亚马逊AWS官方博客
使用 pgpool-II 与 Amazon Aurora for PostgreSQL 构建高可用读写分离架构
 |
在当今数据密集型应用中,数据库的高可用性和性能至关重要。PostgreSQL 作为一个强大的开源关系型数据库,得到了越来越广泛的应用。本文将详细介绍如何结合 Amazon Aurora for PostgreSQL 和 pgpool-II 中间件,构建一个既高可用又高性能的数据库架构,实现自动读写分离、负载均衡和故障自动转移等功能。
Amazon Aurora for PostgreSQL 架构概述
Amazon Aurora for PostgreSQL 是亚马逊云科技提供的企业级关系型数据库服务,它采用了创新的架构设计,具有以下特点:
- 存储与计算分离:Aurora 将存储层与数据库引擎分离,存储层由 6 个副本分布在 3 个可用区,多可用区部署情况下提供 99% 的可用性 SLA。
- 集群架构:一个 Aurora 集群包含一个主实例和最多 15 个只读副本实例。
- 共享存储模型:所有实例共享同一个分布式存储卷,显著降低了传统复制的延迟。
- 快速故障转移:副本实例通常可以在 30 秒内提升为主实例,大大减少了故障恢复时间。
Aurora 提供了多种专用端点,常用的有 2 个:
- 集群端点(Cluster Endpoint):
- 始终连接到当前的主实例(写入器)
- 主要用途:处理所有写操作和需要强一致性的读操作
- 读取器端点(Reader Endpoint):
- 在所有可用的只读副本之间进行负载均衡
- 主要用途:处理只读查询,提高读取性能
如果需要实现读写分离,应用层逻辑需要感知读、写 endpoint 并且把读写请求分别路由。
架构设计:pgpool-II 与 Amazon Aurora for PostgreSQL 集成
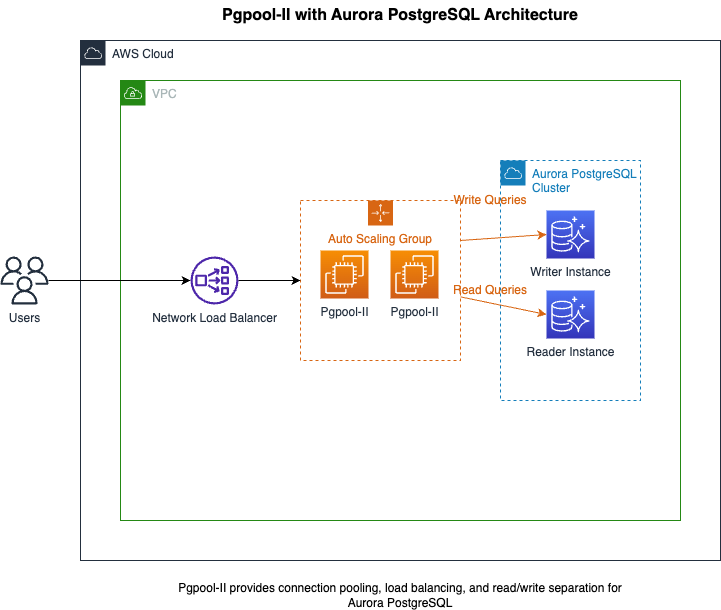
pgpool-Aurora 架构
我们设计的架构包含以下核心组件:
- Amazon Aurora for PostgreSQL 集群:提供高可用、自动扩展的数据库服务,包含一个写入节点和多个只读节点
- pgpool-II 服务器集群:部署在 Auto Scaling Group 中,提供连接池、负载均衡和读写分离功能
- 网络负载均衡器(NLB):分发客户端连接到健康的 pgpool-II 实例
- pgdoctor:监控 pgpool-II 实例的健康状态,为 NLB 提供健康检查端点,只有可以成功连接后端数据库的 pgpool 实例才可以作为 target,并非仅仅是实例和进程层面的探活
pgpool-II 如何实现自动读写分离
pgpool-II 是一个位于 PostgreSQL 数据库和客户端应用之间的中间件,可以视作 PostgreSQL 的 7 层负载均衡器。其对 Amazon Aurora for PostgreSQL 有特别的支持(参考官方文档中的 Aurora 示例),pgpool-II 通过以下机制实现连接池和自动读写分离:
- 连接配置:
- pgpool-II 配置为同时连接 Aurora 的集群端点(主实例)和读取器端点(只读副本)
- 在配置文件中,将 cluster endpoint 标记为可写节点,将 reader endpoint 标记为只读节点
- 查询分析与路由:
- pgpool-II 会解析 SQL 语句,识别查询类型(SELECT、INSERT、UPDATE、DELETE 等)
- 写操作(INSERT、UPDATE、DELETE)自动路由到主实例
- 读操作(SELECT)根据负载均衡策略路由到只读副本
- 负载均衡机制:
- pgpool-II 通过 backend_weight 参数为每个后端服务器设置权重
- 查询分发基于这些权重,权重越高的服务器接收的查询越多
- 可以通过设置较低的主实例权重和较高的只读副本权重,将大部分读查询引导到只读副本
- 负载均衡级别:
- pgpool-II 支持两种级别的负载均衡:会话级别和语句级别
- 会话级别:整个会话的所有查询都路由到同一个后端服务器
- 语句级别:每个查询语句都可能路由到不同的后端服务器
- 通过配置参数 statement_level_load_balance 来控制是否启用语句级别负载均衡
- 会话级控制:
- 支持通过会话变量控制查询路由行为
- 例如,可以设置某些会话始终使用主实例,适用于需要强一致性的场景
- 事务处理:
- 在事务内的所有查询(包括 SELECT)都会路由到主实例,确保事务一致性
- 事务外的 SELECT 语句会根据负载均衡策略路由到只读副本
- 可通过 disable_load_balance_on_write 参数控制写操作后的负载均衡行为
- 该参数用于指定在出现写查询后的负载均衡行为。此参数在流复制模式下特别有用。当写查询发送到主服务器时,这些更改会应用到备用服务器,但存在时间延迟。因此,如果客户端在写查询后立即读取同一行,可能无法看到该行的最新值。如果这是个问题,客户端应始终从主服务器读取数据。然而,这实际上禁用了负载均衡,导致性能下降。该参数允许在非集群感知应用兼容性和性能之间进行精细调整。
参数可选值:- off
如果此参数设置为 off,即使出现写查询,读查询仍然会进行负载均衡。这提供了最佳的负载均衡性能,但客户端可能会看到较旧的数据。这对于 PostgreSQL 参数 synchronous_commit = ‘remote_apply’ 的环境或原生复制模式很有用,因为在这些环境中没有复制延迟。 - transaction(默认)
如果此参数设置为 transaction,且写查询出现在显式事务中,后续读查询将不会进行负载均衡,直到事务结束。请注意,不在显式事务中的读查询不受此参数影响。这个设置在大多数情况下提供了最佳平衡,建议从此设置开始。这是默认值,也是 Pgpool-II 3.7 或更早版本的相同行为。 - trans_transaction
如果此参数设置为 trans_transaction,且写查询出现在显式事务中,该事务内和后续显式事务中的读查询将不会进行负载均衡,直到会话结束。因此,此参数对老应用程序更安全,但性能低于 transaction。请注意,不在显式事务中的读查询不受此参数影响。 - always
如果此参数设置为 always 且写查询出现,后续读查询将不会进行负载均衡,直到会话结束,无论它们是否在显式事务中。这提供了与非集群感知应用程序的最高兼容性,但性能最低。 - dml_adaptive
如果此参数设置为 dml_adaptive,Pgpool-II 会跟踪显式事务中写语句引用的每个表,并且如果之前在同一事务中修改了读取查询的表,则不会对后续读查询进行负载均衡。可以使用 dml_adaptive_object_relationship_list 配置依赖于这些表的函数、触发器和视图。
- off
- 该参数用于指定在出现写查询后的负载均衡行为。此参数在流复制模式下特别有用。当写查询发送到主服务器时,这些更改会应用到备用服务器,但存在时间延迟。因此,如果客户端在写查询后立即读取同一行,可能无法看到该行的最新值。如果这是个问题,客户端应始终从主服务器读取数据。然而,这实际上禁用了负载均衡,导致性能下降。该参数允许在非集群感知应用兼容性和性能之间进行精细调整。
实现方案:使用亚马逊云科技 CDK 自动化部署
我们的实现分为两个主要部分:
- 创建预配置的 pgpool-II AMI,以方便创建 Autoscaling Group 的 launch template
- 使用亚马逊云科技 CDK 部署完整架构
第一部分:创建 pgpool-II AMI
首先,我们需要创建一个包含 pgpool-II 和 pgdoctor 的 Amazon Machine Image (AMI)。我们提供了一个 Python 脚本 create_pgpool_AMI.py 来自动化这个过程:
这个脚本执行以下关键操作:
- 基础环境准备:
- 查找并使用最新的 Amazon Linux 2023 AMI 作为基础镜像
- 创建临时安全组和 EC2 实例
- 配置必要的网络访问权限
- pgpool-II 安装与配置:
- 编译、安装 pgpool-II 4.5.6 版本及其依赖项
- 创建 pgpool 系统用户和必要的目录结构
- 生成初始化的 pgpool.conf 配置文件,包含针对 Amazon Aurora for PostgreSQL 优化的设置
- 配置日志、连接池和负载均衡参数
- pgdoctor 健康检查服务安装:
- 从 GitHub 克隆并编译 pgdoctor 源码
- 配置 pgdoctor 以监控 pgpool-II 与 Aurora 的连接状态
- 设置 systemd 服务确保 pgdoctor 自动启动
- 系统服务配置:
- 创建并启用 pgpool.service 和 pgdoctor.service
- 配置服务依赖关系和自动重启策略
- 设置适当的文件权限和所有权
- AMI 创建与资源清理:
- 等待安装和配置完成
- 创建包含所有配置的 AMI
- 清理临时资源(EC2 实例和安全组)
脚本生成的 pgpool.conf 包含以下关键配置:
- 启用负载均衡模式和语句级负载均衡
- 配置后端连接到 Aurora 集群端点和读取器端点
- 设置主实例和只读副本的权重(1:10 比例)
- 禁用 pgpool-II 内置的健康检查和故障转移功能,由 Aurora 和 NLB 处理
- 配置连接池参数和日志设置
脚本执行完成后,会输出创建的 AMI ID,记录这个 ID 用于后续 CDK 部署步骤。
第二部分:使用 CDK 部署架构
有了预配置的 AMI 后,我们使用亚马逊云科技 CDK 来部署完整的架构。CDK 代码定义了所有必要的亚马逊云资源,包括:
- VPC 和子网:如果未指定现有 VPC,则创建新的 VPC 和子网
- Amazon Aurora for PostgreSQL 集群:创建具有指定实例类型和副本数量的数据库集群
- 安全组:配置适当的安全规则,确保组件间的安全通信
- Auto Scaling Group:使用预配置的 AMI 部署 pgpool-II 实例
- 网络负载均衡器:配置监听器和目标组,将流量分发到健康的 pgpool-II 实例
- IAM 角色和策略:授予必要的权限,如访问 Secrets Manager 中的数据库凭证
- Secrets Manager:自动生成并安全存储 Aurora 数据库凭证
CDK 堆栈通过以下方式管理 Aurora 数据库凭证:
- 自动生成安全密码
- Aurora 集群使用生成的凭证
- pgpool-II 实例动态获取凭证:
- 授予 pgpool-II 实例的 IAM 角色读取 Secrets Manager 的权限
- 在实例启动时,通过 UserData 脚本从 Secrets Manager 获取凭证
- 使用获取的凭证更新 pgdoctor 配置文件
这种方式确保了数据库凭证的安全管理,避免了硬编码密码的安全风险。
部署步骤
前提条件
- 亚马逊云账户和适当的权限
- 安装 Python 3.6+
- 安装 aws CLI 并配置凭证
- 安装 Node.js 10.13.0+(CDK 依赖)
步骤 1:获取项目代码
首先,从 GitHub 仓库获取项目代码:
步骤 2:创建 pgpool-II AMI
**重要说明**:这些参数仅在创建 AMI 时使用,用于初始化 pgpool-II 和 pgdoctor 的配置文件。如果您计划使用 CDK 部署完整架构,这些初始参数将在部署过程中被 CDK 自动生成的实际 Aurora 端点和凭据覆盖。因此,在创建 AMI 时,您可以使用默认值,无需提供实际的数据库参数。如果只是使用该脚本构建 AMI 用于构建自己的 launch template,可以按照实际数据库的参数指定。
脚本执行完成后,会输出创建的 AMI ID,记录这个 ID 用于后续步骤。
步骤 3:部署 CDK 堆栈
部署过程中,CDK 会创建所有必要的资源,并在完成后输出重要的信息,如 NLB 端点和 Aurora 集群端点。
pgpool-II 配置优化
在我们的 AMI 中,pgpool-II 配置了以下关键参数,这些配置专门针对 Amazon Aurora for PostgreSQL 环境进行了优化:
这些配置针对 Amazon Aurora for PostgreSQL 环境进行了特别优化:
- 禁用了 pgpool-II 的复制延迟检查和健康检查:
- Aurora 有自己的复制机制,不需要 pgpool-II 进行复制状态监控
- 健康检查由 pgdoctor 和 NLB 处理
- 禁用了 pgpool-II 的故障转移功能:
- Aurora 有自己的自动故障转移机制
- 通过 DISALLOW_TO_FAILOVER 标志防止 pgpool-II 尝试故障转移
- 优化了负载均衡权重:
- 主实例权重设为 1,读取副本权重设为 10(可根据实际情况设置)
- 这样大部分读查询会路由到读取副本,减轻主实例负担
- 启用了语句级负载均衡:
- 通过 statement_level_load_balance = on 启用
- 允许在同一会话中的不同查询被路由到不同的后端服务器
- 事务级写保护:
- 通过 disable_load_balance_on_write = ‘transaction’ 设置
- 确保在事务中执行写操作后,该事务内的所有后续查询都发送到主节点
健康检查与故障转移
pgpool-II 通过定期健康检查监控 Aurora 实例的状态:
- 健康检查机制:
- 定期向每个后端发送简单查询(如 SELECT 1)
- 检查复制延迟状态
- 监控连接可用性
- 故障检测与处理:
- 当检测到主实例故障时,pgpool-II 会等待 Aurora 自动故障转移完成
- 一旦新的主实例可用,pgpool-II 会自动更新其内部路由表
- 客户端应用无需感知后端变化,继续通过 pgpool-II 访问数据库
- pgdoctor 集成:
- pgdoctor 提供 HTTP 健康检查端点(8071 端口),供 NLB 监控 pgpool-II 实例的健康状态
- 重要:pgdoctor 执行的是数据库级别的健康检查,而非简单的进程检查
- 当 pgdoctor 返回 HTTP 200 状态码时,表示通过该 pgpool-II 节点可以正常访问后端 Aurora 数据库
- 如果后端 Aurora 数据库连接失败,即使 pgpool-II 进程正在运行,pgdoctor 也会返回错误状态,这确保了 NLB 只将流量路由到能够正常处理数据库请求的 pgpool-II 实例
架构优势
这种架构具有以下优势:
- 高可用性:组件部署在多个可用区,单点故障不会影响整体服务
- 自动扩展:根据负载自动调整 pgpool-II 实例数量
- 读写分离:自动将读请求分发到只读节点,写请求发送到主节点
- 连接池:减少数据库连接开销,提高资源利用率
- 自动故障转移:检测并自动处理故障节点
- 简化应用开发:应用程序只需连接到单一端点,无需处理读写分离逻辑
监控与告警
我们建议配置以下监控和告警:
- CloudWatch 指标:监控 pgpool-II 实例和 Aurora 集群的关键指标
- CloudWatch 告警:设置告警通知异常情况
- Enhanced Monitoring:启用 Aurora 增强监控,获取更详细的指标
- Prometheus 集成:社区项目 pgpool2_exporter 提供二进制和容器两种部署方式, 收集的关键指标包括:
- pgpool2_backend_status:后端数据库节点状态
- pgpool2_connections:当前连接数
- pgpool2_pool_cache_hit_ratio:连接池缓存命中率
- pgpool2_backend_weight:后端节点权重
- pgpool2_health_check_stats:健康检查统计
结论
使用 pgpool-II 与 Amazon Aurora for PostgreSQL 构建的高可用读写分离架构为企业级应用提供了一个强大、可靠且易于部署的数据库解决方案。通过亚马逊云科技 CDK 自动化部署和配置,我们大大简化了复杂架构的实现过程。
这个架构不仅提供了高可用性和自动扩展能力,还通过读写分离和连接池优化了性能。无论是处理高流量的 Web 应用还是数据密集型的分析工作负载,这个架构都能提供稳定可靠的数据库服务。
通过遵循本文描述的步骤和最佳实践,您可以快速部署一个生产级别的 PostgreSQL 高可用解决方案,满足现代应用程序的需求。更多 pgpool 自身的配置和优化的内容请参考 pgpool 官方文档。