亚马逊AWS官方博客
推出 Amazon S3 Vectors(预览版):首款大规模支持原生向量的云存储服务
现在,我们宣布推出 Amazon S3 Vectors 预览版,这是一款专门构建的持久向量存储解决方案,可以将上传、存储和查询向量的总成本降低多达 90%。Amazon S3 Vectors 是首款原生支持存储大型向量数据集的云对象存储解决方案,并提供了亚秒级查询性能,让各个企业能够负担得起大规模存储人工智能就绪型数据。
向量搜索是生成式 AI 应用程序中采用的一项新兴技术,该技术利用距离或相似度指标来比较向量表示,以便查找与给定的数据相似的数据点。向量是从嵌入模型中创建的非结构化数据的数字表示。您可以使用嵌入模型为文档内的字段生成向量,并将向量存储到 S3 Vectors 中,以便执行语义搜索。
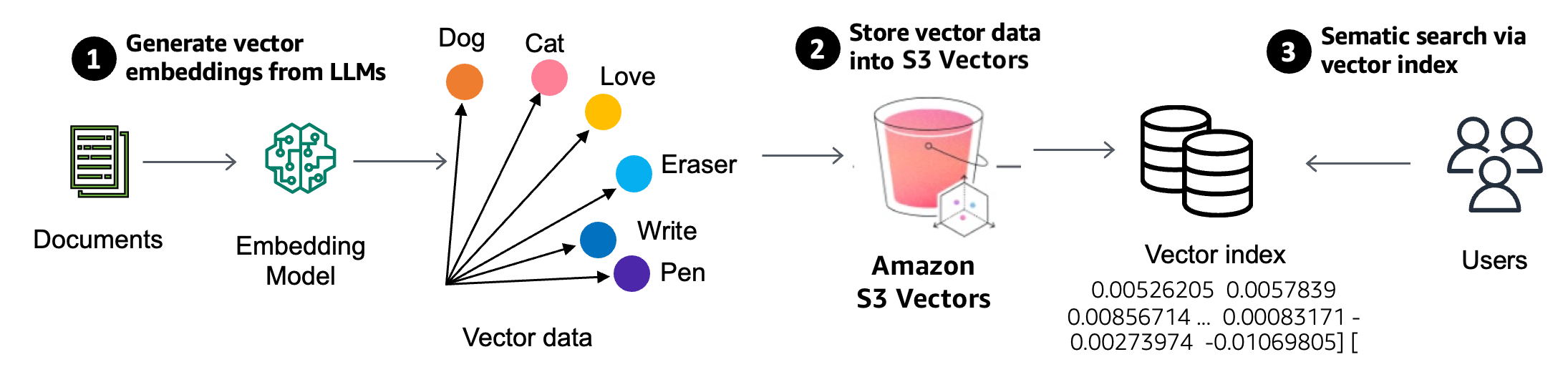
S3 Vectors 推出了向量存储桶,这是一种新的存储桶类型,具有一组专用的 API,无需预置任何基础设施即可存储、访问和查询向量数据。创建 S3 向量存储桶时,您可以在向量索引内组织向量数据,这样即可轻松对数据集执行相似度搜索查询。每个向量存储桶最多可以包含 1 万个向量索引,每个向量索引可以容纳数千万个向量。
创建向量索引之后,为索引添加向量数据时,还可以将元数据作为键值对附加到每个向量,以便根据一组条件(例如日期、类别或用户首选项)筛选未来的查询。随着时间的推移,当您写入、更新和删除向量时,S3 Vectors 会自动优化向量数据,以使向量存储实现最佳性价比,即使数据集在不断扩展和演变。
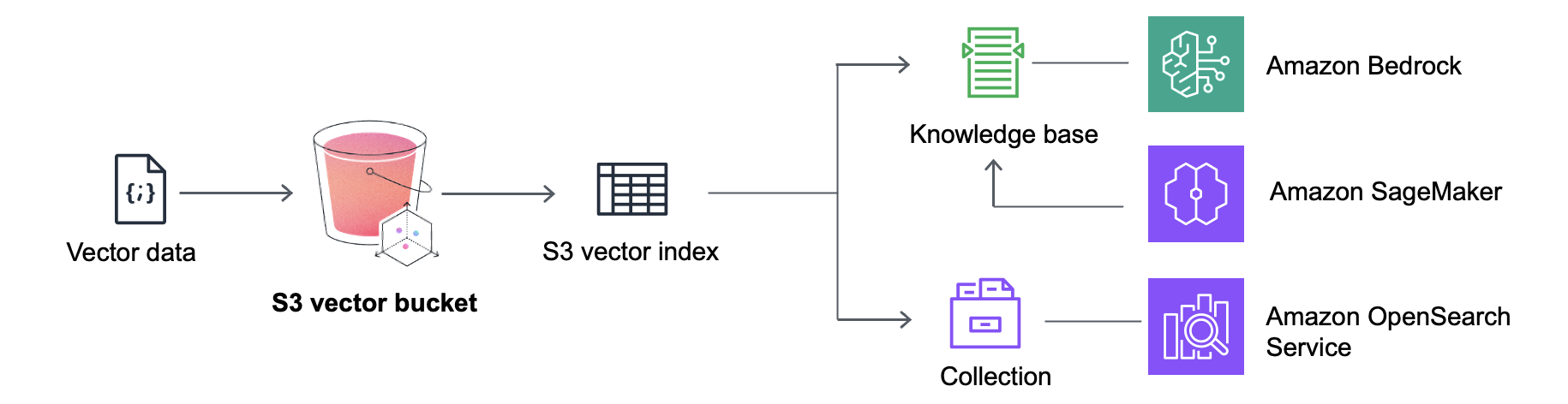
S3 Vectors 还与 Amazon Bedrock 知识库进行了原生集成,包括在 Amazon SageMaker 融通式合作开发工作室内进行原生集成,用于构建经济高效的检索增强生成(RAG)应用程序。通过与 Amazon OpenSearch Service 进行集成,您可以在 S3 Vectors 中保留很少被查询的向量,以便降低存储成本,然后快速将它们移到 OpenSearch 中,以满足增大的需求或者支持实时、低延迟的搜索操作。
借助 S3 Vectors,您现在可以经济划算地存储代表大量非结构化数据(例如图像、视频、文档和音频文件)的向量嵌入,从而支持可扩展的生成式人工智能应用程序,包括语义搜索和相似度搜索、RAG 以及构建代理内存。您还可以构建应用程序,以便支持多种行业使用案例,包括个性化推荐、自动化内容分析和智能文档处理,而无需面对向量数据库管理工作产生的复杂问题和成本。
S3 Vectors 的实际应用
要创建向量存储桶,请在 Amazon S3 控制台的左侧导航窗格中选择向量存储桶,然后选择创建向量存储桶。
输入向量存储桶名称,然后选择加密类型。如果您未指定加密类型,Amazon S3 将应用服务器端加密,并将 Amazon S3 托管的密钥(SSE-S3)用作新向量的基本加密级别。您也可以选择使用 AWS Key Management Service(AWS KMS)密钥(SSE-KMS)进行服务器端加密。要了解有关如何管理向量存储桶的更多信息,请访问《Amazon S3 用户指南》中的 S3 向量存储桶。
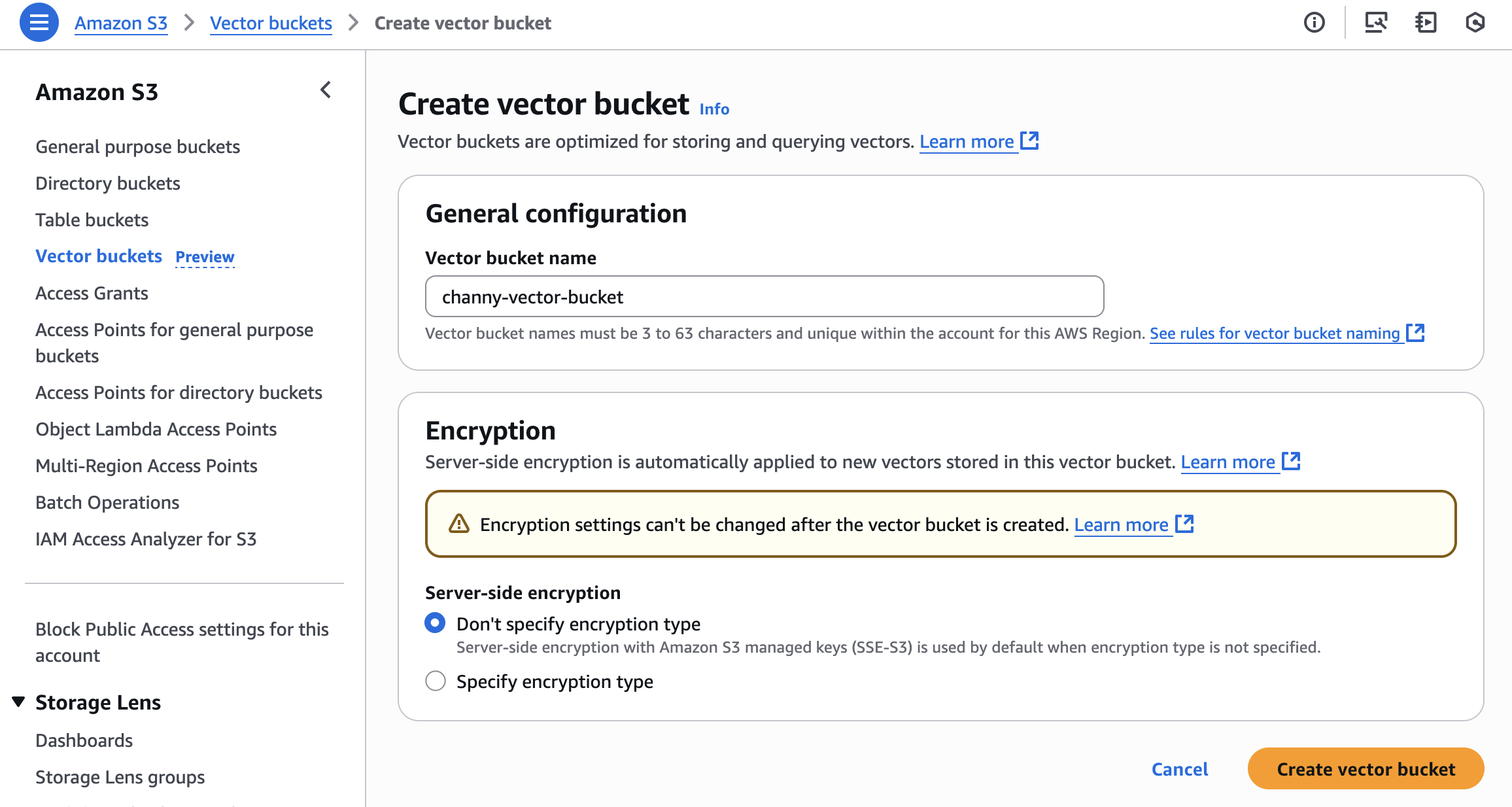
现在,您可以创建向量索引,以便存储和查询您创建的向量存储桶内的向量数据。
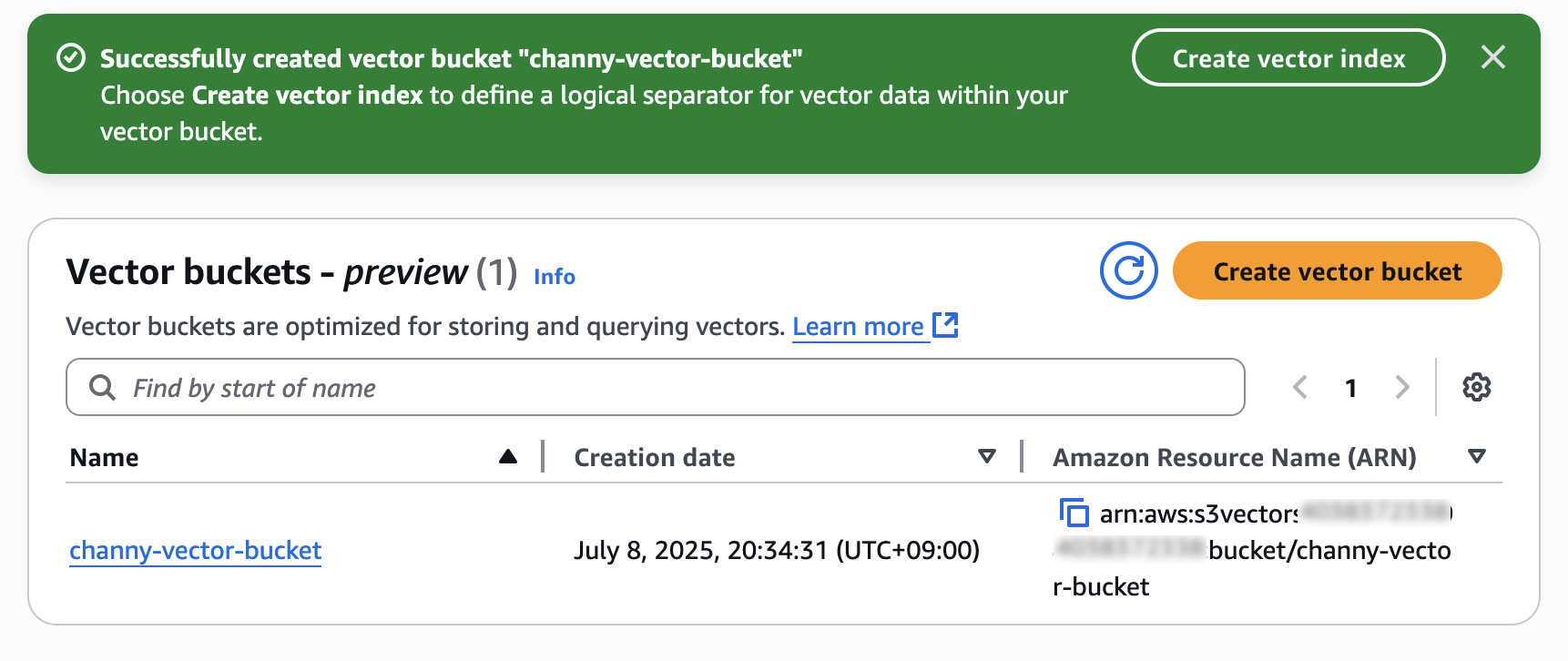
输入向量索引名称以及要插入到索引中的向量的维度。为此索引添加的所有向量都必须具有数量完全相同的值。
对于距离指标,您可以选择余弦或欧几里得。创建向量嵌入时,选择嵌入模型的推荐距离指标,以便获得更准确的结果。
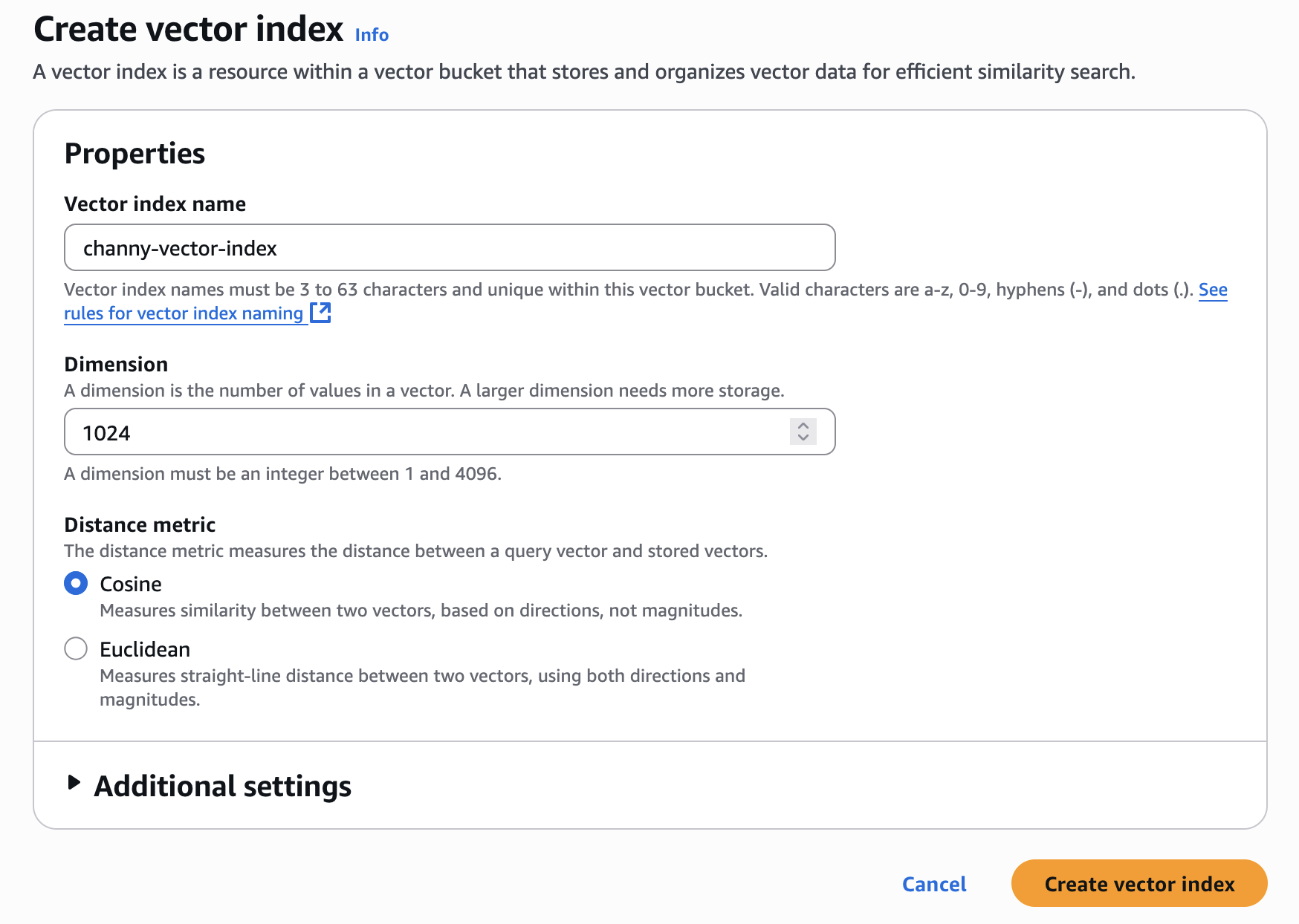
选择创建向量索引,然后可以插入、列出和查询向量。
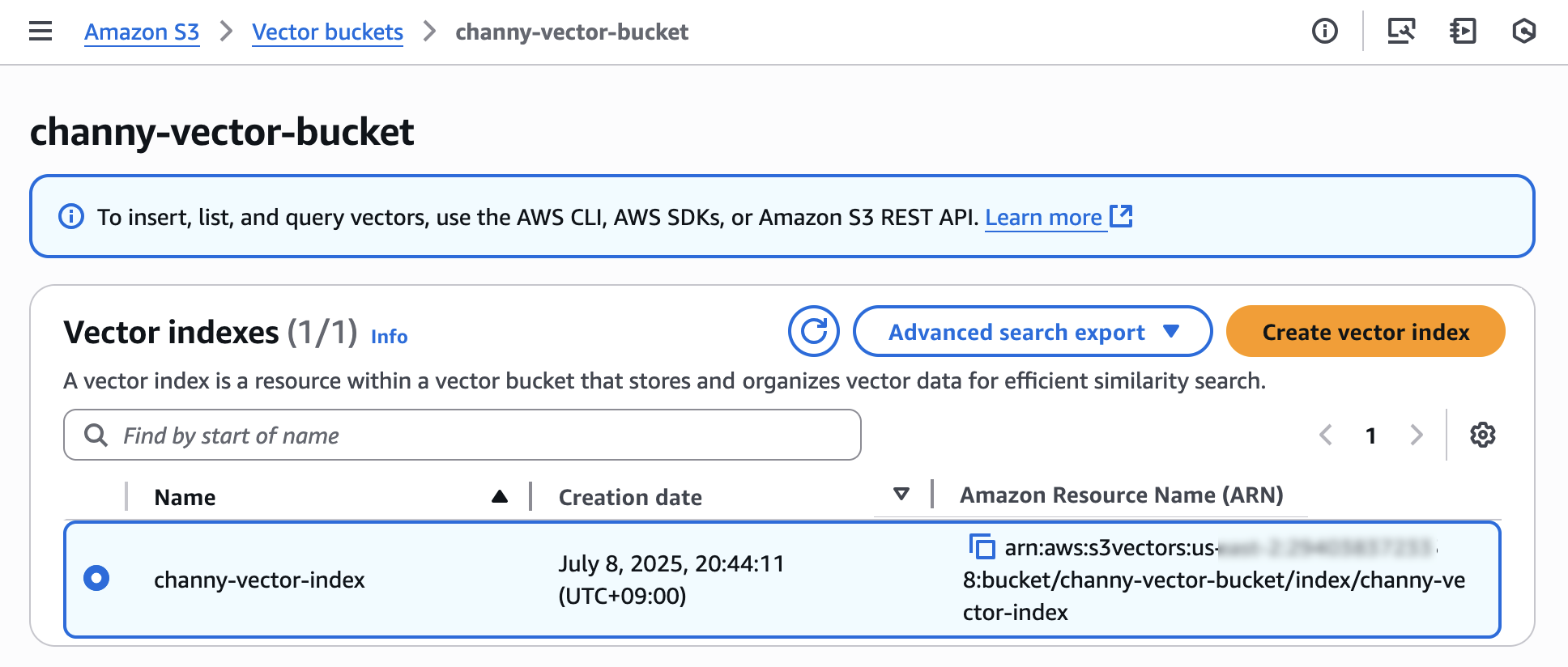
要将向量嵌入插入到向量索引中,您可以使用 AWS 命令行界面(AWS CLI)、AWS 软件开发工具包或 Amazon S3 REST API。要为非结构化数据生成向量嵌入,您可以使用 Amazon Bedrock 提供的嵌入模型。
如果正在使用最新的 AWS Python 软件开发工具包,您可以使用如下代码示例,通过 Amazon Bedrock 为您的文本生成向量嵌入:
# 使用 Amazon Titan 文本嵌入 V2 来生成和打印嵌入。
import boto3
import json
# 在您选择的 AWS 区域中创建 Bedrock Runtime 客户端。
bedrock= boto3.client("bedrock-runtime", region_name="us-west-2")
要转换为嵌入的文本字符串。
texts = [
“《星球大战》:一名农场男孩加入叛军队伍,在太空中与邪恶帝国英勇作战”,
“《侏罗纪公园》:科学家们在发生意外情况的主题公园里创造恐龙”,
“《海底总动员》:鱼爸爸在海洋里苦苦寻觅他那走失的儿子”]
embeddings=[]
# 为输入文本生成向量嵌入
对于文本中的文本:
body = json.dumps({
"inputText": text
})
# 调用 Bedrock 的嵌入 API
response = bedrock.invoke_model(
modelId='amazon.titan-embed-text-v2:0', # Titan embedding model
body=body)
# 解析响应
response_body = json.loads(response['body'].read())
embedding = response_body['embedding']
embeddings.append(embedding)现在,您可以将向量嵌入插入到向量索引中,并使用查询嵌入在向量索引中查询向量:
# 创建 S3Vectors 客户端
s3vectors_client = boto3.client('s3vectors', region_name='us-west-2')
# 插入向量嵌入
s3vectors.put_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
vectors=[
{"key": "v1", "data": {"float32": embeddings[0]}, "metadata": {"id": "key1", "source_text": texts[0], "genre":"scifi"}},
{"key": "v2", "data": {"float32": embeddings[1]}, "metadata": {"id": "key2", "source_text": texts[1], "genre":"scifi"}},
{"key": "v3", "data": {"float32": embeddings[2]}, "metadata": {"id": "key3", "source_text": texts[2], "genre":"family"}}
],
)
# 为您的查询输入文本创建嵌入
# 要转换为嵌入的文本。
input_text = "列出关于太空冒险的电影"
# 为模型创建 JSON 请求。
request = json.dumps({"inputText": input_text})
# 使用请求和模型 ID 来调用模型,例如 Titan 文本嵌入 V2。
response = bedrock.invoke_model(modelId="amazon.titan-embed-text-v2:0", body=request)
# 解码模型的原生响应正文。
model_response = json.loads(response["body"].read())
# 提取并打印所生成的嵌入和输入文本标记计数。
embedding = model_response["embedding"]
# 执行相似度查询。您也可以选择在查询中使用筛选器
query = s3vectors.query_vectors( vectorBucketName="channy-vector-bucket",
indexName="channy-vector-index",
queryVector={"float32":embedding},
topK=3,
filter={"genre":"scifi"},
returnDistance=True,
returnMetadata=True
)
results = query["vectors"]
print(results)
要了解有关如何将向量插入到向量索引中或者列出、查询和删除向量的更多信息,请访问《Amazon S3 用户指南》中的 S3 向量存储桶和 S3 向量索引。此外,通过 S3 Vectors 嵌入命令行界面(CLI),您可以使用 Amazon Bedrock 为数据创建向量嵌入,并使用单个命令将它们存储在 S3 向量索引中并执行查询。有关更多信息,请参阅 S3 Vectors 嵌入 CLI GitHub 存储库。
将 S3 Vectors 与其他 AWS 服务集成
S3 Vectors 可以与 Amazon Bedrock、Amazon SageMaker 和 Amazon OpenSearch Service 等其他 AWS 服务集成,从而增强您的向量处理功能并为人工智能工作负载提供全面的解决方案。
使用 S3 Vectors 创建 Amazon Bedrock 知识库
您可以在 Amazon Bedrock 知识库中使用 S3 Vectors 来简化 RAG 应用程序的向量存储并降低它们的向量存储成本。在 Amazon Bedrock 控制台中创建知识库时,您可以选择 S3 向量存储桶作为向量存储选项。
在步骤 3 中,您可以选择向量存储创建方法来创建 S3 向量存储桶和向量索引,也可以选择之前创建的现有 S3 向量存储桶和向量索引。
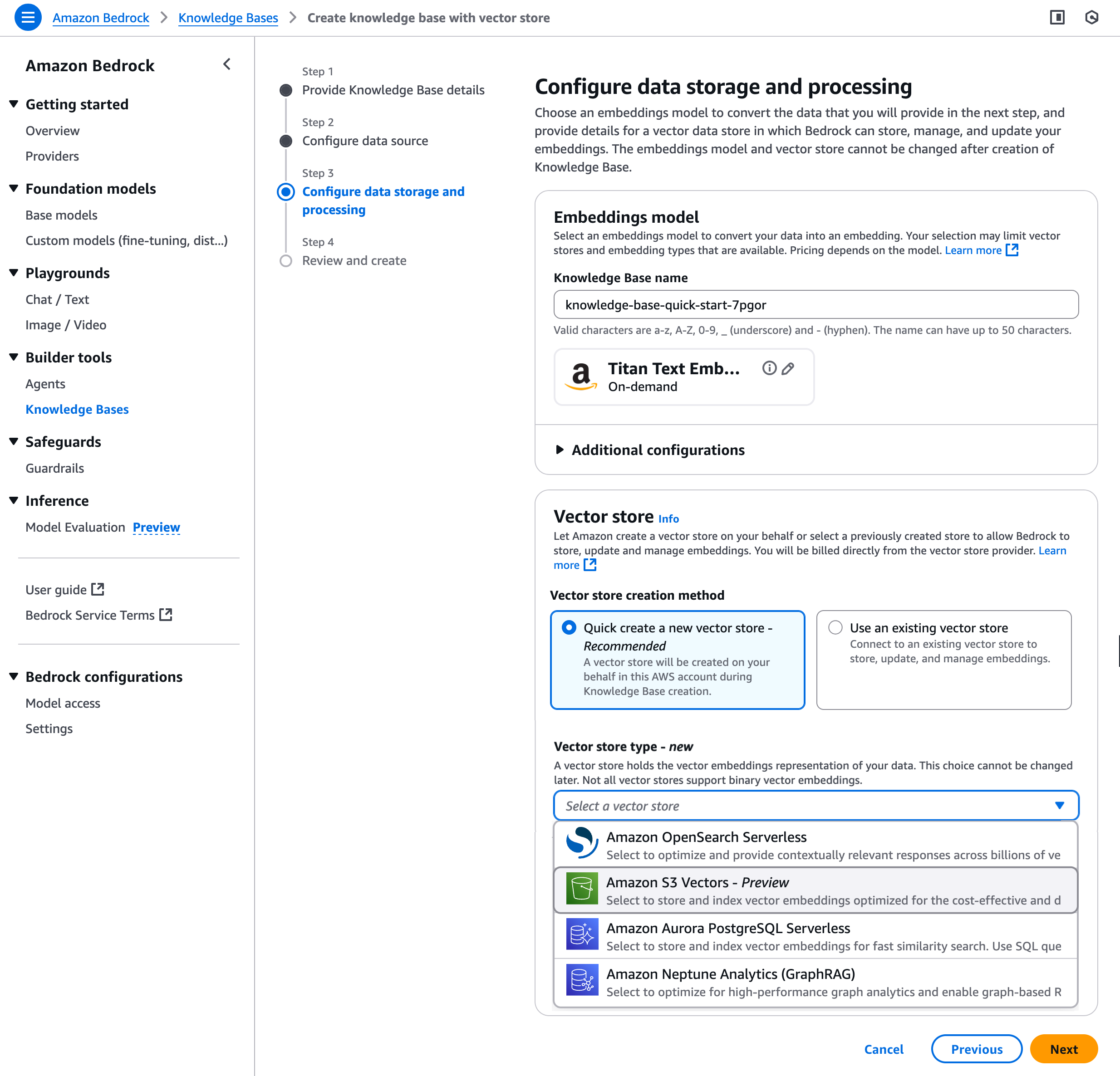
有关详细的分步说明,请访问《Amazon Bedrock 用户指南》中的通过连接到 Amazon Bedrock 知识库中的数据来源来创建知识库。
使用 Amazon SageMaker Unified Studio
当通过 Amazon Bedrock 构建生成式 AI 应用程序时,您可以在 Amazon SageMaker Unified Studio 中使用 S3 Vectors 来创建和管理知识库。SageMaker Unified Studio 可以在下一代 Amazon SageMaker 中使用,它为数据和人工智能提供了一个统一的开发环境,包括使用 Amazon Bedrock 知识库构建和测试生成式 AI 应用程序。

构建生成式 AI 应用程序时,您可以使用通过 Amazon Bedrock 创建的 S3 Vectors 来选择知识库。要了解更多信息,请访问《Amazon SageMaker Unified Studio 用户指南》中的为您的 Amazon Bedrock 应用程序添加数据来源。
将 S3 向量数据导出到 Amazon OpenSearch Service
您可以采用分层策略,以经济高效的方式将长期向量数据存储在 Amazon S3 中,同时将高优先级向量导出到 OpenSearch 以获得实时查询性能,从而平衡成本与性能。
这一灵活性意味着,您的组织可以借助 OpenSearch 的高性能(高 QPS、低延迟)来执行关键的实时应用,例如产品推荐或欺诈检测,同时在 S3 Vectors 中保留对时间不太敏感的数据。
要导出向量索引,请在 Amazon S3 控制台中选择高级搜索导出,然后选择导出到 OpenSearch。
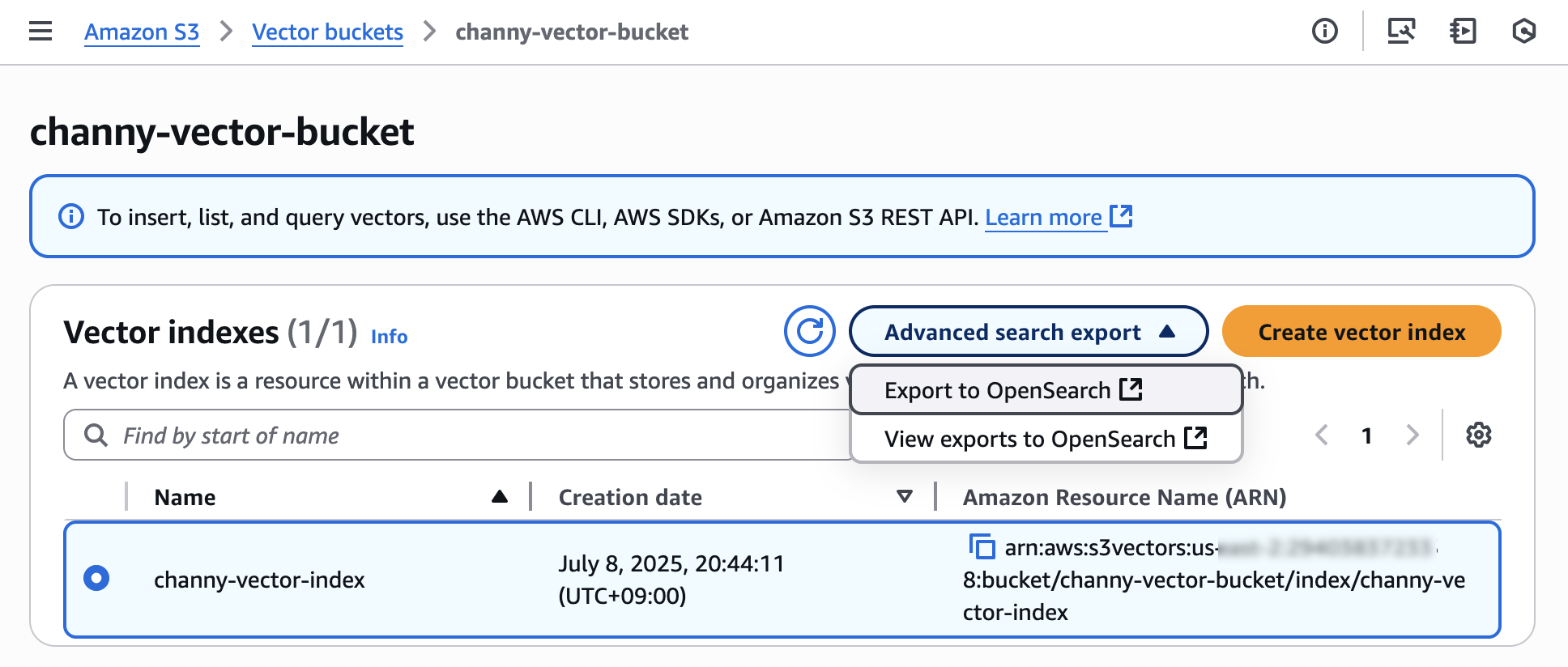
随后,您将进入 Amazon OpenSearch Service 集成控制台,其中包含一个模板,用于将 S3 向量索引导出到 OpenSearch 向量引擎。选择使用预选的 S3 向量来源和服务访问角色进行导出。
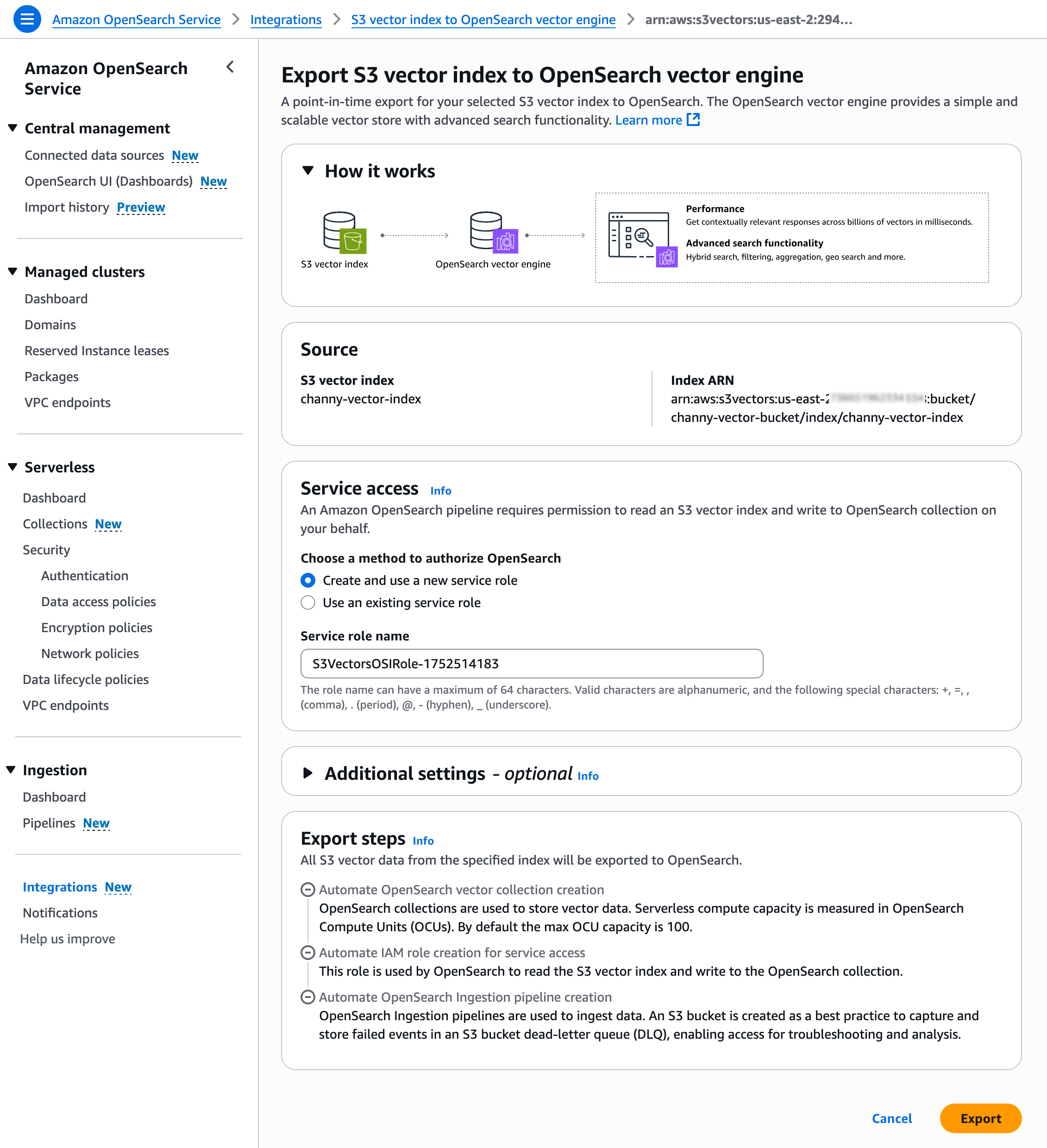
它将开始执行步骤,以便创建新的 OpenSearch 无服务器集合,并将 S3 向量索引中的数据迁移到 OpenSearch knn 索引中。
在左侧导航窗格中,选择导入历史记录。您可以看到为了将 S3 向量索引中的向量数据复制到 OpenSearch 无服务器集合而新建的导入作业。
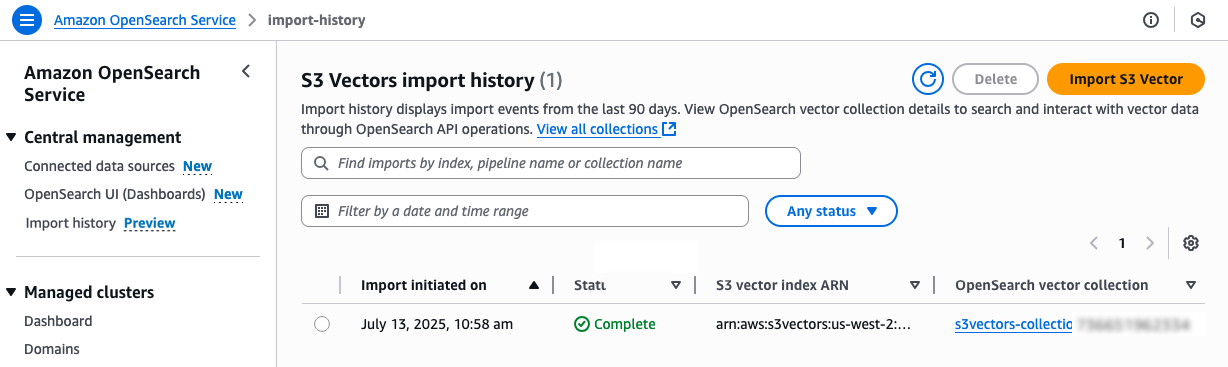
当状态更改为完成之后,您可以连接到新的 OpenSearch 无服务器集合,并查询新的 OpenSearch knn 索引。
要了解更多信息,请访问《Amazon OpenSearch Service 开发人员指南》中的创建和管理 Amazon OpenSearch 无服务器集合。
现已推出
Amazon S3 Vectors 及其与 Amazon Bedrock、Amazon OpenSearch Service 和 Amazon SageMaker 的集成现已在美国东部(弗吉尼亚州北部)、美国东部(俄亥俄州)、美国西部(俄勒冈州)、欧洲地区(法兰克福)和亚太地区(悉尼)等区域提供预览版。
立即在 Amazon S3 控制台中试用 S3 Vectors,并通过您常用的 AWS Support 联系方式向 AWS re:Post for Amazon S3 发送反馈。
— Channy
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。