Amazon Web Services ブログ
Amazon Nova 理解モデルにおけるパフォーマンスの最適化
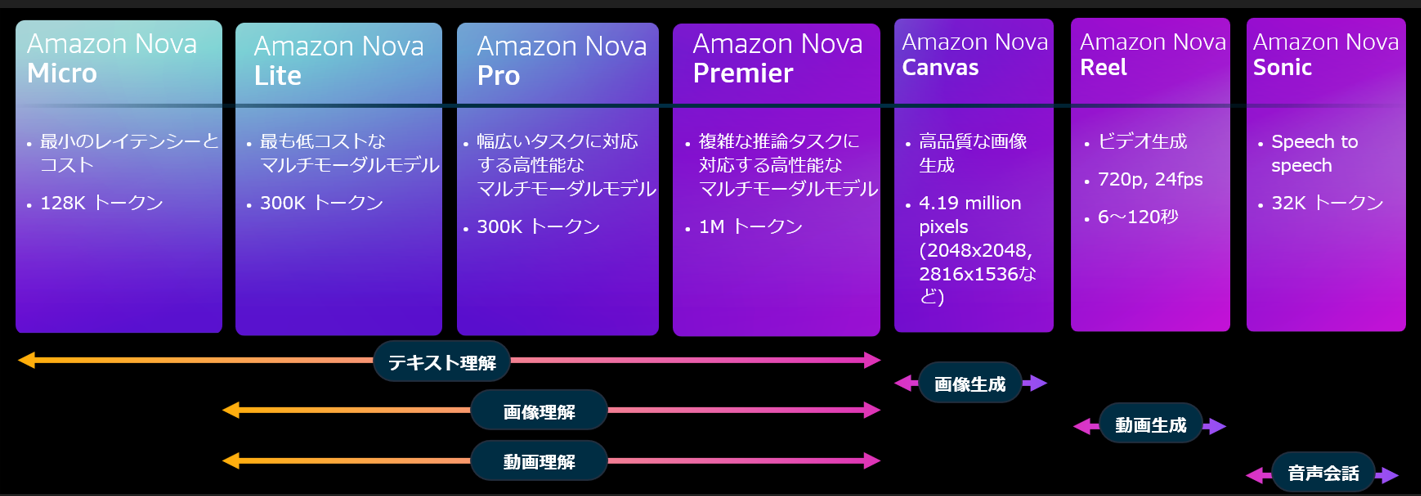
Amazon Nova は、Amazon Bedrock で利用できる、最先端のインテリジェンスと業界をリードするコストパフォーマンスを実現する新世代の基盤モデルで、4 つの理解モデル、2 つのクリエイティブコンテンツ生成モデル、1 つの Speech-to-Speech モデルが含まれます。Amazon Nova 理解モデルは、テキスト、画像、動画入力を受け入れてテキスト出力を生成するモデルで、機能、品質、スピード、コストについて幅広い選択肢を提供します。
この記事では 、Amazon Nova 理解モデルのプロンプトエンジニアリングのベストプラクティスに従って、パフォーマンスを最適化する方法を紹介します。
Amazon Nova 理解モデルの特徴
Amazon Nova モデルには様々なニーズに合うように設計された 4 つの理解モデルが含まれています。
- Amazon Nova Micro – 非常に低コストで最小レイテンシーのレスポンスを提供するテキストのみのモデルです。
- Amazon Nova Lite – 非常に低コストのマルチモーダルモデルで、画像、動画、テキストの入力を高速で処理できます。
- Amazon Nova Pro – 幅広いタスクの精度、速度、コストを最適に組み合わせた、高性能のマルチモーダルモデルです。
- Amazon Nova Premier – 複雑なタスクに最適なマルチモーダルモデルであり、コスト効率の高いアプリケーション向けのカスタムモデルを蒸留するための教師にもなります。
各モデルの料金の詳細については、Amazon Bedrock の料金ページをご覧ください。
Amazon Nova 理解モデルのプロンプトエンジニアリング
モデルを効果的に導いて品質の精度を向上させるため、明確な指示で構造化されたプロンプトを反復的に改善することが重要です。ユースケースに最適なプロンプトを開発できるように、次の要素を検討することをお勧めします。
- プロンプトのユースケースの定義する
- タスク – モデルが具体的に何をするか
- ロール – モデルが想定すべきロール
- 応答スタイル – 出力の構造やトーン
- 指示 – モデルが順守すべきガイドライン
- 思考連鎖を利用するか
- モデルの応答を制限する明確で強い指示を与える
- Step-by-Step で考えることで構造的思考を促す
- フォーマットと構造
- ##Task##、##Context##、##Example## のように、区切り文字を使用してプロンプトのセクションを分ける
- JSON、YAML、Markdown などの出力形式を指定する
- DO、DO NOT、MUST など、強い指示や制限を使用する
- 事前入力(prefill)して、前書きを省略したり指定した形式で出力することを誘導する
Amazon Nova 理解モデルのプロンプト例
議事録を要約する以下の例を考えてみましょう。ベストプラクティスに従って Amazon Nova Pro のプロンプトは以下のシステムプロンプトから始まります。ここでは temperature を 0.2、topP を 0.9 にしています。
ユーザプロンプトには、以下の SF 風の架空の議事録を用意しました。最後に ##OUTPUTS## という文字列を事前入力して、前書きの省略とマークダウン形式での出力を誘導しています。
以下は Amazon Nova Pro の出力になります。マークダウン形式で出力され、各アクションアイテムの明確な担当者も特定しています。
Function calling
生成 AI エージェントの台頭により Tool use(function calling) は大規模言語モデル(LLM)にとって最も重要な機能のひとつとなりました。ジョブに適したツールを低レイテンシーで正しく選択するモデルの能力が、エージェントを使ったシステムの成功と失敗の分かれ目になる場合があります。
Amazon Nova 理解モデルの Tool use は構造化された API の呼び出しをサポートしており、ツール設定スキーマによるツールの選択をサポートしています。また、これらのツールをいつ発動させるか、させないかを決定するメカニズムも提供しています。
以下の例では、 ツール設定スキーマを渡してツールを呼び出しています。Amazon Nova 理解モデルではツールを呼び出す際に Greedy Decoding を使用するように、temperature、topP、topK を 1 に設定することが推奨されています。Converse API を使用する場合は、temperature、topP は、inferenceConfig 属性で指定し、topK は additionalModelRequestFields 属性で指定します。これによりモデルはツールの選択において最高の精度を持つようになります。Greedy Decoding パラメータやその他のツールの使用例については、Tool use (function calling) with Amazon Nova で詳しく説明されています。
tool_config = {
"tools": [{
"toolSpec": {
"name": "get_recipe",
"description": "構造化されたレシピ生成システム",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"recipe": {
"type": "object",
"properties": {
"name": {"type": "string"},
"ingredients": {
"type": "array",
"items": {
"type": "object",
"properties": {
"item": {"type": "string"},
"amount": {"type": "number"},
"unit": {"type": "string"}
}
}
},
"instructions": {
"type": "array",
"items": {"type": "string"}
}
},
"required": ["name", "ingredients", "instructions"]
}
}
}
}
}
}]
}
input_text = "チョコレートラバケーキのレシピを教えてください"
messages = [{
"role": "user",
"content": [{"text": input_text}]
}]
# 推論パラメーターを指定
inf_params = {"topP": 1, "temperature": 1}
# additionalModelRequestFields でモデル固有の推論パラメータ (topK=1) を指定
response = client.converse(
modelId="us.amazon.nova-lite-v1:0",
messages=messages,
toolConfig=tool_config,
inferenceConfig=inf_params,
additionalModelRequestFields={"inferenceConfig": {"topK": 1}}
)まとめ
Amazon Nova 理解モデルは、Amazon Bedrock で利用可能な高性能かつコスト効率に優れた次世代基盤モデルです。4 つの理解モデルは、機能、品質、スピード、コストに応じて選択できます。Amazon Nova 理解モデルのパフォーマンスを最適化するには、明確な指示で構造化されたプロンプトを反復的に改善すること、Tool use において Greedy Decoding を使用する設定を行うことが推奨されます。また、これらの手法を活用することでより安価なモデルでも十分なパフォーマンスを発揮しコスト最適化に寄与する可能性があります。