Cos'è la RAG (generazione potenziata da recupero dati)?
Cos'è la generazione potenziata da recupero dati?
La generazione potenziata da recupero dati (RAG) è il processo di ottimizzazione dell'output di un modello linguistico di grandi dimensioni, in modo che faccia riferimento a una base di conoscenza autorevole al di fuori delle sue origini dati di addestramento prima di generare una risposta. I modelli linguistici di grandi dimensioni (LLM) vengono addestrati su vasti volumi di dati e utilizzano miliardi di parametri per generare output originali per attività come rispondere a domande, tradurre lingue e completare frasi. La RAG estende le capacità già avanzate degli LLM a domini specifici o alla knowledge base interna di un'organizzazione, il tutto senza la necessità di riaddestrare il modello. È un approccio conveniente per migliorare l'output dell'LLM in modo che rimanga pertinente, accurato e utile in vari contesti.
Perché la generazione potenziata da recupero dati è importante?
Gli LLM sono una tecnologia chiave di intelligenza artificiale (IA) che alimenta chatbot intelligenti e altre applicazioni di elaborazione del linguaggio naturale (NLP). L'obiettivo è creare bot in grado di rispondere alle domande degli utenti in vari contesti incrociando fonti di conoscenza autorevoli. Sfortunatamente, la natura della tecnologia LLM introduce imprevedibilità nelle risposte LLM. Inoltre, i dati di addestramento degli LLM sono statici e stabiliscono una data limite per le conoscenze in loro possesso.
Le sfide note degli LLM includono:
- Presentazione di informazioni false quando non si ha la risposta.
- Presentazione di informazioni obsolete o generiche quando l'utente si aspetta una risposta specifica e attuale.
- Creazione di una risposta da fonti non autorevoli.
- Creazione di risposte imprecise a causa della confusione terminologica, in cui diverse fonti di addestramento utilizzano la stessa terminologia per parlare di cose diverse.
Puoi pensare al modello linguistico di grandi dimensioni come a un nuovo dipendente troppo entusiasta che si rifiuta di aggiornarsi sugli eventi attuali ma risponderà sempre a ogni domanda con assoluta fiducia. Sfortunatamente, un simile atteggiamento può influire negativamente sulla fiducia degli utenti e i tuoi chatbot non dovrebbero emularlo.
La RAG è un approccio per risolvere alcune di queste sfide. Reindirizza l'LLM per recuperare informazioni pertinenti da fonti di conoscenza autorevoli e predeterminate. Le organizzazioni hanno un maggiore controllo sull'output di testo generato e gli utenti ottengono informazioni su come l'LLM genera la risposta.
Quali sono i vantaggi della generazione potenziata da recupero dati?
La tecnologia RAG offre diversi vantaggi agli sforzi di IA generativa di un'organizzazione.
Implementazione conveniente
Lo sviluppo di chatbot inizia in genere utilizzando un modello di fondazione. I modelli di fondazione (FM) sono modelli LLM accessibili tramite API addestrati su un ampio spettro di dati generalizzati e senza etichette. I costi computazionali e finanziari del riaddestramento degli FM per informazioni specifiche sull'organizzazione o sul dominio sono elevati. La RAG è un approccio più conveniente per l'introduzione di nuovi dati nell'LLM. Rende la tecnologia di intelligenza artificiale generativa (IA generativa) più ampiamente accessibile e utilizzabile.
Informazioni attuali
Anche se le origini dati di addestramento originali per un LLM sono adatte alle tue esigenze, è difficile mantenere la pertinenza. La RAG consente agli sviluppatori di fornire le ricerche, le statistiche o le notizie più recenti ai modelli generativi. Possono utilizzare la RAG per collegare l'LLM direttamente ai feed live dei social media, ai siti di notizie o ad altre fonti di informazioni aggiornate di frequente. L'LLM può quindi fornire le informazioni più recenti agli utenti.
Maggiore fiducia da parte degli utenti
La RAG consente all'LLM di presentare informazioni accurate con l'attribuzione della fonte. L'output può includere citazioni o riferimenti a fonti. Gli utenti possono anche cercare personalmente i documenti di origine se necessitano di ulteriori chiarimenti o maggiori dettagli. Ciò può aumentare la fiducia e la sicurezza nella tua soluzione di IA generativa.
Maggiore controllo da parte degli sviluppatori
Con la RAG, gli sviluppatori possono testare e migliorare le loro applicazioni di chat in modo più efficiente. Possono controllare e modificare le fonti di informazioni dell'LLM per adattarle ai mutevoli requisiti o all'utilizzo interfunzionale. Gli sviluppatori possono anche limitare il recupero di informazioni sensibili a diversi livelli di autorizzazione e garantire che l'LLM generi risposte appropriate. Inoltre, possono anche risolvere i problemi e apportare correzioni se l'LLM fa riferimento a fonti di informazioni errate per domande specifiche. Le organizzazioni possono implementare la tecnologia di IA generativa con maggiore sicurezza per una gamma più ampia di applicazioni.
Come funziona la generazione potenziata da recupero dati?
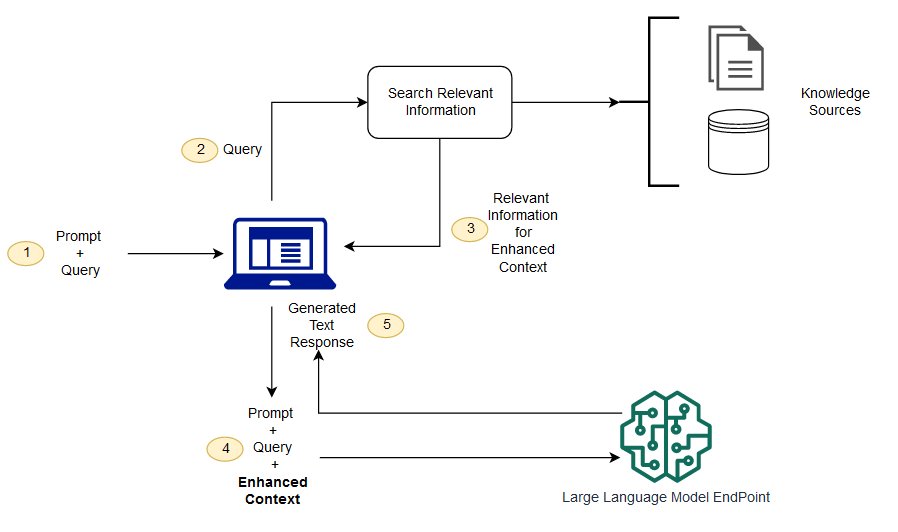
Senza la generazione potenziata da recupero dati (RAG), l'LLM prende l'input dell'utente e crea una risposta in base alle informazioni su cui è stato addestrato o su ciò che già conosce. Con la RAG, viene introdotto un componente di recupero delle informazioni che utilizza l'input dell'utente per estrarre prima le informazioni da una nuova origine dati. La richiesta dell'utente e le informazioni pertinenti vengono entrambe fornite all'LLM. L'LLM utilizza le nuove conoscenze e i suoi dati di addestramento per creare risposte migliori. Le seguenti sezioni forniscono una panoramica del processo.
Creazione di dati esterni
I nuovi dati al di fuori del set di dati di addestramento originale dell'LLM sono chiamati dati esterni. Possono provenire da più origini dati, come API, database o archivi di documenti e possono esistere in vari formati come file, record di database o testo lungo. Un'altra tecnica di IA, chiamata embedding dei modelli di linguaggio, converte i dati in rappresentazioni numeriche e li archivia in un database vettoriale. Questo processo crea una libreria di conoscenze che i modelli di IA generativa possono comprendere.
Recupero di informazioni pertinenti
Il passaggio successivo consiste nell'eseguire una ricerca di pertinenza. La query dell'utente viene convertita in una rappresentazione vettoriale e abbinata ai database vettoriali. Ad esempio, considera un chatbot intelligente in grado di rispondere alle domande sulle risorse umane per un'organizzazione. Se un dipendente chiede: “Quante ferie annuali ho?” il sistema recupererà i documenti relativi alla politica delle ferie annuali insieme al registro delle ferie passate del singolo dipendente. Questi documenti specifici verranno restituiti perché sono molto pertinenti a ciò che il dipendente ha inserito. La rilevanza è stata calcolata e stabilita utilizzando calcoli e rappresentazioni matematiche vettoriali.
Aumento del prompt LLM
Successivamente, il modello RAG aumenta l'input (o i prompt) dell'utente aggiungendo i dati recuperati pertinenti nel contesto. Questa fase utilizza tecniche di progettazione dei prompt per comunicare efficacemente con l'LLM. Il prompt potenziato consente ai modelli linguistici di grandi dimensioni di generare una risposta accurata alle domande degli utenti.
Aggiornamento di dati esterni
La domanda successiva potrebbe essere: cosa succede se i dati esterni diventano obsoleti? Per mantenere aggiornate le informazioni per il recupero, aggiorna in modo asincrono i documenti e la rappresentazione di embedding dei documenti. È possibile farlo tramite processi automatizzati in tempo reale o elaborazione periodica in batch. Questa è una sfida comune nell'analisi dei dati: è possibile utilizzare diversi approcci scientifici dei dati per la gestione delle modifiche.
Il diagramma seguente mostra il flusso concettuale dell'utilizzo di RAG con gli LLM.
Qual è la differenza tra generazione potenziata da recupero dati e ricerca semantica?
La ricerca semantica migliora i risultati della RAG per le organizzazioni che desiderano aggiungere vaste fonti di conoscenza esterne alle proprie applicazioni LLM. Le aziende moderne archiviano grosse quantità di informazioni, come manuali, domande frequenti, report di ricerca, guide all'assistenza clienti e archivi di documentazione sulle risorse umane, su vari sistemi. Il recupero del contesto è impegnativo su larga scala e di conseguenza riduce la qualità dell'output generativo.
Le tecnologie di ricerca semantica possono scansionare grandi database di informazioni disparate e recuperare i dati in modo più accurato. Ad esempio, possono rispondere a domande come: “Quanto è stato speso per le riparazioni dei macchinari l'anno scorso?” associando la domanda ai documenti pertinenti e restituendo un testo specifico anziché i risultati della ricerca. Gli sviluppatori possono quindi utilizzare questa risposta per fornire più contesto all'LLM.
Le soluzioni di ricerca convenzionali o per parole chiave nella RAG producono risultati limitati per attività ad alta intensità di conoscenza. Gli sviluppatori devono inoltre occuparsi dell'embedding di parole, della suddivisione in gruppi di documenti e di altre complessità mentre preparano manualmente i dati. Al contrario, le tecnologie di ricerca semantica svolgono tutto il lavoro di preparazione della knowledge base in modo che gli sviluppatori non debbano farlo. Generano inoltre passaggi semanticamente rilevanti e parole chiave ordinate per rilevanza per massimizzare la qualità del payload della RAG.
In che modo AWS può supportare i tuoi requisiti di generazione potenziata da recupero dati?
Amazon Bedrock è un servizio completamente gestito che offre una scelta di modelli di fondazione ad alte prestazioni insieme a un'ampia gamma di funzionalità necessarie per creare applicazioni di IA generativa, semplificando lo sviluppo e mantenendo privacy e sicurezza. Con le Knowledge Base per Amazon Bedrock, puoi connettere gli FM alle tue origini dati per la RAG in pochi clic. Le conversioni vettoriali, i recuperi e la migliore generazione di output vengono tutti gestiti automaticamente.
Per le organizzazioni che gestiscono le proprie RAG, Amazon Kendra è un servizio di ricerca aziendale estremamente accurato basato sul machine learning. Fornisce un'API Retrieve di Kendra ottimizzata che puoi utilizzare con il ranker semantico ad alta precisione di Amazon Kendra come strumento di recupero aziendale per i tuoi flussi di lavoro RAG. Ad esempio, con l'API Retrieve, puoi:
- recuperare fino a 100 passaggi semanticamente rilevanti composti da un massimo di 200 parole simboliche ciascuno, ordinati per rilevanza;
- utilizzare connettori predefiniti per le tecnologie di dati più diffuse come Amazon Simple Storage Service, SharePoint, Confluence e altri siti web;
- supportare un'ampia gamma di formati di documenti come HTML, Word, PowerPoint, PDF, Excel e file di testo;
- filtrare le risposte in base ai documenti consentiti dalle autorizzazioni dell'utente finale.
Amazon offre anche opzioni per le organizzazioni che desiderano creare soluzioni di IA generativa più personalizzate. Amazon SageMaker JumpStart è un hub ML con FM, algoritmi integrati e soluzioni ML predefinite che puoi implementare con pochi clic. È possibile velocizzare l'implementazione della RAG facendo riferimento ai notebook SageMaker esistenti e agli esempi di codice.
Inizia a usare la generazione potenziata da recupero dati su AWS creando subito un account gratuito
Fasi successive su AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages