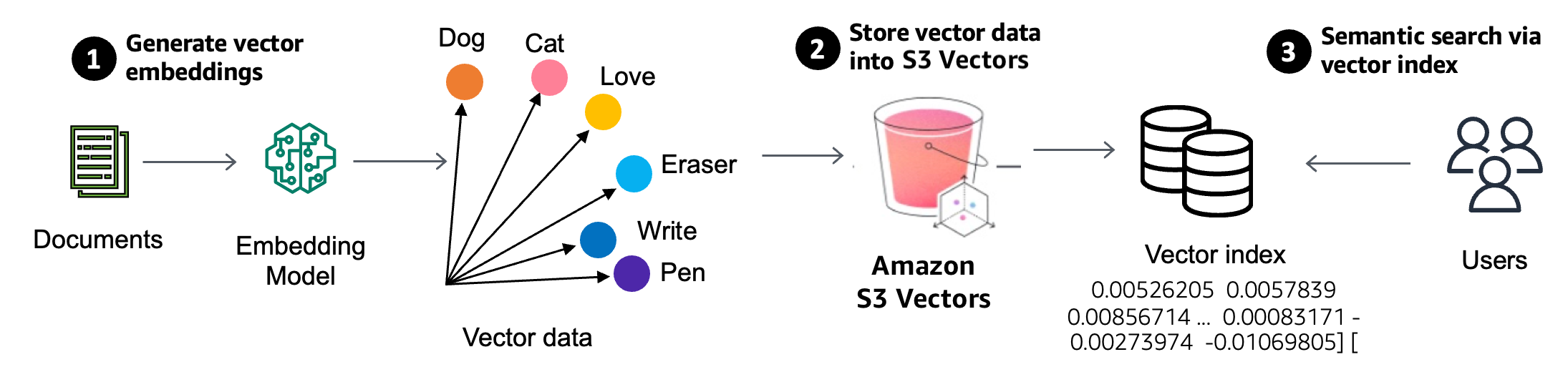
인프라를 프로비저닝하지 않고도 벡터 데이터를 저장, 액세스, 쿼리할 수 있도록 일련의 API를 지원하는 새로운 버킷 유형인 벡터 버킷이 S3 Vectors에 도입되었습니다. S3 벡터 버킷을 생성할 때, 벡터 인덱스 내에 벡터 데이터를 구성하게 되므로 데이터세트에 대해 유사성 검색 쿼리를 간단하게 실행할 수 있습니다. 각 벡터 버킷은 최대 1만 개의 벡터 인덱스로 구성할 수 있으며, 벡터 인덱스마다 수천만 개의 벡터를 저장할 수 있습니다.
벡터 인덱스를 생성한 후 인덱스에 벡터 데이터를 추가할 때, 메타데이터를 각 벡터에 키-값 쌍으로 첨부하여 날짜, 카테고리, 사용자 기본 설정 등의 조건 세트에 따라 향후 쿼리를 필터링할 수도 있습니다. 시간이 지나면서 사용자가 벡터를 작성, 업데이트, 삭제하면 S3 Vectors는 벡터 데이터를 자동으로 최적화하여 데이터세트가 규모 조정되고 변경되더라도 벡터 스토리지에서 가능한 최고의 가격 대비 성능을 제공합니다.
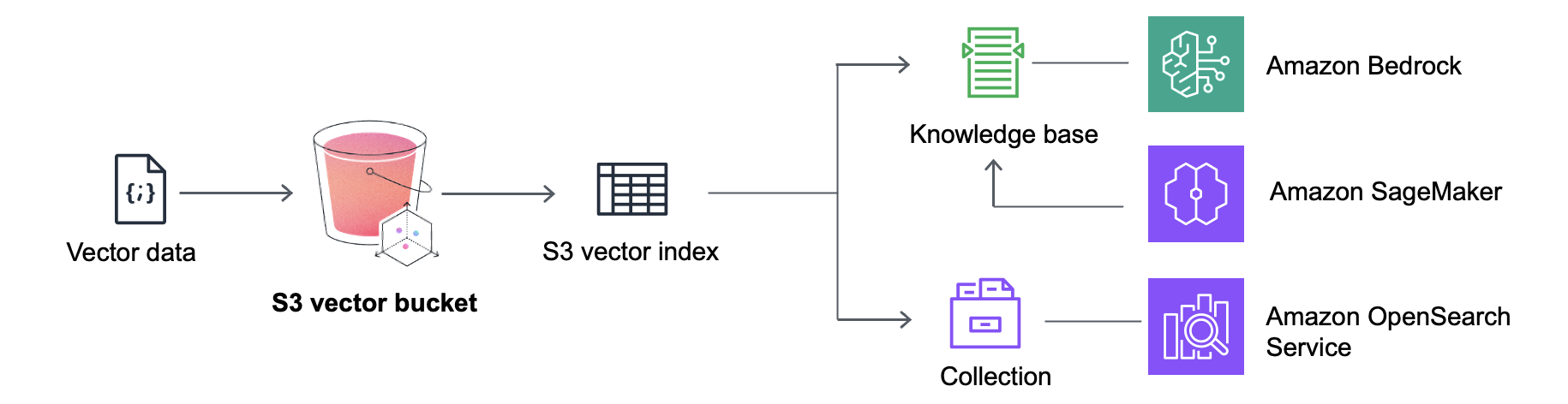
또한 S3 Vectors는 Amazon SageMaker Unified Studio 내의 지식 기반을 비롯한 Amazon Bedrock Knowledge Bases와 기본적으로 통합되므로, 비용 효율적인 검색 증강 생성(RAG) 애플리케이션을 구축할 수 있습니다. Amazon OpenSearch Service 통합을 통해, 자주 쿼리되지 않는 벡터를 S3 Vectors에 보관하고 수요가 늘어나면 해당 벡터를 OpenSearch로 신속하게 이동하거나 지연 시간이 짧은 실시간 검색 작업을 지원함으로써 스토리지 비용을 절감할 수 있습니다.
이제 S3 Vectors를 사용하여 이미지, 비디오, 문서, 오디오 파일 등의 비정형 데이터를 나타내는 벡터 임베딩을 경제적으로 저장할 수 있으므로, 의미론적 검색과 유사성 검색, RAG, 빌드 에이전트 메모리 등 확장 가능한 생성형 AI 애플리케이션을 구현할 수 있게 되었습니다. 또한 벡터 데이터베이스를 관리하는 데 따른 복잡성과 비용 없이, 개인화된 추천, 자동화된 콘텐츠 분석, 지능형 문서 처리 등의 다양한 산업별 사용 사례를 지원하는 애플리케이션을 구축할 수 있습니다.
S3 Vectors 사용 방식
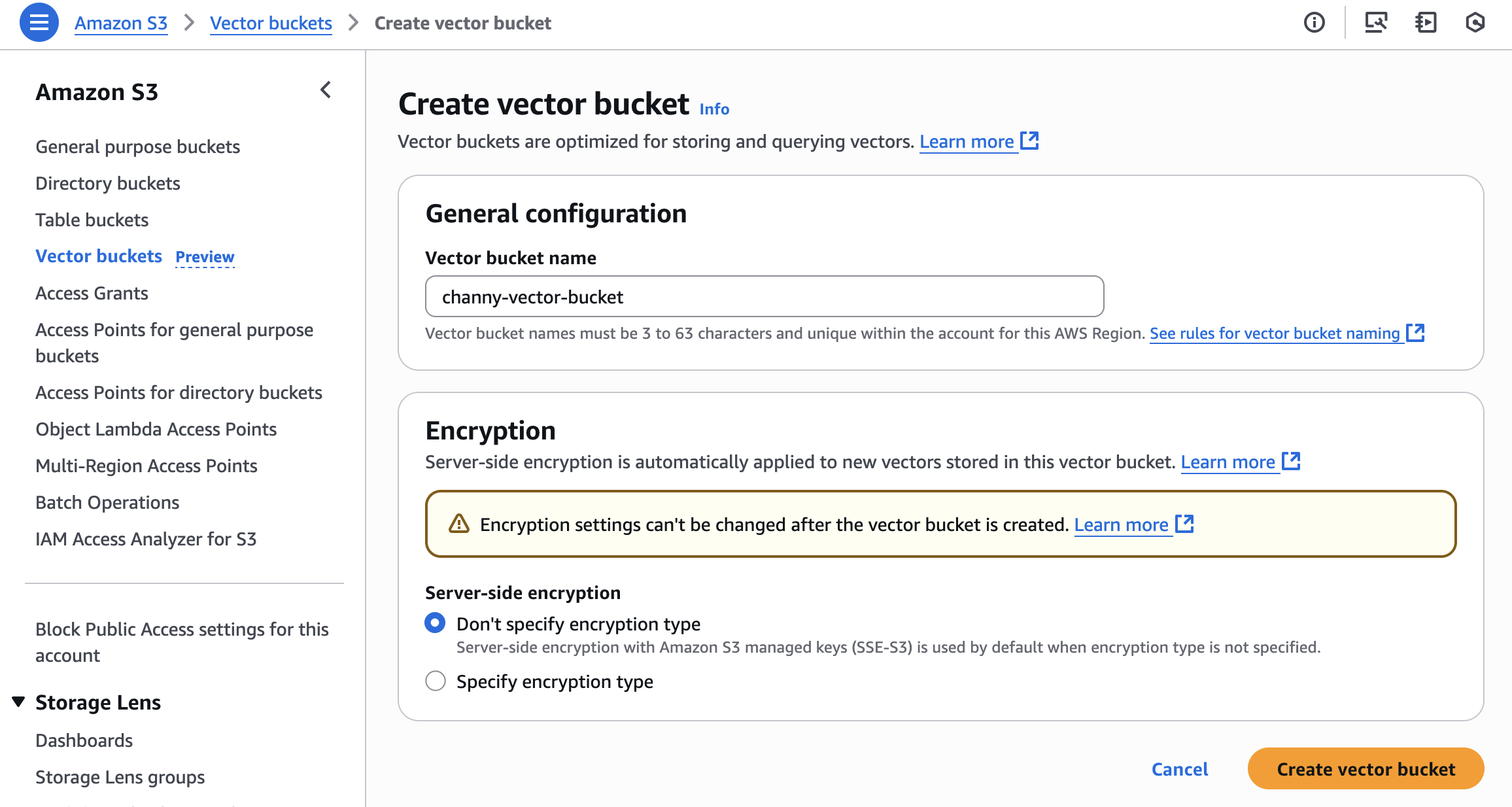
벡터 버킷을 생성하려면 Amazon S3 콘솔의 왼쪽 탐색 창에서 벡터 버킷을 선택한 다음 벡터 버킷 생성을 선택합니다.
벡터 버킷 이름을 입력하고 암호화 유형을 선택합니다. 암호화 유형을 지정하지 않으면 Amazon S3가 Amazon S3 관리형 키(SSE-S3)를 사용한 서버 측 암호화를 새 벡터의 기본 암호화 수준으로 적용합니다. AWS Key Management Service(AWS KMS) 키(SSE-KMS)를 사용한 서버 측 암호화를 선택할 수도 있습니다. 벡터 버킷 관리에 대해 자세히 알아보려면 Amazon S3 사용 설명서에서 S3 벡터 버킷을 참조하세요
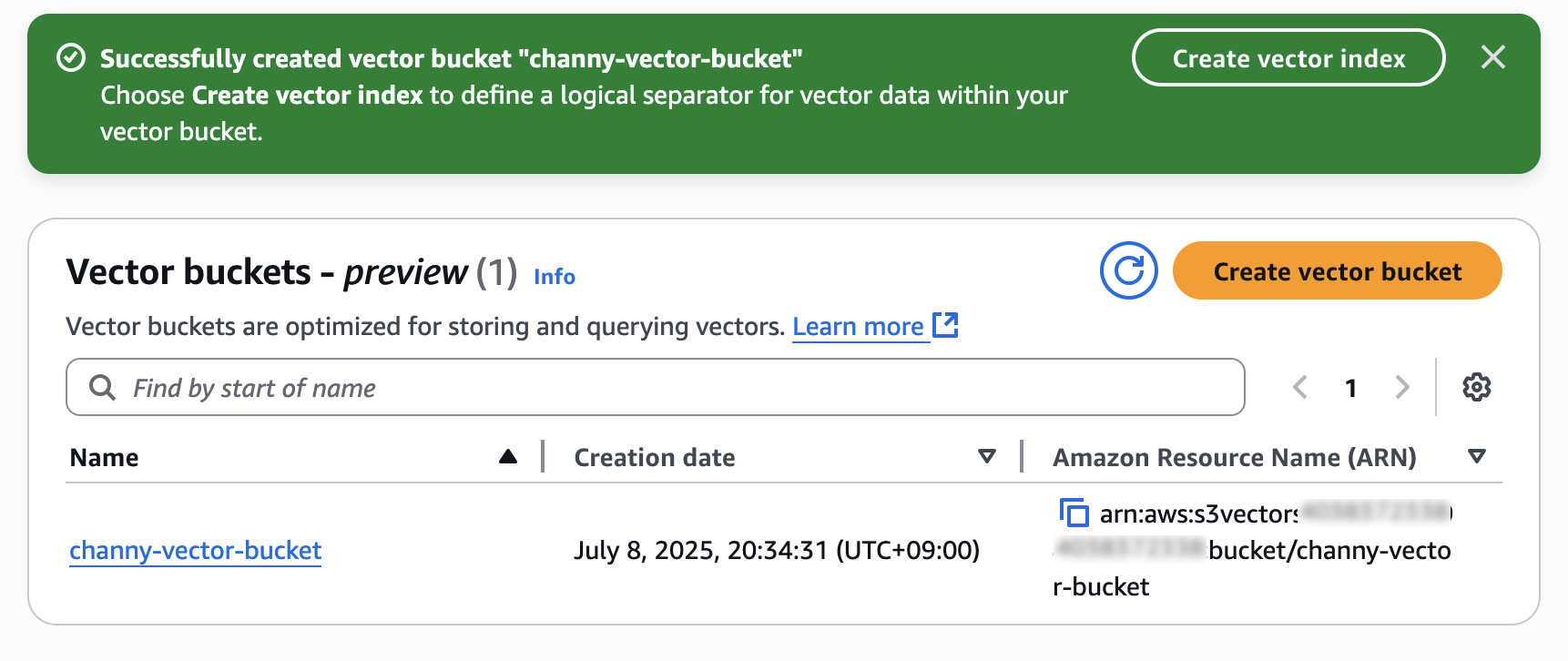
이제 벡터 인덱스를 생성하여 생성된 벡터 버킷 내에 벡터 데이터를 저장하고 쿼리할 수 있습니다.
벡터 인덱스 이름과 인덱스에 삽입할 벡터의 차원을 입력합니다. 이 인덱스에 추가된 모든 벡터의 값 개수가 정확히 일치해야 합니다.
거리 지표의 경우 코사인 또는 유클리드 중 하나를 선택할 수 있습니다. 벡터 임베딩을 생성할 때, 임베딩 모델의 권장 거리 지표를 선택하면 보다 정확한 결과를 얻을 수 있습니다.
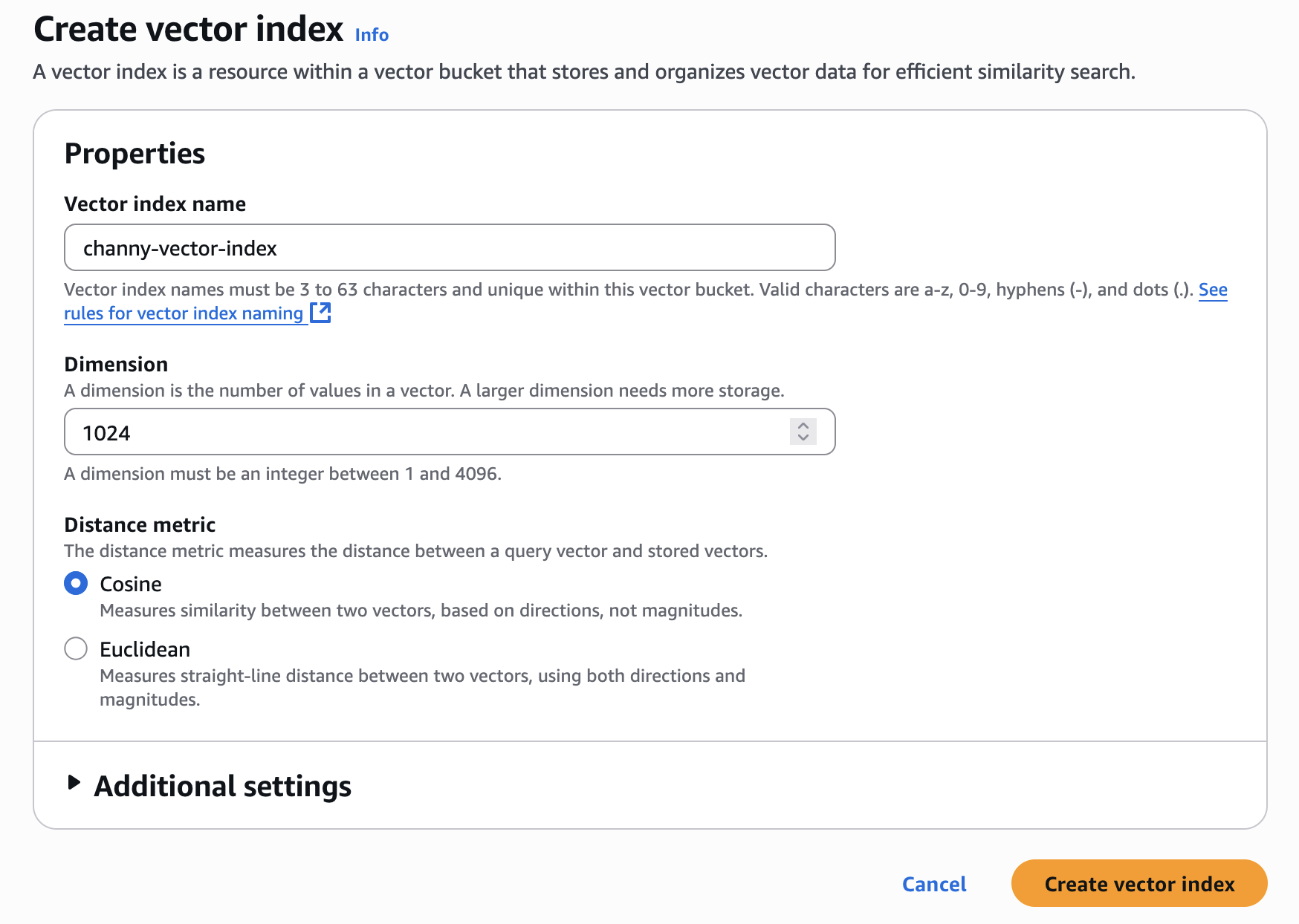
벡터 인덱스 생성을 선택하면 벡터를 삽입, 나열, 쿼리할 수 있습니다.
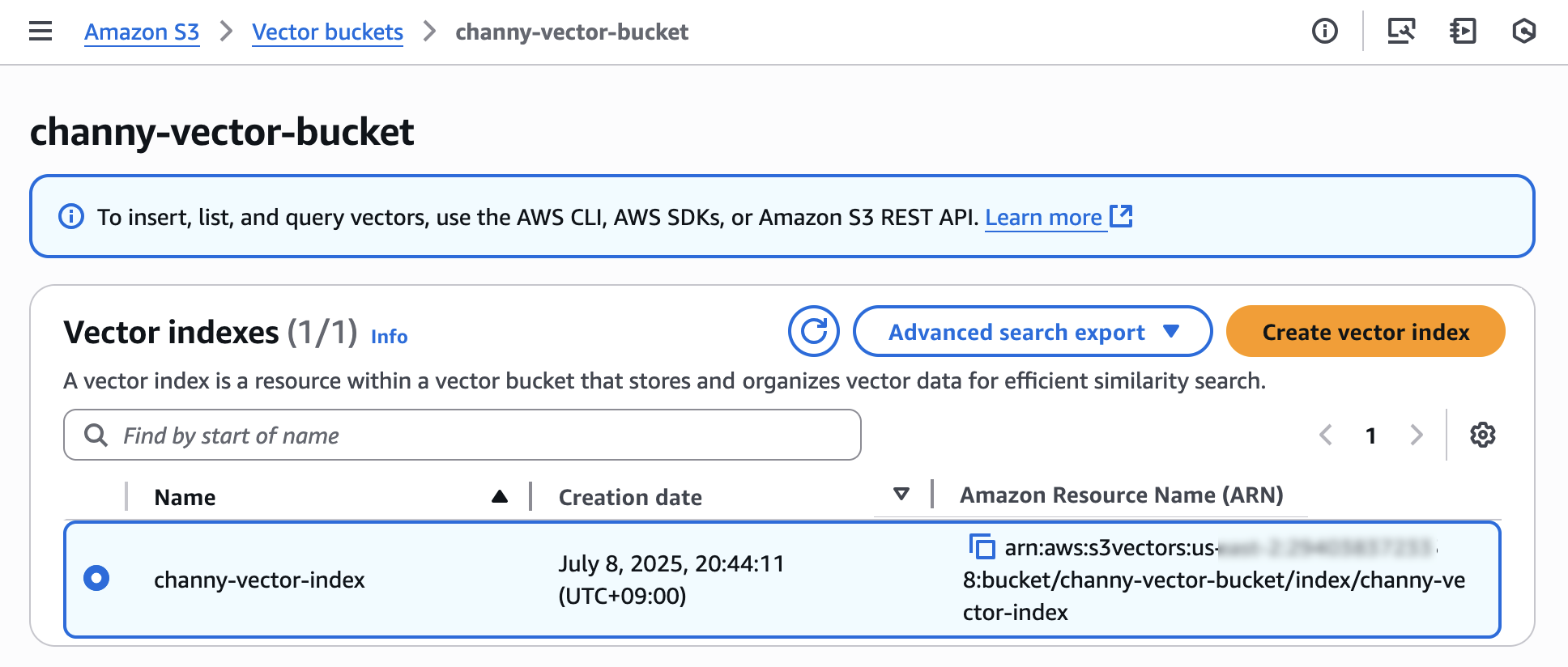
벡터 임베딩을 벡터 인덱스에 삽입할 때는 AAWS Command Line Interface(AWS CLI), AWS SDK 또는 Amazon S3 REST API를 사용할 수 있습니다. 비정형 데이터의 벡터 임베딩을 생성할 때는 Amazon Bedrock에서 제공하는 임베딩 모델을 사용할 수 있습니다.
최신 AWS Python SDK를 사용하는 경우, Amazon Bedrock에 다음 코드 예시를 사용하여 텍스트의 벡터 임베딩을 생성할 수 있습니다.
# Amazon Titan Text Embeddings V2를 사용하여 임베딩을 생성하고 인쇄합니다.
import boto3
import json
# 원하는 AWS 리전에서 Bedrock 런타임 클라이언트를 생성합니다.
bedrock= boto3.client("bedrock-runtime", region_name="us-west-2")
임베딩으로 변환할 텍스트 문자열입니다.
texts = [
"Star Wars: A farm boy joins rebels to fight an evil empire in space",
"Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong",
"Finding Nemo: A father fish searches the ocean to find his lost son"]
embeddings=[]
# 입력 텍스트의 벡터 임베딩을 생성합니다.
for text in texts:
body = json.dumps({
"inputText": text
})
# Bedrock의 임베딩 API를 직접적으로 호출합니다.
response = bedrock.invoke_model(
modelId='amazon.titan-embed-text-v2:0', # Titan embedding model
body=body)
# 응답을 구문 분석합니다.
response_body = json.loads(response['body'].read())
embedding = response_body['embedding']
embeddings.append(embedding)이제 쿼리 임베딩을 사용하여 벡터 인덱스에 벡터 임베딩을 삽입하고 벡터 인덱스에서 벡터를 쿼리할 수 있습니다.
# S3Vector 클라이언트 생성
s3vectors_client = boto3.client('s3vectors', region_name='us-west-2')
# 벡터 임베딩을 삽입합니다.
s3vectors.put_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
vectors=[
{"key": "v1", "data": {"float32": embeddings[0]}, "metadata": {"id": "key1", "source_text": texts[0], "genre":"scifi"}},
{"key": "v2", "data": {"float32": embeddings[1]}, "metadata": {"id": "key2", "source_text": texts[1], "genre":"scifi"}},
{"key": "v3", "data": {"float32": embeddings[2]}, "metadata": {"id": "key3", "source_text": texts[2], "genre":"family"}}
],
)
# 쿼리 입력 텍스트의 임베딩을 생성합니다.
# 임베딩으로 변환할 텍스트입니다.
input_text = "List the movies about adventures in space"
# 모델에 대한 JSON 요청을 생성합니다.
request = json.dumps({"inputText": input_text})
# 요청과 모델 ID(예: Titan Text Embeddings V2)를 사용하여 모델을 간접적으로 호출합니다.
response = bedrock.invoke_model(modelId="amazon.titan-embed-text-v2:0", body=request)
# 모델의 네이티브 응답 본문을 디코딩합니다.
model_response = json.loads(response["body"].read())
# 생성된 임베딩과 입력된 텍스트 토큰 수를 추출하고 출력합니다.
embedding = model_response["embedding"]
# 유사성 쿼리를 수행합니다. 선택적으로 쿼리에 필터를 사용할 수도 있습니다.
query = s3vectors.query_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
queryVector={"float32":embedding},
topK=3,
filter={"genre":"scifi"},
returnDistance=True,
returnMetadata=True
)
results = query["vectors"]
print(results)
벡터 인덱스에 벡터를 삽입하거나 벡터를 나열, 쿼리, 삭제하는 방법에 대해 자세히 알아보려면 Amazon S3 사용 설명서에서 S3 벡터 버킷 및 S3 벡터 인덱스를 참조하세요. 또한 S3 Vectors에 내장된 명령줄 인터페이스(CLI)를 사용하면 Amazon Bedrock을 사용하여 데이터의 벡터 임베딩을 생성하고 단일 명령으로 S3 벡터 인덱스에 저장 및 쿼리할 수 있습니다. 자세한 내용은 S3 Vectors 내장 CLI GitHub 리포지토리를 참조하세요.
S3 Vectors를 다른 AWS 서비스와 통합
S3 Vectors는 Amazon Bedrock, Amazon SageMaker, Amazon OpenSearch Service 등의 다른 AWS 서비스와 통합되어 벡터 처리 기능을 강화하고 AI 워크로드를 위한 포괄적인 솔루션을 제공합니다.
S3 Vectors로 Amazon Bedrock Knowledge Bases 생성
Amazon Bedrock Knowledge Bases에서 S3 Vectors를 사용하면 RAG 애플리케이션의 벡터 스토리지를 간소화하고 비용을 절감할 수 있습니다. Amazon Bedrock 콘솔에서 지식 기반을 생성할 때 벡터 저장소 옵션으로 S3 벡터 버킷을 선택할 수 있습니다.
3단계에서 벡터 저장소 생성 방법을 선택하여 S3 벡터 버킷과 벡터 인덱스를 생성하거나 이전에 생성한 기존 S3 벡터 버킷과 벡터 인덱스를 선택할 수 있습니다.
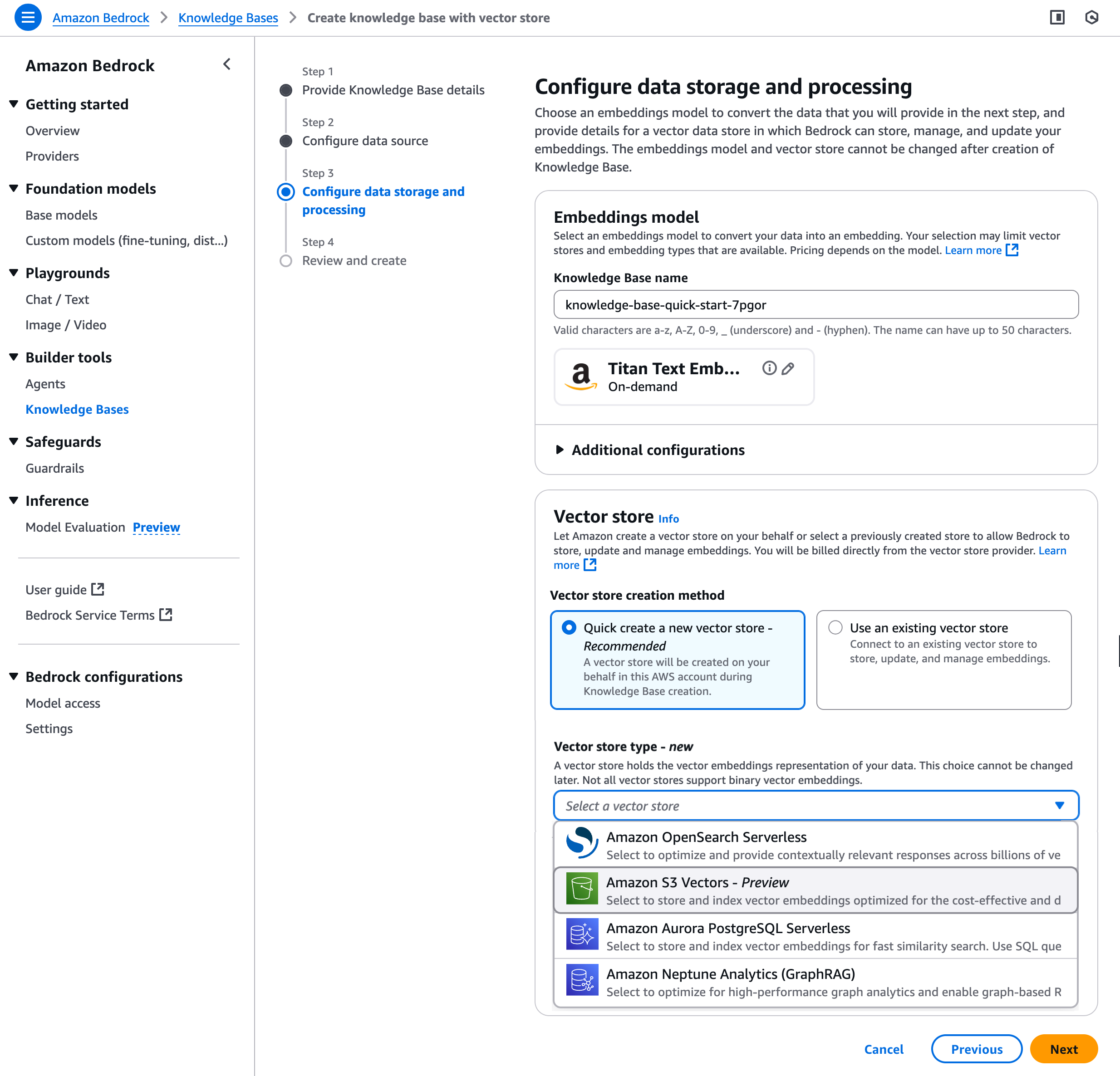
자세한 단계별 지침은 Amazon Bedrock 사용 설명서에서 Amazon Bedrock Knowledge Bases의 데이터 소스에 연결하여 지식 기반 생성을 참조하세요.
Amazon SageMaker Unified Studio 사용
Amazon Bedrock을 통해 생성형 AI 애플리케이션을 구축할 때 Amazon SageMaker Unified Studio에서 S3 Vectors를 사용하여 지식 기반을 생성하고 관리할 수 있습니다. SageMaker Unified Studio는 차세대 Amazon SageMaker에서 사용할 수 있으며, Amazon Bedrock Knowledge Bases를 사용하는 생성형 AI 애플리케이션을 구축하고 테스트하는 등 데이터와 AI를 지원하는 통합 개발 환경을 제공합니다.
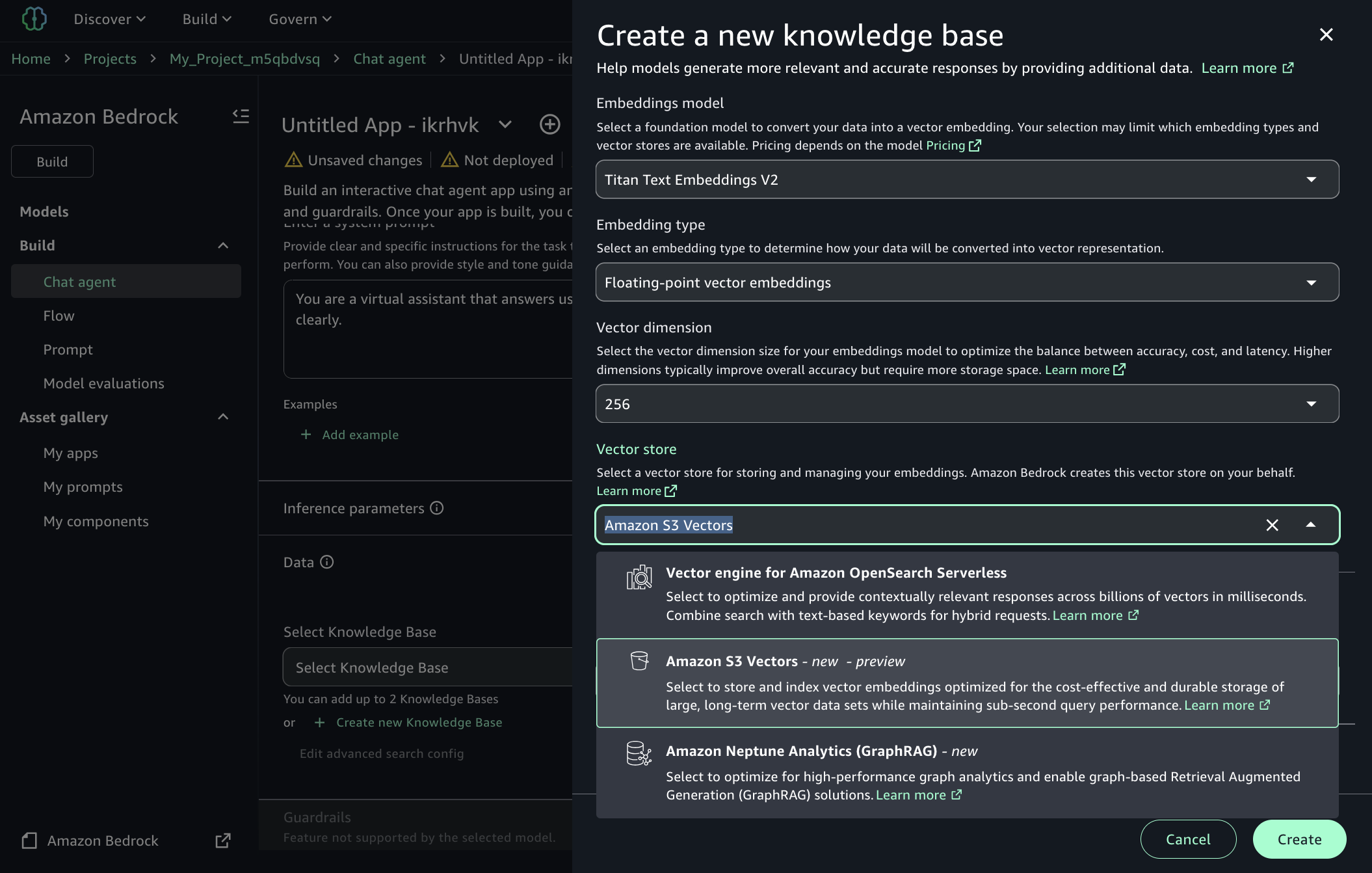
SageMaker Unified Studio에서 새 지식 기반을 생성할 때 Amazon S3 Vectors를 벡터 저장소로 선택할 수 있습니다. 자세한 내용은 Amazon SageMaker Unified Studio 사용 설명서에서 채팅 에이전트 앱에 Amazon Bedrock 지식 베이스 구성 요소 추가를 참조하세요.
S3 벡터 데이터를 Amazon OpenSearch Service로 내보내기
장기간에 걸친 벡터 데이터를 Amazon S3에 비용 효율적으로 저장하고 실시간 쿼리 성능을 높이기 위해 우선순위가 높은 벡터를 OpenSearch로 내보내는 계층형 전략을 적용하여 비용과 성능의 균형을 이룰 수 있습니다.
이 같은 유연성은 조직이 제품 추천이나 사기 탐지와 같은 중요한 실시간 애플리케이션에 OpenSearch의 높은 성능(높은 QPS, 짧은 지연 시간)을 이용하면서 시간에 덜 민감한 데이터를 S3 Vectors에 보관할 수 있도록 해줍니다.
벡터 인덱스를 내보내려면 고급 검색 내보내기를 선택한 다음 Amazon S3 콘솔에서 OpenSearch로 내보내기를 선택합니다.
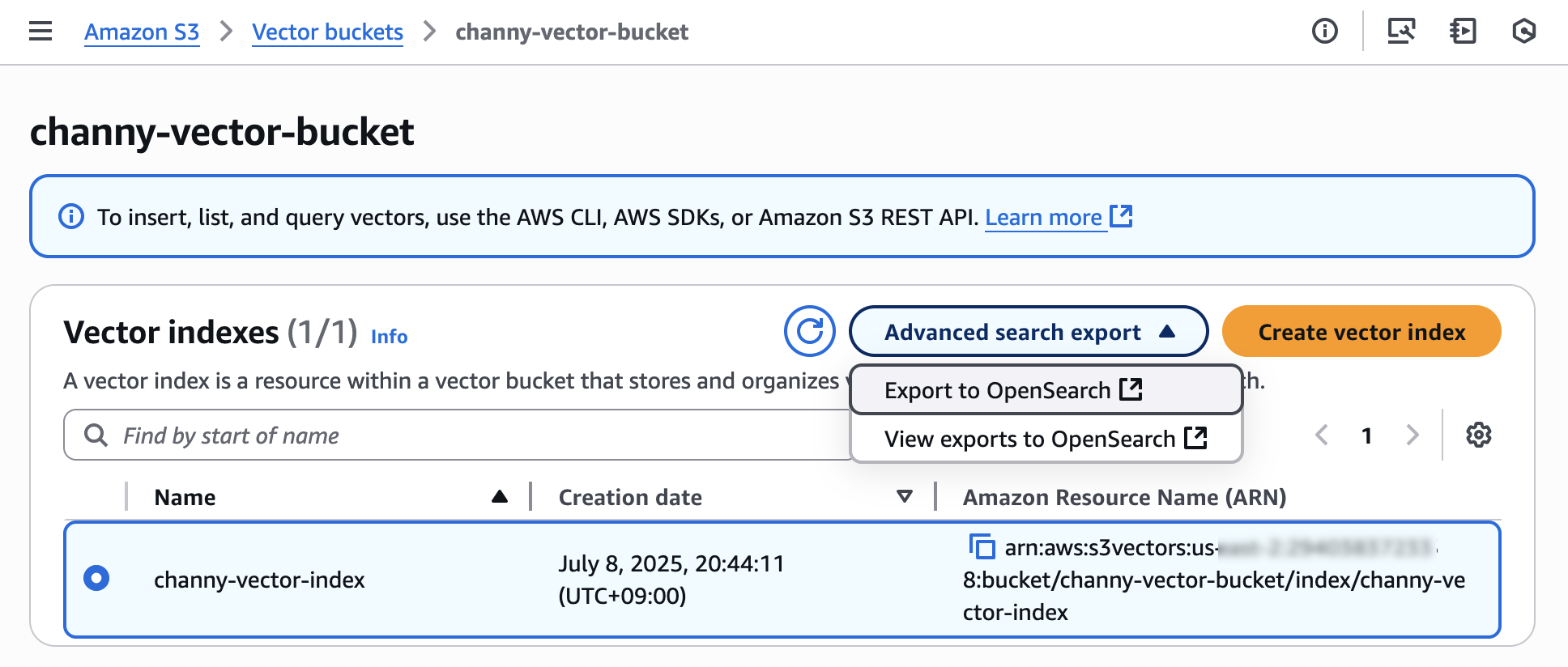
그러면 S3 벡터 인덱스를 OpenSearch 벡터 엔진으로 내보내기 위한 템플릿이 있는 Amazon OpenSearch Service 통합 콘솔로 이동하게 됩니다. 사전 선택된 S3 벡터 소스와 서비스 액세스 역할을 그대로 두고 내보내기를 선택합니다.
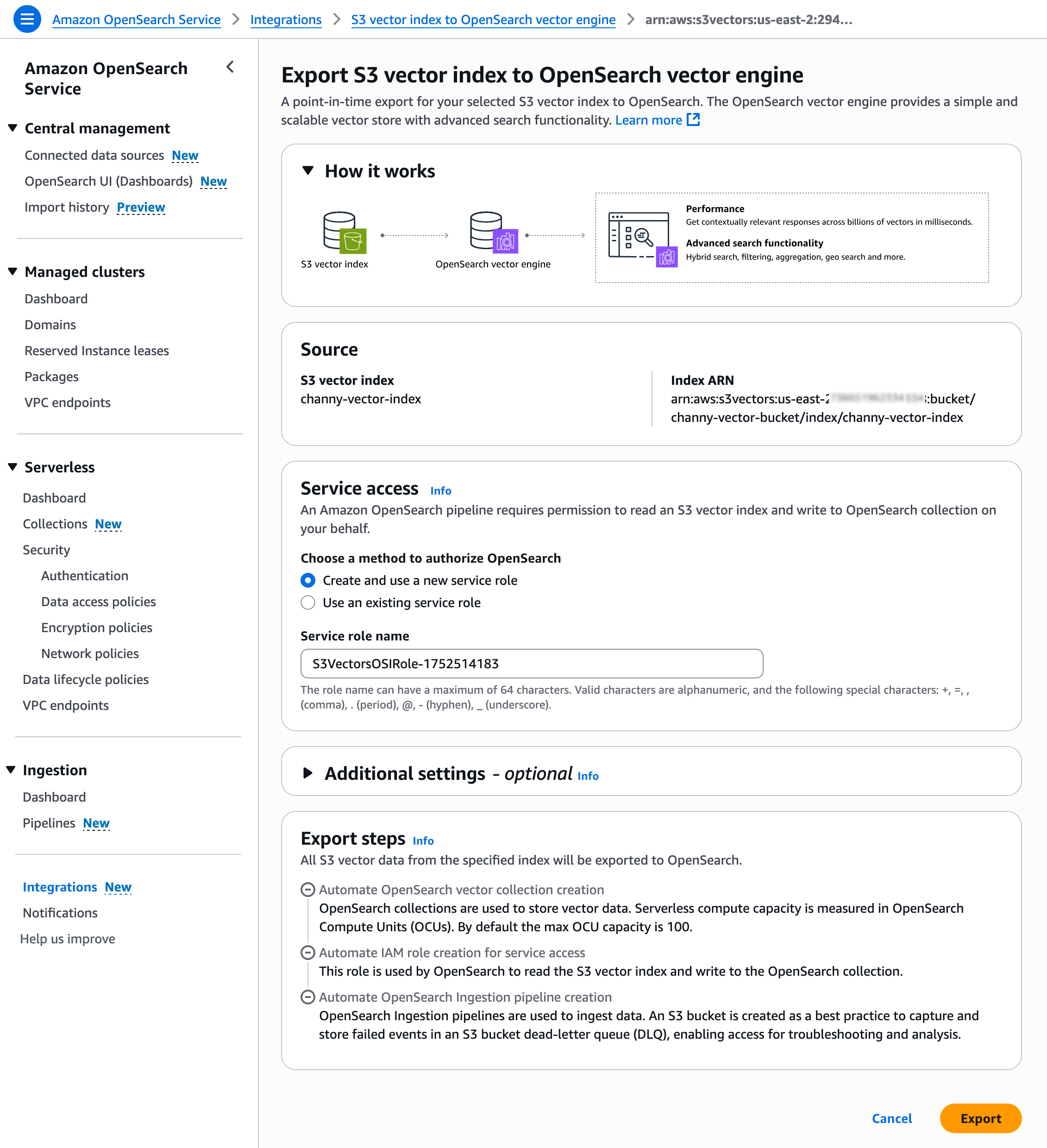
그러면 새 OpenSearch Serverless 컬렉션을 생성하고 S3 벡터 인덱스의 데이터를 OpenSearch knn 인덱스로 마이그레이션하는 단계가 시작됩니다.
왼쪽 탐색 창에서 가져오기 기록을 선택합니다. 여기서 S3 벡터 인덱스의 벡터 데이터를 OpenSearch Serverless 컬렉션으로 복사하기 위해 생성된 새 가져오기 작업을 볼 수 있습니다.
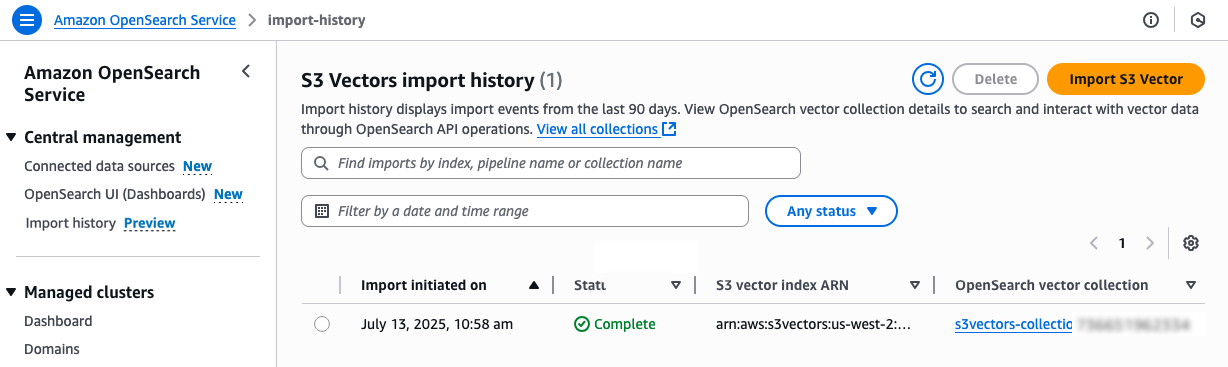
상태가 완료로 바뀌면 새 OpenSearch Serverless 컬렉션에 연결하여 새 OpenSearch knn 인덱스를 쿼리할 수 있습니다.
자세히 알아보려면 Amazon OpenSearch Service 개발자 가이드에서 Amazon OpenSearch Serverless 컬렉션 생성 및 관리를 참조하세요.
정식 출시
이제 Amazon S3 Vectors, 그리고 이 서비스와 Amazon Bedrock, Amazon OpenSearch Service, Amazon SageMaker의 통합 기능이 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(오리건), 유럽(프랑크푸르트), 아시아 태평양(시드니) 리전에서 평가판으로 제공됩니다.
지금 바로 Amazon S3 콘솔에서 S3 Vectors를 사용해 보고 AWS re:Post for Amazon S3 또는 평소 이용하는 AWS Support 연락처로 피드백을 보내주세요.
– Channy