Amazon Web Services ブログ
詳解: Amazon EKS 超大規模クラスター
この記事は Under the hood: Amazon EKS ultra scale clusters (記事公開日: 2025 年 7 月 16 日) を翻訳したものです。
本日、Amazon Elastic Kubernetes Service (Amazon EKS) は最大 10 万台のノードをサポートするクラスターの提供を発表しました。Amazon EC2 の新世代高速コンピューティングインスタンスタイプを活用することで、これは単一の Kubernetes クラスターで 160 万個の AWS Trainium チップまたは 80 万個の NVIDIA GPU を実現することを意味します。これにより、最先端のモデルトレーニング、ファインチューニング、エージェント推論などの超大規模人工知能 (AI) および機械学習 (ML) ワークロードが可能になります。現在 Amazon EKS を直接利用しているお客様だけでなく、EKS をコンピュートレイヤーとして活用する Amazon SageMaker HyperPod with EKS などの他の AI/ML サービスにもこれらの改善が拡張され、AWS の超大規模コンピューティング能力全体を向上させます。
お客様からは、トレーニングジョブのコンテナ化や Kubeflow などのオペレーター、Karpenter のようなプロジェクトを通じたリソースプロビジョニングとライフサイクルの合理化、プラグ可能なスケジューリング戦略のサポート、そして豊富なクラウドネイティブツールのエコシステムへのアクセスが、AI/ML 領域での成功に不可欠であることが明確に示されています。Kubernetes は、強力で拡張可能な API モデルと堅牢なコンテナオーケストレーション機能により、アクセラレーテッドワークロードの迅速なスケーリングと信頼性の高い実行を可能にする重要な要素として注目されています。複数の技術革新、アーキテクチャの改善、オープンソースでのコラボレーションを通じて、Amazon EKS は Kubernetes に完全に準拠しながら、超大規模向けの次世代クラスターコントロールプレーンとデータプレーンを構築しました。
AWS では、結合度が低く水平方向にスケーラブルな汎用アプリケーションを実行するお客様に対して、成長を維持するための戦略としてセルベースのアーキテクチャに従うことを推奨しています。しかし、最先端の AI/ML モデルの開発には、低遅延で高帯域幅の通信を備えた単一の統合システムとして連携する数千のアクセラレーターが必要です。これらを単一のクラスター内で実行することには、いくつかの重要な利点があります。まず、大規模な事前トレーニングからファインチューニング、バッチ推論まで、多様なジョブを実行するための共有されたキャパシティプールを通じて使用率を高めることでコンピューティングコストを削減します。これらのジョブを別々のクラスターに分割すると、キャパシティの断片化や再マッピングの遅延により使用率が低下する可能性があります。次に、巨大なジョブを複数のクラスターに分割すると、スケジューリング、検出、修復などの一元化された操作が複雑になります。代わりに単一のクラスターで実行することで、クラスター間の調整オーバーヘッドを排除し、全体的な信頼性とパフォーマンスを向上させることができます。第三に、ML フレームワークは、グローバルなクラスタービューで実行することを前提としているため、分割クラスターモードでは常にうまく機能するとは限りません。これらが時間の経過とともにマルチクラスターモデルに進化する一方で、私たちはお客様が今日イノベーションを起こせるようにすることが重要だと考えています。
技術的詳細
Kubernetes のコアクラスターアーキテクチャはここに示される通りです。Amazon EKS はその上に特定のインフラストラクチャとソフトウェア構成、クラスター管理プレーン、そしてお客様により進んだ AWS 統合を提供するコンポーネント・サービスを構築しています。Kubernetes データストア (etcd) と API サーバーはクラスターの中核を形成し、超大規模を実現する重要な要素です。これに続いて、クラスター全体の操作やノードのローカルな操作を実行する様々なコントローラーがあります。アドオンは、クラスター内で実行されるアプリケーションのサービスディスカバリー、テレメトリ、認証情報の提供などの拡張機能を提供します。アクセラレーテッドワークロードには、ノード管理とモニタリングのためのデバイスプラグインやデーモンなど、広範なアドオンが必要です。クラスター領域の外では、Amazon EKS 管理プレーンの様々なサービスが継続的にすべてのクラスターのセキュリティ確保、スケーリング、更新を行っています。この取り組みの一環として、私たちはこれらすべてのコンポーネントとサービスが 10 万台のノード規模でシームレスに動作するように設計し、継続的な統合テストを通じて継続的に検証しています。詳細を見ていきましょう。
次世代データストア
etcd は強力な一貫性を持つ分散キーバリューデータベースで、Kubernetes API のストレージバックエンドを提供します。内部的には、Raft コンセンサスアルゴリズムを使用して、すべてのクラスターメンバー間で一貫性のあるレプリケーションされたトランザクションログを維持します。各メンバーはログのコピーを保持し、クラスターメンバーの過半数(またはクォーラム)がそのログに永続化した後にのみ、特定のトランザクションがローカルデータベースの状態に適用されます。etcd の管理とスケーリングは大きな負担であり、私たちはすでにこれをお客様から抽象化しています。私たちは etcd アーキテクチャに複数のイノベーションを導入し、Kubernetes に完全に準拠しながら、次世代のクラスターパフォーマンスをお客様に提供しています。私たちはオープンソースの etcd プロジェクトの成功に引き続き投資し、確かな etcd コアだけがこのような進歩への道を開くことができると信じています。
コンセンサスのオフロード: 根本的な変更を通じて、Amazon EKS は etcd のコンセンサスバックエンドを Raft ベースの実装から Journal にオフロードしました。Journal は AWS で 10 年以上にわたって構築してきた内部コンポーネントで、マルチアベイラビリティゾーン (AZ) の耐久性と高可用性を備えた超高速の順序付きデータレプリケーションを提供します。コンセンサスを Journal にオフロードすることで、クォーラム要件に縛られることなく etcd レプリカを自由にスケールでき、ピアツーピア通信の必要性を排除しました。様々な回復力の向上に加えて、この新しいモデルは Journal の堅牢な I/O 最適化データプレーンを通じて、お客様に優れた予測可能な読み取りと書き込みの Kubernetes API パフォーマンスを提供します。
インメモリデータベース: etcd の耐久性は、基本的には基盤となるトランザクションログの耐久性によって決まります。なぜなら、ログによってデータベースが過去のスナップショットから復元できるようになるからです。Journal がログの耐久性を担当するため、私たちはもう一つの重要なアーキテクチャの進歩を可能にしました。etcd のマルチバージョン同時実行制御 (MVCC) レイヤーを永続化するバックエンドである BoltDB を、ネットワーク接続型の Amazon Elastic Block Store ボリュームから tmpfs を使用した完全なインメモリストレージに移行しました。これにより、より高い読み取りと書き込みのスループット、予測可能なレイテンシー、より高速なメンテナンス操作という形で桁違いのパフォーマンス向上が実現します。さらに、障害時の平均復旧時間 (MTTR) を低く保ちながら、サポートされる最大データベースサイズを 20 GB に倍増しました。
パーティション化されたキースペース: Kubernetes はネイティブに etcd クラスターをリソースタイプごとにパーティション化することをサポートしており、異なるタイプのキーの間でのシリアライズ可能なトランザクションを必要としません。etcd 自体は単純化のために現在キースペースのパーティション化をネイティブにサポートしていませんが、超大規模クラスターは、ホットなリソースタイプを別々の etcd クラスターに分割することで大きな恩恵を受けます。最適なパーティション化スキームにより、Amazon EKS は長年にわたって Kubernetes 向けに進化してきた etcd の豊富な API セマンティクスを引き続き使用しながら、書き込みスループットを最大 5 倍に向上させました。私たちの新しいアーキテクチャは動的な再パーティション化を可能にしますが、適切に割り当てられた静的なパーティションが 10 万台のノード規模をサポートするのに十分であることがわかりました。これらの改善は、超大規模向けの機能が有効化された新しい EKS クラスターでのみ利用可能です。
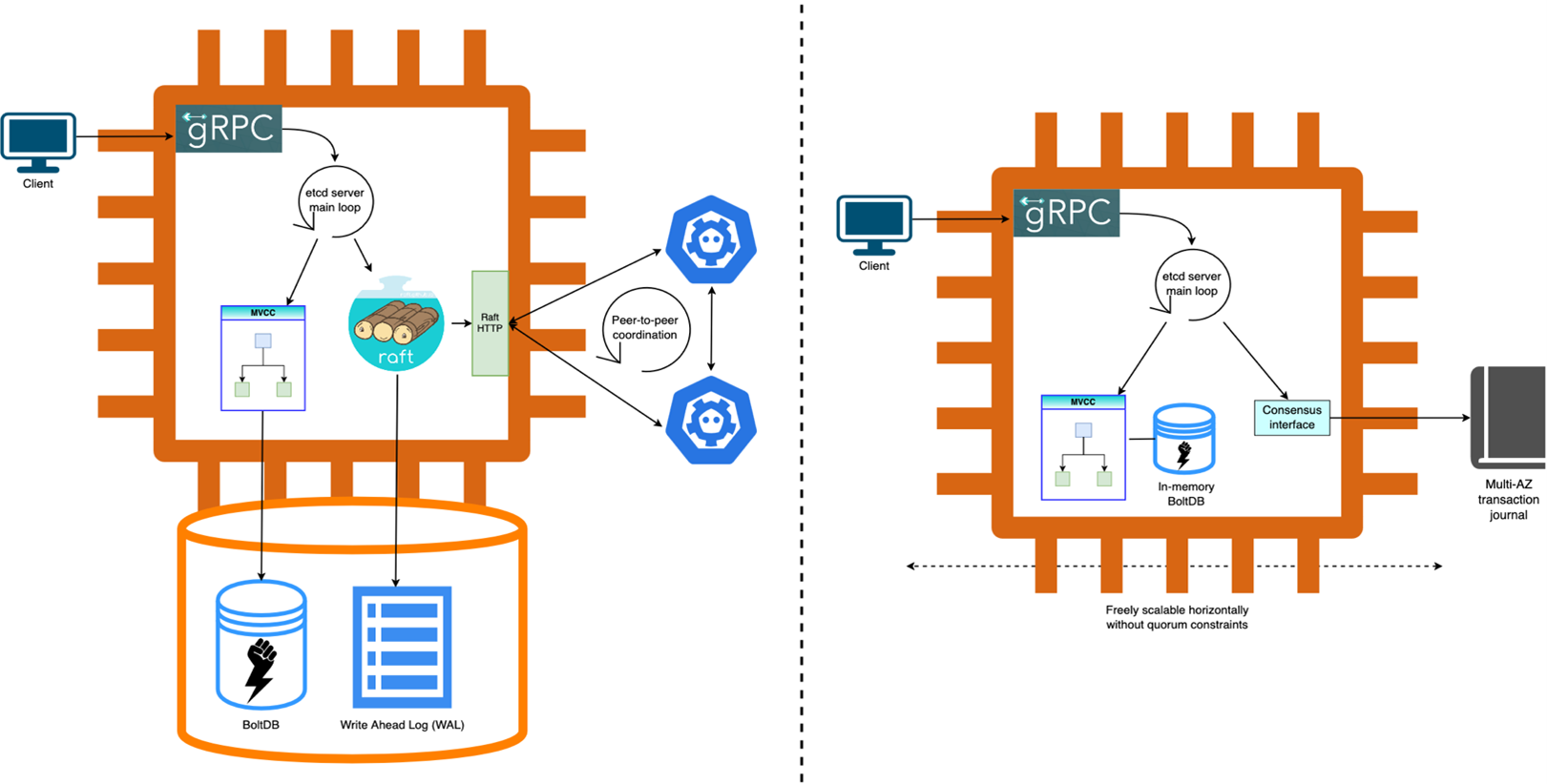
図 1. 再構築前後の Amazon EKS etcd サーバー
極限のスループットを持つ API サーバー
Amazon EKS の Kubernetes API サーバーは現在、垂直方向と水平方向に自由にスケールでき、これは様々な利用のシグナルに応じて読み取りスループットと watch のファンアウトを増加させるために既に使用している戦略です。一方、書き込みスループットは主に etcd によって決定され、そこでの改善についてはすでに説明しました。以下では、Amazon EKS クラスターの Kubernetes v1.33 以降で提供される超大規模を可能にするための更なる強化について説明します。
API サーバーとウェブフックのチューニング: 大規模なトラフィックパターン、特にアクセラレーテッドワークロードでは、リソース効率とスケーラビリティのトレードオフを調整する方法で API サーバーと重要なウェブフックをチューニングすることが非常に適しています。リクエストタイムアウト、再試行戦略、並列処理、スロットリングルール、HTTP 接続の存続時間、ガベージコレクション、etcd クライアント設定など、様々な構成を慎重にチューニングすることで最適なパフォーマンスを達成しました。このようなチューニングはほとんどのワークロードには有益ではありませんが、数万ノードでのスループットとクラスターの信頼性向上には非常に効果的です。
キャッシュからの整合性のある読み取り: Kubernetes v1.31 では、キャッシュからの強力な整合性のある読み取りが導入され、読み取りトラフィックの大部分を etcd から API サーバーにオフロードできるようになりました。以前は、ラベルやフィールドベースのフィルタリングを必要とする読み取り(例えば、Kubelet がノードに割り当てられた Pod を list する場合)では、API サーバーがまず etcd から全コレクションを list して、その後メモリ内でフィルタリングを実行してクライアントにレスポンスを送信していました。新しいメカニズムは etcd とのキャッシュの鮮度を追跡し、最新の場合は API サーバーのキャッシュから直接読み取りを提供します。サーバー側の CPU 使用率を 30% 削減し、list リクエストを 3 倍高速化することで、大幅な読み取りスループットの向上が明らかになりました。超大規模テストの一環として、ページ分割された読み取りを行うクライアントが v1.33 で不必要に etcd にフォールバックしていることを発見し、v1.33.3 でこれを修正して、大量のリクエストが同時に発生するシナリオでのクラスターの安定性を回復させました。
大規模コレクションの効率的な読み取り: 大規模クラスターには大量オブジェクトのコレクションが伴います。これらを効率的に list することは、reconciliation loop を開始する前に全コレクションをフェッチする必要がある Kubernetes コントローラーの前提条件です。例えば、Anthropic はジョブスケジューラーでこれを必要としていました。Kubernetes v1.33 で有効化された list レスポンスのストリーミング機能は、コレクション全体を一度にバッファリングするのではなく、コレクション内のアイテムを段階的にエンコード・送信することで、メモリ効率を向上させ、それによって API サーバーの list リクエストの同時実行性 (約 8 倍) を改善しました。
カスタムリソースのバイナリエンコーディング: Kubernetes カスタムリソース (CR) は、トレーニングジョブ、パイプライン、推論サービスをモデル化するために Kubeflow などの ML フレームワークで広く使用されています。これらのリソースは、非効率な JSON エンコーディングのため、大規模にそれらを保存、処理、クライアントに送信する際にサーバー側で大きなオーバーヘッドが生じます。Kubernetes v1.32 でアルファ版の機能として導入された Concise Binary Object Representation (CBOR) エンコーディングは、より効率的な代替手段を提供します。バイナリエンコーディングを使用してペイロードサイズとシリアル化のオーバーヘッドを最大 25% 削減し、CR の処理を高速化・低コスト化します。これは、AI/ML のお客様が一般的に使用するノードデーモンなど、高スループットで高カーディナリティの CR クライアントにも利点があります。この機能は現在、アップストリームではデフォルトで有効になっていないことに注意してください。私たちはパフォーマンスをベンチマークして、ベータ版への昇格を支援しています。
超高速クラスターコントローラー
クラスタースコープで動作するコントローラーは通常、集中的なクラスター操作(Pod のスケジューリングなど)を実行するためにリソースのグローバルビューを維持する必要があります。高可用性のために複製されていますが、多くの場合、競合を避けるために「リーダー」レプリカのみが実際の作業を行っています。クラスターが大きくなるほど、メモリに保持する状態が大きくなり、依存関係の TPS が増加し、大量の決定を下す必要があります。ほとんどのコントローラーは、複数のワーカースレッドとロックセーフなワークキューを通じて、受信した作業を並列に処理できます。十分なリソースがあれば、コントローラーが達成するスループットは多くの場合、ワーカーの並列性または依存関係のレート制限によって制限されます。これらを改善することで、多くの Kubernetes および EKS コントローラーのスループットを向上させました。しかし、超大規模を達成するには、これを超えてコントローラーのアーキテクチャを改善する必要がありました。
ロックの競合を最小化: Kubernetes コントローラーは Informer パターンを広く使用しています。これは、リソースのローカルなインメモリキャッシュを維持し、変更が発生したときに登録されたハンドラーに通知することで、Kubernetes リソースの変更を効率的に追跡して対応するメカニズムです。変更自体は、Kubernetes API サーバーとの長時間実行される watch の接続を通じて配信されます。コントローラーのワーカースレッドが大規模な list を実行すると、共有された Informer のキャッシュで高い読み取りと書き込みのロック競合が発生し、受信イベントの処理が遅延し、キューの滞留、高いメモリ使用量、最終的には輻輳崩壊などの様々な二次的な影響を引き起こすことを観察しました。私たちはこの問題についてアップストリームで広範な調査を行い、大規模な list リクエストを最適化するインデックスを追加することで、いくつかの主要なコントローラーを修正しました。さらに、バッチ処理により、変更率の高いシナリオでのイベント処理スループットを最大 10 倍向上させました。これらの改善をアップストリームに継続的に貢献しています。
スケジューリングの最適化: お客様は現在、独自のスケジューラーを導入し、デフォルトの Kubernetes スケジューラー (KS) の代わりに、または併用して使用できます。特定の AI/ML ワークロードは、ギャングスケジューリングとプリエンプションを効率的に実行するジョブスケジューラーの恩恵を受けます。しかし、KS は Kubernetes の DaemonSet、Deployment、Job、StatefulSet に一般的に使用される最も汎用的なスケジューラーであり続けています。ほとんどのコントローラーとは異なり、KS は正確性を満たすために Pod を直列に処理するため、そのスループットは本質的にレイテンシーに制約されています。大規模クラスターでは、評価するノードが多いため、このレイテンシーが悪化します。しかし、ワークロードに基づいてスケジューラープラグインを慎重に調整し、ノードのフィルタリングとスコアリングのパラメータを最適化することで、10 万台のノード規模でも一貫して 毎秒 500 Pod という高いスループットを達成しました。
Karpenter の強化
Karpenter は、Kubernetes のための柔軟で高性能なノードライフサイクル管理プロジェクトで、AWS が主導しています。Pod のスケジューリングニーズに基づいて適切なサイズのノードを自動的にプロビジョニングし、使用率の低いノードを統合することで、お客様がクラスターを効率的にスケールしてコストを最適化するのに役立ちます。お客様は多くの場合、汎用ワークロードとアクセラレーテッドワークロードを同じクラスターで実行し、Karpenter でコンピュートを統一的に管理したいと考えています。しかし、いくつかの制限により、超大規模 AI/ML ワークロードに理想的に適合しませんでした。私たちはこれらの問題を解決するために Karpenter を進化させました。
超大規模のための保証されたキャパシティ: ML トレーニングジョブは特定のパターンでバッチ処理されることがよくあります。Karpenter のリアクティブなプロビジョニングモデルはこれを予測せず、大規模なジョブが同時に到着したときにプロビジョニングの遅延を引き起こす可能性があります。この問題に対処するために、静的キャパシティのサポートを導入しました。静的ノードプールを使用することで、お客様はクラスター内の最小限のノードセットを一貫して作成および維持でき、それによって長期間実行される AI/ML ワークロードのためのキャパシティを保証できます。また、NodeClass API で EC2 Capacity Blocks for ML のサポートも追加しました。キャパシティブロックは、モデルトレーニング、ファインチューニング、実験の実行、推論需要の急増に備えるのに理想的です。Karpenter は、他のキャパシティタイプにフォールバックする前に、静的キャパシティをプロビジョニングする際にキャパシティブロックの使用を優先します。これらの変更はまもなくアップストリームに反映される予定です。
アクセラレーテッドコンピュートの自動修復: アクセラレーターの故障は稀ですが、発生すると AI/ML ワークロードに混乱をもたらす可能性があります。健全性の低下を検出するために EKS ノードモニタリングエージェントと Karpenter のノード修復機能を使用することで、お客様は必要に応じて異常なノードの自動交換を実行できます。同様に、お客様は Amazon EKS 最適化アクセラレーテッド AMI などのコンピュート構成の更新を推進するためにドリフト機能を活用できます。私たちは Karpenter の様々なコントローラーを並列化して、スケール時のパフォーマンスを向上させました。さらに、テスト中にメモリ割り当てや依存する API の非効率な呼び出しによるいくつかのボトルネックを発見しました。リソース使用量を最適化し、冗長な API 呼び出しを排除し、適切な操作をバッチ処理するために、これらのコードパスを最適化しました。これらの変更はすべて、超大規模でのノード修復とドリフトのレイテンシーの改善に役立ち、アップストリームで利用可能になっています。
クラスターネットワークのスケーリング
Amazon EKS は Kubernetes Pod のネイティブ VPC ネットワーキングをサポートし、オーバーレイネットワークのオーバーヘッドを回避します。また、カスタムサブネット、セキュリティグループ、アクセラレーテッドワークロード向けの Elastic Fabric Adapter (EFA) サポートなどの進んだネットワーク統合も可能にします。お客様は、トラフィックを処理するロードバランサーとバックエンド Pod 間のネットワークホップを排除することで、アプリケーションの高いパフォーマンスを実現できます。以下の機能強化により、超大規模 AI/ML 機能がさらに向上しました。
IP 割り当てからウォームプレフィックスへの移行: クラスタースケールが大きくなるにつれて、Network Address Usage (NAU) メトリクスを計画する必要があります。各 NAU ユニットは VPC のサイズを表す合計に貢献し、VPC は最大 256,000 NAU、または別の VPC とピアリングされている場合は 512,000 NAU をサポートできます。デフォルトでは、各 Pod は現在クラスター VPC から個別の IP アドレスを取得します。IP アドレスと IP プレフィックスはプレフィックスサイズに関係なく単一の NAU ユニットとしてカウントされるため、超大規模クラスターでアドレス管理にプレフィックスモードを使用するように Amazon VPC CNI を構成しました。さらに、プレフィックスの割り当ては、Amazon VPC CNI がノード起動後にノードからローカルにネットワークメタデータを検出する形で、Karpenter によってインスタンス起動パスで直接行われました。これらの改善により、10 万台のノード用の単一の VPC でネットワークを合理化しながら、ノードの起動速度を最大 3 倍に高速化することができました。
ネットワークパフォーマンスの最大化: 巨大なペタバイト規模のデータセットでトレーニングする場合、ネットワーク帯域幅がボトルネックになる可能性があります。超大規模 AI/ML ワークロードでは、Amazon S3 から膨大なデータをクラスターにプルする必要がよくあります。データを待つ間にアクセラレーターがアイドル状態になるのを避けるために、ストレージレイヤーとノード間の高帯域幅データ転送が必要です。デフォルトでは、Amazon VPC CNI は Pod に割り当てられた Elastic Network Interface (ENI) に対して 1 つのネットワークカードを選択します。このネットワークカードは、Pod のすべての送受信トラフィックを処理します。複数のネットワークカードをサポートする高速コンピューティングインスタンスタイプでは、追加のネットワークカードに Pod ENI を作成するプラグインサポートを有効にしました。これにより、Pod のネットワーク帯域幅容量(100 GB/s 以上)とパケットレート性能が向上し、それによってアクセラレーターの使用率も向上しました。
高速コンテナイメージプル
超大規模 AI/ML ワークロードでは、PyTorch トレーニング、TensorFlow ノートブック、SageMaker ディストリビューションなど、5 GB を超える大規模なコンテナイメージを使用する傾向があることを観察しました。コンテナイメージのダウンロードと展開の速度は、ワークロードの準備において重要な要素です。私たちは Seekable OCI (SOCI) 高速プルを導入し、ダウンロードと展開の並列処理を可能にしました。SOCI 高速プルは大きなレイヤーをチャンクでダウンロードし、このステップをより速く完了させます。次に、Trn2 ならびに P5e と P6 インスタンスタイプの両方でサポートされている高い Elastic Block Store (EBS) IOPS (260k) とスループット (10 GB/s) を活用して、展開時間を短縮しました。各レイヤーが完了するのを待ってから次のレイヤーを開始するのではなく、複数のレイヤーを同時に解凍して処理できる並列展開を導入しました。私たちのテストでは、デフォルトと比較して全体的なイメージのダウンロードと展開が最大 2 倍高速化されることが示されています。さらに、ワーカーノード VPC に Amazon S3 VPC エンドポイントを作成し、アベイラビリティゾーンあたり 100 GB/s の帯域幅を保証しました。これにより、コンテナイメージレイヤーのダウンロード中に十分なスループットが確保され、ノードの準備が大幅に高速化されました。
規模のテスト
私たちのテスト方法の重要な原則は、お客様と緊密に協力し、お客様のニーズから逆算して作業することです。これは、実際の超大規模 AI/ML ワークロードと、それらの成功を可能にする統合を模倣することを意味します。これには、大規模な分散事前トレーニングジョブから複数の同時ファインチューニングまたは蒸留ジョブ、高スループット推論の提供まで、幅広いワークロードをカバーする必要がありました。アクセラレーテッドインフラストラクチャを活用するには、クラスターがコンピュート・ネットワーク・ストレージ用の様々なデバイスプラグインを実行し、Amazon ECR、Amazon FSx、Amazon S3 などの重要な AWS サービスを利用する必要もあります。さらに、AI/ML のお客様は一般的に、ヘルスモニタリング(EKS ノードモニタリングエージェント)、テレメトリ(Amazon CloudWatch エージェント、NVIDIA DCGM サーバー)、アプリケーション認証情報(EKS Pod Identity エージェント)、イメージキャッシュのためのノードエージェントをインストールします。広範なテストを通じて、これらすべてのコア機能が 10 万台のノードでシームレスにスケールし、信頼性高く動作することを検証しました。
ノードライフサイクル
まず、Karpenter を使用して、ノードプールとインスタンスタイプの組み合わせで 10 万台の Amazon EC2 インスタンスを起動しました。これは 50 分で完了し、1 分あたり 2000 の準備完了ノードがクラスターに参加するレートでした。次に、新しい AMI にすべてのノードを更新するドリフトを実行しました。これはお客様にとって一般的な Day-2 オペレーションです。Karpenter はノードの Disruption Budget を尊重しながら、約 4 時間でクラスター全体をドリフトさせることができました。最後に、Karpenter ですべてのノードを 70 分でスケールダウンしました。以下のグラフは、それぞれプロビジョニング、ドリフト、終了のタイムラインを示しています。
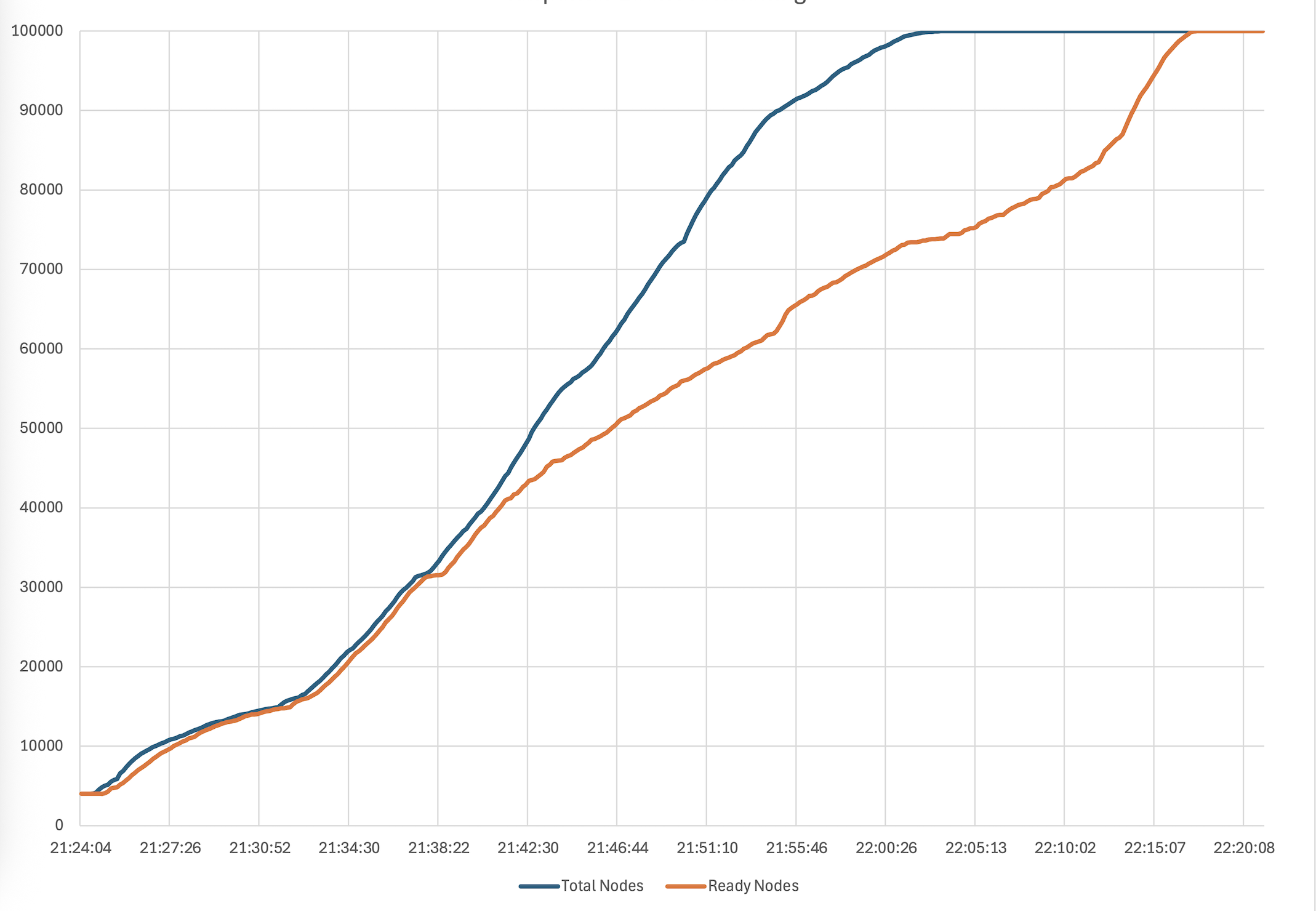
図 2. 10 万台のノードプロビジョニングのタイムライン
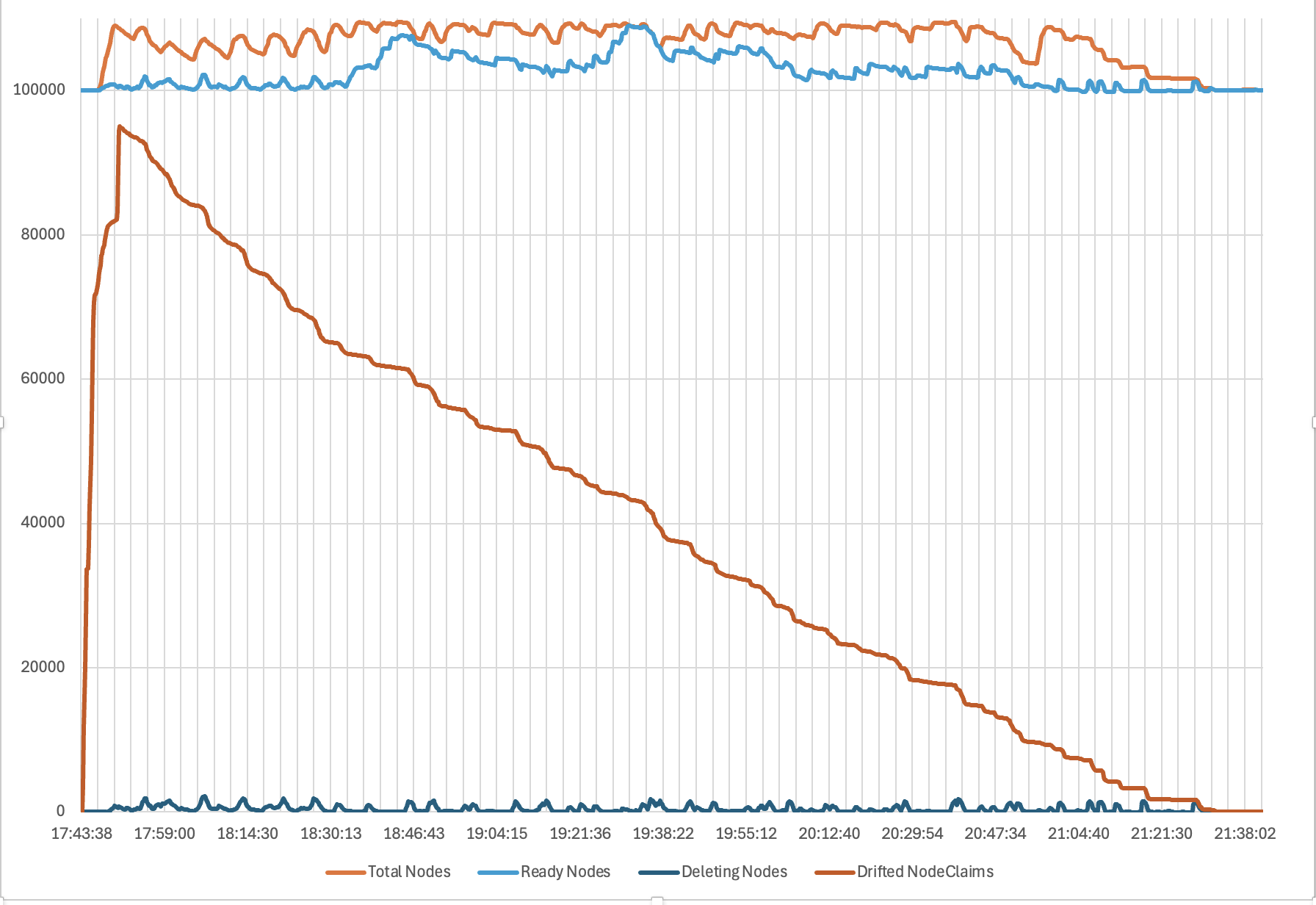
図 3. Karpenter によるドリフトのタイムライン
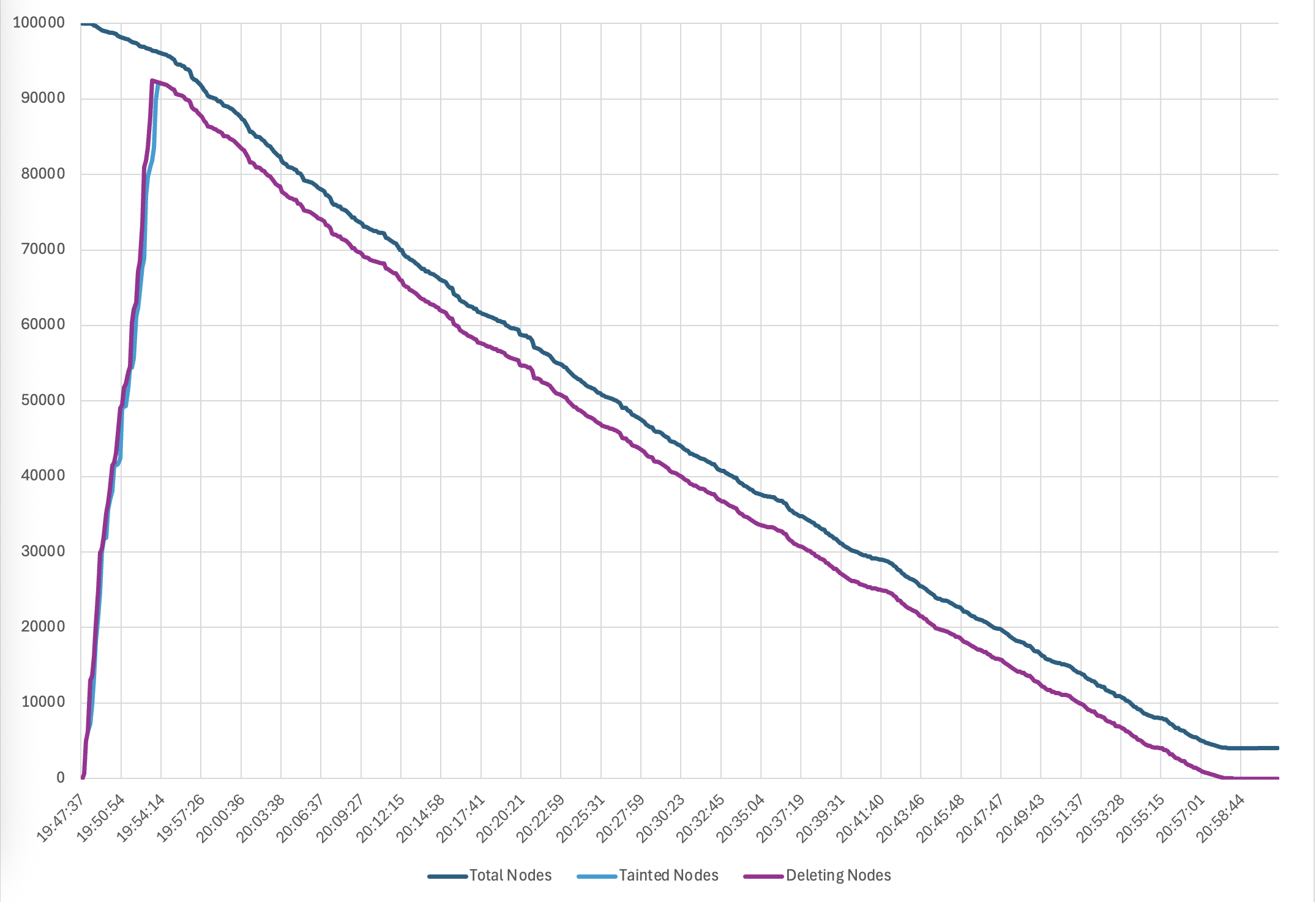
図 4. ノード終了のタイムライン
ワークロードテスト
私たちのテストは 3 つのシナリオをカバーしました。すべての 10 万台のノードで実行される大規模な事前トレーニングジョブ、それぞれ 1 万台のノードを使用する 10 の並列ファインチューニングジョブ、そして 7 万台のノードでファインチューニングジョブを実行し、3 万台のノードで大規模推論を提供する混合モードのワークロードです。Amazon ECR からプルした vLLM モデルサーバーと Amazon FSx からロードされたモデルの重みを使用して、Meta Llama-3.2-1B-Instruct で推論を提供するために LeaderWorkerSet を使用しました。最大 10 万個の異種の AI Pod を実行するクラスターを観察してください。
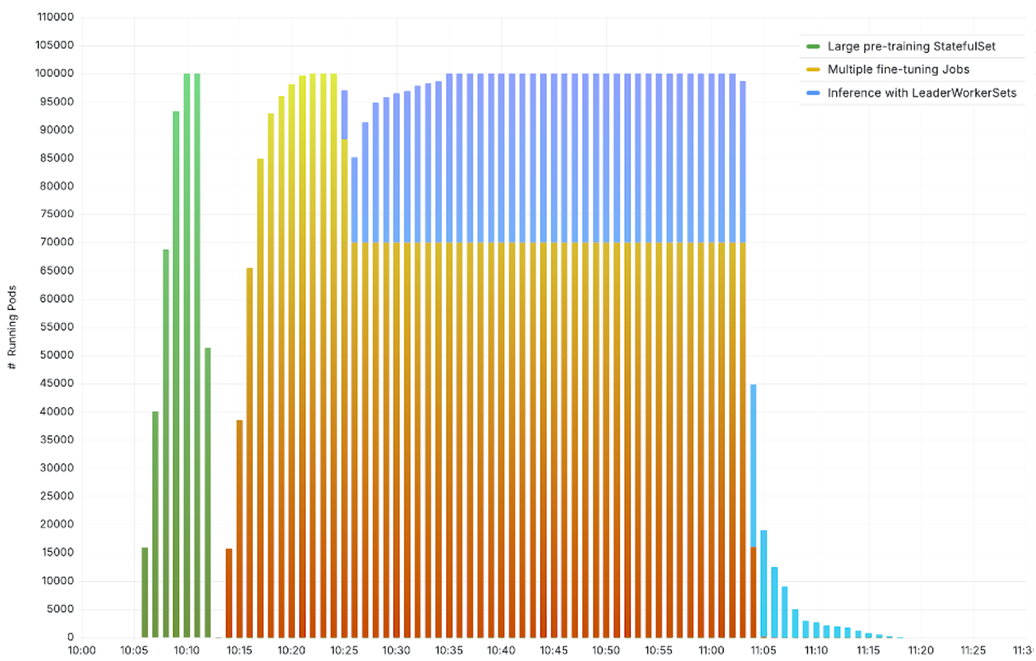
図 5. 10 万台のノードで実行される AI/ML テストシナリオ
クラスターがこれらのワークロードを処理する際、高い Kubernetes API の読み取りスループット (左) と書き込みスループット (右) が問題なく提供されます。
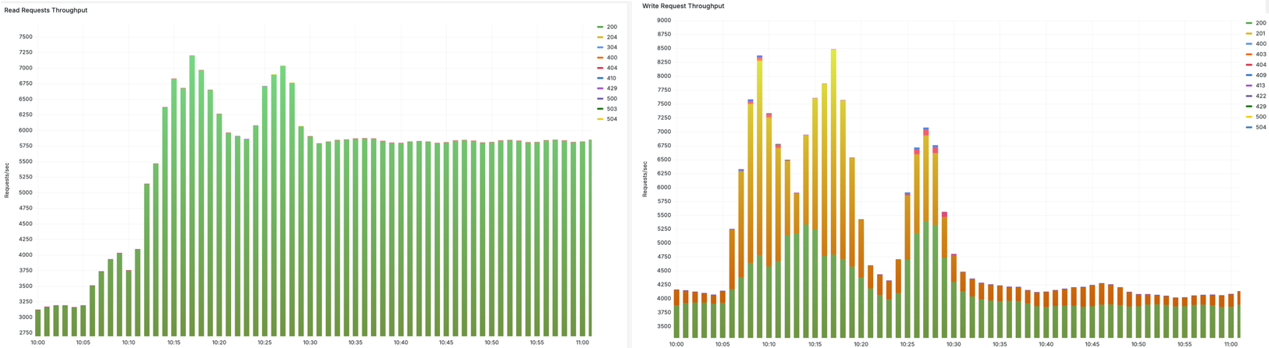
図 6. 高スループットの読み取りと書き込みリクエスト
そして、p99 API レイテンシーは、get と write (左) の 1 秒と list (右) の 30 秒という Kubernetes SLO ターゲット内に十分収まっています。
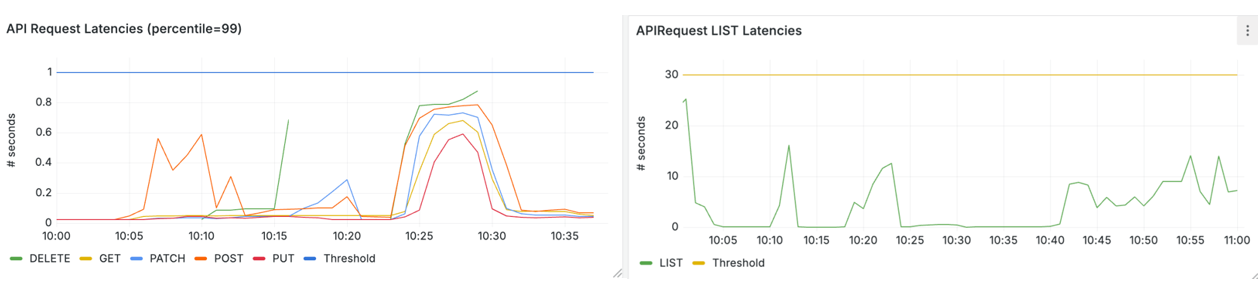
図 7. SLO ターゲット内の Kubernetes API リクエストレイテンシー
クラスターには 10 万台のノードと 90 万個の Pod を含む 1000 万個以上の Kubernetes オブジェクト (左) と、パーティション全体で 32 GB に達する集約された etcd データベースサイズ (右) が含まれています。
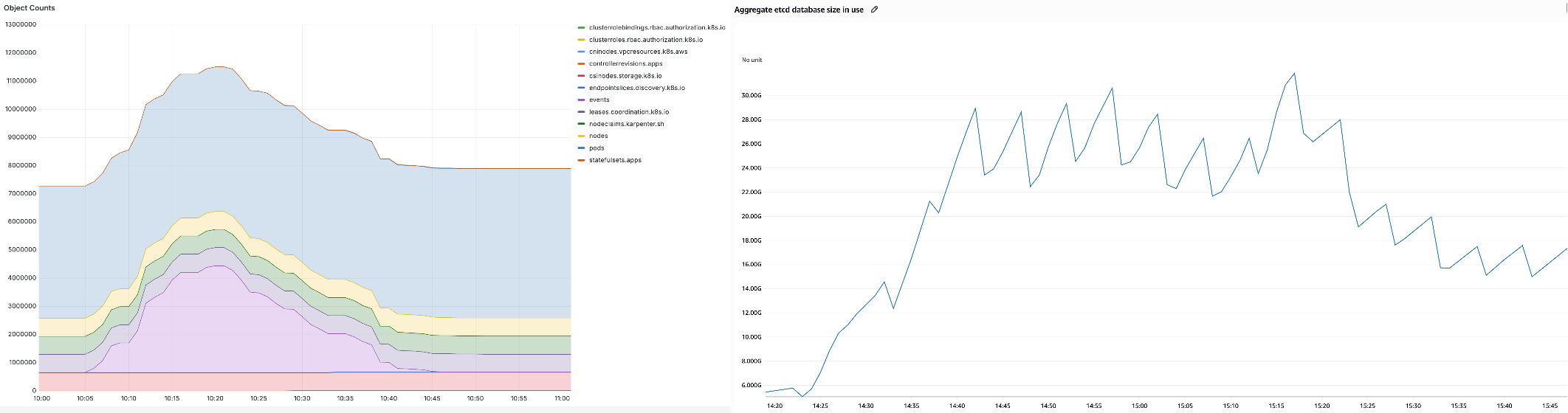
図 8. 1000 万個以上のオブジェクトを持つ 32 GB の etcd データベース
Kubernetes スケジューラーは一貫して毎秒最大 500 Pod のスループット (左) を提供し、クラスターコントローラーは短いワークキューの待ち行列 (右) を維持しながら処理に対応できました。
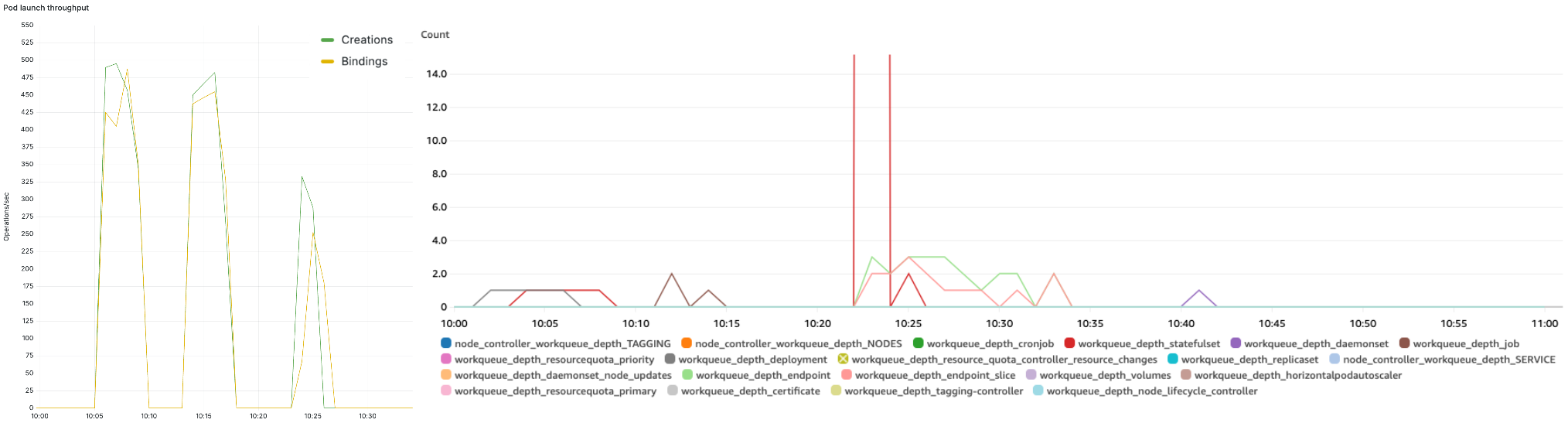
図 9. 毎秒 500 Pod のスケジューラースループットと短いコントローラーワークキューの待ち行列
クラスターの回復力
クラスターの回復力をテストするために、1000 ノードにわたって健全性の低下を誘発し、EKS ノードモニタリングエージェントがそれらを検出して異常としてマークし、Karpenter がそれらを健全な新しいノードに置き換えるノード自動修復を実行するまでの時間を測定しました。全体として、劣化した 1000 ノードすべてが 5 分以内に健全な新しいノードに置き換えられました (左)。また、150 万 QPS でクラスター DNS クエリを引き起こしました。EKS CoreDNS オートスケーラーが Deployment のレプリカを 4000 にスケールすることで、p99 クエリレイテンシーは 1 秒未満に保たれました (右)。
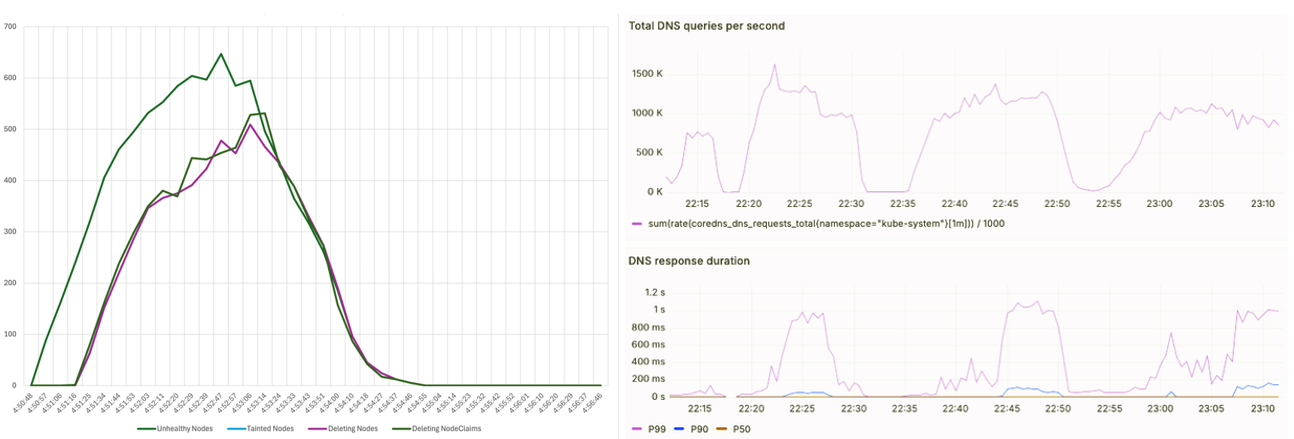
図 10. 1000 ノード障害と 150 万 QPS DNS クエリに対するクラスターの回復力
まとめ
Amazon EKS の 10 万台のノードクラスターのサポートは、超大規模 AI/ML インフラストラクチャにおける画期的な進歩を表しており、お客様は単一の統合システムで最大 160 万個の AWS Trainium チップまたは 80 万個の NVIDIA GPU をデプロイできるようになりました。etcd コンセンサスを AWS のマルチ AZ の Journal システムにオフロードするなどの一連のアーキテクチャ改善と様々な最適化により、Kubernetes に完全に準拠しながら桁違いのパフォーマンス向上を達成しました。これらのイノベーションは、Anthropic のようなお客様が最先端のモデルトレーニングと推論ワークロードを大規模で実行できるようにするだけでなく、Amazon SageMaker HyperPod などの Amazon のより広範な AI/ML サービス基盤も強化します。生成 AI が計算要件の限界を押し上げ続ける中、私たちは前例のない信頼性、パフォーマンス、規模で次世代のアクセラレーテッドワークロードをサポートする準備ができています。
翻訳はシニアパートナーソリューションアーキテクトの市川が担当しました。原文はこちらです。