Amazon Web Services ブログ
GENIAC プログラムから学んだ基盤モデル構築支援の教訓
はじめに
2024年、経済産業省は GENIAC(Generative AI Accelerator Challenge) を立ち上げました。これは、企業に資金、メンタリング、そして基盤モデル開発のための 大規模なコンピューティングリソースを提供することで生成AIを推進する国家プログラムです。AWSはGENIACの第二期において、一括調達方式のクラウドプロバイダーとして選定されるとともに、個別調達方式でGENIACに参加する事業者からの計算リソース需要にも対応しました。結果として、12の事業者に向けて基盤モデル開発のための計算リソースと、AIアクセラレータークラスタ構築・運用支援を主とする技術支援を提供させていただきました。技術支援という観点では表面的には、各チームに数百のGPU/Trainiumを提供するというシンプルな課題のように見えましたが、実際には 基盤モデル(FM)のトレーニングには、単なるハードウェア以上の要素が必要でした。
AWSは、 1000以上のアクセラレーターの割り当ては始まりに過ぎないことを早期から認識していました。真の課題は、信頼性の高いインフラストラクチャ・ソフトウェアスタックの構築、ユーザーへの知識共有、分散トレーニングの障害克服にありました。GENIAC第2サイクルでは、12の顧客が1日で 127台の Amazon EC2 P5インスタンス (NVIDIA H100 TensorCore GPUサーバー)と24台の Amazon EC2 Trn1インスタンス (AWS Trainiumサーバー)をデプロイし、その後の6ヶ月間で、各社複数の大規模モデルがトレーニングされました。
この記事では、その取り組みから得られた重要な教訓を共有します。これらは、大規模な基盤モデルを構築しようとする企業や他の国家イニシアチブに適用できる貴重な知見です。
Cross Functional なエンゲージメントチーム
GENIACの取り組みに対してAWSがどういった支援を提供できるかを検討する中で得られた重要な初期の教訓は、複数組織による国家規模のMLイニシアチブを実行するには、AWS内部の多数のチームが協業して支援を提供する必要があるということでした。このため AWSは、アカウントチーム、Specialist SA/BD、サポート担当者、サービスチームを統合した Virtual Team(“v-team”)を設立しました。GENIACに向けたエンゲージメントモデルは、顧客と多層的なAWSチーム構造との緊密なコラボレーションを基盤としています。
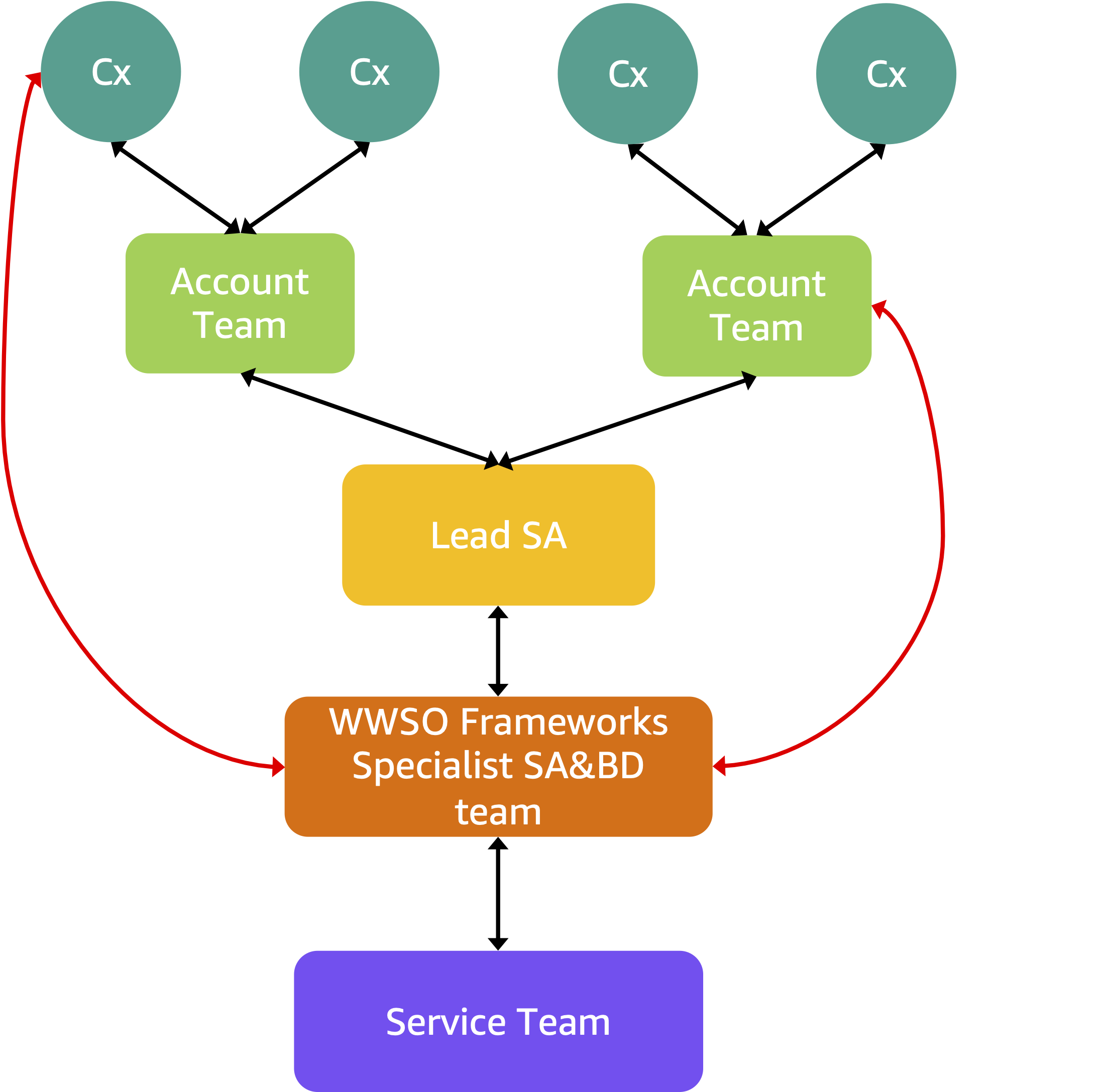
顧客(Cx)は通常、ビジネスリード、テクニカルリード、MLまたはプラットフォームエンジニアで構成され、トレーニングワークロードの実行を担当します。 AWS Account Team(ソリューションアーキテクトとアカウントマネージャー)は関係性の管理、ドキュメントの維持、顧客と内部スペシャリストとのコミュニケーションフローを確保します。 World Wide Specialist Organization(WWSO)Frameworksチームは、このエンゲージメント構造の確立と、プログラム内の技術的エンゲージメントの監督を担当します。彼らは他のステークホルダーとパートナーシップを組み、エンゲージメントをリードし、他のステークホルダーのためのエスカレーションポイントとして機能します。彼らは サービスチーム(Amazon EC2、Amazon S3やAmazon FSx for LustreなどのStorageサービス、Amazon SageMaker HyperPod)と直接連携し、エンゲージメント、エスカレーション(ビジネスおよび技術的)、エンゲージメントフレームワークの正常な動作を確保します。彼らは顧客にトレーニングと推論に関するガイダンスを提供し、他のチームに技術を教育します。WWSO Frameworksチームは GENIACに向けた支援体制で特に設定した役割であるリードソリューションアーキテクト(Lead SA)と密接に連携しました。これらのリードSAは、このエンゲージメントの基盤となる存在です。彼らはFrameworksスペシャリストチームと協力しながら、顧客とアカウントチームと直接連携します。彼らは顧客と直接対話しながら、詳細な技術的議論やトラブルシューティングの際には Frameworks チームの対応者と連携します。この階層構造により、AWSは複雑な基盤モデルトレーニングワークロードにわたって技術的ガイダンスを効果的にスケールさせることができます。
GENIACのもう一つの重要な成功要因は、顧客とAWSメンバー間の堅牢なコミュニケーションチャネルの確立でした。私たちのコミュニケーション戦略の基盤は、GENIAC支援のための専用の 内部Slackチャネルで、AWSアカウントチームとLead SA、Frameworks team が連携します。このチャネルは、リアルタイムのトラブルシューティング、ナレッジ共有、事業者の問題を適切な技術スペシャリストやサービスチームメンバーへの迅速なエスカレーションを可能にしました。これを補完するのが、AWSチームと事業者を橋渡しする 外部Slackチャネルで、参加者が質問をし、洞察を共有し、即時の技術支援を受けられる協力的な環境を作り出しました。この直接的なコミュニケーションラインは、解決時間を大幅に短縮し、参加者間の実践コミュニティを育みました。
私たちは、各顧客のトレーニング実装の詳細(モデルアーキテクチャ、分散トレーニングフレームワーク、関連するソフトウェアコンポーネント)とインフラストラクチャの仕様(インスタンスタイプと数量、ParallelClusterまたはHyperPodデプロイメントのクラスター設定、FSx for LustreやS3などのストレージソリューション)を Tracking Document として文書化しました。こうした文書を用いることで、各事業者のプロジェクトの詳細や、過去のやり取りと、サポートケースの状況等を透過的に把握できました。
この構造化されたコミュニケーションとドキュメントのアプローチにより、私たちは共通の課題を特定し、チーム間でソリューションを共有し、サポートモデルを継続的に改善することができました。詳細な追跡システムは、将来のGENIACサイクルのための貴重な洞察を提供し、顧客のニーズを予測し、基盤モデル開発プロセスにおける潜在的なボトルネックを先行的に対処するのに役立ちました。
リファレンスアーキテクチャ
もう一つの重要な洞察は、 基盤モデル開発に特化したリファレンスアーキテクチャの重要性でした。各事業者が独自のクラスターを一から立ち上げる必要がないよう、AWSは2つの主要なアプローチ AWS ParallelCluster(Self-managed の HPC クラスタ管理ツール)と Amazon SageMaker HyperPod(Managed の回復力のあるクラスターサービス用)のための 事前検証済みリファレンスアーキテクチャを開発しました。これらのリファレンスアーキテクチャは、ネットワークとストレージからコンテナ実行環境とモニタリングなど、分散学習実行に必要な機能をカバーしています。 これらのリファレンスアーキテクチャは GitHub レポジトリ( awsome-distributed-training )上で提供され、チームが最小限の工数でデプロイできるようになっています。
このリファレンスアーキテクチャは、Computing、Networking、Storage、Monitoring を、大規模な基盤モデルトレーニングに特化して設計された統合システムにシームレスに組み合わせています。
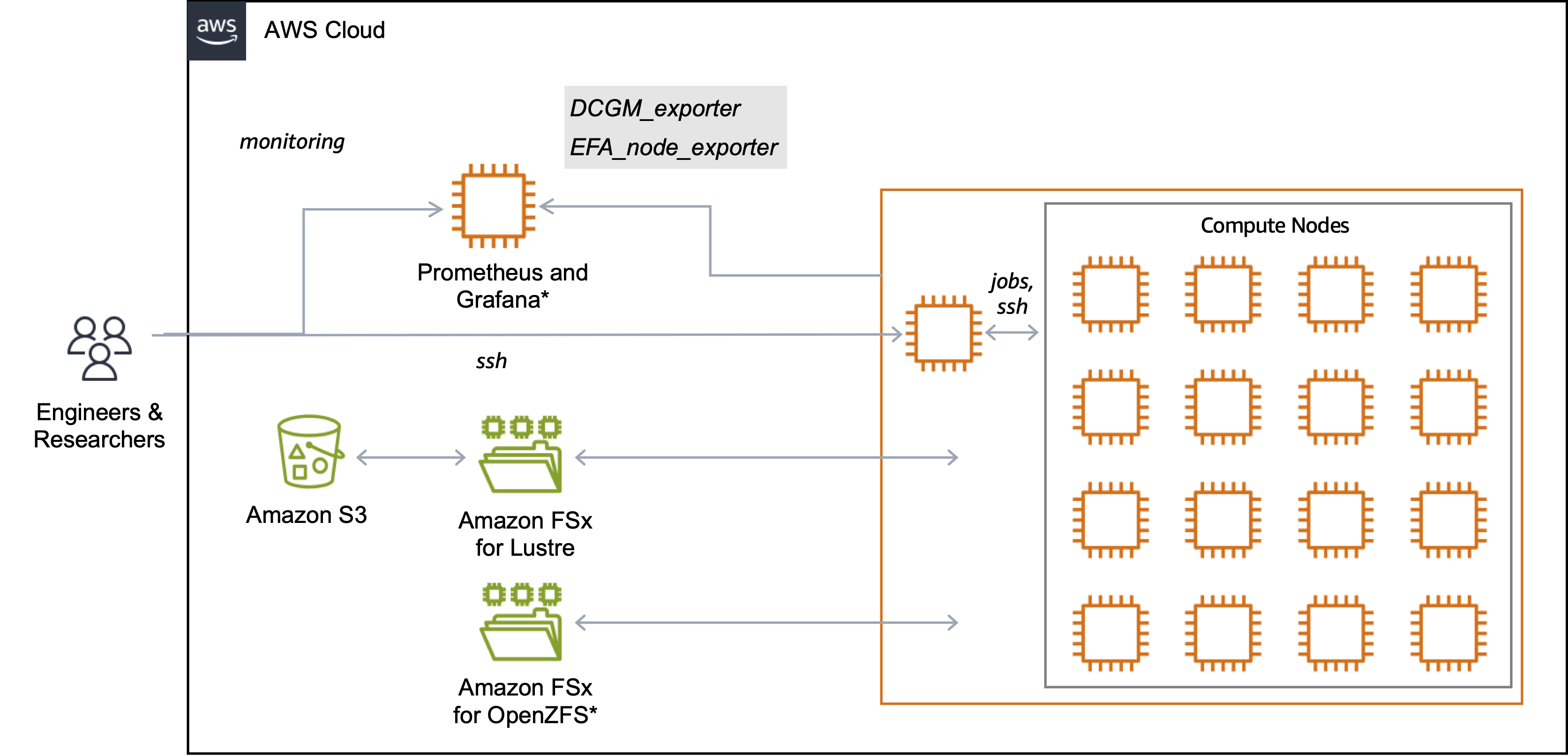
このレファレンスアーキテクチャはベースインフラストラクチャスタックと、クラスタ本体から構成されます。
ベースインフラストラクチャスタックは CloudFormationテンプレートとして利用可能で、最小限の労力デプロイ可能です。このテンプレートは、最適化されたネットワーク設定を持つ専用VPCを自動的に設定し、トレーニングデータ用の高性能なAmazon FSx for Lustre Filesystemを実装します(オプショナルで共有ホームディレクトリ用に FSx for OpenZFS Filesystem を Deploy することも可能です)。また、このインフラストラクチャスタックではパフォーマンスとコスト効率のバランスを取る階層型ストレージアプローチを採用しています。基盤となるのは、トレーニングデータとチェックポイントの長期ストレージを提供するAmazon S3です。トレーニング中のストレージボトルネックを防ぐため、S3バケットは データリポジトリアソシエーション(DRA)を通じてLustreファイルシステムとリンクされています。DRAは、Amazon S3とFSx for Lustre間の自動的で透過的なデータ転送を可能にし、手動コピーなしでS3データへの高性能アクセスを実現します。
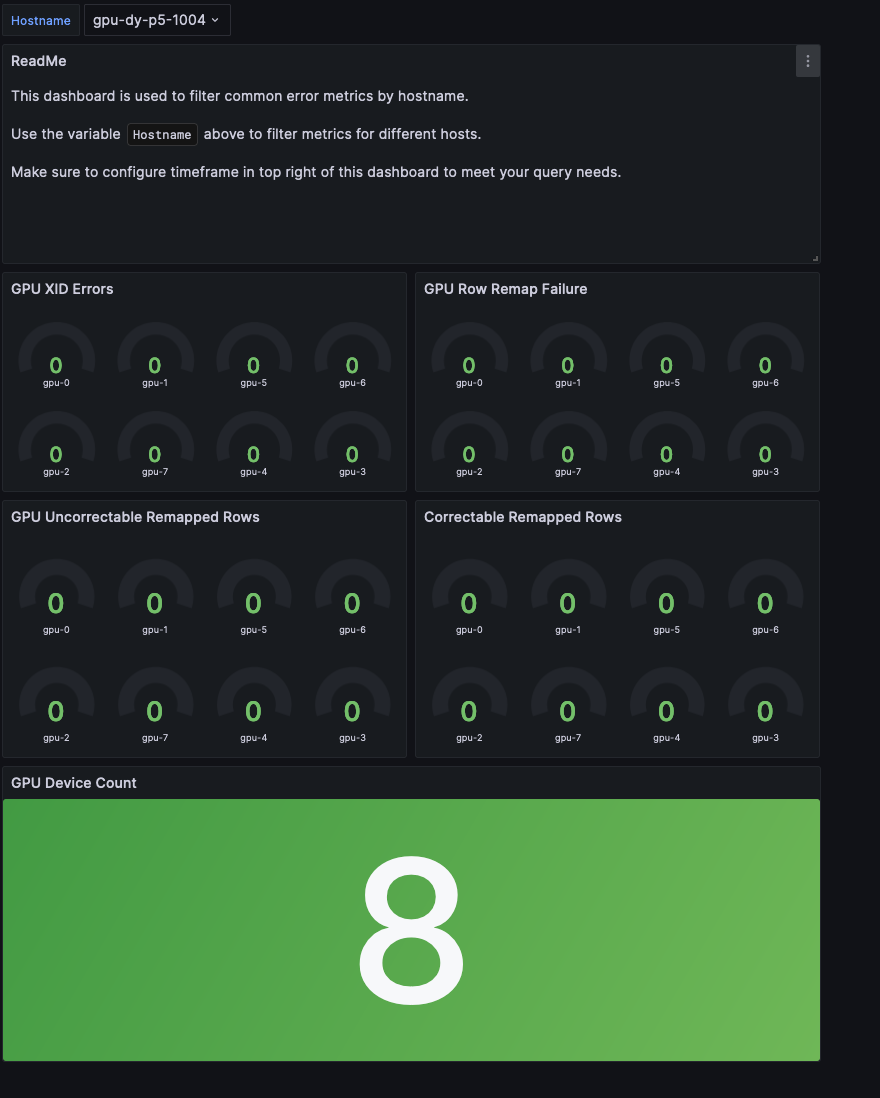
オプションのモニタリングインフラストラクチャは、 Amazon Managed Service for PrometheusとAmazon Managed Grafana(または EC2上で実行されるセルフマネージドGrafanaサービス)を組み合わせて、包括的な可観測性を提供します。GPUメトリクスのDCGM ExporterとネットワークメトリクスのEFA Exporterを統合し、システムの健全性とパフォーマンスのリアルタイムモニタリングを可能にしました。このセットアップにより、GPUの健全性、ネットワークパフォーマンス、トレーニングの進捗を継続的に追跡し、Grafanaダッシュボードを通じて異常の自動アラートを実現します。例えば、 GPU Health Dashboardは、Uncorrectable Remapped Rows、Correctable Remapped Rows、XID Error Codes、Row Remap Failure、Thermal violations、Missing GPUs(Nvidia-SMIから)などの一般的なGPUエラーのメトリクスを提供し、ユーザーがハードウェア障害を可能な限り迅速に特定できるようにします。
詳細なDeployment Guide とワークショップ
リファレンスアーキテクチャも、チームが使用方法を知らなければ役に立ちません。GENIACの成功の重要な要素は、 再現可能なデプロイメントガイドとワークショップを通じた知識の共有でした。
2024年10月3日、AWS JapanとWWSO Frameworksチームは、GENIAC第2サイクル参加者向けの大規模なワークショップを開催し、米国からのFrameworksチームメンバーを招いて、AWSでの基盤モデルトレーニングのベストプラクティスを共有しました。
このイベントには80名以上の参加者を迎え、講義、ハンズオンラボ、グループディスカッションを組み合わせた包括的なプログラムを提供し、CSAT 4.75 という高い評価をいただきました。講義セッションでは、インフラストラクチャの基礎、AWS ParallelCluster、Amazon EKS、Amazon SageMaker HyperPodなどのオーケストレーションオプション、AWSを使用した大規模基盤モデル(FM)の構築とトレーニングに必要なソフトウェアコンポーネントについて説明しました。セッションでは、FM開発における実践的な課題—大規模なコンピューティング要件、スケーラブルなネットワーキング、高スループットストレージを取り上げ、それらを適切なAWSサービスとベストプラクティスにマッピングしました( 講義セッションのスライドデッキ)。別のセッションではベストプラクティスに焦点を当て、参加者はPrometheusとGrafanaを使用したパフォーマンスダッシュボードの設定、EFA Trafficのモニタリング、NVIDIAのDCGMツールキットとFrameworksチームの2000台のP5インスタンスを持つクラスター管理経験に基づくカスタムGrafanaダッシュボードを使用したGPU障害のトラブルシューティングを学びました。
さらに、WWSOチームはParallelCluster( Machine Learning on AWS ParallelCluster)とHyperPod( Amazon SageMaker HyperPod Workshop)の双方に対応したワークショップを準備しました。これらの資料を使用して、参加者はSlurmを使用したトレーニングクラスターのデプロイ、FSx for LustreとFSx for OpenZFSを含むファイルシステム、マルチノードPyTorch分散トレーニングの実行を実践しました。ワークショップの別のセグメントでは可観測性とパフォーマンスチューニングに焦点を当て、参加者はリソース使用率、ネットワークスループット(EFAトラフィック)、システムの健全性のモニタリング方法を学びました。これらのセッションを通して、顧客とサポートするAWSエンジニアの両方が、共有の知識基盤とベストプラクティスのツールキットを確立しました。学んだすべての資産と知識を使用して、顧客はリードSAと共に、特定のユースケースに合わせたクラスターを同時にデプロイしました。このステップはオンボーディングセッションと呼ばれます。これらのセッション中、各リードSAは顧客がクラスターをデプロイし、NCCLテストを使用してクラスターの機能をテストし、通話中に発生した技術的な質問に対処できることを確認しました。
顧客のフィードバック
データ入力の課題を根本的に解決するため、通常項目にはSLMとLLMを使用した2段階推論と自律学習、詳細項目には10万件の合成データサンプルを使用したVLMによる視覚学習を適用し、処理精度とコスト効率を大幅に改善しました。また、Amazon EC2 P5インスタンスを活用して研究開発効率を向上させました。これらの野心的な取り組みは、AWSを含む多くの方々のサポートによって可能になりました。広範なサポートに深く感謝いたします。
井上 拓真 – 執行役員CTO, AI Inside
フューチャーはGENIACでの日本語とソフトウェア開発に特化した大規模言語モデルの開発においてAWSを選択しました。複数ノードを用いた大規模なモデル学習ではノード間通信等の環境設定に関する不安がありましたが、AWSではParallelCulsterをはじめとして周辺ツールが充実していたことに加え、AWSのソリューションアーキテクトの方々からも強力なサポートを頂き、迅速に大規模な学習を開始することができました。
森下 睦 – Chief Research Engineer, Future Corporation
結果と今後の展望
このブログで述べたような包括的な支援体制ににより、AWSは 12の顧客が1日で127台以上のP5インスタンスと24台のTrn1を立ち上げる支援を提供できました。クラスタ上での6ヶ月の学習を通して、各事業者は基盤モデルの開発を行いました。 GENIACは、大規模な基盤モデルのトレーニングが本質的に組織的な課題であり、単なるハードウェアの問題ではないことを実証しました。構造化されたサポート、再現可能なテンプレート、クロスファンクショナルなコラボレーションを通じて、小さなチームでもクラウドで大規模なワークロードを成功裏に実行することができます。
AWSはすでにGENIACの次のサイクルの準備を開始しています。その一環として、AWSは4月3日に東京で基盤モデルビルダーにハンズオン体験とアーキテクチャガイダンスを提供するための技術イベントを開催しました。50名以上の参加者を集めたこのイベントは、スケーラブルで回復力のある生成AIインフラストラクチャをサポートするAWSの取り組みを示しました。

このイベントでは、GENIACのためのAWSの技術的エンゲージメントモデルと、 LLM Development Support Programや Generative AI Acceleratorなどの他のサポートメカニズムが紹介されました。イベント午前中には SageMaker HyperPod に関するワークショップが行われ、参加者はマルチノードGPUクラスターの立ち上げ、分散PyTorchトレーニング、オブザーバビリティを手を動かしながら学びました。午後に行われたセッションは、コンテナ化されたML、分散トレーニング戦略、AWSのカスタムシリコンソリューションなどの重要なトピックをカバーしました。またClassmethod Inc. からも実践的なHyperPodの洞察を共有するセッションがありました。このイベントは、インフラストラクチャからデプロイメントツールまで、AWSのエンドツーエンドのGenAIサポートエコシステムを紹介し、GENIAC第3サイクルの基盤を築きました。AWSが基盤モデル開発のサポートを拡大し続ける中、GENIACの成功は、組織が基盤モデル開発を効果的に構築しスケールするための青写真として機能します。
この記事は、AWS GENIAC Cycle2のコアテックメンバーである 小林正人、 一柳健太、 白澤聡、Accelerated Computing Specialist 木内 舞、ならびにリードソリューションアーキテクトの 宮本大輔、 針原佳貴、 佐々木啓、 常世大史によって寄稿されました。エグゼクティブスポンサーシップとして 安田俊彦が支援を提供しました。また、AWS在籍時にコアメンバーおよびリードソリューションアーキテクトとして 畑浩史 氏、 尾原颯 氏、 卜部達也 氏も支援を提供しました。WWSO Frameworks チームのメンバーである Maxime Hugues、 Matthew Nightingale、 Aman Shanbhag、 Alex Iankoulski、 Anoop Saha、 Yashesh Shroff、 Shubha Kumbadakone も広範な技術支援を提供しました。 Pierre-Yves Aquilanti 氏 もAWS 在職中に技術支援を提供しました。
著者について
渡辺啓太は、AWS WWSO FrameworksチームのSenior Specialist Solutions Architectで、基盤モデルの学習と推論を専門としています。AWS 入社前は、E コマース業界で Machine Learning Researcherとして商品検索向けの画像検索システムの開発に従事していました。GENIAC における技術面のリードを担当しています。
井阪大は、AWS WWSO Frameworksチームの Principal Business Development で、機械学習と人工知能ソリューションを専門としています。GENIAC の立ち上げ当初から関与しており、AWS の生成系 AI 製品の市場戦略をリードしています。
小林正人は、2013年からAWS Japanのソリューションアーキテクト(SA)として、お客様のクラウド活用を技術的な側面・ビジネス的な側面の双方から支援してきました。2024年からは特定のお客様を担当するチームを離れ、技術領域やサービスを担当するスペシャリストSAチームをリードする役割に変わりました。好きな温泉の泉質は、酸性-カルシウム-硫酸塩泉です。