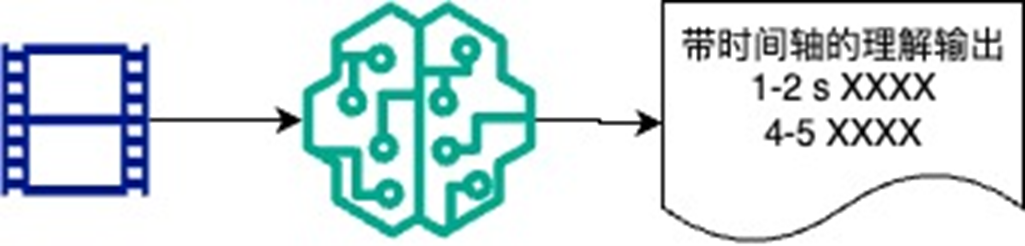
为什么需要智能剪辑
媒体娱乐、广告营销、零售电商等行业的客户拥有大量的视频资源,如网剧、纪录片、访谈和创意素材等。为满足不同观众群体和分发渠道的需求,需要对这些视频资源进行大量的编辑和再创作。对于中长视频,需要对内容总结、剪辑、翻译、提取精彩片段等;对于短视频,需要增加特效、变换、重新配音等。要完成这些工作,通过传统的视频工具链将耗费大量的人力和时间。
随着多模态模型的不断发展,对于视频理解的能力不断增强,通过多模态模型与多种专业模型的配合,能够多维度的高效率的理解视频内容,包括视频中音轨,视频中字幕,视频中的画面,视频中分片;这也使得通过深入的视频理解,有明确目标的视频二次加工成为可能。
本文介绍一套利用生成式AI多模态模型用于视频理解从而进行视频编辑的指南,通过多模态大模型对视频内容进行深入理解,在此基础上提供了一套智能剪辑的功能集合,用于简化视频编辑工作流,提高视频创作效率,从而为观众提供更友好和丰富多样的视觉体验。
本文将介绍:
- 智能剪辑的多种客户场景
- 方案指南的设计原理
- 指南主要功能介绍和优势
- 代码示例以及API使用介绍
- 实际应用场景的介绍
智能剪辑的多种客户场景
在传统影视行业,流媒体行业,广告行业,娱乐行业,零售电商行业,体育行业等,只要涉及视频领域的创作就离不开视频剪辑,视频剪辑的工作是一个相对劳动密集型工作,需要大量人工观看视频,理解视频,视频打点,视频编辑,视频特效等劳动,其中一些环节是可以利用AI驱动的工作流进行辅助,从而提高效率。
| 业务场景 |
客户类型 |
业务特点 |
| 影视剪辑和二创 |
流媒体公司,影视版权公司 |
客户具有版权电影,电视剧等进行自动分段,高光时刻,进行多区域和多平台分发 |
| 体育比赛精彩时刻 |
体育媒体,体育运营 |
对于各类型体育赛事中的比赛,进行精彩时刻的提取,比如足球进球,比赛逆转,绝杀,精彩展现回放等 |
| 短剧投放视频 |
短剧内容运营企业 |
大量的短剧资源,需要制作一些精彩时刻,前情提要,进行多渠道投放,吸引付费用户 |
| 科教片和纪录片的分段和总结 |
传统媒体,流媒体公司 |
知识类视频,需要进行专业的理解,翻译,分段,在合适的频道进行播放 |
| 直播快速分段和提取 |
娱乐行业,零售电商 |
娱乐直播,电商直播或者其他类型的视频直播,进行快速的分割,并提取出其中重要信息。 |
各类客户面对的痛点
- 利用传统工作流,需要人力成本高, 效率低, 难以满足运营需求
- 需要专业人才,成本高,周期长,、
- 视频剪辑和制作缺乏自动化工具
- 准确性和标准化,很难进行精确控制
- 内容一致性, 等一致性问题
- 需要多部门流程,缺乏统一的自动化工作流管理
这对上述的业务场景和普遍的痛点,我们利用生成式AI多模态大模型,Agentic AI,媒体服务,打造了一套指南,目的在于利用AI自动化视频内容的剪辑的工作流,辅助人工,大幅提高工作效率,解决客户的痛点。
方案指南设计原理和对比
从工作流的角度,我们对于AI智能剪辑的思路,是模拟专业团队的工作流对视频内容进行处理,从而产出最终用户所预期的视频内容。这对这个工作流,我们可以大致可以分为一下几个关键环节:
- 视频理解:包括视频画面,音频,字幕在时间纬度上综合理解
- 视频内容的抽取:包括分段,精彩时刻抽取,特定场景抽取、特定情节抽取等工作
- 视频组合:根据理解和抽取的结果,利用媒体处理工具或者服务,对于视频进行重新合成以及配音,字幕,转场特效等工作
对于每个工作流的节点有不同的方法实现,我们针对工作流中,每种可能方式进行对比测试,得到了相对能适合大多数场景的技术组合。
视频理解方式
视频理解方式从基础形式上来说分为两种:分段理解综合理解和整段理解
整段理解的形式
是把整个视频输入给多模态模型,由多模态模型直接给出时间维度的理解
分段理解的形式
先把视频内容按照一定规则进行分割,成子单元,每个子单元分别进行理解再进行整体理解
这两种方式个有优缺点
对于整段理解来说
- 优点:操作比较简单并且灵活适配各种视频模式
- 缺点:视频长度变长后,由于目前VLM model取样逐渐稀疏,时间准确度会下降,
下面是针对一组不同时长的,足球标赛视频,标记出射门,进球时刻,用一个多模态大模型的测试结果
使用如下提示词:
请分析如下视频,长度为 {video-length}, 请标记射门,进球的时刻
|
5分钟 |
15分钟 |
29分钟 |
45分钟 |
| 视频正确信息 |
1:35 射门并进球 |
射门1:35 ,5:20,10:31
进球:1:35 |
射门1:35 ,5:20,10:31,16:01,24:32
进球:1:35,24:32 |
N/A |
| 时间偏差 |
0s |
0-3s |
3-5s |
N/A |
| 是否有遗漏 |
无 |
无 |
有 |
N/A |
可以看到随着视频长度的增加,时间精度会下降,甚至有遗漏的情况,另外模型不支持超长视频输入
对于分段理解来说
- 优点:时间准确度较高,并且分段越细致,时间准确度越高
- 缺点:需要多个模块组合,工程化比较复杂
结论1:作为视频剪辑的方案来说,为了视频剪辑的效果,时间精确度是基础,另外对于不同的客户场景,长度一小时以上的视频编辑是比较普遍的需求;所以我们选择分段理解来保持时间的精度并能处理较长的视频。
如何分段
我们选择分段理解作为我们理解方式,那么如何分段就是一个需要面对的技术问题,分段的方式是否合适决定了
- 时间的准确度
- 最小的视频处理短圆
- 视频理解的精度和深度:
分段的基本方式包括
- 按照镜头顺序分割
- 按照音频转场分割
- 按照时间平均分割
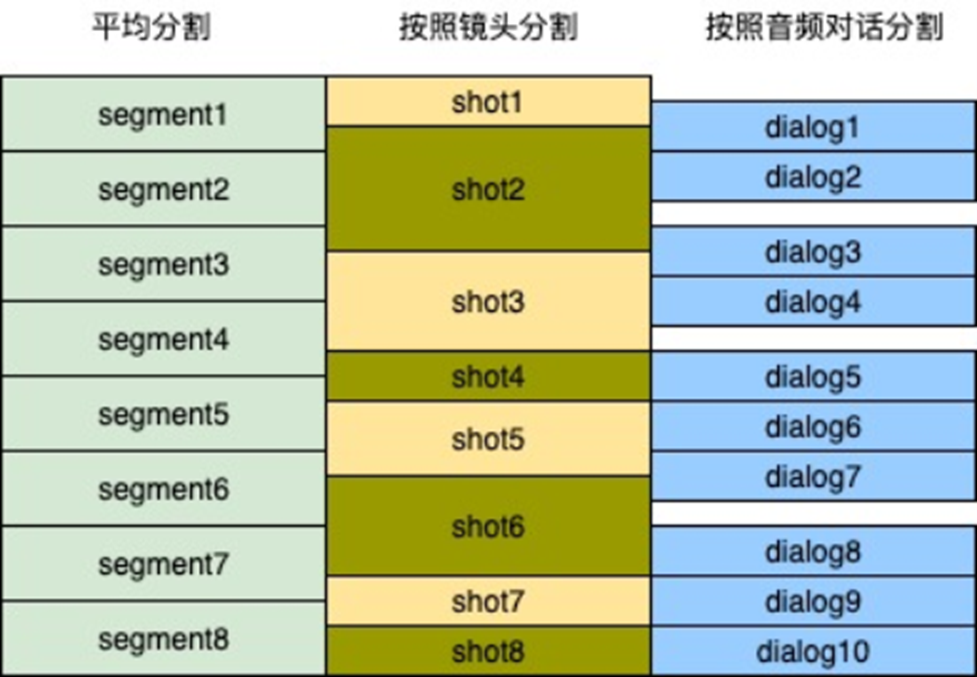
下面的图显示了对于一个视频来说,不同分段的特性
特征总结
- 平均分割虽然简单但是会把镜头和对话截断
- 镜头分割法可以覆盖整个视频,但是可能会截断对话,适合体育比赛,纪录片大部分信息在画面的视频
- 按照音频对话分割可能覆盖不了全部视频,但不会截断对话,适合短剧等以对话驱动情节的视频
结论2:我们不采用平均分割,采用镜头分割和语音对话分割的综合理解,来适应不同的视频场景
视频的抽取方式
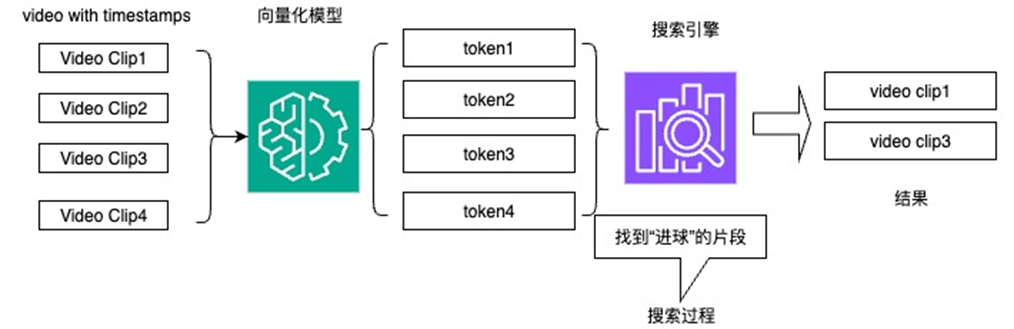
对于智能视频剪辑来说,基于视频理解的视频抽取是核心的步骤,这里有两个主流方式
通过向量化搜索的方式
通过大模型推理的方式
这两种方式,第一种是利用向量化(视频或者转录后文字等多种方式向量化)与搜索引擎相结合,查找结果;第二种是利用大模型对剧情全局理解,再对结构化数据进行进行推理,从而产生结果。
这两种结果各有优点
场景1 精确动作 “查找进球镜头” 每个分片大概2-3分钟
|
10个分片包含5个进球镜头 |
50个分片包含20个进球镜头 |
100个分片包含20个进球镜头 |
200个分片包含100个进球镜头 |
| 方法1 遗漏和选错总数 |
0 |
1 |
2 |
2 |
| 方法2 遗漏和选错总数 |
0 |
2 |
2 |
6 |
场景2 按照情节查找 “男主幽默的对话”,这里会有些主观判断
|
5组对话 |
20组对话 |
50组对话 |
| 方法1 遗漏和选错总数 |
有1-2个 |
有5个左右 |
会出现较多误判 |
| 方法2 遗漏和选错总数 |
0 |
0 |
2 |
对于精确动作片段的查找,方法1和方法2在时长2小时内是基本相似的,而且错误率较低;当视频数量过多时,方法2会有遗漏
对于按照情节查找,方法1错误率较高,方法2可以保持一定正确率
综合测试结果和系统分析,方法1 更适合标签化的媒体资源系统,方案2 更适合影视剧单片按照视频情节剪辑
结论3 模拟内容剪辑工作流,理解视频情节后进行视频剪辑,我们更倾向于 “利用大模型对剧情全局理解,再对结构化数据进行进行推理,从而产生结果”
方案指南的流程设计
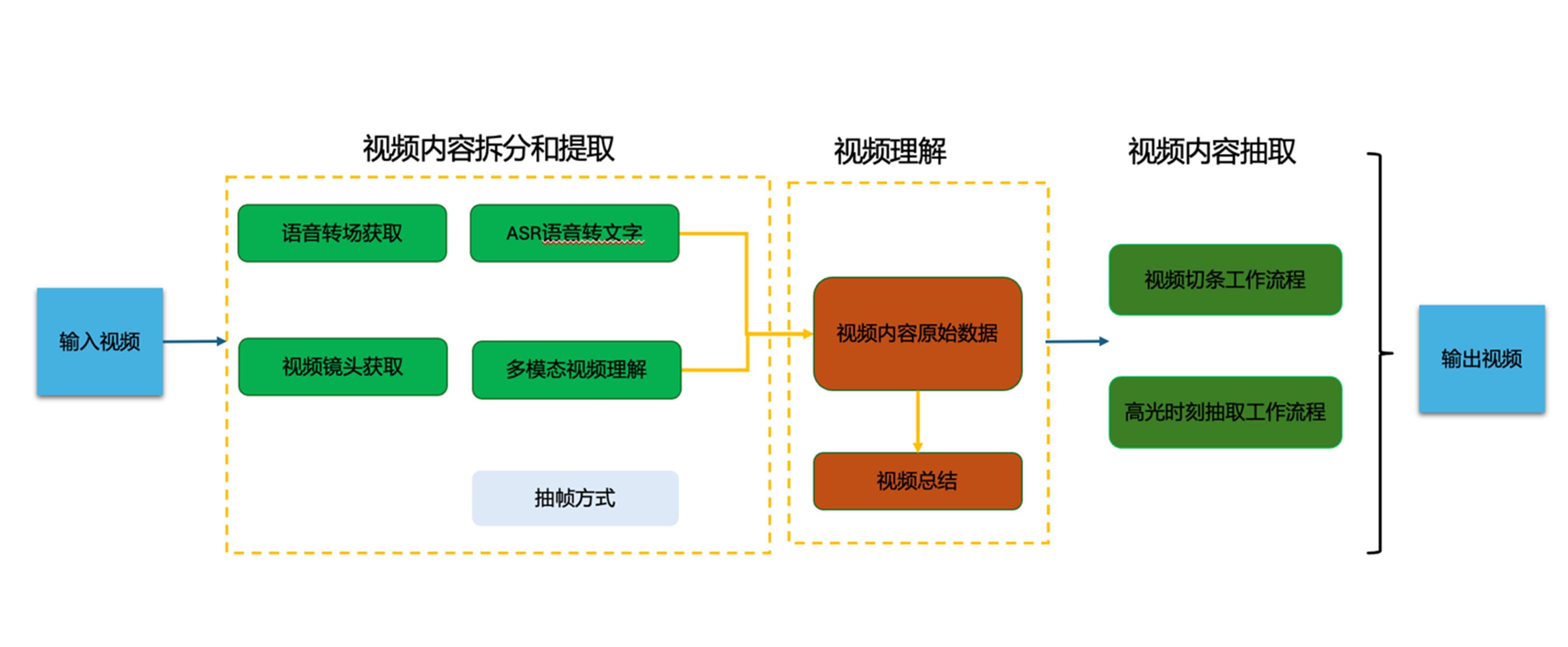
根据如上的结论1,结论2 和结论3,我们进行如下设计:
- 通过语音转场和视频镜头转场进行视频的拆分和提取,
- 再通过多模态模型进行综合理解,
- 然后再利用大语言模型按照用户需求和影视内容情节进行查找,得到内容片段组合
逻辑架构
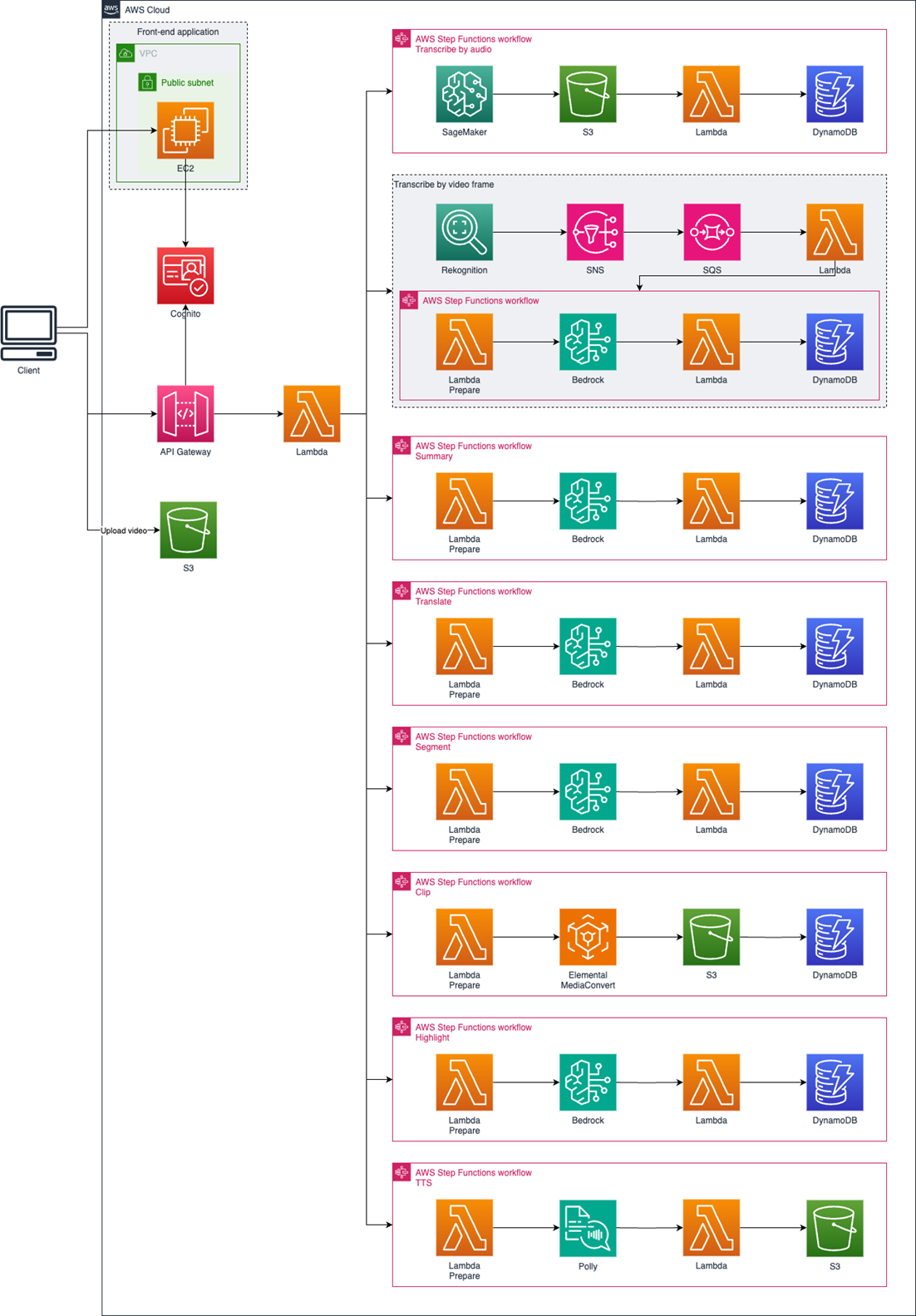
方案指南的技术架构和主要功能
技术架构
根据逻辑架构进行了技术架构设计,并以此进行了指南的开发
本方案提供了一个综合的视频处理系统架构,包括前端应用程序和后端的多个视频处理与分析工作流模块。
- 视频上传到S3存储桶后,通过API Gateway和Lambda服务处理客户端请求,以及协调各个工作流。
- 音频转录模块通过Amazon SageMaker、S3、Lambda等服务实现音频的提取,并将结果存储到DynamoDB中。支持导出srt格式的字幕文件。
- 视频理解模块通过AI服务Rekognition和Bedrock上的多模态大模型,以及SNS、SQS、Lambda和DynamoDB等多种服务,实现对视频帧活视频片段的理解、分析和处理。
- 视频摘要生成、视频字幕翻译、视频拆分、高光时刻等模块,充分利用了Bedrock上的大模型,然后把结果存储到DynamoDB中,生成的视频直接存储到S3。
方案指南的功能列表
- 视频理解:把音频转录为文字;基于视频片段抽帧或视频片段生成对镜头的描述
- 视频摘要:基于音频转录的文字或镜头描述,通过大语言模型进行总结/摘要
- 字幕翻译:将视频字幕文件从一种语言翻译为其他语言
- 视频剪辑:通过大语言模型理解音频转录文字或镜头的文字描述,根据用户需求拆分成小的视频片段
- 高光时刻:通过对视频的理解,生成精彩视频的片段
- 配音、字幕烧录:在生成高光时刻时,可使用自定义文字进行配音(旁白),并把字幕烧录到视频中
方案指南有如下优点
- 用户可以根据实际需求调整提示词和调用顺序,达到不同产出效果
- 不绑定任何模型,用户可以根据实际需求配置模型
- 在安全方面,操作都在客户账号下,保证媒体内容资源的安全,视频数据不会用于公共基础模型训练。
- 本方案提供了完整工具链对接方式和API。
- 本方案采用Serverless架构,无需运营人员考虑系统的并发和容量问题。
指南主要功能介绍和代码示例以及API使用介绍
多种方式的视频信息提取提取
本方案指南提供多种视频拆分和信息提取的方式,功能如下图所示
示例代码
多种模式的视频信息提取
a)利用语音
音频识别部分
model = whisper.load_model(
model_type, download_root="/opt/ml/code/models/", in_memory=True, device="cuda"
)
result = model.transcribe(source, **decode_options)
# language detection
audio = whisper.load_audio(source)
mel = whisper.log_mel_spectrogram(audio, model.dims.n_mels, padding=whisper.audio.N_SAMPLES).to(model.device)
mel_segment = whisper.pad_or_trim(mel, whisper.audio.N_FRAMES)
_, probs = model.detect_language(mel_segment)
lang = max(probs, key=probs.get)
在进行自动语音识别(Automatic Speech Recognition, ASR)时,偶尔会出现幻觉,为了减轻这种现象,需要引入语音活动检测(Voice Activity Detection, VAD)。对于不同的语言,使用擅长的VAD。
from funasr import AutoModel as FunasrModel
from silero_vad import get_speech_timestamps, load_silero_vad, read_audio
if lang == "zh":
vad_model = FunasrModel(
model="/opt/ml/code/models/vad_model", model_revision="v2.0.4"
)
res = vad_model.generate(input=source)
speech_timestamps = []
for row in res[0]["value"]:
speech_timestamps.append({"start": row[0] / 1000, "end": row[1] / 1000})
else:
vad_model = load_silero_vad()
wav = read_audio(source)
speech_timestamps = get_speech_timestamps(
wav,
vad_model,
return_seconds=True,
threshold=0.2, # Return speech timestamps in seconds (default is samples)
)
b)利用片段抽取视频
在默剧或者纪录片中,仅采用ASR对语音识别不够,需要基于视频帧或视频片段进行理解。当采用这种方式时,先使用亚马逊云科技的Rekognition服务对视频进行逻辑切分,即把视频根据镜头切分为若干个片段(segment)。然后基于片段进行抽帧,把同一个片段的图片发送到大语言模型进行理解。对于支持视频模态的大模型,则可以直接把一个视频片段直接发送给大语言模型进行理解。在这里为保证抽帧涵盖整个视频片段,减少遗漏,我们设计了抽帧逻辑。
def get_sample_points(start, end, sample_count=12):
step = (end - start) / (sample_count + 1)
center = (start + end) / 2
sample_points = []
for i in range(1, sample_count + 1):
point = start + i * step
if point == center:
rounded_point = int(round(point))
elif point < center:
rounded_point = int(math.ceil(point))
else:
rounded_point = int(math.floor(point))
sample_points.append(rounded_point)
return list(set(sample_points))
parameter_list = []
index = 0
for shot in shots:
start_time = shot["StartTimestampMillis"] / 1000
duration = (shot["EndTimestampMillis"] - shot["StartTimestampMillis"]) / 1000
video_bytes = process_segment(temp_file_path, start_time, duration)
# 上传LLM payload到S3,而不是原始视频
video_key = f"transcribe_video/{project_id}/{shot['StartFrameNumber']}.json"
s3_client.put_object(
Bucket=bucket_name,
Key=video_key,
Body=json.dumps(build_llm_payload(get_content_messages(video_bytes, "video"), language)),
)
parameter_list.append(
{
"index": index,
"start_time": str(round(shot["StartTimestampMillis"] / 1000, 2)),
"end_time": str(round(shot["EndTimestampMillis"] / 1000, 2)),
"next_start_time": str(round(shot["next_start_time"] / 1000, 2)),
"previous_end_time": str(round(shot["previous_end_time"] / 1000, 2)),
"parameter_key": video_key,
}
)
index += 1
视频摘要功能示例
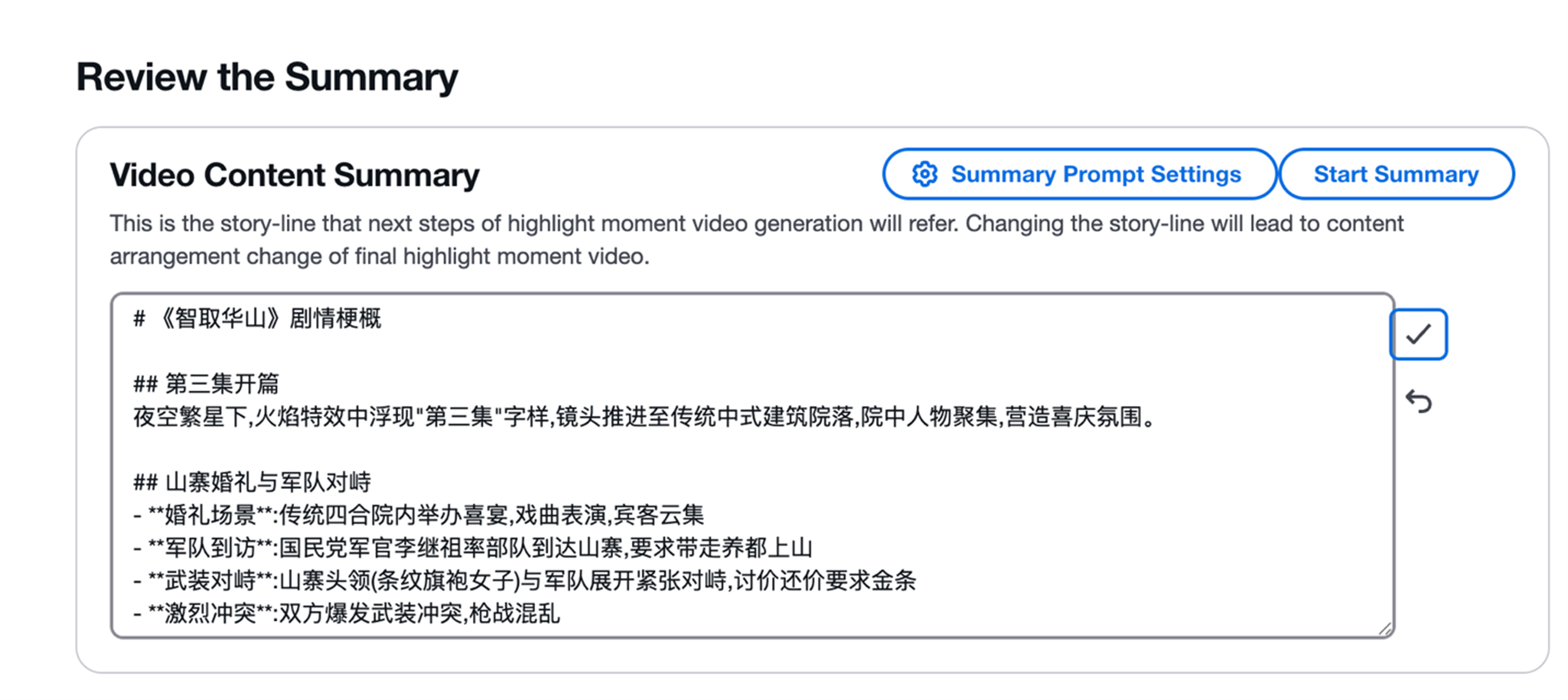
本方案指南,能够通过视频分段和内容提取得到原始的视频内容信息,通过大语言模型可以进行视频内容的摘要
提示词示例
You are a professional video editor, skilled in analyzing video shot sequences and extracting their core content. I will provide you with a series of video shot descriptions in chronological order. Your task is to create a summary describing what the video is about.
Note that this summary needs to be completed in the same language as the shot description. If the shot description is in English, then the summary you create must also be in English.
Please carefully read the following shot descriptions:
<document>
${shot_str}
</document>
Please follow the steps below:
1. Read through the sequence of shot descriptions carefully to ensure understanding of the overall content and the connections between shots.
2. Extract the core scenes and key information from the lens sequence.
3. Organize these core scenarios and key information into a coherent summary. The summary content needs to be structured.
4. Please use the ${language} language for output.
Please only output the summary content, do not add any additional explanations or comments.
智能切片功能示例
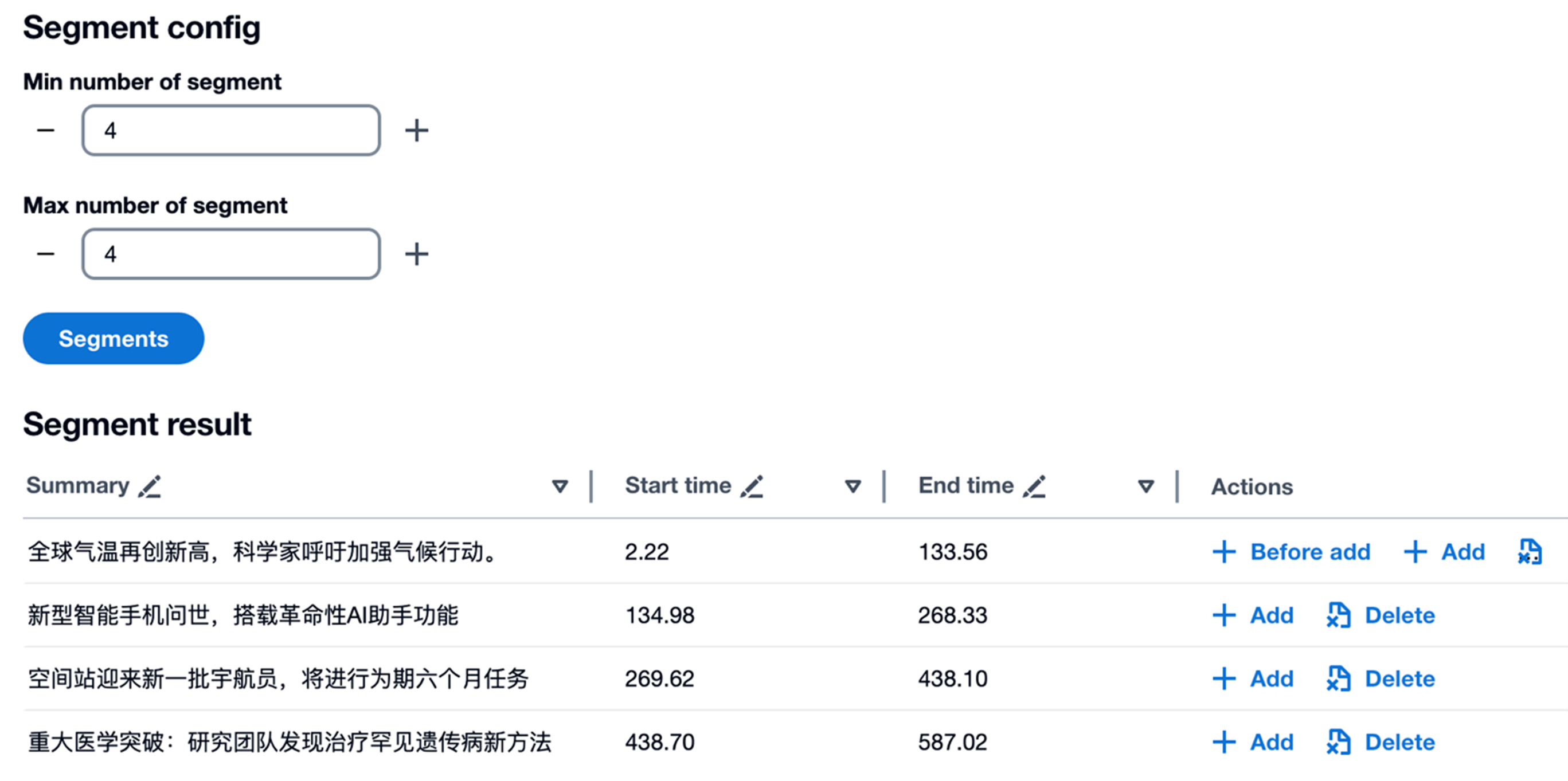
本方案指南,能够智能识别长视频中的关键内容点,将冗长的视频精准切分为多个主题鲜明的短视频片段。
用户可通过本方案页面上传视频文件到s3,也可以直接指定s3上现有的视频文件。然后即可对视频进行理解。常规视频可使用基于音频的理解。对于记录片或者默剧,可使用基于视频帧/视频片段的方式。
接下来即可进行分段处理,用户可以设置希望分段的最大值和最小值,也可以把最大值和最小值都设置为0,让大语言模型根据内容进行自由分段。提交分段设置后,大语言模型根据内容进行分割,并把结果展示给用户。
用户可对开始、结束时间进行调整,也可以手动增加、删除分段。确认后,点击切割按钮对视频文件进行实际切割,方案会把最终生成的视频存放到S3上。
无论是分段还是其他需要视频内容提取的操作都是用大语言模型配合动态提示词来完成
示例代码
"You are a professional text editor, skilled in segmenting long texts and summarizing topics.
Please carefully read the following sentences and segment the content according to the given rules.
I will edit the video based on your segmentation results.\n\nNote that these segments and summaries need to be completed in the same language as the text.
If the text is in English, then the segments and summaries you create must also be in English
.\n\nsentence:\n<document>\n${data}\n</document>\n\n\nPlease follow the following guidelines:\n\n1. Combine consecutive, thematically related sentences into one concise summary of the topic.\n2.
Ensure the topic is concise, clear, and engaging.\n3. Output the summarized topics and corresponding sentence number ranges in order, using a hyphen to connect the starting and ending sentence numbers (e.g., 1-10).\n4. Sentences within each paragraph must be continuous, and cross-sentence segmentation is not allowed.\n5. All sentences must be included in paragraphs.\n6. Please output in the original language.\n7. Do not use any single or double quotes in the summary.\n\nPlease summarize into a minimum of 1 and a maximum of 4 paragraphs\n\nPlease strictly follow the following JSON format to output your segmented results:\n\n[\n{\"start\": <starting sentence number>, \"end\": <ending sentence number>, \"seg\": <paragraph number>, \"summary\": \"<summarized paragraph content>\"}\n{\"start\": <start sentence number>, \"end\": <end sentence number>, \"seg\": <paragraph number>, \"summary\": \"<summarized paragraph content>\"}\n...\n]\nNote:\n\n- The paragraph number (seg) must be a consecutive integer.\nPlease ensure that all content from sentence 1 to sentence 658 is included in your segment.\n- Only output the content in JSON format, no other explanations are needed.\n\nPlease remember that high-quality segmentation and summarization are crucial for the subsequent video editing work. We look forward to your professional performance!
def lambda_handler(event, context):
if event["segment"]["payload"].get("error"):
raise Exception(event["segment"]["payload"].get("error"))
transcribe_job_id = event["transcribe_job_id"]
job_id = event["job_id"]
segment = event["segment"]["payload"].get("body")
if segment.startswith("```json") and segment.endswith("```"):
segment = segment[7:-3]
try:
segment_dict = json.loads(segment)
except json.decoder.JSONDecodeError:
logger.info(segment)
segment_dict = parse_json(segment)
sentences = get_all_sentences(transcribe_job_id)
i = 0
with segment_table.batch_writer() as batch:
for item in segment_dict:
segment = {}
segment["start_time"] = sentences[item["start"] - 1]["start_time"]
segment["end_time"] = sentences[item["end"] - 1]["end_time"]
segment["summary"] = item["summary"]
segment["job_id"] = job_id
segment["index"] = i
i = i + 1
batch.put_item(Item=segment)
高光时刻功能示例
在当今信息爆炸的时代,视频内容日益丰富,但用户时间有限。为了解决这一矛盾,通过本方案能够智能识别并提取视频中最具价值、最吸引人的片段,为用户提供精华内容体验。
在流程上,系统先对原视频进行理解,并对内容进行文字摘要。然后根据场景,比如产品发布会、短剧,传入不同的提示词模板,即可得到不同场景下的高光时刻集锦,用户可对大语言模型挑选出来的高光时刻片段进行调整,可以勾选其他片段,也可以删除现有片段。确认后,点击生成按钮,即可合成最终的高光时刻视频。
在提取高光时刻片段时,有时我们需要加入旁白,而不采用原音。本方案提供此支持,并支持多语言旁白和字幕。
示例代码
在提取高光时刻场景,用户除了希望提取精彩片段,还希望精彩片段在一个时间范围内,以便推广。在利用LLM进行提取精彩片段时,即使明确告知LLM每个片段时长以及需要提取时长,也经常出现一次不能达到目标情况。可以多次迭代以便LLM选出合适内容。
# Determine which prompt to use based on the current step
if current_highlight_step == 0:
# Initial selection - ask for complete highlight selection
task_prompt = INITIAL_TASK_PROMPT
format_prompt = INITIAL_FORMAT_PROMPT.format(second_limit=second_limit)
elif highlight_second > current_highlight_duration:
# Need to add more shots
diff_time = round(highlight_second - current_highlight_duration, 2)
task_prompt = INCREMENTAL_TASK_PROMPT
format_prompt = INCREMENTAL_FORMAT_PROMPT.format(
current_highlight_duration=current_highlight_duration,
diff_time=diff_time,
current_highlight_shots=current_highlight_shots,
)
else:
# Need to remove some shots
diff_time = round(current_highlight_duration - highlight_second, 2)
task_prompt = DECREMENTAL_TASK_PROMPT
format_prompt = DECREMENTAL_FORMAT_PROMPT.format(
current_highlight_duration=current_highlight_duration,
diff_time=diff_time,
current_highlight_shots=current_highlight_shots,
)
提供完整的API
本方案提指南供了OpenAPI格式的API,供第三方调用。完整API文档在部署完成后即可浏览。
下图为方案部分API,,用户在API页面展开浏览和测试每一个方法,每个方法的使用具有详细的解释,每个参数也有对应schema说明。
在API鉴权方面有三种模式:
- prod,生产模式,默认值,调用API时需要指定API key和OIDC(cognito)的jwt token
- api,API模式,调用API时仅需API key。此模式主要用于和第三方系统集成。
- dev,开发模式,调用API时不进行鉴权,可以在OpenAPI文档上调用和测试API。禁止在生产环境中使用开发模式。
实际应用场景的介绍
在实际客户应用中,根据客户实际情况,配置方案指南,调试提示词,并给出每个客户最佳使用方法是实际应用的难点。
我们需要充分了解:
- 客户素材库中视频资源格式(如 MP4、MOV、AVI 等)与分辨率(从 480P 到 4K 不等)
- 不同类别的输入视频形式:比如长视频(如数小时的访谈、赛事录像)、无声视频(如默剧、产品演示片段)的复杂情况,需通过分类处理策略适配多样化素材。
- 客户需要产出视频的形式:比如高光时刻,视频总结,视频分段,视频摘要
- 客户需要的工作流:比如自动化的批量产生视频浓缩、和原有的成熟工作流相结合
下面是一些典型情况的举例:
- 对于有音频的视频,采用 ASR 语音识别技术(如 Whisper 模型)提取音频语义,转化为文字信息作为剪辑依据;
- 对于无音频或音频无效的视频,以及含硬字幕的素材,通过抽帧工具按合理频率提取画面帧,再借助 OCR 技术提取字幕或画面文字,补充内容理解维度。
- 而对于需深度画面分析的场景(如识别无声视频中的动作逻辑、复杂场景细节),则直接调用支持视频输入的大语言模型,将视频片段作为输入,让模型生成结构化的画面描述,为后续智能剪辑提供精准的内容参考,确保各类素材都能被有效解析。
下面是实际的应用案例:
案例1 演出和发布会视频自动剪辑
每年的re:Invent云计算峰会无疑是科技行业的年度盛事,作为全球最具影响力的云计算技术峰会之一,它总能带来令人目不暇接的新产品发布、技术突破与战略方向。然而,随之而来的是海量视频内容和庞大的信息流,如何从中提炼出真正的精彩时刻,一直是市场团队面临的巨大挑战。
往年,市场部团队需要投入大量人力进行视频内容的手工筛选和精彩片段的提取工作。这一过程不仅耗时耗力,还面临着主观判断可能导致的关键信息遗漏。团队成员需要观看数百小时的演讲、工作坊和技术演示,从中识别并剪辑出最具价值的内容片段,这种方式效率低下且难以保证质量一致性。
在2024年的re:Invent后,市场团队引入了本方案,彻底改变了这一工作流程。该方案利用先进的视频内容分析技术,能够自动识别演讲中的关键产品发布、重要技术公告、观众热烈反应以及演讲者的精彩表现等重要时刻。实施这一方案后,市场团队处理re:Invent效率大幅提升。方案完成初步筛选后,市场团队只需进行最后的审核和微调。
更重要的是,这一方案不仅减轻了工作量,还提高了内容质量。实现更全面的覆盖,确保不会遗漏任何关键时刻;更快速的内容发布,提升市场反应速度。
客户要求:
- 客户快速的通过现场录制得到1K视频,大小在10G左右,
- 输入视频为:长度2-3小时,每天有30-40个视频, 视频中的有效部分一直都有演讲声音,为英语,无字幕
- 每个视频为转换为输出的浓缩视频,可以投放到社交媒体的短视频,每个3-4分钟
- 客户需要的工作流:自动化的批量产生
设计的最佳应用方法:
客户通过API调用的方式实现自动化工作流
- 调用Project方法,自动化同时建立5-10个highlightmoment 的project
- 获得project_id后,通过调用TrancribeJob方法同时建立audio方式的视频内容提取
- 音频信息提取成功后通过调用SummaryJob方法,并发建立摘要任务
- 摘要成功后,通过并行调用HighlightJob方法设置length参数为3分钟
- 通过调用Highlight方法得到最终产出视频
推荐的highlight moment提示词为:
你是一名专业的视频剪辑师。这是你需要剪辑的视频介绍:
<video_intro>
${summary_str}
</video_intro>
以下是一系列按时间顺序排列的视频镜头,包括用<shot_description>标记的对话内容和<duration>标记的镜头时长(秒)。
<shot_sequence>
${shot_str}
</shot_sequence>
你的任务是${task_prompt}
剪辑出高光时刻,高光时刻只需要包括新产品科技发布, 精彩的示例
严格按照原片的时间顺序排列这些不调整先后顺序
请注意,一个高光时刻可能跨越多个连续镜头。为保持对话的连贯性,你可以将这些相关镜头都包含在高光视频中。
为了连续性,在选择高光时刻时请尽可能包括多个连续的镜头。对话内容不要太突兀。尽量保持连贯性。如果一个镜头小于5秒,且前后的镜头都没有被选为高光时刻,那么它也不该被选中。
每个高光时刻包含的若干个连续镜头中的对话应该是完整的,不应该突然跳转到另一个高光时刻。
请剔除片头曲和片尾曲 ${format_prompt}
请删除头尾空白部分
案例2 影视视频的多国语言二次创作
中国头部的传媒公司,具有大量多语种的记录片资源,需要进行剪辑,二次创作,全球多个社交媒体平台进行分发。
客户面临着如下问题:
- 需要大量人力,而且周期长,难以满足运营节奏
- 对于视频切条的时间准确度无法把握
- 多语种需要专业人才,成本高,周期长,而且一个片子里可能存在不同语言
- 需要多个部门配合
客户实际要求:
- 片源形态大多数为记录片,2K视频,大小在10G左右,
- 输入视频为:长度1小时,每天有10个视频, 视频中有多国语言的解说
- 每个视频进行分段,每个5-10分钟
- 需要相对完整工具链和工作流
设计的最佳应用方法:
客户基于视频理解的视频编辑指南资产为技术底座,和其现有的工作流结合
- 媒体资源库内容批量上传的S3
- 按照步骤进行批量的音频和视频转录
- 按照缺省方式进行视频的理解
- 按照提示词设计的方式进行视频分段,大概8-10段
- 从S3中下载分段后的结果
推荐的分段提示词为:
你是一位专业的文本编辑,擅长分割长文本并概括主题。请仔细阅读以下句子,并根据给定规则进行分段。
我将根据你的分段结果编辑视频。
注意:这些分段和概括需要用与文本相同的语言完成。
如果文本是英语,则你创建的分段和概括也必须使用英语。
请遵循以下指南:
1. 将连续的主题相关句子合并为一个简洁的主题概述。
2. 确保主题简洁、清晰且引人入胜。
3. 输出概括的主题和对应的句子编号范围,使用连字符连接起始和结束句子号(例如 1-10)。
4. 每个段落内的句子必须连续,跨句子分段不允许。
5. 所有句子必须包含在段落中。
6. 请以原始语言输出。
7. 不要在概括中使用任何单引号或双引号。
请概括为最小1个和最大4个段落。请严格遵循以下JSON
{\"start\": <starting sentence number>, \"end\": <ending sentence number>, \"seg\": <paragraph number>, \"summary\": \"<summarized paragraph content>\"}\n{\"start\": <start sentence number>, \"end\": <end sentence number>, \"seg\": <paragraph number>, \"summary\": \"<summarized paragraph content>\"}\n...\n]\n
注意:
- 段落号(seg)必须是连续整数。请确保从句子1到句子658的所有内容都包含在你的分段中。
- 仅输出JSON格式内容,不需要其他说明。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心: 云端创新的引领者
探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用

|
 |