Amazon Web Services ブログ
同時挿入により Amazon Redshift でのデータ取り込みパフォーマンスを強化
Amazon Redshift は、クラウドで提供される完全マネージド型のペタバイト規模のデータウェアハウスサービスです。MPP (Massively Parallel Processing) アーキテクチャにより、クエリをコンピュートノード全体に分散してデータを処理します。各ノードは、割り当てられたデータに対して同一のクエリコードを実行し、並列処理を実現します。
Amazon Redshift は、データベーステーブルにカラムナーストレージを採用し、全体的なディスク I/O の必要量を削減しています。このストレージ方式は、クエリ時のデータ読み取りを最小限に抑えることで、分析クエリのパフォーマンスを大幅に向上させます。データは多くの組織にとって最も価値のある資産となり、データウェアハウスでのリアルタイムまたはニアリアルタイムの分析への需要を増加させています。この需要に応えるには、クエリのパフォーマンスを維持しながら、同時にデータをロードできるシステムが必要です。この投稿では、Amazon Redshift の同時データ取り込みオペレーションにおける主要な改善点をご紹介します。
書き込みワークロードにおける課題と問題点
データウェアハウス環境では、データへの同時アクセスの管理が重要でありながら、課題となっています。Amazon Redshift を使用するお客様は、さまざまなアプローチでデータを取り込んでいます。例えば、一般的に INSERT や COPY ステートメントを使用してテーブルにデータを読み込む方法があり、これらは 純粋な書き込み オペレーションとも呼ばれます。データの鮮度を最大化するために、低レイテンシーでの取り込みが要件となることがあります。これを実現するために、同じテーブルに対して同時にクエリを実行することができます。これを可能にするため、Amazon Redshift はデフォルトで スナップショット分離 を実装しています。スナップショット分離は、複数のトランザクションが同時に実行されている場合のデータ整合性を提供します。スナップショット分離は、各トランザクションがトランザクション開始時点のデータベースの一貫したスナップショットを参照することを保証し、データの整合性を損なう可能性のある読み取りと書き込みの競合を防ぎます。スナップショット分離により、読み取りクエリを並列に実行できるため、データウェアハウスが提供する完全なパフォーマンスを活用できます。
しかし、純粋な書き込みオペレーションは順次実行されます。具体的には、純粋な書き込みオペレーションはトランザクション全体で排他ロックを取得する必要があります。このロックは、トランザクションがデータをコミットした時点でのみ解放されます。このような場合、純粋な書き込みオペレーションのパフォーマンスは、セッション間での書き込みの直列実行速度によって制限されます。
これをより深く理解するために、純粋な書き込みオペレーションがどのように機能するかを見てみましょう。すべての純粋な書き込みオペレーションには、同じテーブルに対するスキャン、ソート、集計などの取り込み前のタスクが含まれます。取り込み前のタスクが完了すると、データの一貫性を維持しながらテーブルにデータが書き込まれます。純粋な書き込みオペレーションは直列に実行されるため、並列性がないことにより取り込み前のステップも直列に実行されていました。つまり、複数の純粋な書き込みオペレーションが同時に送信された場合、取り込み前のステップでさえ並列化されることなく、1 つずつ順番に処理されます。同一テーブルへの取り込みの並列性を向上させ、取り込みの低レイテンシー要件を満たすため、お客様はしばしばステージングテーブルを使用する回避策を採用しています。具体的には、ステージングテーブルに INSERT ... VALUES(..) ステートメントを送信します。その後、ALTER TABLE APPEND を使用してターゲットテーブルにデータを追加する前に、ファクトテーブルや ディメンションテーブルなどの他のテーブルとの結合を実行します。このアプローチは、ステージングテーブルを維持する必要があり、ALTER TABLE APPEND ステートメントの使用によるデータブロックの断片化により、より大きなストレージ容量が必要になる可能性があるため、望ましくありません。
まとめると、INSERT 文と COPY 文の同時実行は、排他的なロック動作のため、Amazon Redshift でのデータ取り込みワークフローのパフォーマンスと効率を最大化する際に課題となります。これらの制限を克服するには、追加の複雑さとオーバーヘッドを伴う回避策を採用する必要があります。次のセクションでは、Amazon Redshift が同時挿入の改善によってこれらの課題にどのように対処したかを説明します。
同時挿入処理とそのメリット
Amazon Redshift の パッチ 187 では、同時挿入のサポートによりデータ取り込みの同時実行性が大幅に向上しました。これにより、COPY や INSERT ステートメントなどの純粋な書き込みオペレーションの同時実行が改善され、Amazon Redshift へのデータロードにかかる時間が短縮されます。具体的には、複数の純粋な書き込みオペレーションが同時に進行し、スキャン、ソート、集計などの取り込み前のタスクを並列で実行できるようになりました。
この改善を視覚化するために、異なるトランザクションから同時に実行される 2 つのクエリの例を考えてみましょう。
以下はトランザクション 1 のクエリ 1 です。
以下は、トランザクション 2 のクエリ 2 です。
次の図は、同時挿入機能のない場合の純粋な書き込みオペレーションを簡略化して視覚化したものです。

同時挿入機能がない場合、主要なコンポーネントは以下の通りです。
- まず、純粋な書き込みオペレーション (INSERT) は、それぞれ
table bとtable cからデータを読み取る必要があります。 - ピンク色のセグメントはスキャンステップ (データの読み取り) で、緑色のセグメントは書き込みステップ (実際のデータの挿入) です。
- 「同時挿入前」の状態では、両方のクエリが順次実行されます。具体的には、クエリ 2 のスキャンステップは、クエリ 1 の挿入ステップが完了するのを待ってから開始されます。
たとえば、異なるトランザクションで同じサイズのクエリを 2 つ実行する場合を考えてみましょう。両方のクエリは同じ量のデータをスキャンし、ターゲットテーブルに同じ量のデータを挿入する必要があります。両方のクエリが午前 10 時に発行されたとします。まず、クエリ 1 は午前 10 時から午前 10 時 50 分までデータをスキャンし、午前 10 時 50 分から午前 11 時までデータを挿入します。次に、クエリ 2 はスキャンと挿入の量が同じなので、午前 11 時から午前 11 時 50 分までデータをスキャンし、午前 11 時 50 分から午後 12 時までデータを挿入します。両方のトランザクションは午前 10 時に開始されました。エンドツーエンドの実行時間は 2 時間です(トランザクション 2
は午後 12 時に終了)。
次の図は、前の例と異なり、同時挿入機能が使用できる場合の純粋な書き込みオペレーションを簡略化して示したものです。

同時挿入機能が有効な場合、クエリ 1 とクエリ 2 のスキャンステップを同時に実行できます。いずれかのクエリがデータを挿入する必要がある場合は、順次実行されます。異なるトランザクションで同じサイズの 2 つのクエリを使用した同じ例を考えてみましょう。両方のクエリは同じ量のデータをスキャンし、ターゲットテーブルに同じ量のデータを挿入する必要があります。ここでも、両方のクエリが午前 10 時に発行されたとします。午前 10 時に、クエリ 1 とクエリ 2 が同時に実行を開始します。午前 10 時から午前 10 時 50 分まで、クエリ 1 とクエリ 2 は並行してデータをスキャンできます。午前 10 時 50 分から午前 11 時まで、クエリ 1 がターゲットテーブルにデータを挿入します。次に、午前 11 時から午前 11 時 10 分まで、クエリ 2 がターゲットテーブルにデータを挿入します。両方のトランザクションの合計実行時間は 1 時間 10 分に短縮され、クエリ 2 は午前 11 時 10 分に完了します。このシナリオでは、両方のクエリの取り込み前のステップ (データのスキャン) を同時に実行でき、前の例と同じ時間 (50 分) で完了します。ただし、ターゲットテーブルへの実際のデータ挿入は順次実行され、クエリ 1 が最初に挿入を完了し、その後クエリ 2 が続きます。これは Amazon Redshift の同時挿入機能のパフォーマンス上の利点を示しています。取り込み前のステップを同時に実行できるようにすることで、この機能が導入される前の順次実行と比較して、全体の実行時間が 50 分短縮されます。
同時挿入により、取り込み前のステップを並行して進めることができます。取り込み前のタスクには、スキャン、ソート、集計などの単一または複数の組み合わせがあります。クエリのエンドツーエンドの実行時間において、大幅なパフォーマンス向上が達成されます。
メリット
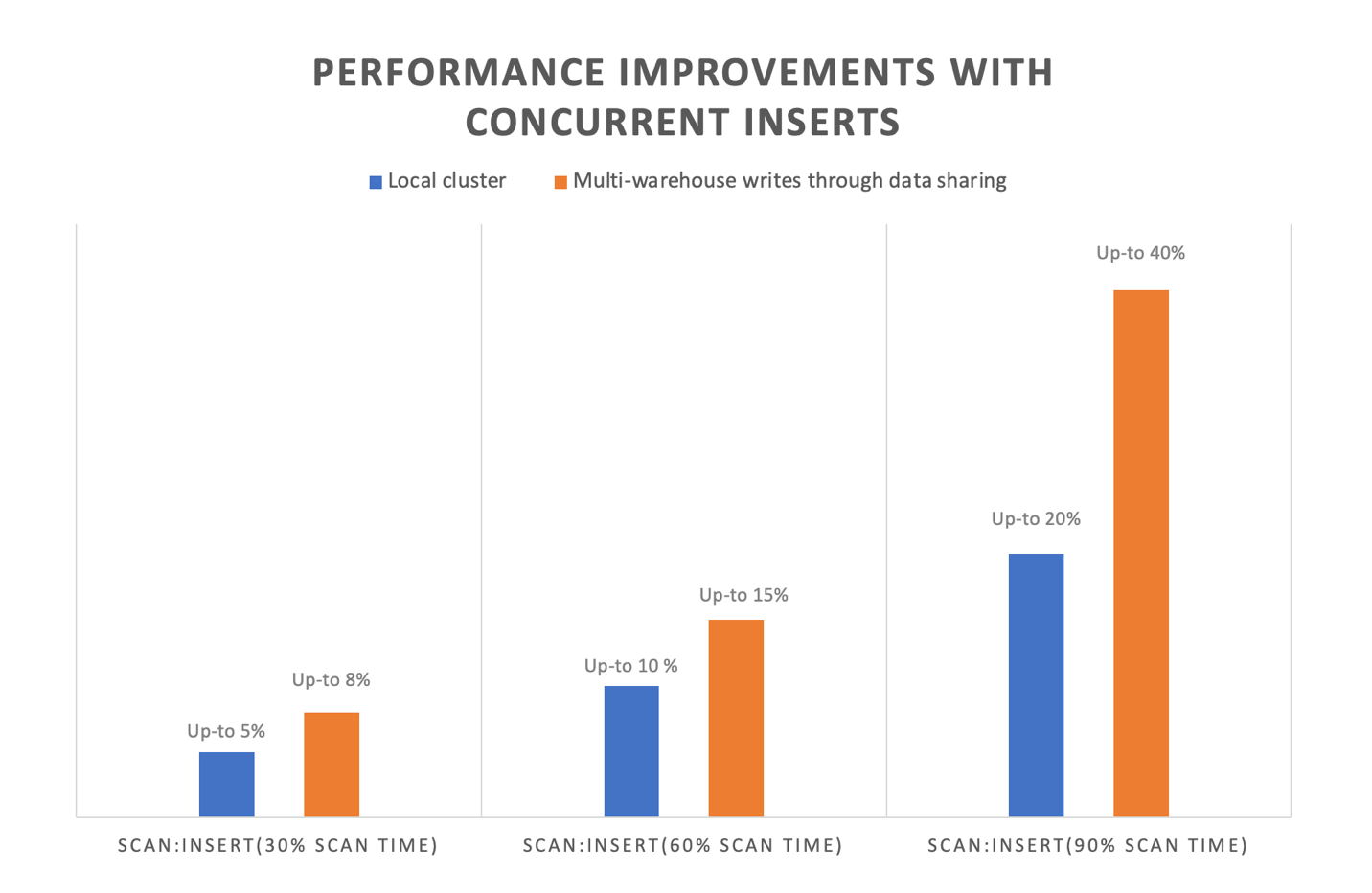
サービスが自動的に同時挿入処理を行うため、追加の設定なしでこれらのパフォーマンス改善の恩恵を受けることができます。同時挿入の改善には複数のメリットがあります。同じテーブルに書き込む際のインジェストワークロードのエンドツーエンドのパフォーマンスが向上します。社内のベンチマークでは、同じテーブルへの同時挿入トランザクションにおいて、エンドツーエンドの実行時間が最大 40% 改善されることが示されています。この機能は、特にスキャン処理の多いクエリ (データの書き込みよりもデータの読み取りに時間を要するクエリ) に効果的です。クエリにおける scan:insert の比率が高いほど、より大きなパフォーマンスの改善が期待できます。
この機能は、データ共有によるマルチデータウェアハウス書き込みのスループットとパフォーマンスも向上させます。データ共有を通じたマルチウェアハウス書き込みにより、専用の Redshift クラスターまたはサーバーレスワークグループ全体で書き込みワークロードをスケールでき、リソース使用率を最適化し、ETL (抽出、変換、ロード) パイプラインのより予測可能なパフォーマンスを実現できます。具体的には、データ共有を通じたマルチウェアハウス書き込みでは、異なるウェアハウスからのクエリが同じテーブルにデータを書き込むことができます。同時挿入により、リソースの競合を軽減し、クエリを同時に進行させることで、これらのクエリのエンドツーエンドのパフォーマンスが向上します。
次の図は、同時挿入における内部テストのパフォーマンス改善を示しています。オレンジ色のバーはデータ共有を通じたマルチウェアハウス書き込みのパフォーマンス改善を、青色のバーは同一ウェアハウスでの同時挿入のパフォーマンス改善を示しています。グラフが示すように、INSERT オペレーションに対して SCAN オペレーションの割合が高いクエリは、この新機能により最大 40% のパフォーマンス向上が得られます。
同時挿入を使用してインジェストパイプラインを管理することで、さらなるメリットを得ることができます。ALTER TABLE APPEND ステートメントを使用する回避策ではなく、同時挿入の利点を活用して同じテーブルに直接データを書き込むことで、ストレージ使用量を削減できます。これには 2 つの利点があります。1 つは一時テーブルの排除、もう 1 つは頻繁な ALTER TABLE APPEND ステートメントによるテーブルの断片化の軽減です。さらに、複雑な回避策を管理する運用上のオーバーヘッドを避け、頻繁なバックグラウンドでの自動実行および手動実行の VACUUM DELETE オペレーションにより一時テーブルをターゲットテーブルに追加することによって引き起こされる断片化を軽減できます。
考慮事項
Amazon Redshift の同時挿入機能の強化は大きなメリットをもたらしますが、スナップショット分離環境で発生する可能性のあるデッドロックシナリオに注意することが重要です。具体的には、スナップショット分離環境では、同じテーブルで同時書き込みトランザクションを実行する際に、特定の条件下でデッドロックが発生する可能性があります。スナップショット分離のデッドロックは、同時実行される INSERT 文と COPY 文がロックを共有して処理を進めている際に、別のステートメントが同じテーブルに対して排他ロックを必要とするオペレーション (UPDATE、DELETE、MERGE、または DDL オペレーション) を実行しようとする場合に発生します。
以下のシナリオを考えてみましょう。
- トランザクション 1:
- トランザクション 2:
共有ロックを持つ同じテーブルで INSERT および COPY オペレーションを含む複数のトランザクションが同時に実行され、そのうちの 1 つのトランザクションが純粋な書き込みオペレーションの後に UPDATE、MERGE、DELETE、DDL ステートメントなどの排他ロックを必要とするオペレーションを実行する場合、デッドロックが発生する可能性があります。このような状況でデッドロックを回避するには、排他ロックを必要とするステートメント (UPDATE、MERGE、DELETE、DDL ステートメント) を別のトランザクションに分離することで、INSERT および COPY ステートメントを同時に進行させ、排他ロックを必要とするステートメントをその後に実行することができます。あるいは、同じテーブルに対して INSERT および COPY ステートメントと MERGE、UPDATE、DELETE ステートメントを含むトランザクションの場合、アプリケーションにリトライロジックを組み込むことで、潜在的なデッドロックに対処することができます。デッドロックの詳細については、単一のテーブルが関連する同時書き込みトランザクションの考えられるデッドロック状況を参照し、同時実行トランザクションの例については同時書き込みの例を参照してください。
まとめ
このブログ記事では、Amazon Redshift が単一のテーブルへの同時データ取り込みパフォーマンスの向上という重要な課題にどのように対処したかを説明しました。この機能強化により、最新データへのアクセス時の低レイテンシーとより厳格な SLA の要件を満たすことができます。このアップデートは、お客様のフィードバックに基づいて Amazon Redshift に重要な機能を実装するという私たちのコミットメントを示すものです。
著者について
 Raghu Kuppala は、データベース、データウェアハウス、分析の分野で経験豊富なアナリティクス スペシャリスト ソリューションアーキテクトです。仕事以外では、様々な料理を試したり、家族や友人と時間を過ごすことを楽しんでいます。
Raghu Kuppala は、データベース、データウェアハウス、分析の分野で経験豊富なアナリティクス スペシャリスト ソリューションアーキテクトです。仕事以外では、様々な料理を試したり、家族や友人と時間を過ごすことを楽しんでいます。
 Sumant Nemmani は AWS のシニアテクニカルプロダクトマネージャーです。Amazon Redshift のお客様が、機械学習とインテリジェントなメカニズムを活用した機能を利用できるよう支援することに注力しています。これらの機能により、サービス自身によるチューニングと最適化が可能となり、お客様の利用規模が拡大しても Redshift の価格性能比を維持することができます。
Sumant Nemmani は AWS のシニアテクニカルプロダクトマネージャーです。Amazon Redshift のお客様が、機械学習とインテリジェントなメカニズムを活用した機能を利用できるよう支援することに注力しています。これらの機能により、サービス自身によるチューニングと最適化が可能となり、お客様の利用規模が拡大しても Redshift の価格性能比を維持することができます。
 Gagan Goel は AWS のソフトウェア開発マネージャーです。顧客中心のソリューションを提供するためにチームの優先順位付けとガイダンスを行い、顧客のワークロードに対するクエリパフォーマンスの監視と向上を通じて、Amazon Redshift の機能が顧客のニーズを満たすことを確実にしています。
Gagan Goel は AWS のソフトウェア開発マネージャーです。顧客中心のソリューションを提供するためにチームの優先順位付けとガイダンスを行い、顧客のワークロードに対するクエリパフォーマンスの監視と向上を通じて、Amazon Redshift の機能が顧客のニーズを満たすことを確実にしています。
 Kshitij Batra は Amazon のソフトウェア開発エンジニアで、レジリエントでスケーラブル、高性能なソフトウェアソリューションの構築を専門としています。
Kshitij Batra は Amazon のソフトウェア開発エンジニアで、レジリエントでスケーラブル、高性能なソフトウェアソリューションの構築を専門としています。
 Sanuj Basu は AWS のプリンシパルエンジニアで、Amazon Redshift を次世代のエクサバイトスケールのクラウドデータウェアハウスへと進化させる取り組みを主導しています。Redshift のコアデータプラットフォーム (マネージドストレージ、トランザクション、データ共有を含む) のエンジニアリングをリードし、お客様がシームレスなマルチクラスター分析とモダンなデータメッシュアーキテクチャを実現できるようにしています。Sanuj の取り組みは、Redshift のお客様が限界を突破するのを支援しています。
Sanuj Basu は AWS のプリンシパルエンジニアで、Amazon Redshift を次世代のエクサバイトスケールのクラウドデータウェアハウスへと進化させる取り組みを主導しています。Redshift のコアデータプラットフォーム (マネージドストレージ、トランザクション、データ共有を含む) のエンジニアリングをリードし、お客様がシームレスなマルチクラスター分析とモダンなデータメッシュアーキテクチャを実現できるようにしています。Sanuj の取り組みは、Redshift のお客様が限界を突破するのを支援しています。
翻訳はソリューションアーキテクトの小役丸が担当しました。原文はこちらです。