Amazon Web Services ブログ
Amazon SageMaker HyperPodでのチェックポイントなしかつ弾力的なトレーニングの紹介
2025 年 12 月 3 日、 Amazon SageMaker HyperPod における 2 つの新しい AI モデル訓練機能を発表しました:チェックポイントレス訓練は、ピアツーピアの状態回復を可能にすることで従来のチェックポイントベースのリカバリーの必要性を軽減するアプローチであり、エラスティック訓練は、リソースの可用性に基づいて AI ワークロードを自動的にスケールさせることを可能にします。
- チェックポイントなしのトレーニング – チェックポイントなしのトレーニングは、障害が発生してもトレーニングの進行を維持し、数時間かかる復旧時間を数分に短縮することで、中断を引き起こすチェックポイント再起動のサイクルを排除します。AI モデル開発を加速させ、開発スケジュールの時間を取り戻し、数千の AI アクセラレータに対してトレーニングワークフローを自信を持って拡張しましょう。
- 弾力的トレーニング – 弾力的トレーニングは、トレーニングのワークロードが利用可能なアイドル容量を自動的に活用して拡大し、推論などの優先度の高いワークロードがピークに達したときにリソースを確保するために縮小することで、クラスターの利用効率を最大化します。計算資源の利用可能性に基づいてトレーニングジョブを再設定するのに費やすエンジニアリング時間を、週あたり数時間節約できます。
トレーニングのインフラを管理する時間を費やすのではなく、これらの新しいトレーニング手法によって、チームはモデルの性能向上に専念でき、最終的には AI モデルをより早く市場に投入することができます。従来のチェックポイント依存をなくし、利用可能な容量を最大限に活用することで、モデルのトレーニング完了時間を大幅に短縮できます。
チェックポイントレストレーニング:仕組み
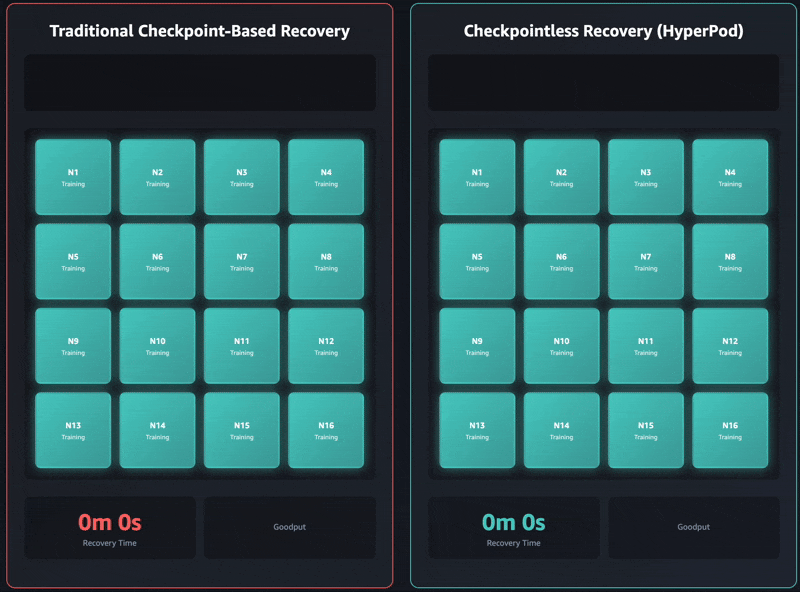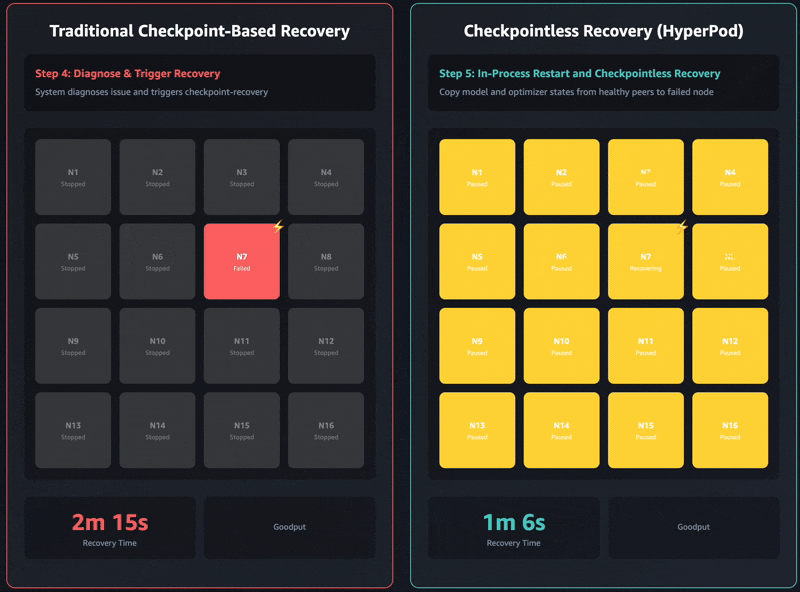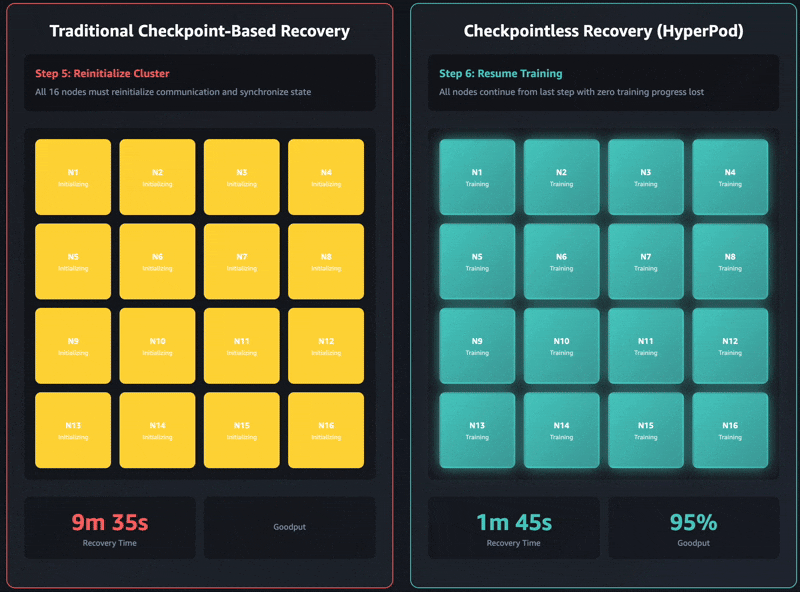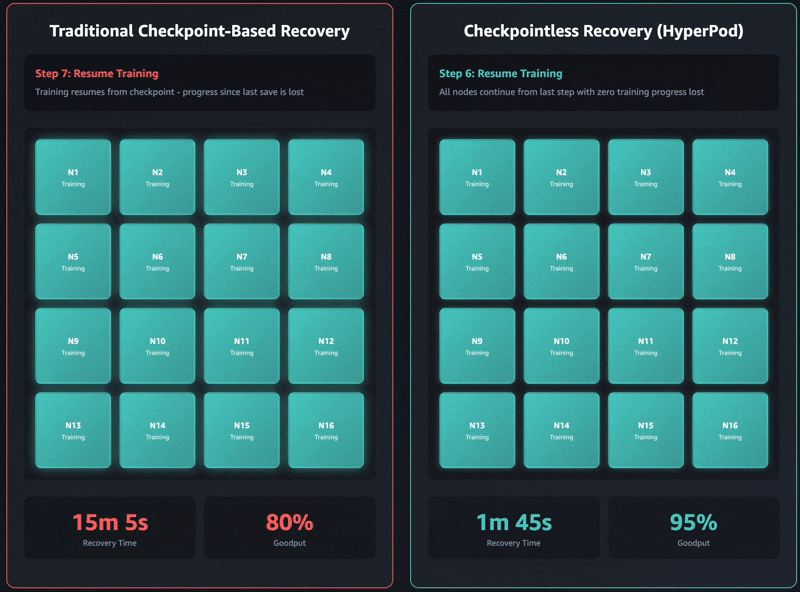
従来のチェックポイントベースのリカバリには、次の順序でジョブのステージがあります: 1) ジョブの終了と再起動、2) プロセスの検出とネットワークのセットアップ、3) チェックポイントの取得、4) データローダの初期化、5) トレーニングループの再開。障害が発生すると、各段階がボトルネックになり、セルフマネージドのトレーニングクラスターではトレーニングの回復に最大で 1 時間かかることがあります。トレーニングを再開する前に、クラスタ全体がすべてのステージの完了を待たなければなりません。これにより、リカバリ操作中にトレーニングクラスタ全体がアイドル状態になる可能性があり、コストが増加し、市場投入までの時間が延びます。
チェックポイントなしのトレーニングは、トレーニングクラスター全体でモデルの状態を連続的に保持することで、このボトルネックを完全に取り除きます。障害が発生すると、システムは正常なピアを使用して即座に回復するため、ジョブ全体を再開する必要のあるチェックポイントベースのリカバリは不要になります。その結果、チェックポイントのないトレーニングにより、数分で障害回復が可能になります。
チェックポイントレストレーニングは、段階的な導入を想定して設計されており、連携する 4 つのコアコンポーネントに基づいて構築されています。1)通信の初期化の一括最適化、2)キャッシュを可能にするメモリマップデータロード、3)インプロセスリカバリ、4)チェックポイントレスなピアツーピア状態レプリケーションです。これらのコンポーネントは、ジョブの起動に使用されるHyperPodトレーニングオペレーターによって調整されます。各コンポーネントは復旧プロセスの特定のステップを最適化し、これらを組み合わせることで、何千もの AI アクセラレータを使用しても、手動による介入なしで、数分でインフラストラクチャ障害の自動検出と復旧が可能になります。トレーニングの規模に合わせて、これらの各機能を段階的に有効にすることができます。
最新の Amazon Nova モデルは、このテクノロジーを使用して何万ものアクセラレータでトレーニングされました。さらに、16 個の GPU から 2,000 個を超える GPU までのクラスタサイズに関する社内調査に基づくと、チェックポイントレストレーニングではリカバリ時間が大幅に短縮され、従来のチェックポイントベースのリカバリと比較してダウンタイムが 80 %以上短縮されたことが示されました。
詳細については、Amazon SageMaker AI 開発者ガイドの HyperPod チェックポイントレストレーニングをご覧ください。
エラスティックトレーニング:仕組み
さまざまなタイプのモダン AI ワークロードを実行するクラスターでは、短期間のトレーニングの実行が完了したり、推論の急増が発生して収まったり、完了した実験からリソースが解放されたりすると、アクセラレーターの可用性は 1 日を通して継続的に変化する可能性があります。このように AI アクセラレーターが動的に利用可能であるにもかかわらず、従来のトレーニングワークロードは最初のコンピューティング割り当てに縛られたままであり、アイドル状態のアクセラレーターを手動で操作しないと活用できません。この硬直性により、貴重な GPU 容量が未使用のままになり、組織がインフラストラクチャへの投資を最大限に活用できなくなります。
 エラスティックトレーニングは、トレーニングワークロードがクラスターリソースと相互作用する方法を変えます。トレーニングジョブは、利用可能なアクセラレータを利用するように自動的にスケールアップし、他の場所でリソースが必要になったときに適切に契約できます。しかも、トレーニングの質は維持されます。
エラスティックトレーニングは、トレーニングワークロードがクラスターリソースと相互作用する方法を変えます。トレーニングジョブは、利用可能なアクセラレータを利用するように自動的にスケールアップし、他の場所でリソースが必要になったときに適切に契約できます。しかも、トレーニングの質は維持されます。
ワークロードの弾力性は、Kubernetes コントロールプレーンとリソーススケジューラーとの統合を通じてスケーリングの決定を調整する HyperPod レーニングオペレーターによって実現されます。ポッドライフサイクルイベント、ノードアベイラビリティの変更、リソーススケジューラーの優先度シグナルという 3 つの主要なチャネルを通じてクラスターの状態を継続的に監視します。この包括的な監視により、新たに利用可能になったリソースによるものか、優先度の高いワークロードからのリクエストによるものかにかかわらず、スケーリングの機会をほぼ瞬時に検出できます。
スケーリングメカニズムは、データ並列レプリカの追加と削除に依存しています。追加のコンピューティングリソースが使用可能になると、新しいデータ並列レプリカがトレーニングジョブに加わり、スループットが向上します。逆に、スケールダウンイベント(たとえば、優先度の高いワークロードがリソースを要求する場合)では、ジョブ全体を終了するのではなく、レプリカを削除してシステムがスケールダウンし、少ないキャパシティでトレーニングを継続できます。
さまざまなスケールにわたって、システムはグローバルなバッチサイズを維持し、学習率を調整して、モデルのコンバージェンスに悪影響が及ぶのを防ぎます。これにより、手動で操作しなくても、ワークロードを動的にスケールアップまたはスケールダウンして、利用可能な AI アクセラレータを利用できます。
Llama や GPT-OSS などの公開されているファンデーションモデル(FM)の HyperPod レシピからエラスティックトレーニングを開始できます。さらに、PyTorchトレーニングスクリプトを変更して、ジョブを動的にスケーリングできるエラスティックイベントハンドラーを追加することもできます。
詳細については、「Amazon SageMaker AI デベロッパーガイド」の「SageMaker HyperPod training plans」にアクセスしてください。はじめに、AWS GitHub リポジトリにある HyperPod レシピを見つけてください。
今すぐご利用いただけます
どちらの機能も、Amazon SageMaker HyperPod が利用できるすべてのリージョンで利用できます。これらのトレーニングテクニックは追加費用なしで使用できます。詳細については、SageMaker HyperPod の製品ページと SageMaker AI の料金ページにアクセスしてください。
ぜひお試しいただき、AWS re:Post for Amazon SageMaker 宛てに、または通常の AWS サポートの連絡先を通じて、フィードバックをお寄せください。
– Channy
原文はこちらです。