AWS Startup ブログ
Amazon Neptune を活用したシンプルフォーム社のリスク評価サービス
はじめに
金融犯罪や不正取引の手法が日々複雑化・巧妙化する中、企業間の隠れた関係性を迅速に把握することが、リスク管理において極めて重要になっています。シンプルフォーム株式会社は、グラフデータベースを用いた、法人間の複雑なネットワークを可視化する革新的なソリューションを提供しています。本記事では、シンプルフォーム社がどのように Amazon Neptune を活用して、法人の審査業務を変革しているかを技術的側面から解説します。
シンプルフォーム社のリスク評価サービスの概要
シンプルフォーム株式会社は、全国 500 万法人の定性情報を収集・データベース化し、法人調査プロセス自動化プロダクト「SimpleCheck」を提供しています。従来、数日を要していた法人の最新情報収集を約 30 秒で完了させ、金融犯罪防止や業務効率化に貢献しています。このサービスは、2024 年 12 月にリリースされた「関連性表示機能」という機能によりさらに拡張されました。一見無関係に見える法人間の隠れたつながりを素早く可視化し、リスク評価の精度向上を実現しています。これにより、取引先だけでなく、関連事業者も含めたリスク・実体性の評価が可能となり、結託による詐欺や不正の防止に大きく貢献しています。
グラフデータベースとは
グラフデータベースは、データをノード(頂点)とエッジ(辺)の形で表現し、それらの関係性に焦点を当てたデータベースです。ノードはエンティティ(人、場所、物など)を表し、エッジはノード間の関係性を表します。また、ノードとエッジには属性やメタデータを付与することができ、より豊かな情報を表現できます。
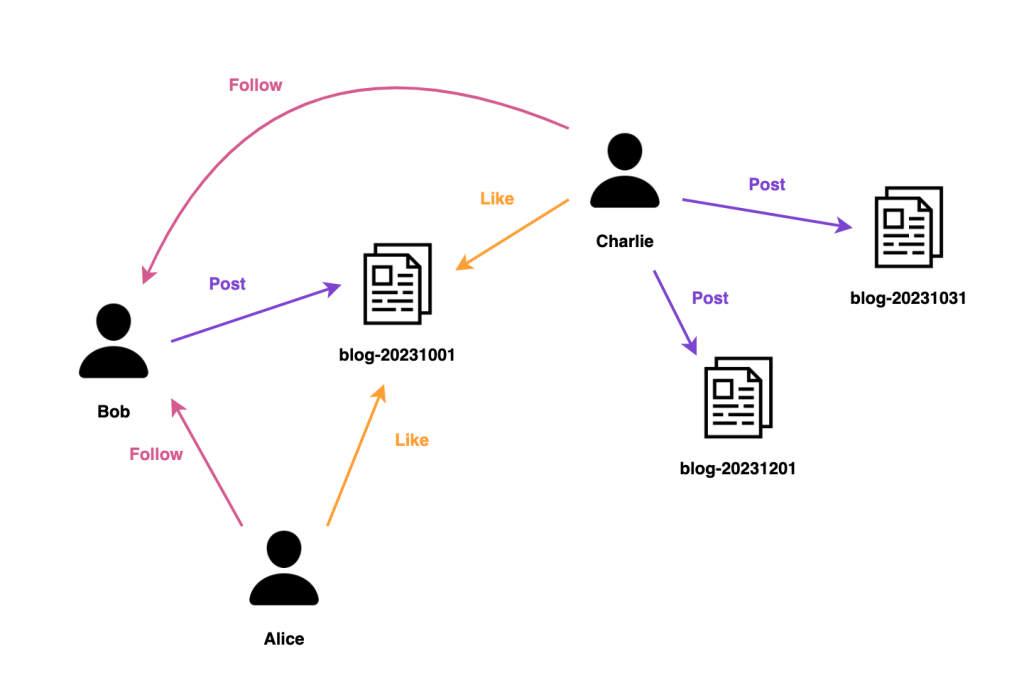
従来のリレーショナルデータベースでは、テーブル間の関係は結合 (JOIN) 操作によって実行時に確立されますが、グラフデータベースでは関係性そのものがデータモデルの中心となります。また、グラフデータベースを用いることで、SQL では表現できないような高度な処理もできます。これにより、グラフデータベースでは、複雑な関係性や大量の結合を持つデータを効率よく表現、探索することが可能になります。
リスク評価におけるグラフデータベースの優位性
リスク評価、特に法人間の関連性分析において、グラフデータベースが従来のデータベースと比較して優れている点は以下の通りです:
- 関係性の探索効率
- リレーショナルデータベースでは多段階の関係性を探索する場合、複数の JOIN 操作が必要となり、クエリが複雑化し、パフォーマンスが低下します
- グラフデータベースでは、関係性をたどる操作(探索、もしくはトラバーサル)が基本機能として最適化されており、何段階もの関係性を高速に探索できます
- パターン検出能力
- 不正取引や詐欺行為は、しばしば複雑なネットワークパターンとして現れますが、リレーショナルデータベースでは、このようなパターンを検出するには再帰的クエリや一時テーブルの作成が必要で、実装が複雑かつ非効率的です
- グラフデータベースは、不正を検知するための特徴的なパターンなど、特定のネットワークパターンを効率的に検出できます
- 動的なデータモデル
- 新たな関係性や属性が発見された場合、リレーショナルデータベースではスキーマ変更が必要になることがあります
- グラフデータベースは、リレーショナルデータベースのような固定的な列定義概念はなく、新しい種類の関係性や属性を容易に追加できます
- 直感的な表現と可視化
- 法人間の関係性は本質的にグラフ構造であるが、リレーショナルデータベースに格納するためには正規化されたテーブル構造、テーブル間の外部キー参照とした抽象的な表現にする必要があるため、実際のデータ間の関連性を直感的に理解することが難しくなります
- 関係性の可視化が容易で、分析者が複雑なネットワークを理解しやすくなります
リスク評価の文脈では、「この法人は誰と関係があるか?」「この代表者が関わる他の法人は?」「この住所に登記されている他の法人は?」といった問いに対して、グラフデータベースは最も効率的に回答を提供できます。また、「6 次の隔たり」のような多段階の関係性を探索する場合も、グラフデータベースは卓越したパフォーマンスを発揮します。
具体的な例として、「特定の組織を起点とし、代表関係や所在地関係を通じて最大2ステップ以内に到達できる住所ノードまでの経路を探索する」というクエリを考えてみましょう。リレーショナルデータベースでは、これを実現しようとすると、複雑な JOIN 操作が必要となり、処理負荷が高くなるだけでなく、実行結果が爆発的に増加する可能性があります。一方、グラフデータベースでは、このような多段階の関係性探索を直感的かつ効率的に表現できます。
Amazon Neptune とは
Amazon Neptune は、優れたスケーラビリティと可用性を実現する高性能なサーバーレスのグラフデータベースです。Amazon Neptune の中核は、目的に特化して構築された高性能グラフデータベースエンジンであり、数十億の関係性を格納し、ミリ秒単位のレイテンシでグラフをクエリするために最適化されています。
Amazon Neptune は、代表的なプロパティグラフクエリ言語である openCypher、Apache TinkerPop Gremlin そして W3C の RDF クエリ言語である SPARQL をサポートしています。これにより、簡単に強力なクエリを表現することが可能になります。3 つのアベイラビリティゾーン (AZ) にまたがってデータを保存し、継続的バックアップ、ポイントインタイムリカバリを提供していることで高い信頼性も実現されています。
シンプルフォームの「関連性表示機能」
SimpleCheck に統合されている「関連性表示機能」は、代表者名や役員名、住所などの情報をもとに、同一人物が代表・役員を務める別法人の有無や、同じ住所に登記された他法人の有無など、他の事業者との共通点・関連性を自動的に判定・解析します。判定の根拠と共に、事業者間の最新のネットワークを表示します。
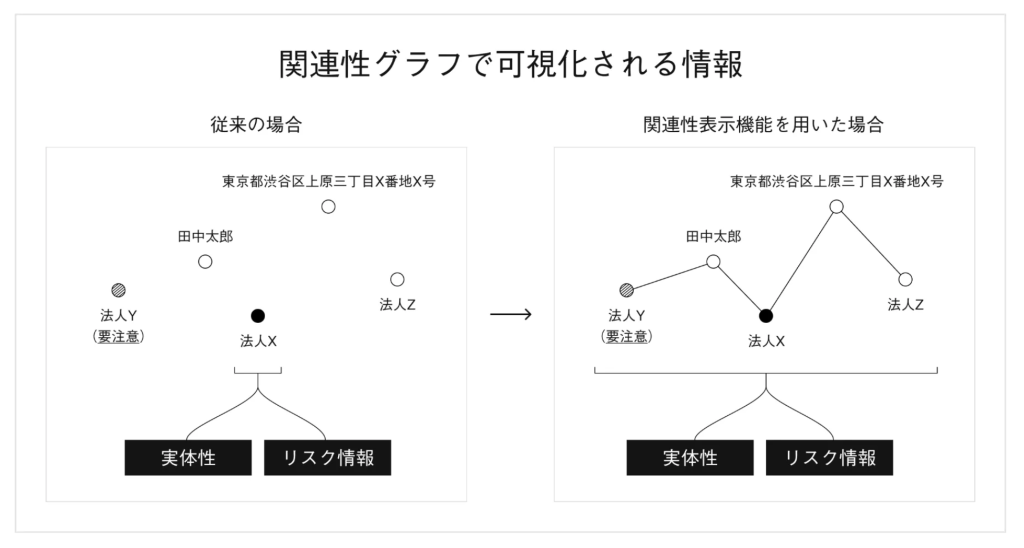
この機能は、迅速に大量の審査が必要な BPSP*(Business Payment Solution Provider)などのシーンを想定しており、取引先同士の結託リスクの有無など、密接な関連性を確認できるアドオン機能も備えています。
*…クレジットカード加盟店ではない売り手企業(サプライヤー)に対しても買い手企業(バイヤー)がカード決済を可能とする仕組みです。Visa、JCB、Mastercard など各ブランドが異なる名称で同様のフレームを提供していますが、この本文中ではVisaが提唱する名称の「BPSP」を用いています。
Amazon Neptune Database を用いたグラフデータベース解析を構築したことにより、SimpleCheck における既存のレポート生成と同時に、同一画面内に約 30 秒でネットワークを出力することが可能となり、法人・人物間の結びつきの根拠や強度を分析・整理し、一定の関連性が認められた事業者のみの表示を可能にすることで、エンドユーザに提供できる価値を大きく拡大することができました。
シンプルフォーム社が Amazon Neptune Database を選択した理由としては、AWS のマネージドサービスとしての利点が大きく影響しています。導入ハードルの低さ、キャッチアップコストの削減、技術サポートの充実などが主な決め手となりました。また、プロパティグラフに対して openCypher と Apache TinkerPop Gremlin の両方のクエリ言語をサポートしている点も、選定の重要な要素でした。商用環境での安定稼働に十分耐えうる仕様であることも確認され、最終的に Amazon Neptune Database の採用が決定されました。
関連性表示機能のシステムアーキテクチャ
SimpleCheck 関連性表示機能については、シンプルフォーム社の駒井氏および杉氏に伺いました。SimpleCheck は Amazon Elastic Container Service(Amazon ECS) 上に稼働する Web アプリケーションとして実装されています。ユーザーのアクションからレポート生成プロセスが開始され、各所から収集したデータを元にレポートを生成して Web アプリケーションに描画します。
データ収集時の検索対象としては、Web 情報や通常のリレーショナルデータベースに加えて、Amazon Neptune Database で構築した法人ナレッジグラフも含まれています。法人ナレッジグラフに対する CRUD 操作は、API としてラップされ、Amazon ECS サービスとして稼働しています。
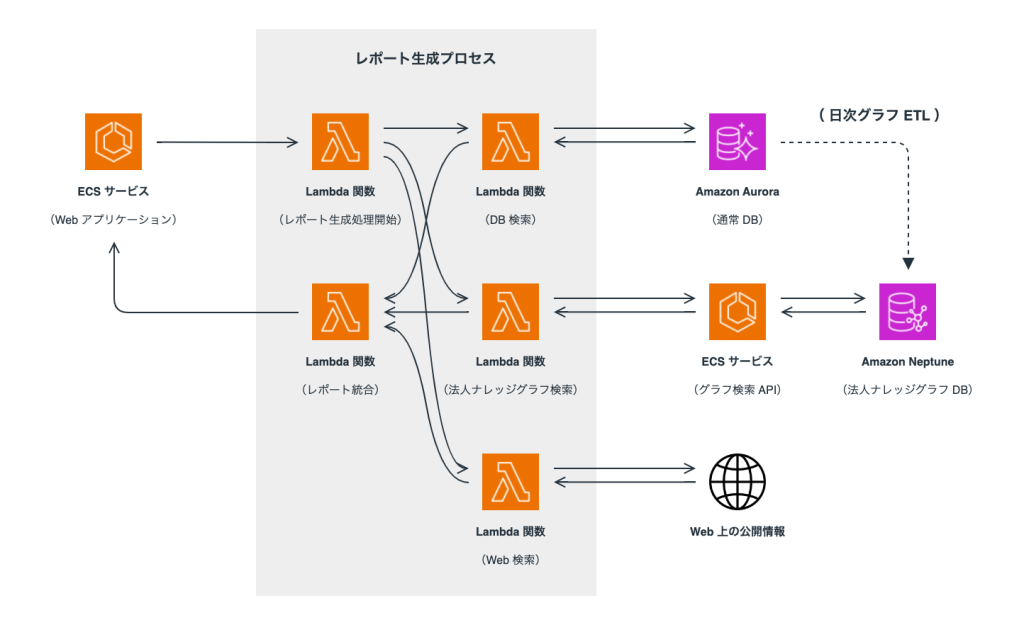
レポート生成プロセスでは、複数の AWS Lambda 関数が連携して動作しています。レポート生成処理を開始する Lambda 関数、DB 検索を行う Lambda 関数、法人ナレッジグラフ検索を行う Lambda 関数、Web 検索を行う Lambda 関数、そしてレポートを統合する Lambda 関数が、それぞれの役割を担っています。
このアーキテクチャにより、複数のデータソースを統合した包括的な法人情報の提供が可能になっています。また、日次の ETL プロセスにより、Amazon Aurora に蓄積された最新の法人情報が Amazon Neptune Database のグラフデータベースに反映される仕組みも構築されています。
Amazon Neptune Database へのデータの格納を行うETL実装の詳細
Amazon Neptune Database を活用したグラフデータベースの実装において、効率的なETL(抽出・変換・ロード)プロセスを構築しています。インフラチームの山岸氏にその詳細について伺いました。
ETL パイプラインは、Amazon Aurora に存在するリレーショナルデータをもとにグラフデータを生成し、Neptune クラスターに投入する役割を担っています。以下の図は、ETL ワークフローの全体像を示しています。
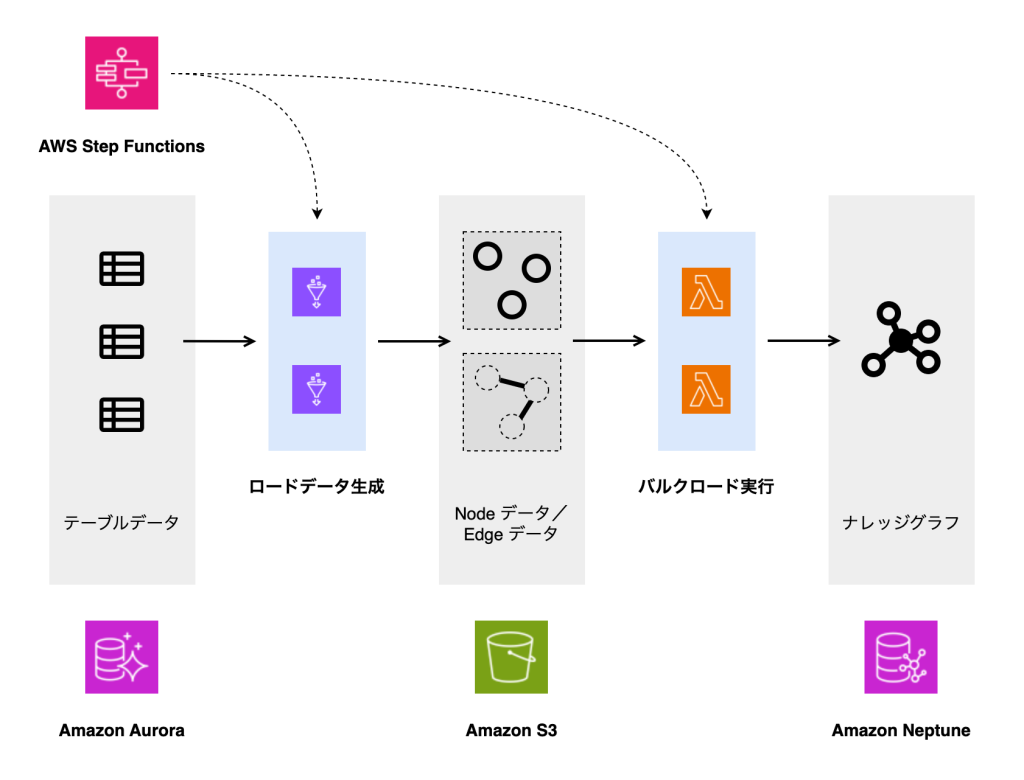
リレーショナルデータベースからのデータの読み取り、変換は AWS Glue ジョブとして実装されています。AWS Glue ジョブは、Amazon Aurora からデータを抽出し、バルクロード用の CSV ファイルを生成します。生成された CSV ファイルは Amazon S3 に保存されます。
データモデルとしてプロパティグラフ、データ形式は Apache TinkerPop Gremlin を採用し、Vertex(ノード)データと Edge(エッジ)データを CSV 形式で準備しています。例えば、法人ノードのデータは以下のような形式になります:
~id, ~label, name:String(single), established_date:Date(single)
company1, company, 株式会社サンプル, 2010-01-01
company2, company, サンプル商事株式会社, 2015-06-15
また、代表者と法人の関係を表すエッジデータは以下のような形式です:
~id, ~from, ~to, ~label, role:String(single), appointed_date:Date(single)
rel1, person1, company1, represents, 代表取締役, 2010-01-01
rel2, person1, company2, represents, 代表取締役, 2015-06-15
このような一見シンプルなデータ表現により高度な分析が可能になるのは、グラフデータベースの強みの一つです。
次に、AWS Lambda 関数を用いて Neptune Bulk Loader エンドポイントを呼び出し、S3 に保存された CSV ファイルを Neptune クラスターにロードします。Neptune Bulk Loader エンドポイントは、大量の法人データを効率的にロードするため採用されています。このエンドポイントは、S3 に格納された CSV ファイルから直接データをロードする機能を提供します。エンドポイントに対して、POST、GET、DELETE リクエストを送ることで、ロードジョブの作成、状態確認、キャンセルが可能です。
AWS Step Functions による ETL ワークフローの管理
ETL プロセス全体は、AWS Step Functions を使用してオーケストレーションされています。ワークフローは主に3つのステップで構成されています:
- AWS Glue ジョブを利用してバルクロード用にエッジ、ノードのそれぞれのデータを生成
- Amazon Neptune Database バルクローダーへのリクエストを送信し、データの格納を行う
- ロードジョブのステータスの監視、完了・エラー状態の検知、結果の通知
AWS Step Functions を用いることにより、条件分岐、AWS サービスの API の呼び出し、繰り返し、ワークフロー全体としてパラメータや設定の入力、またはそれぞれのステップへの受け渡しをローコードで実現できています。
バルクロード実行に関する各種メトリクスはデータ基盤に取り込まれており、通知されたワークフローの実行名と取り込みジョブ ID を用いて、各ジョブの詳細情報を Redash という BI ツール上で確認できるようになっています。
こちらの ETL の詳細については シンプルフォーム Tech Blog を参照いただけます。
差分更新の実装
全データの再ロードを避けるため、差分更新の仕組みを実装しています。リレーショナルデータベースの各テーブルに更新日時を表す timestamp 型カラムを持たせ、このカラムの値を利用してデータフレームをフィルタリングすることで、定期的な差分更新を実現しています。また、Neptune バルクローダー の updateSingleCardinalityProperties パラメータを活用して、既存のプロパティ値を上書きするかどうかを制御しています。
また、開発・テスト環境の整備にも工夫がなされています。グラフデータベースのテスト基盤を構築することで、開発サイクルの高速化を実現しています。詳細については、シンプルフォーム社のテックブログ「グラフデータベースのためのテスト基盤を構築し、開発サイクルを高速化してみた」をご参照ください。
グラフデータベースによるインパクト
Amazon Neptune Database の導入により、シンプルフォーム社は従来のリレーショナルデータベースでは困難だった多次元に絡み合う法人間の関係性をリアルタイムで検索・分析することが可能になりました。企業データをグラフ構造(ノードとエッジ)として保持し、Gremlin や openCypher を用いた高速なパス探索を実現することで、「A 法人 → その役員 → 役員が関連する B 法人 → B 法人の株主」といった複雑なネットワーク構造も、動的かつ瞬時に可視化できるようになりました。
実務上、金融犯罪調査において非常に重要な「ある組織と関連するすべての住所を、直接的な関係だけでなく、代表者を介した間接的な関係も含めて特定する」というような分析を考えてみましょう。このような分析は、ペーパーカンパニーの検出や不正ネットワークの特定に不可欠です。
リレーショナルデータベース でこのような分析を実現しようとすると、組織テーブル、代表者テーブル、住所テーブルの間で複数の複雑な JOIN 操作が必要となり、関係の「ホップ数」ごとに別々のクエリを作成する必要があります。さらに、データ量が増えるにつれてパフォーマンスは急激に低下し、実用的な応答時間での実行が困難になります。
一方、グラフデータベースでは、「特定の組織ノードを起点とし、代表関係または所在地関係を通じて、最大2ステップ以内に到達できる住所ノードまでの経路を探索する」という複雑な分析が、以下のようなシンプルかつ直感的なクエリで表現できます:
g.V().hasLabel("organization")
.has("organization_id", "xxxxxxxx")
.union(
// 最大2ステップの探索パス
__.until(
__.or(
__.hasLabel("address"),
__.loops().is(2)
)
).repeat(
__.bothE()
.or(
__.hasLabel("represent"),
__.hasLabel("place")
)
.bothV()
.or(
__.hasLabel("organization"),
__.hasLabel("individual"),
__.hasLabel("address"),
)
.simplePath()
),
// 1ステップの探索パス
__.until(
__.or(
__.hasLabel("address"),
__.loops().is(1)
)
).repeat(
__.bothE()
.or(
__.hasLabel("represent"),
__.hasLabel("place")
)
.bothV()
.or(
__.hasLabel("organization"),
__.hasLabel("individual"),
__.hasLabel("address"),
)
.simplePath()
)
)
.simplePath()
.limit(100)
.path()
.by(__.valueMap(true))このクエリにより、組織が直接登録している住所だけでなく、その代表者が関連する他の組織の住所も含めて、すべての関連住所を効率的に特定できます。これは、複数の法人を使った不正スキームの検出や、表面上は無関係に見える組織間の隠れた関連性の発見に非常に有効です。
上記のような、複数ステップに亘る法人・個人間のつながりという、従来リレーショナルデータベースでは困難だったインサイトの抽出ができるようになりました。これにより、表面的な企業単体のリスク評価にとどまらず、企業間のつながりを起点とした深層的なリスク分析が可能になったことがビジネスインパクトに繋がります。従来では直接的に関与していた「表の脅威アクター」しか検出できなかった局面でも、グラフ構造をたどることで、水面下に潜む「つながりの中の脅威」を芋づる式に検出できるようになりました。
この仕組みにより、シンプルフォーム社は金融機関や行政機関に対し、より高度なアンチマネー・ローンダリング(AML)技術を提供できる体制を確立しています。
導入効果と顧客事例
シンプルフォーム社の「関連性表示機能」は、金融機関をはじめとする多くの企業に導入され、リスク評価プロセスの効率化と精度向上に貢献しています。公式発表から確認できる顧客事例を見ていきましょう。
みずほ銀行様の事例
みずほ銀行様では、AML・金融犯罪対策業務において、SimpleCheck の関連性表示機能を活用されています。不審な取引のある法人の調査を中心に利用されており、調査対象法人の取引情報と関連事業者の情報を組み合わせることで、不審なつながりをより広く効率的に捕捉できる点が評価されています。
福岡銀行様の事例
福岡銀行様では、Web 法人口座開設業務において本機能を活用されています。調査対象法人だけではなく、関連する企業や役員も可視化されており、審査精度の向上や効率化につながっている点が評価されています。
インフキュリオン様の事例
インフキュリオン様では、請求書支払いプラットフォームの利用企業・取引内容の確認業務において活用されています。人手では容易に見抜けない関係性を迅速に確認できる点が評価されており、結託取引の未然検知によるリスク抑制へ期待されています。
事例出典: シンプルフォーム様のプレスリリース
まとめ
シンプルフォーム社の「関連性表示機能」は、AWS が提供するグラフデータベースサービスである Amazon Neptune Database を活用することで、従来は人手では困難だった法人間の複雑な関連性を 30 秒で可視化することを実現しました。本記事では、この革新的なソリューションの技術的側面に焦点を当て、Amazon Neptune Database の活用方法と実装の詳細を解説しました。
シンプルフォーム社の事例は、グラフデータベースの特性を活かした関連性分析が、金融犯罪対策や審査業務の効率化に大きく貢献できることを示しています。特に、リレーショナルデータベースでは実現が困難だった「複数ステップに亘る法人・個人間のつながり」というインサイトの抽出が可能になったことは、大きな技術的ブレークスルーと言えるでしょう。
Amazon Neptune Database のマネージドサービスとしての特性を活かし、インフラ管理の負担を軽減しながら、グラフデータによる高度な不正検知システムを実現したシンプルフォーム社の取り組みは、他の企業がグラフデータベースを導入する際の参考になるでしょう。今後も、グラフデータベース技術の進化とともに、より高度なリスク評価ソリューションの開発が期待されます。