Amazon Web Services ブログ
Web Audio API を使用してマルチチャンネルオーディオを Amazon Transcribe にストリーミングする
マルチチャネル文字起こしストリーミングは、Amazon Transcribe の機能の一つで、多くの場合ウェブブラウザで利用できます。このストリームソースの作成にはいくつかの制約がありますが、 JavaScript Web Audio APIを使用すると、動画、音声ファイル、マイクなどのハードウェアなど、さまざまなオーディオソースを接続して組み合わせ、文字起こしを作成できます。
この記事では、2 つのマイクをオーディオソースとして使用し、それらを 1 つのデュアルチャネルオーディオに結合し、必要なエンコードを実行して Amazon Transcribe にストリーミングする方法を説明します。ブラウザに 2 つのマイクを接続する際に必要とする Vue.js アプリケーションのソースコードも提供されています。ただし、このアプローチの汎用性はこのユースケースにとどまらず、さまざまなデバイスやオーディオソースに対応するように調整できます。
このアプローチでは、1 回の Amazon Transcribe セッションで 2 つのソースの文字起こしを取得できるため、ソースごとに個別のセッションを使用する場合と比較して、コスト削減などのメリットが得られます。
2つのマイクを使用する際の課題
今回のユースケースでは、2 つのマイクでシングルチャネルのストリームを使用し、 Amazon Transcribe のスピーカーラベル識別機能 を有効にしてスピーカーを識別すれば十分かもしれませんが、いくつか考慮すべき点があります。
- スピーカーラベルはセッション開始時にランダムに割り当てられるため、ストリーム開始後にアプリケーションで結果をマッピングする必要があります。
- 似たような声色を持つスピーカーが誤ってラベル付けされる可能性があり、人間でさえ区別が困難です。
- 2 人のスピーカーが 1 つのオーディオソースで同時に話すと、音声が重なり合う可能性があります。
マイクで 2 つのオーディオソースを使用し、各トランスクリプトが固定の入力ソースから取得することで、これらの懸念に対処できます。スピーカーにデバイスを割り当てることで、アプリケーションはどのトランスクリプトを使用するかを事前に認識できます。ただし、近くにある 2 つのマイクが複数の音声を拾っている場合、音声が重なり合う可能性があります。これは、指向性マイク、音量管理、Amazon Transcribe の単語レベルの信頼度スコアを使用することで軽減できます。
ソリューションの概要
次の図はソリューションのワークフローを示しています。
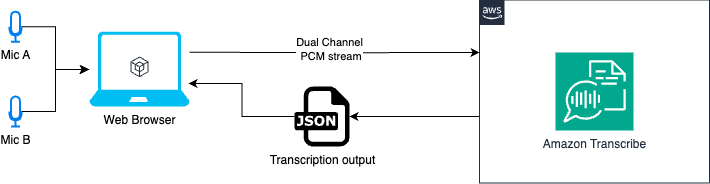
2つのマイクのアプリケーション図
Web Audio API では、2つのオーディオ入力を使用します。この API を使うと、マイク A とマイク B の2つの入力を1つのオーディオデータソースに統合できます。左チャンネルがマイク A、右チャンネルがマイク B を表します。
次に、このオーディオソースを PCM (パルス符号変調) オーディオに変換します。PCM はオーディオ処理で一般的なフォーマットであり、Amazon Transcribe がオーディオ入力に必要とするフォーマットの1つです。最後に、PCM オーディオを Amazon Transcribe にストリーミングして文字起こしを行います。
前提条件
以下の環境を事前に用意することが必要です。
- GitHub リポジトリからのソースコード。
- Bun または Node.js が JavaScript ランタイムとしてインストールされていること。
- Web Audio API と互換性のあるウェブブラウザ。このソリューションは、Google Chrome バージョン 135.0.7049.85 で動作することがテストされています。
- 2 つのマイクがコンピュータに接続され、ブラウザからこれらのマイクにアクセスできること。
- Amazon Transcribe の権限を持つ AWS アカウント。例として、Amazon Transcribe には次のAWS Identity and Access Management ポリシーを使用できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DemoWebAudioAmazonTranscribe",
"Effect": "Allow",
"Action": "transcribe:StartStreamTranscriptionWebSocket",
"Resource": "*"
}
]
}アプリケーションを起動する
アプリケーションを起動するには、以下の手順を実行してください。
- コードをダウンロードしたルートディレクトリに移動します。
env.sampleファイルから AWS アクセスキーを設定するための .env ファイルを作成します。- パッケージをインストールし、
bun installを実行します(Node.js を使用している場合はnode installを実行します)。 - Web サーバーを起動し、
bun devを実行します(Node.js を使用している場合はnode devを実行します)。 - ブラウザで
http://localhost:5173/を開きます。.
2つのマイクを接続して http://localhost:5173 で実行されているアプリケーション
コードの説明
このセクションでは、実装のための重要なコード部分を解説します。
- 最初のステップは、ブラウザ API
navigator.mediaDevices.enumerateDevices()を使用して、接続されているマイクの一覧を取得することです。
const devices = await navigator.mediaDevices.enumerateDevices();
return devices.filter((d) => d.kind === 'audioinput');- 次に、接続されているマイクごとにMediaStreamオブジェクトを取得する必要があります。これは、ユーザーのメディアデバイス(カメラやマイクなど)へのアクセスを可能にする
navigator.mediaDevices.getUserMedia()APIを使用して実行できます。その後、これらのデバイスからの音声または動画データを表すMediaStreamオブジェクトを取得できます。
const streams = []
const stream = await navigator.mediaDevices.getUserMedia({
audio: {
deviceId: device.deviceId,
echoCancellation: true,
noiseSuppression: true,
autoGainControl: true,
},
})
if (stream) streams.push(stream)- 複数のマイクからの音声を結合するには、音声処理用のAudioContextインターフェースを作成する必要があります。この
AudioContext内で、ChannelMergerNodeを使用して、異なるマイクからの音声ストリームを結合できます。connect(destination, src_idx, ch_idx)メソッドの引数は次のとおりです。- destination – 出力先。この例では
mergerNodeです。 - src_idx – ソースチャンネルのインデックス。この例では両方とも0です(各マイクがシングルチャンネルの音声ストリームであるため)。
- ch_idx – 出力先のチャンネルインデックス。この例ではそれぞれ0と1で、ステレオ出力を作成します。
- destination – 出力先。この例では
// audioContextのインスタンス
const audioContext = new AudioContext({
sampleRate: SAMPLE_RATE,
})
// マイクのストリームデータを処理するために使用
const audioWorkletNode = new AudioWorkletNode(audioContext, 'recording-processor', {...})
// microphone A
const audioSourceA = audioContext.createMediaStreamSource(mediaStreams[0]);
// microphone B
const audioSourceB = audioContext.createMediaStreamSource(mediaStreams[1]);
// 2つの入力用のオーディオノード
const mergerNode = audioContext.createChannelMerger(2);
// オーディオ ソースを mergerNode の宛先に接続。
audioSourceA.connect(mergerNode, 0, 0);
audioSourceB.connect(mergerNode, 0, 1);
// mergerNodeをAudioWorkletNodeに接続
merger.connect(audioWorkletNode);
- そのマイクデータは AudioWorklet tで処理され、指定された録音フレーム数ごとにデータメッセージが送信されます。これらのメッセージには、Amazon Transcribeに送信するPCM形式でエンコードされた音声データが含まれます。 p-event ライブラリを使用すると、Workletからのイベントを非同期的に反復処理できます。このWorkletの詳細については、この記事の次のセクションで説明します。
import { pEventIterator } from 'p-event'
...
// ワークレットを登録する
try {
await audioContext.audioWorklet.addModule('./worklets/recording-processor.js')
} catch (e) {
console.error('Failed to load audio worklet')
}
// 非同期イテレータ
const audioDataIterator = pEventIterator<'message', MessageEvent<AudioWorkletMessageDataType>>(
audioWorkletNode.port,
'message',
)
...
// AsyncIterableIterator: ワークレットが `SHARE_RECORDING_BUFFER` メッセージを含むイベントを発行するたびに、このイテレータは必要な AudioEvent オブジェクトを返す。
const getAudioStream = async function* (
audioDataIterator: AsyncIterableIterator<MessageEvent<AudioWorkletMessageDataType>>,
) {
for await (const chunk of audioDataIterator) {
if (chunk.data.message === 'SHARE_RECORDING_BUFFER') {
const { audioData } = chunk.data
yield {
AudioEvent: {
AudioChunk: audioData,
},
}
}
}
}
- Amazon Transcribeへのデータのストリーミングを開始するには、作成したイテレータを使用し、
NumberOfChannels: 2とEnableChannelIdentification: trueを有効にしてデュアルチャネルの文字起こしを有効にします。詳細については、 AWS SDK StartStreamTranscriptionCommand のドキュメントをご覧ください。
import {
LanguageCode,
MediaEncoding,
StartStreamTranscriptionCommand,
} from '@aws-sdk/client-transcribe-streaming'
const command = new StartStreamTranscriptionCommand({
LanguageCode: LanguageCode.EN_US,
MediaEncoding: MediaEncoding.PCM,
MediaSampleRateHertz: SAMPLE_RATE,
NumberOfChannels: 2,
EnableChannelIdentification: true,
ShowSpeakerLabel: true,
AudioStream: getAudioStream(audioIterator),
})
- リクエストを送信すると、オーディオストリームデータと Amazon Transcribe の結果を交換するための WebSocket 接続が作成されます。
const data = await client.send(command)
for await (const event of data.TranscriptResultStream) {
for (const result of event.TranscriptEvent.Transcript.Results || []) {
callback({ ...result })
}
}
result オブジェクトには、ch_0 や ch_1 など、マイクのソースを識別するために使用できる ChannelId プロパティが含まれます。
詳細: オーディオワークレット
オーディオワークレットは別スレッドで実行することで、非常に低レイテンシなオーディオ処理を実現します。実装とデモのソースコードは、public/worklets/recording-processor.js ファイルにあります。
今回のケースでは、このワークレットを使用して主に2つのタスクを実行します。
mergerNodeのオーディオを反復処理します。このノードは両方のオーディオチャンネルを含み、ワークレットへの入力となります。mergerNodeノードのデータバイトを PCM 符号付き 16 ビット リトルエンディアン オーディオ形式にエンコードします。この処理は、反復処理ごとに、またはアプリケーションにメッセージペイロードを送信する必要があるときに行います。
これを実装するための一般的なコード構造は次のとおりです。
class RecordingProcessor extends AudioWorkletProcessor {
constructor(options) {
super()
}
process(inputs, outputs) {...}
}
registerProcessor('recording-processor', RecordingProcessor)
このWorkletインスタンスには、processorOptions属性を使用してカスタムオプションを渡すことができます。デモでは、新しいメッセージペイロードを送信するタイミングを決定するためのビットレートガイドとして、maxFrameCount: (SAMPLE_RATE * 4) / 10を設定しています。メッセージの例は以下のとおりです。
this.port.postMessage({
message: 'SHARE_RECORDING_BUFFER',
buffer: this._recordingBuffer,
recordingLength: this.recordedFrames,
audioData: new Uint8Array(pcmEncodeArray(this._recordingBuffer)), // PCM encoded audio format
})
2チャンネルのPCMエンコード
最も重要なセクションの一つは、2チャンネルのPCMエンコード方法です。Amazon Transcribe APIリファレンスのAWSドキュメントによると、AudioChunkはDuration (s) * Sample Rate (Hz) * Number of Channels * 2で定義されます。2チャンネルの場合、16000Hzで1秒は、1 * 16000 * 2 * 2 = 64000 bytesです。エンコード関数は以下のようになります。
// 入力は配列であり、各要素は AudioWorkletProcessor からの -1.0 ~ 1.0 の Float32 値を持つチャネルであることに注意してください。
const pcmEncodeArray = (input: Float32Array[]) => {
const numChannels = input.length
const numSamples = input[0].length
const bufferLength = numChannels * numSamples * 2 // 2 bytes per sample per channel
const buffer = new ArrayBuffer(bufferLength)
const view = new DataView(buffer)
let index = 0
for (let i = 0; i < numSamples; i++) {
// 各チャンネルごとにエンコード
for (let channel = 0; channel < numChannels; channel++) {
const s = Math.max(-1, Math.min(1, input[channel][i]))
// 32 ビット浮動小数点数を 16bit PCM オーディオ波形サンプルに変換します。
// 最大値: 32767 (0x7FFF)、最小値: -32768 (-0x8000)
view.setInt16(index, s < 0 ? s * 0x8000 : s * 0x7fff, true)
index += 2
}
}
return buffer
}
オーディオデータブロックの処理方法の詳細については、 AudioWorkletProcessor: process() ソッドを参照してください。PCM形式のエンコードの詳細については、 Multimedia Programming Interface and Data Specifications 1.0を参照してください。
結論
この記事では、ブラウザの Web Audio API と Amazon Transcribe ストリーミングを使用して、リアルタイムのデュアルチャネル文字起こしを実現するウェブアプリケーションの実装の詳細について説明しました。AudioContext、ChannelMergerNode、AudioWorklet を組み合わせることで、2 つのマイクからの音声データをシームレスに処理およびエンコードし、Amazon Transcribe に送信して文字起こしを行うことができました。特に AudioWorklet を使用することで、低レイテンシーの音声処理を実現し、スムーズで応答性の高いユーザーエクスペリエンスを提供できました。
このデモを基に、会議の録音から音声制御インターフェースまで、幅広いユースケースに対応する、より高度なリアルタイム文字起こしアプリケーションを作成できます。
ぜひこのソリューションをお試しいただき、コメント欄にフィードバックをお寄せください。
原文はこちらです。
About the Author
 Jorge Lanzarotti is a Sr. Prototyping SA at Amazon Web Services (AWS) based on Tokyo, Japan. He helps customers in the public sector by creating innovative solutions to challenging problems.
Jorge Lanzarotti is a Sr. Prototyping SA at Amazon Web Services (AWS) based on Tokyo, Japan. He helps customers in the public sector by creating innovative solutions to challenging problems.