亚马逊AWS官方博客
使用 Amazon S3,AWS Glue 和 BladePipe 五分钟实现数据实时入湖
 |
介绍
Apache Iceberg 是一种开放的数据表格式,解决了在数据湖管理方面的诸多痛点,如元数据混乱、文件不可追踪、事务不完整等问题,已成为数据湖架构建设中备受关注的技术方案。Apache Iceberg 已深度集成进 AWS 的数据湖生态系统,是实现Serverless、 高可靠共享数据的关键组件。通过将 Iceberg 与 S3、Glue、Athena 等 AWS 服务结合,可以构建现代化的数据湖仓架构,实现更强的数据治理能力和分析性能。
BladePipe 是一款专业的端到端数据实时迁移同步工具,凭借其低延迟、高稳定性、自动化、可视化等优势,广泛应用于金融、医药、游戏、新能源汽车等领域。BladePip e支持 40+ 主流数据源, 对于 Iceberg 这类非传统数据库交互的产品,BladePipe 也实现了数据迁移同步的自动化流程,包括结构定义转换、类型映射、约束清理、类型长度适配等工作,都可在 BladePipe 一站式完成。
BladePipe 支持 Iceberg 3 种 Catalog 和 2 种存储方式,搭配关系为:
- AWS Glue + Amazon S3
- Nessie + MinIO / Amazon S3
- Rest + MinIO / Amazon S3
本文将介绍如何使用 BladePipe 五分钟快速构建数据管道,实现数据实时入湖。
支持的数据源
目前,BladePipe 支持从以下数据源同步数据至 Iceberg。
- MySQL/MariaDB/AuroraMySQL
- Oracle
- PostgreSQL
- SQL Server
- Kafka
未来将有更多数据源持续开放。
数据同步流程
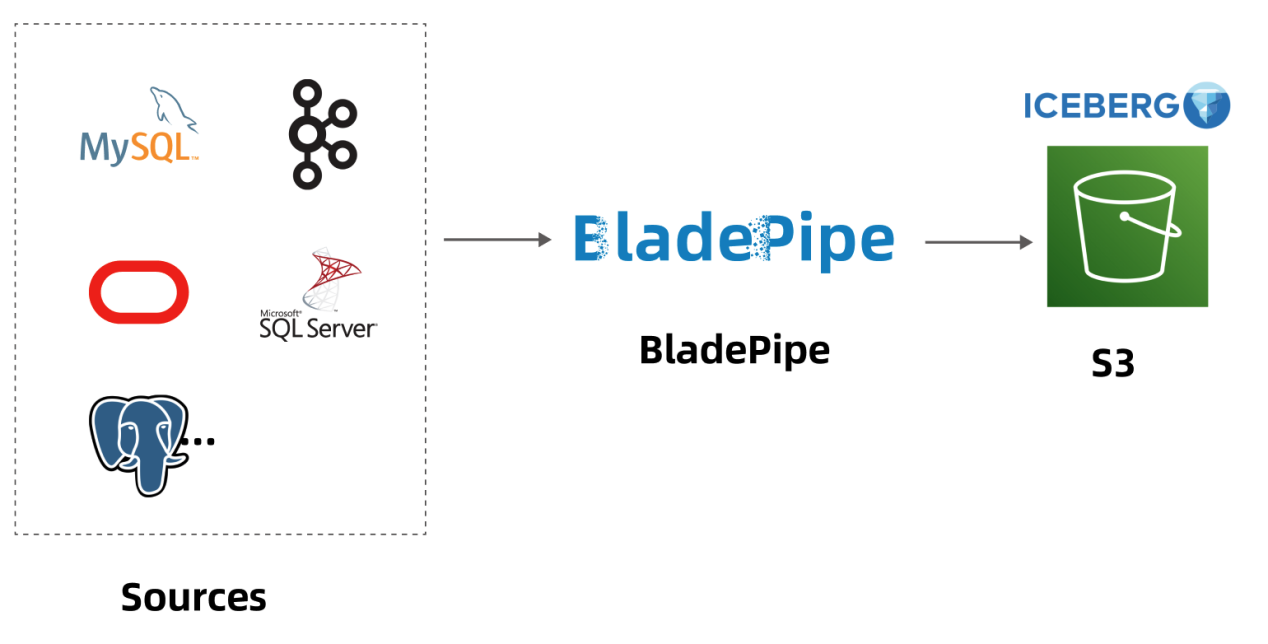 |
前置准备
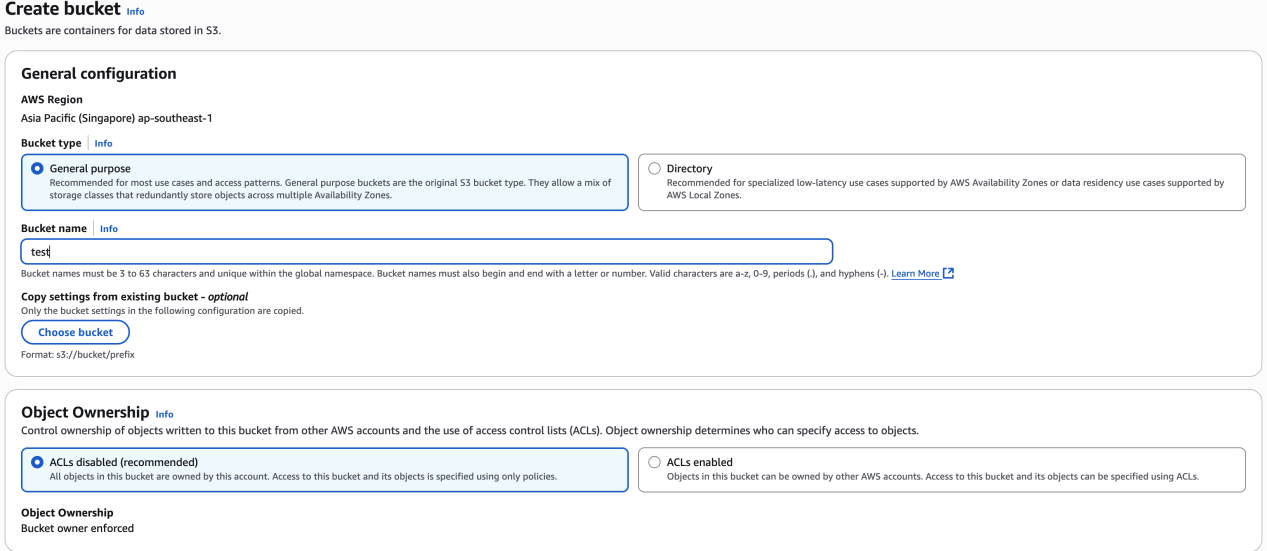
1. 准备存储桶
在 Amazon S3 上创建一个存储桶。
 |
 |
2. 准备 BladePipe
BladePipe 提供私有部署(On-Premise)和 BYOC 两种部署模式。本文将以 BYOC 部署模式为例,介绍同步流程。
在 BYOC 部署模式下,登录 BladePipe 云平台,根据 Install Worker(Docker) 或 Install Worker(Binary) 的指引,下载安装 BladePipe Worker。
操作演示
本案例将展示从 MySQL(自建) 到 Iceberg (AWS Glue + Amazon S3) 的数据迁移同步。
1. 添加数据源
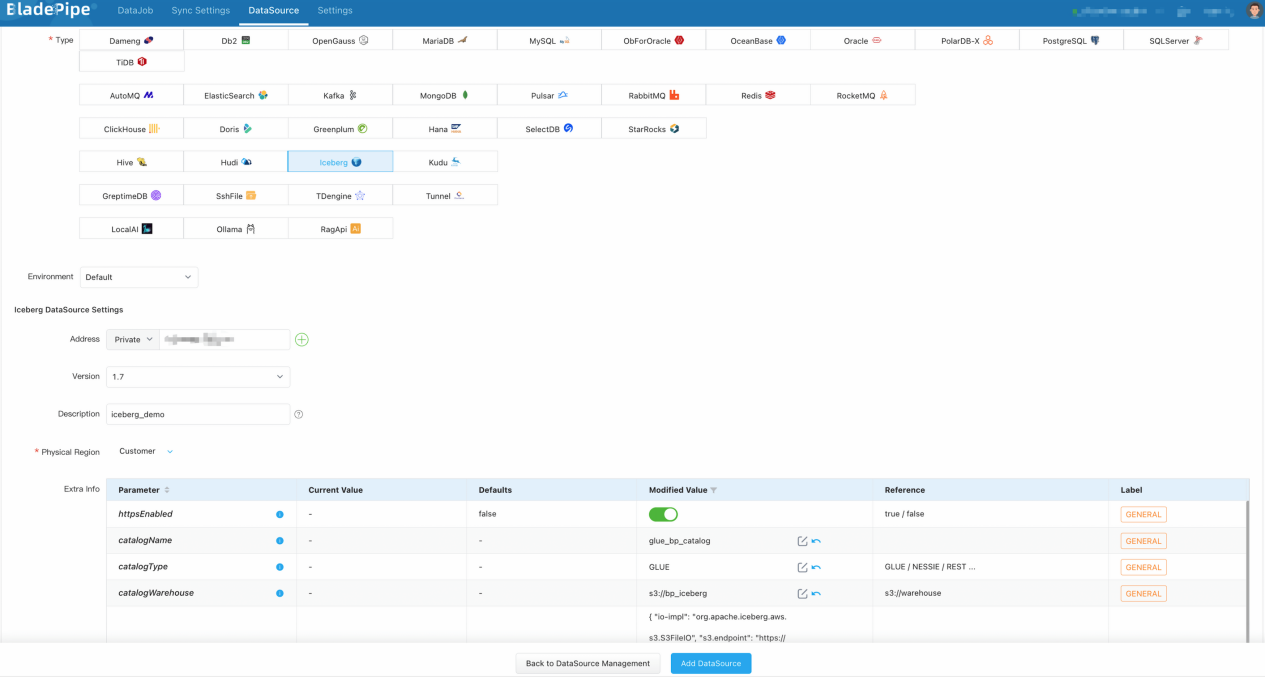
登录 BladePipe 平台,点击 数据源管理 > 添加数据源,添加 MySQL 和 Iceberg 数据源。
添加 Iceberg 数据源时所要填写的信息如下(<>内按实际情况替换)。
- 网络地址:本例填写 AWS Glue 服务地址。
<aws_glue_region_code>.amazonaws.com - 版本:保持默认值即可。
- 描述:用于辨别实例用途。
- 额外参数配置:
| 参数名称 | 说明 |
| httpsEnabled | 打开开关,即设置为 true |
| catalogName | 设置一个意义明确的名字,如 glue_<biz_name>_catalog |
| catalogType | 设置为 GLUE |
| catalogWarehouse | 元数据和数据文件最终存放位置,如 s3://<biz_name>_iceberg |
| catalogProps | 参考配置: |
 |
2. 创建任务
- 在 BladePipe 平台,点击 同步任务 > 创建任务。
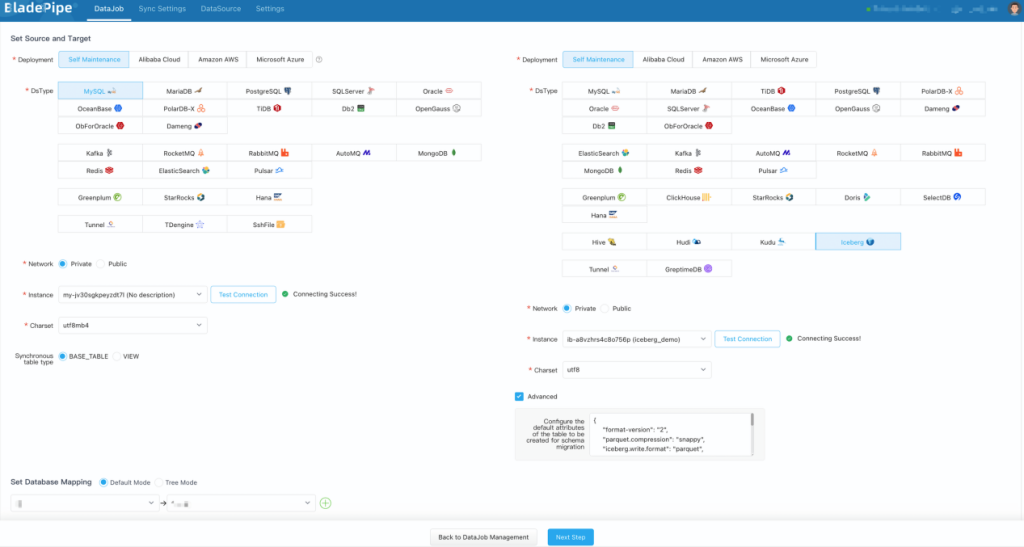
- 选择源(MySQL)和目标(Iceberg)实例,并分别点击 测试连接。其中 Iceberg 数据源结构迁移属性配置推荐如下:
如遇到测试连接长时间不返回,可以刷新页面重新选择。数据库连接信息错误或网络不通都可能造成该现象。
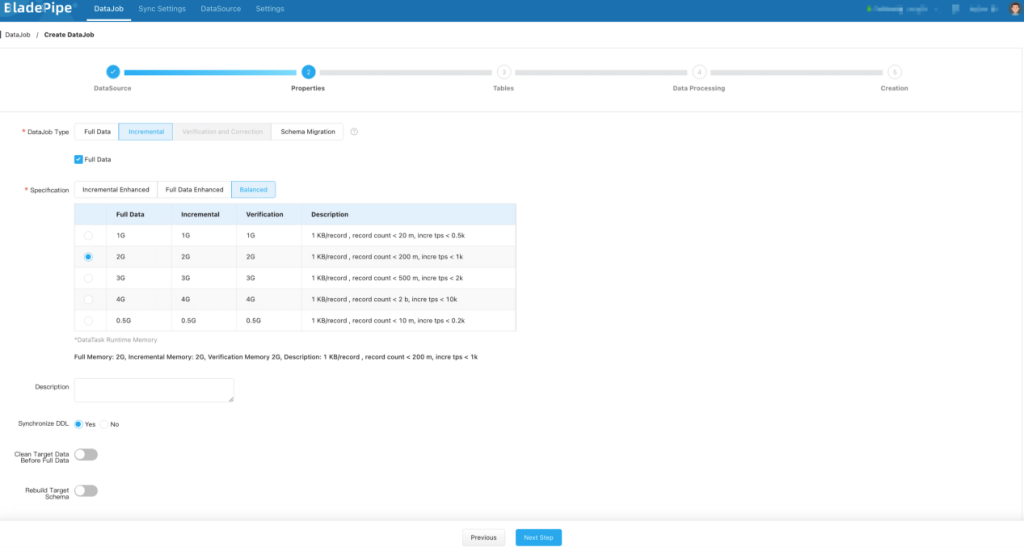
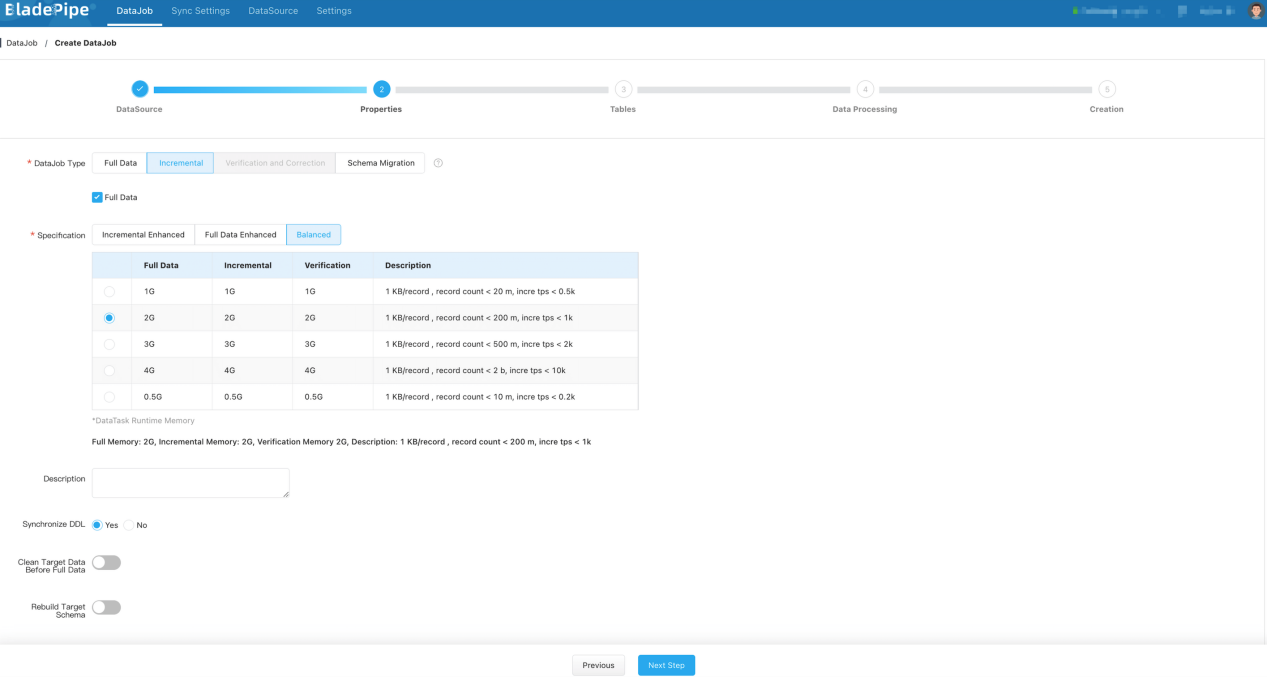
- 在 功能配置 页面,选择 增量同步,并勾选 全量初始化。任务规格选择默认 2 GB 或 1 GB 即可。不建议选择小于 1 GB 的任务,批量更新或写入较多可能造成任务内存紧张,性能急剧下降。
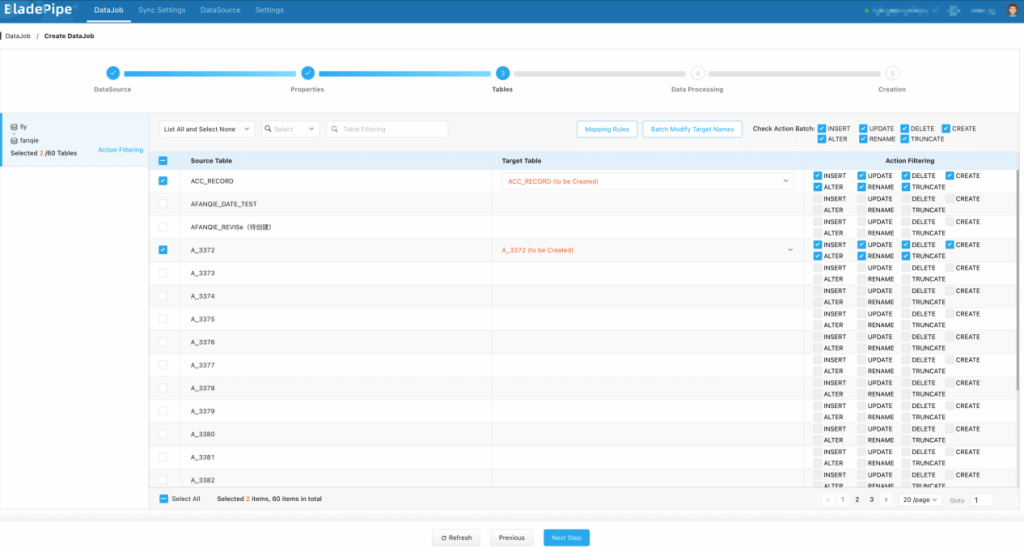
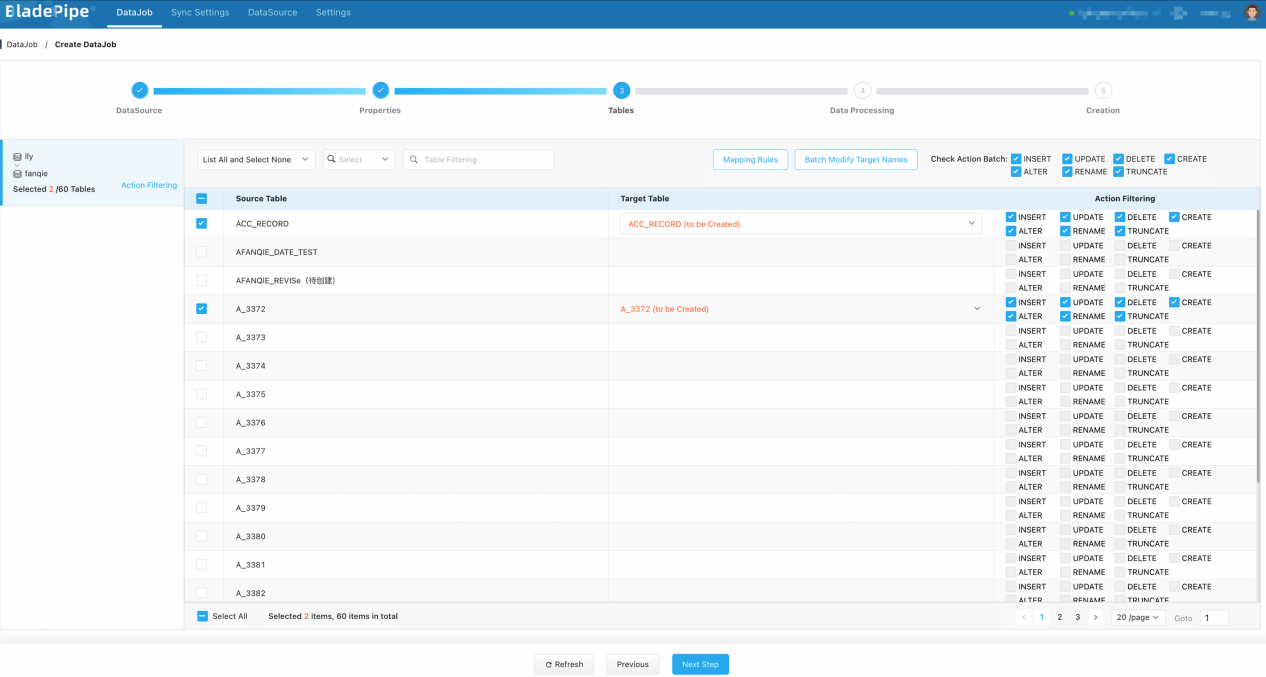
- 在 表和操作过滤 页面,选择需要迁移同步的表,可同时选择多张。单个任务推荐选择表数量控制在 1000 张以内。
- 在 数据处理 页面,保持默认配置。
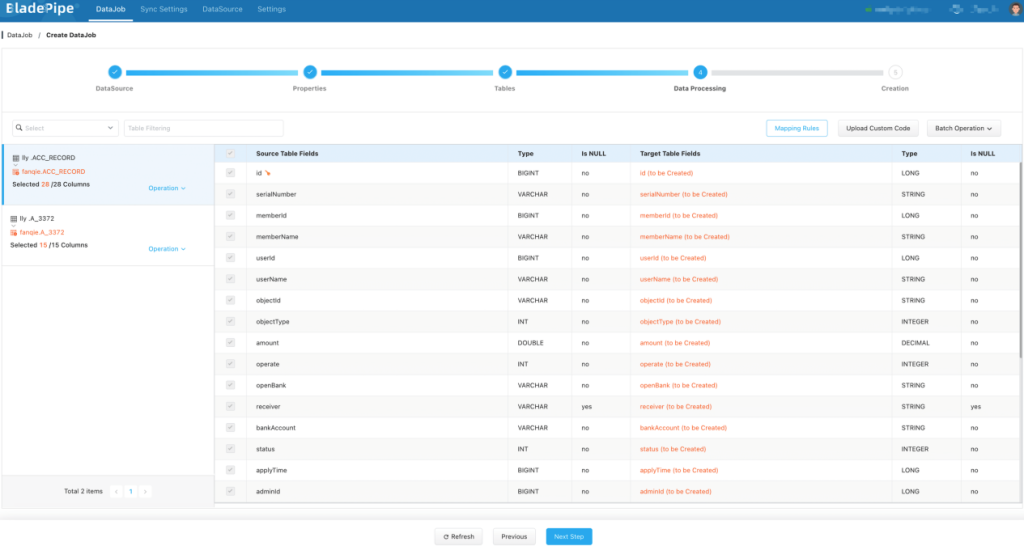
- 在 创建确认 页面,点击 创建任务,开始运行。

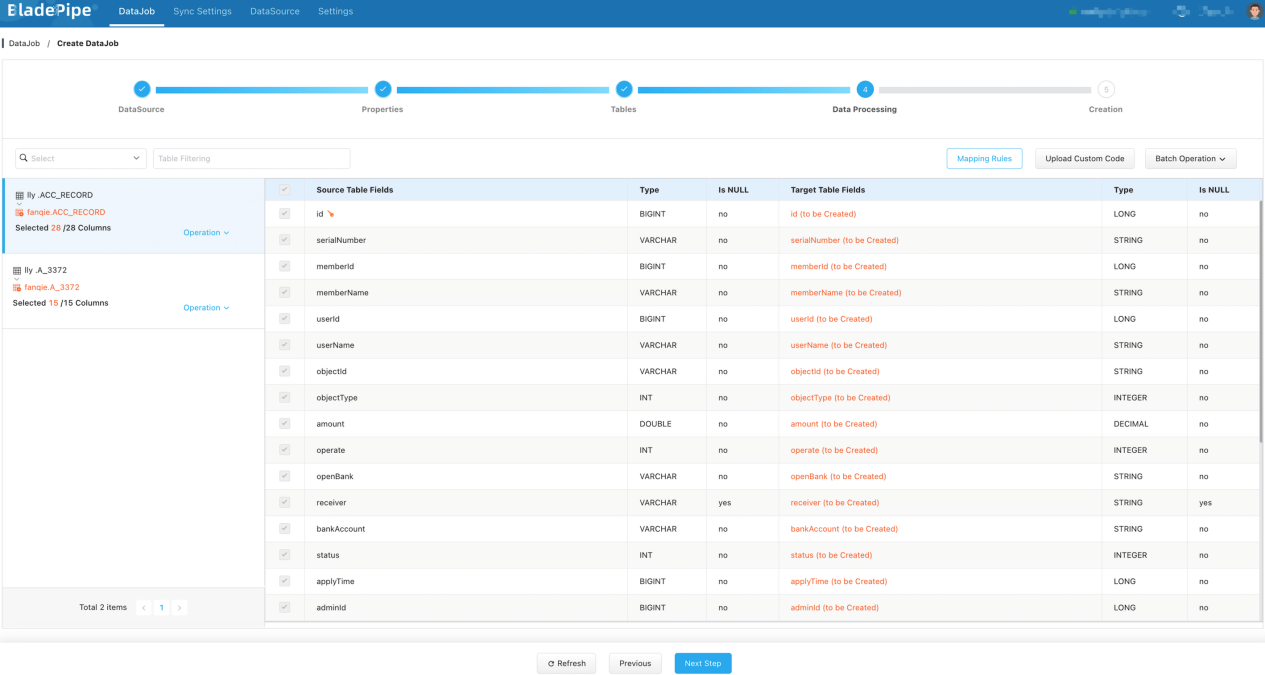

至此,MySQL 数据库中的数据已实时传输到 Iceberg,延迟时间保持在 20 秒内。
总结
本文介绍了一种基于 Amazon S3、AWS Glue 和 BladePipe 的数据实时入湖方案。该方案在保障数据准确性与一致性的前提下,实现了秒级延迟的数据入湖,能够为组织内多样化的业务场景提供实时数据支撑,尤其适用于构建湖仓融合的现代数据平台。