亚马逊AWS官方博客
Amazon Connect结合Strands框架及Bedrock Agent Core的智能客服机器人解决方案(实践篇)

|
延续之前发布的基于Bedrock和Amazon Connect打造智能客服自助服务设计篇,本博客将展示智能客服自助服务领域中如何利用Strands框架和Amazon Connect进行集成,同时结合Bedrock AgentCore Memory及Runtime功能的最佳实践及解决方案技术框架。
1. 客户对智能客服自助机器人的评价指标:
客户对智能客服自助机器人的评价指标,一般会从 服务效果、体验感受、系统性能、管理运营 四个维度来衡量。
1.1服务效果类
- 问题解决率(Resolution Rate):机器人能否真正帮客户解决问题。
- 首次解答正确率(First Contact Resolution, FCR):一次对话是否就能给出准确答案。
- 知识覆盖率:机器人能回答的常见问题比例。
- 人工转接率:需要转人工的比例(越低说明机器人更有效)。
1.2. 用户体验类
- 响应速度:从提问到答复的时间。
- 交互自然度:语言是否流畅,是否像与人对话。
- 多轮对话顺畅度:是否能记住上下文,避免重复提问。
- 个性化程度:是否能基于用户历史、偏好提供定制化回答。
- 满意度评分(CSAT):客户对服务的即时评价。
1.3. 系统性能类
- 稳定性与可用性:是否出现崩溃、超时、答非所问。
- 并发处理能力:高峰期响应是否依然流畅。
- 准确率与召回率:意图识别是否精准,知识检索是否全面。
- 安全与合规性:是否保障用户隐私与数据安全。
1.4. 管理与运营类
- 知识更新及时性:知识库内容是否快速更新。
- 运营可视化:后台是否提供对话分析、用户画像、热点问题统计。
- 自我学习与优化能力:是否能通过反馈持续改进。
- 人工客服协同度:转人工时是否无缝衔接。
- ROI 与成本节省:减少人工客服成本、提升整体效率。
2. 基于GenAI智能客服自助系统设计中Agent框架选择的因素
在基于 GenAI 的智能客服自助系统设计中,选择 Agent 框架 时要考虑多个因素,因为 Agent 不仅是“问答机器人”,还需要作为一个可以调用知识库、业务系统、工具(Tool)和人工客服的智能体来运作。
目前Agentic AI不断发展,新技术新模式层出不穷,主要往更智能化,更自动化的方向发展,但在智能客服领域主要是要提高客户满意度,真正帮助客户解决问题,该场景需要双方互动,因此从目前实际项目效果来看WorkFlow模式更适合该场景,本次实践也是采用了Stands框架中的WorkFlow来实现。
2.1技术能力与适配度
大模型适配:是否支持接入多种基础模型,避免锁定单一模型。
多工具调用:能否灵活调用数据库、API、CRM、ERP、支付系统、工单系统等。
上下文管理:支持长对话记忆、多轮对话追踪、会话状态管理。
知识增强 (RAG):是否支持文档检索、知识图谱、FAQ知识库集成。
2.2系统架构与扩展性
模块化设计:是否支持分层架构(对话管理、任务代理、工具代理)。
可扩展性:能否快速增加新场景、新业务流程。
跨渠道支持:是否支持接入Web、App、微信、WhatsApp、电话IVR等渠道。
编排能力:能否用工作流或低代码方式编排对话与工具调用。
2.3性能与稳定性
实时性:响应是否快速,能否满足毫秒级响应需求。
并发能力:是否能支撑高并发场景(电商促销、游戏活动高峰)。
健壮性:应对模型回答错误、API超时等异常时,是否有降级机制。
2.4安全与合规
数据安全:是否支持敏感信息脱敏、加密存储、访问权限控制。
合规要求:是否满足 GDPR、CCPA、网络安全法等法规要求。
可控性:是否有安全护栏,防止模型生成不当内容(越权操作、违规回答)。
2.5运维与优化能力
可观测性:是否能追踪对话日志、Agent调用链路,便于问题定位。
可训练性:是否支持持续学习(基于用户反馈优化)。
A/B 测试:能否在不同 Agent 策略或模型之间做对比实验。
成本控制:调用大模型的 Token 消耗与框架优化能力(如缓存、混合模型调用)。
3. Amazon Connect结合Strands和Bedrock AgentCore智能客服自助系统架构设计
3.1 解决方案High Level设计
本次实践采用Amazon Connect的Chat文字聊天作为客户接入方式,整个自助服务的流程控制采用Amazon Connect的Workflow设计实现,客户输入后由Connect通过lambda来调用GenAI模型来实现意图识别,基于Bedrock的RAG知识库查询,基于Stands框架的的 Multi Agent来实现自助服务,不同的意图会对应不同的处理流程,详见图1。
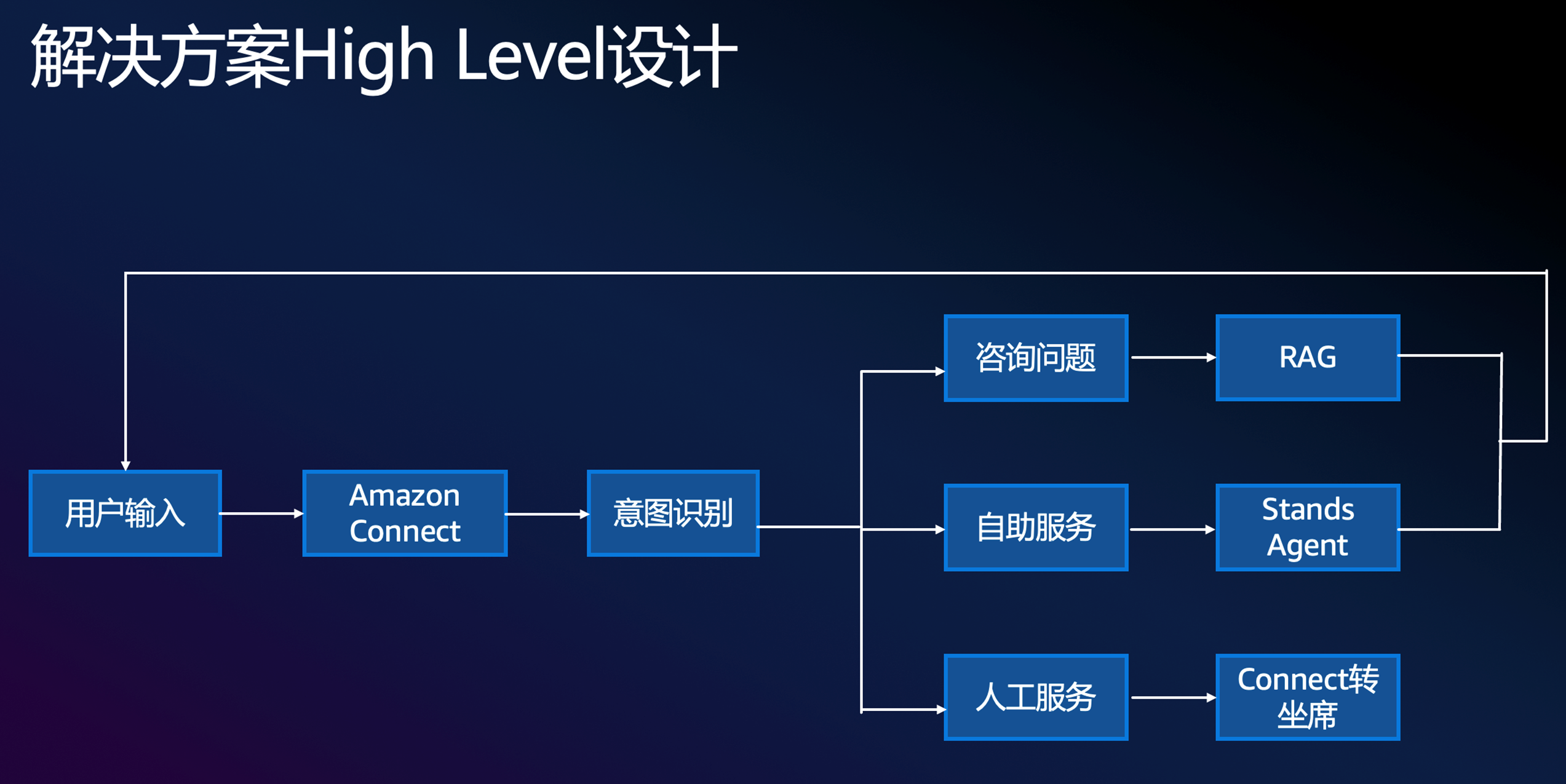 |
3.2 系统架构设计
整个解决方案可以同时支持电话及文字聊天等多渠道呼叫中心解决方案,不同的接入渠道采用统一的流程管理。整体方案设计中以Amazon Connect作为呼叫中心平台核心服务平台,同时采用Amazon Lex作为自主服务组件,Amazon Lex以及Amazon Connect Content Flow通过调用Lambda来实现对Bedrock Cluade模型的调用以及Bedrock 知识库的调用。详细流程见图2.
业务流程说明:
- 通过内部CRM系统整理知识库文件并放入S3,采用Bedrock知识库服务并同步S3数据源
- 客户通过文字聊天发起服务并进入connect服务
- Connect通过Workflow定制流程并调用lex进行对话交流
- Lambda实现客户意图识别及调用AgentCore Memory实现会话记忆
- Connect workflow获取到客户自助服务就调用Lambda
- Lambda调用基于Strands框架编写并运行在AgentCore Runtime上的Agent实现自助服务
- 自助服务满足不了客户需求,转人工坐席
- 坐席调用AgentCore Memory长期记忆功能获取之前对话总结并为客户继续提供服务
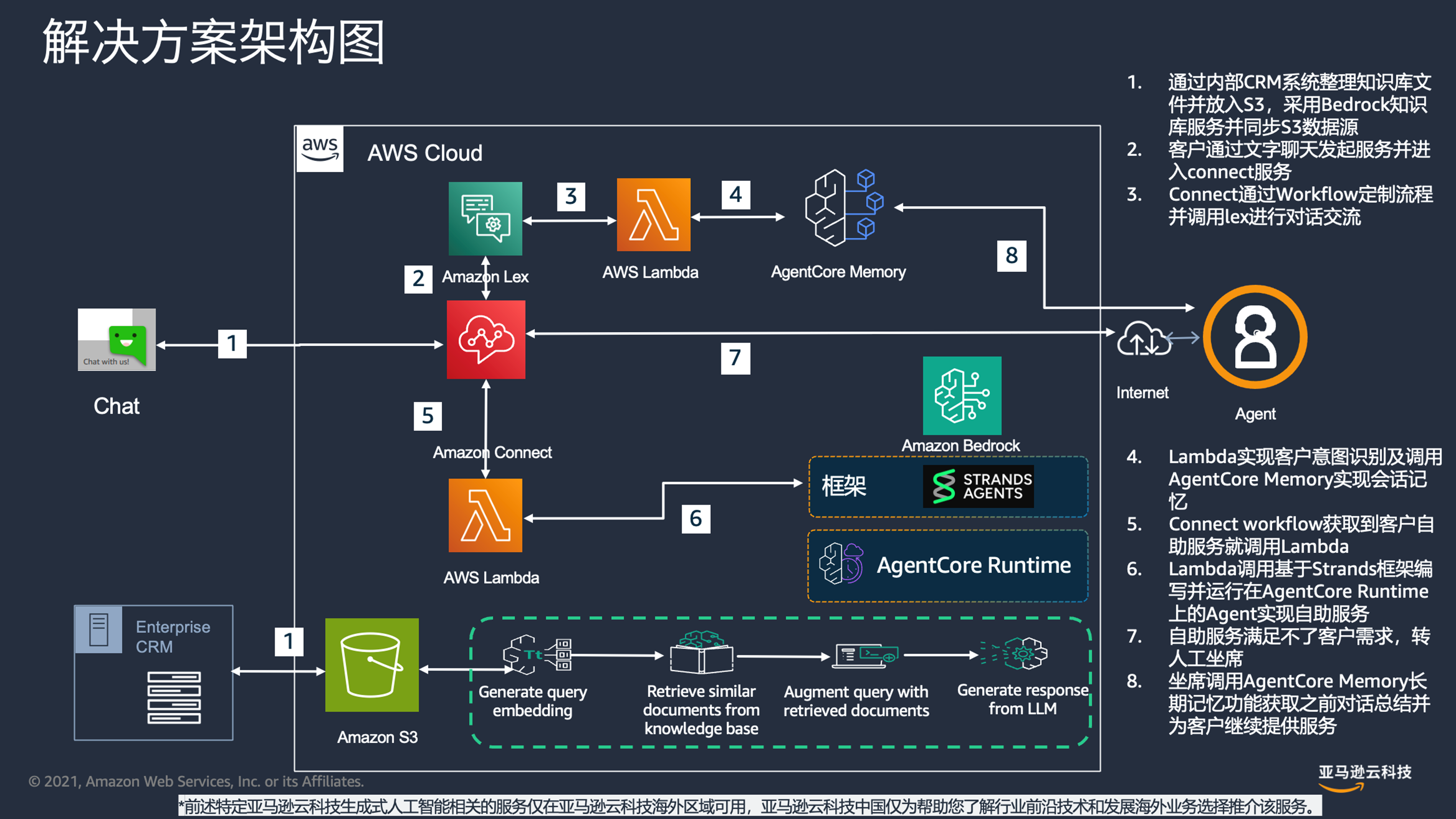 |
图2 详细系统架构设计图
3.3 对话记忆功能实现解析
如何实现对话记忆功能有可以有多种方案,之前博客采用的是利用Amazon Connect的随路数据来实现。本次采用Bedrock AgentCore Memory最新服务来实现。
Amazon Bedrock AgentCore 的 Memory 模块是一个由 AWS 托管的持久化记忆系统,用于存储和管理 AI Agent 的对话和知识。它提供短期记忆(short-term memory)和长期记忆(long-term memory)两种模式。短期记忆负责在一次会话中记录最近的交互内容(例如最近几轮对话),确保代理能够“记住”当前对话的上下文。长期记忆则从对话中提取结构化的关键信息,在多个会话之间保留知识,使Agent能够“学习”用户偏好、事实和摘要等信息。
Memory 模块在架构上采用分层存储策略:短期记忆层存储原始交互事件作为即时上下文,长期记忆层存储从事件提取的概要知识。Memory 服务背后实现了自动的信息处理流水线:当新的事件被存储时,如果 Memory 配置了长期记忆策略,服务会异步地对事件内容进行分析(例如调用基础模型)来提炼出可长期保存的知识片段。
所有数据由 AWS 以 加密 方式存储,并使用命名空间(namespace)进行隔离分区,确保不同应用或用户的记忆数据彼此分隔。这一完全托管的记忆基础设施让开发者无需自己搭建数据库或向量存储,就能方便地让 Agent 拥有记忆功能。
如图3所示是本次实践采用AgentCore Memory,并充分利用了长期记忆,如摘要信息来简化客服转坐席的总结功能,同时也可以实现自动语义识别来提取信息写入CRM系统,详细参加图3。
 |
图3 AgentCore Memory功能
3.4 Agent框架及运行解析
本次实践采用Stands框架来实现了具体Agent。并和Benrock AgentCore Runtime结合,每次调用Agent就是启动一次Bedrock AgentCore Runtime。
Bedrocl AgentCore Runtime 是一款高度安全、弹性、高效能的 Serverless Agent 托管平台,它让企业无需为基础设施烦恼,即可专注 Agent 业务开发,并满足生产级安全、成本和可扩展性需求。支持多步逻辑和异步任务执行,Runtime 可保持会话状态长达 8 小时,适合复杂推理和长流程任务,采用按实际计算资源使用计费方式,计算只有在 Agent 真正执行时才计费,节省大量因等待外部 LLM 或 API 的空闲时间费用,非常适合客服应用场景。
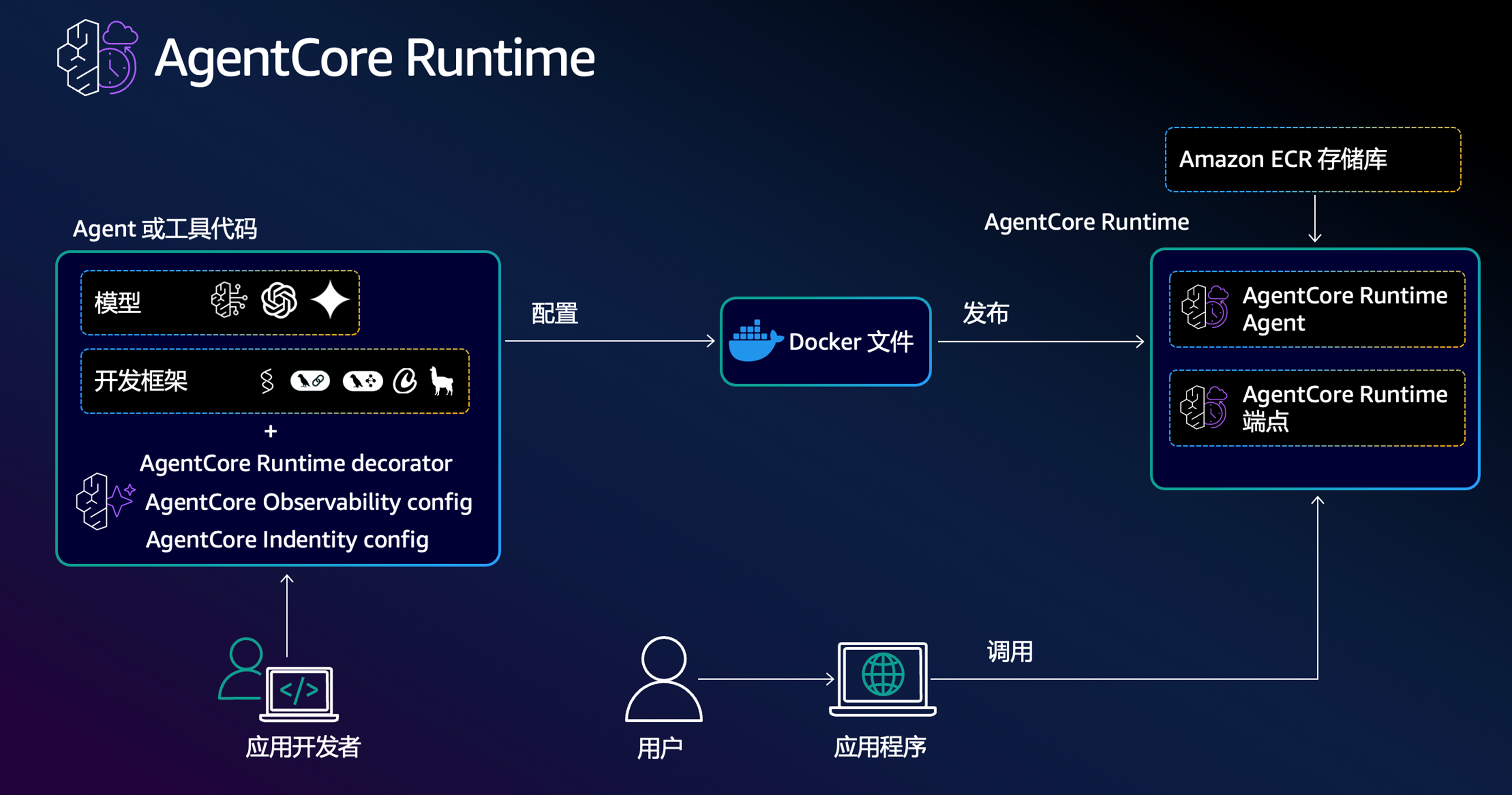 |
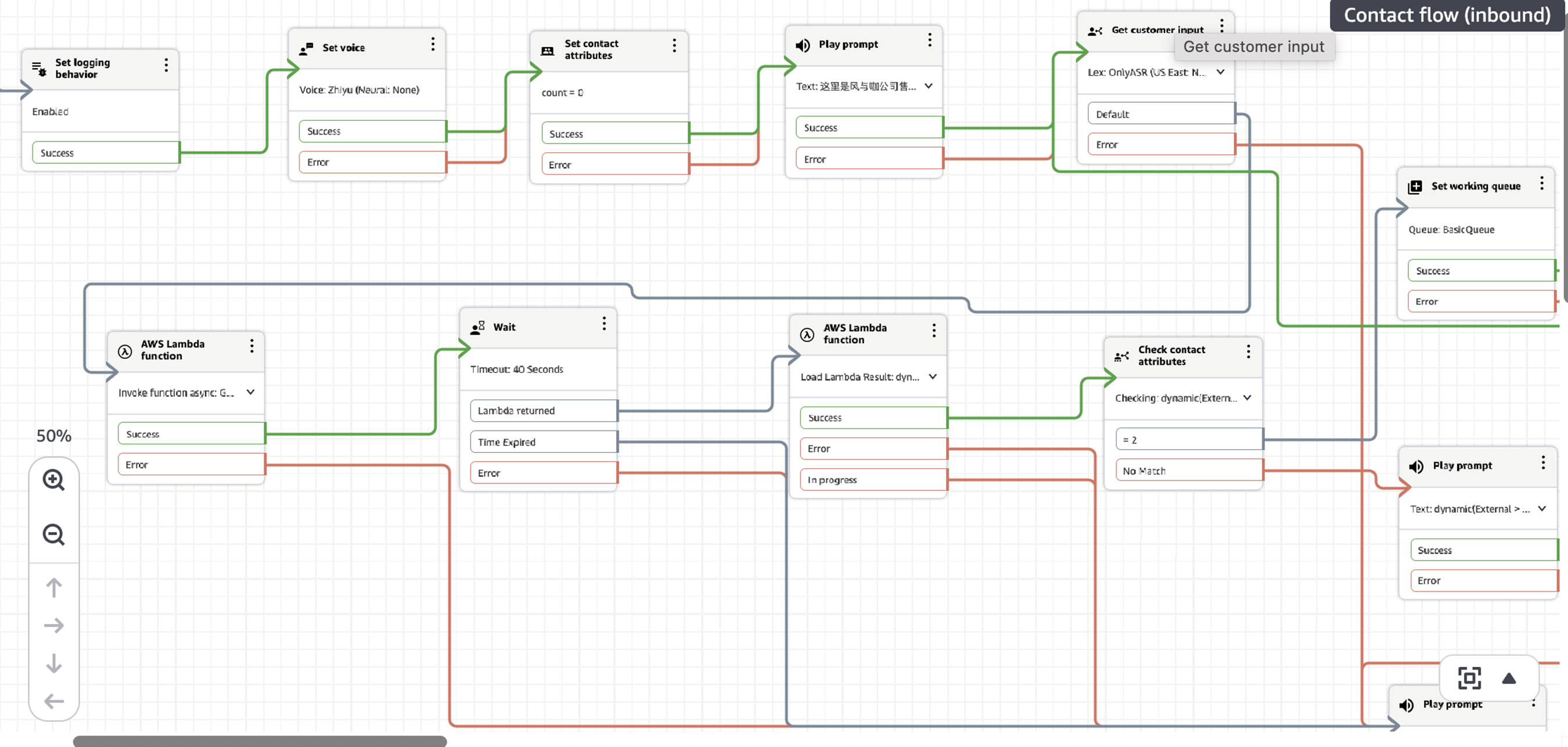
3.3 Amazon Connect ContentFlow调用Lambda的最佳实践
在Amazon Connect ContentFlow中调用Lambda实现和外部系统集成时如果采用同步模式,Lambda最大执行超时时间是8秒,这个现在在调用大语言模型时如果任务比较复杂,执行会超过8秒,这会导致这个流程报错。为解决这个问题可以采用最新的异步调用模式,这个可以将最大执行时间延长到60秒,肯定可以满足要求。具体调用方法参加下图。先在AWS Lambda Function调用时候选择异步模式,然后设置Wait节点等待执行完成,执行完成后再次调用AWS Lambda Function节点,并选择Load Lambda Result来获取执行结果。这样可以解决超时瓶颈问题。
 |
4. 具体代码实现及部署解决方案
4.1本次实践客户场景描述
- 本次实践以制造业海外售后服务为背景,通过智能客服来实现产品售后服务咨询,订单查询,自动退货等实际场景,如果问题复杂无法通过自助服务解决将自动转接人工坐席。
- 智能客服统一采用基于Stands框架的Multi Agent架构,将意图识别,知识库调用,工具调用统一封装为各种Agent服务,可以实现简单智能调用。
4.2Amazon Connect业务流实现:
- 利用Connect Content Flow来实现整个业务场景。
- 通过Lex来获取用户输入,支持语音和Chat两个渠道。
- Connect Content Flow通过异步调用Lambda实现智能Agent的调用,并返回最佳回复给到客户,整个过程支持多轮对话和多业务处理。
-
- 当Agent返回结合告知该服务需要人工坐席接入则系统自动转人工坐席并提供自动服务的全程对话摘要,避免坐席重复询问之前的问题,提升用户体验。
 |
4.3 Stands Agent及Bedrock AgentCore Runtime部署及实现:
- Strands Agents SDK 是由亚马逊云科技开源的Agent软件开发工具包,它采用模型驱动的方式,旨在简化和加速 AI 智能体的构建与部署。它的主要优势:
- 开发流程简化:开发者只需定义核心的提示词(Prompt)和可用的工具列表,而无需编写复杂的工作流代码。极大降低了开发成本,加快上线速度。
- 广泛的生态支持:SDK 具有高度的开放性和兼容性,支持包括 Amazon Bedrock、OpenAI、Ollama 等在内的多种大型语言模型。并且,预置了文件管理、代码执行、网络请求等多种实用工具,开箱即用。
- 支持多智能体编排:该 SDK 引入了先进的 Swarm 架构,支持多智能体并发处理和协同工作。这对于处理复杂任务、提升处理效率和准确率至关重要。
- 在本次的智能客服机器人的实践中,我们采用了如下的多Agent编排的架构,让负责的客服任务能够更精确有效的执行。
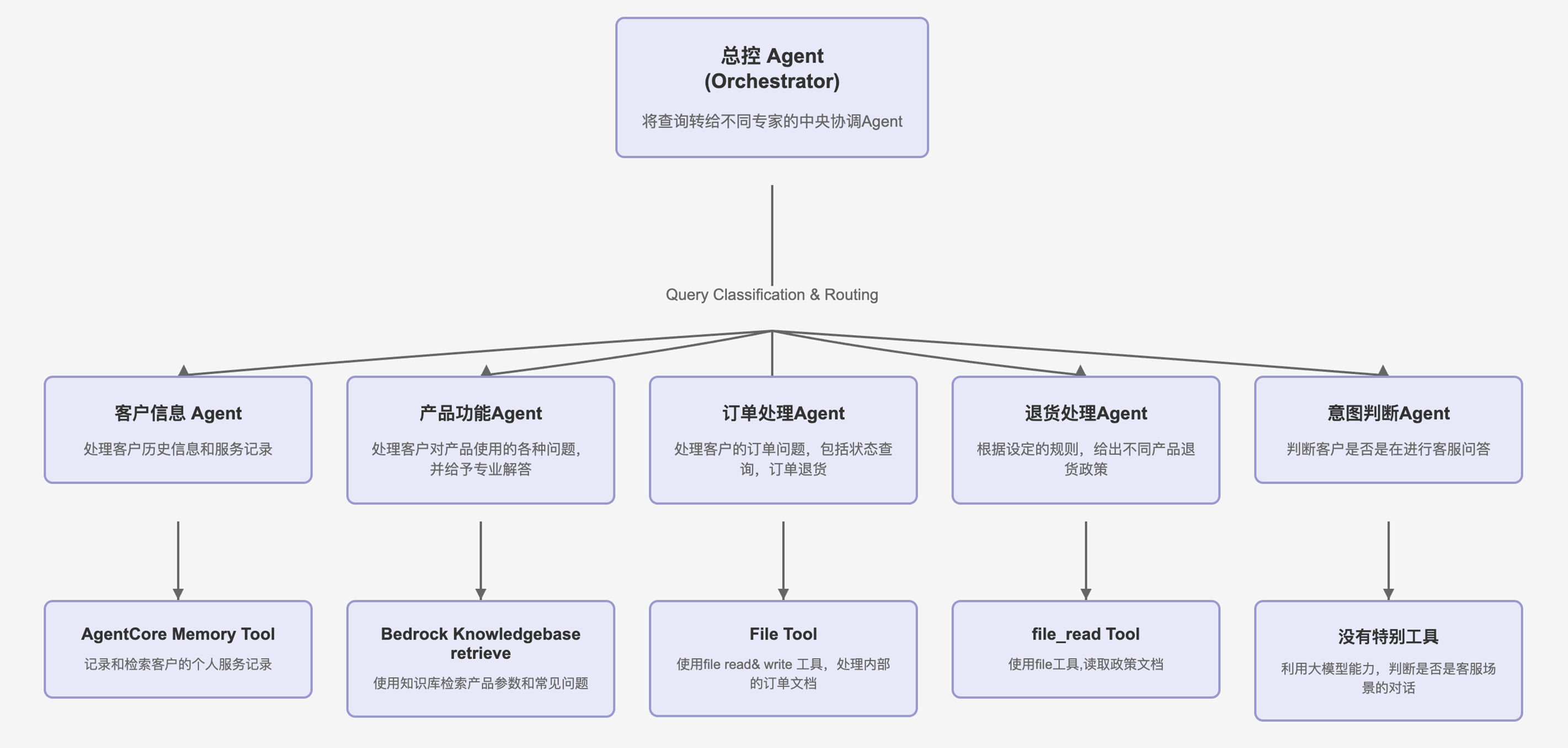 |
- Strands SDK 多Agent的关键代码实现:
- 总控Agent的代码实现:
bedrock_model = BedrockModel(
model_id="global.anthropic.claude-sonnet-4-20250514-v1:0",
temperature=0.3,
top_p=0.8,
)
# Create the supervisor agent with all specialist Agents
self.current_agent = Agent(
name="Supervisor Agent",
system_prompt=self._build_system_prompt(),
model=bedrock_model,
state={"session_id": session_id},
tools=[
update_user_id,
get_product_usage,
start_return_process,
check_order_status,
],
)
-
- 子Agent的代码实现:
@tool
def retrieve_from_kb(query: str) -> Dict[str, Any]:
"""
Retrieve information from a knowledge base based on a query.
Args:
query: The search query
Returns:
Dictionary containing retrieval results
"""
try:
# Call the retrieve tool directly
retrieve_response = retrieve.retrieve(
{
"toolUseId": str(uuid.uuid4()),
"input": {
"text": query,
"score": MIN_RELEVANCE_SCORE,
"numberOfResults": MAX_RAG_RESULTS,
"knowledgeBaseId": DEFAULT_KNOWLEDGE_BASE_ID,
"region": AWS_REGION,
},
}
)
logger.info(f"retrieve_response: {retrieve_response}")
return retrieve_response
except Exception as e:
logger.error(f"Error details: {str(e)}")
raise
return {
"status": "error",
"message": f"Error retrieving from knowledge base: {str(e)}",
}
def init_agent(agent_name: str) -> Agent:
return Agent(
name=agent_name,
system_prompt=faq_agent_system_prompt,
model=bedrock_model,
tools=[retrieve_from_kb, check_order_status],
)
4.4 Bedrock AgentCore Memory调用实现:
- Amazon Bedrock AgentCore 是一个由亚马逊云科技推出的全托管、模块化平台,旨在帮助开发者大规模构建、部署和运营安全可靠的 AI Agent。其中,Memory是为Agent提供持久化的短期和长期记忆能力,以维护对话上下文。
在本客服机器人实践中,我们利用AgentCore Memory的能力来保存客户历史上的对话记录,并将这些历史对话记录作为客服的基础,来更好的回答客户的问题和诉求。在此,我们以代码片段的形式,将Memory的调用过程,展示给大家。
-
- 第一步,创建memory
-
- 第二步,保存memory
-
- 第三步,在适合的流程中,召回memory。 召回Memory的过程中,我们使用Strands tools:AgentCoreMemoryToolProvider。可以使用不同的Query召回不同分类的Memory。使得Memory的应用更加灵活和精准。
- Amazon Bedrock AgentCore Runtime是为Agent是一个专门为托管 AI Agent而设计的基础设施。它采用容器化的部署方式,负责处理用户输入、维护上下文,并利用容器的隔离能力,给AI应用一个安全高效的运行环境。
在本次实践中,我们多Agent的应用部署平台,就采用了AgentCore Runtime。它保证了我们客服能够按需付费,不用为客服的闲时花费基础资源费用,同时Runtime的高扩展性,也保证了整个系统可以应对突然的业务高峰冲击。 我们客服机器人的业务调用流如下: Connect 服务为客服机器人系统的接入模块,负责chat或voice数据的流入,Lex为客服逻辑模块,负责意图识别和系统调度,Lex可以通过Lambda调用部署在AgentCore Runtime上的多Agent客服系统,自动处理客户问题。
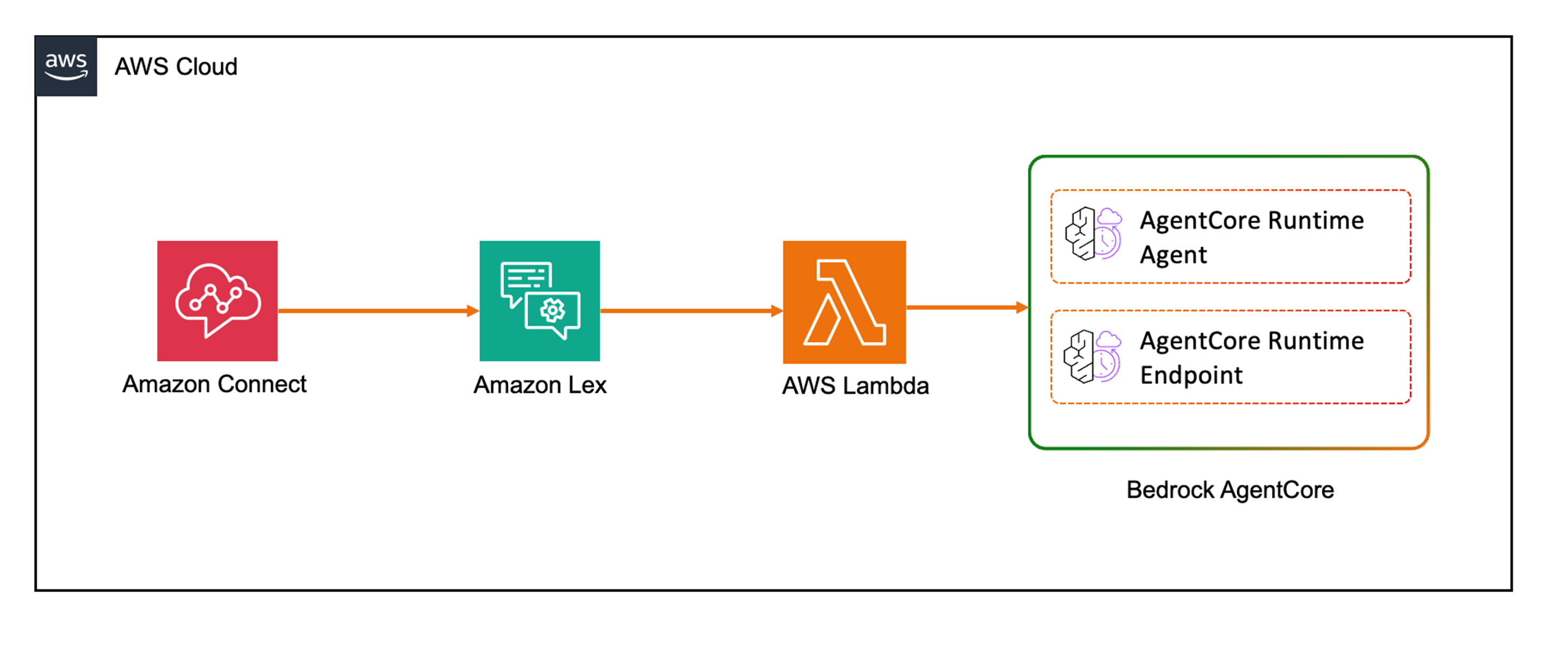 |
- AgentCore Runtime有2种部署方式,本文使用的是可定制化程度更高的自建Docker image,上传ECR的部署形式。具体的操作流程可以参见附件所列的文档。
5. 附录
Github code:https://github.com/heqiqi/multi-agent-for-customer-support
6. 总结
本篇讨论了亚马逊云科技Amazon Connect呼叫中心服务和Amazon Bedrock AgentCore以及Strands agent框架结合实现智能客服自助服务最佳实践。本博客从用户实际需求出发提供一个实际可行的解决方案,结合技术和成本综合考虑提供最佳实践。本设计充分考虑呼叫中心的特殊性,采用Lambda,Amazon Bedrock,Amazon Bedrock AgentCore,Stands Agent框架结合提供综合解决方案,同时提供了Amazon Bedrock AgentCore Runtime和Stands Agent结合的代码并和Amazon Connect实现集成,提供Amazon Bedrock AgentCore Memory集成及调用代码实现智能客服上下文自动记忆功能。本篇提供了整个实践的完整代码及实现的效果展示,,让读者可以清楚了解实现效果和技术细节。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。