亚马逊AWS官方博客
在Apache DataHub中整合Amazon Glue任务的数据血缘
 |
1. 概述
Apache DataHub (下面简称DataHub)是一个开源的元数据平台,旨在解决现代数据生态系统中的元数据管理挑战。它最初由 LinkedIn 开发并开源,现已成为 Linux 基金会下的独立项目。DataHub 提供了一个集中式平台,用于组织、发现、理解和管理企业数据资产。
本文旨在简述如何将Amazon Glue中数据库元数据同步到DataHub中,同时将Glue任务中的数据血缘一起展现在DataHub中。
本文部分内容参考自Amazon Blog Deploy DataHub using AWS managed services and ingest metadata from AWS Glue and Amazon Redshift – Part 1 和 Deploy DataHub using AWS managed services and ingest metadata from AWS Glue and Amazon Redshift – Part 2
2. DataHub介绍
Apache DataHub是由Linkedin开源的,官方喊出的口号为:The Metadata Platform for the Modern Data Stack – 为现代数据栈而生的元数据平台。目的就是为了解决多种多样数据生态系统的元数据管理问题,它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。它采用基于推送的数据收集架构(当然也支持pull拉取的方式),能够持续收集变化的元数据。当前版本已经集成了大部分流行数据生态系统接入能力,包括但不限于:Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery。
下图展示了 DataHub 架构,其中Metadata Service是摄入元数据的对应服务,也叫GMS。我们将通过调用API的方式将Glue的表信息插入到Metadata Service。
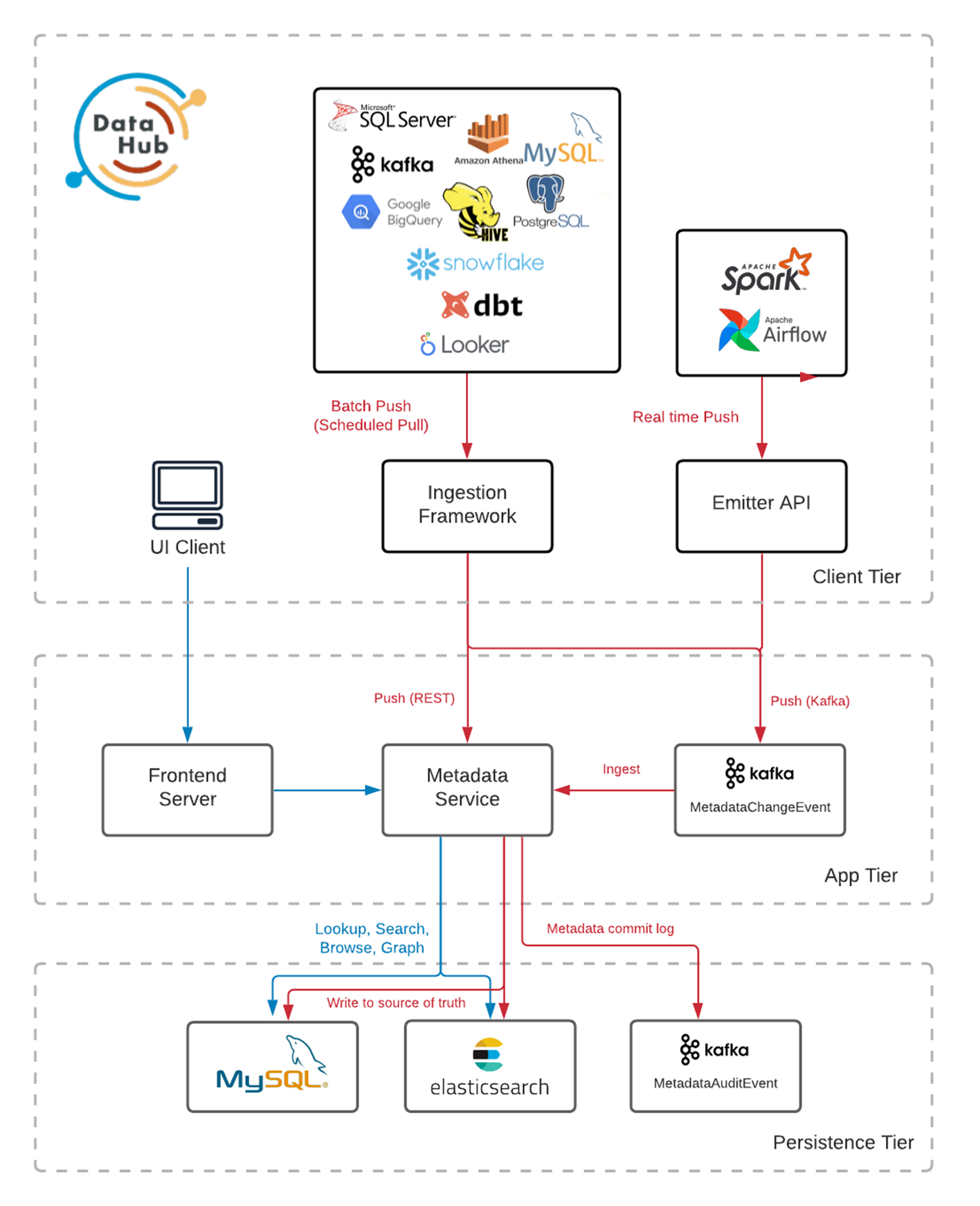 |
以下的展示过程中,图的左边是通过DataHub的Python SDK把Glue Data Catalog的现有数据库和表信息同步到DataHub的GMS服务器中,右边是通过Spark插件把Glue ETL任务运行时的血缘关系插入到GMS服务器中。
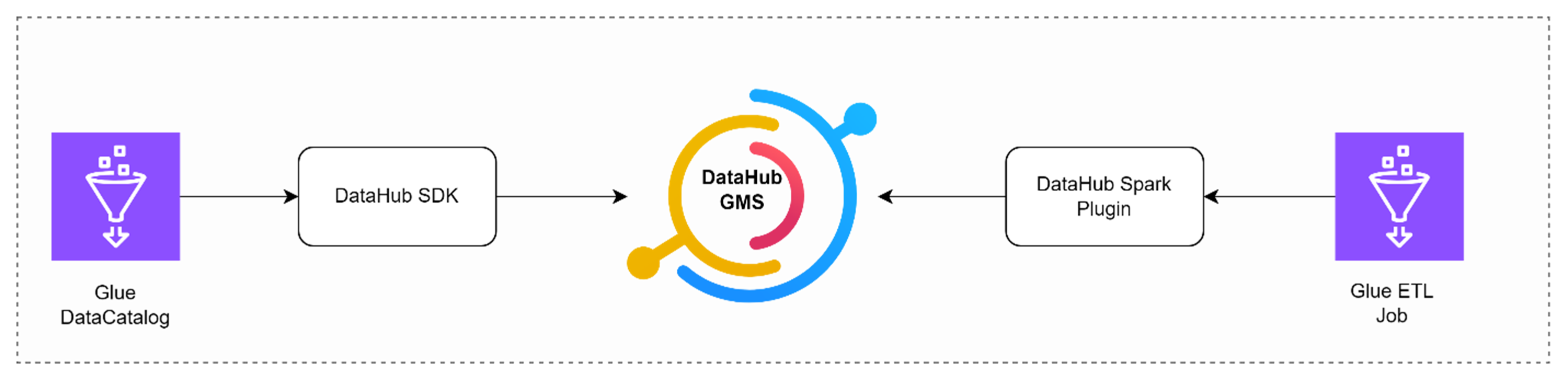 |
3. 准备工作
本部分将快速搭建一个DataHub测试环境。版本为1.2.0。
3.1. 创建EC2
首先,我们需要创建一个能够连接互联网的Amazon Linux 2023 EC2实例,最好能顺利连接GitHub和Docker Hub。
创建一个EC2 Role,拥有AWSGlueServiceRole或者更高的权限,然后分配给这个EC2。这样在EC2上运行Python脚本时就可以有足够权限来访问Glue。
3.2. 安装Docker和Python
在EC2上安装必要的软件环境:
3.3. 安装DataHub
安装DataHub及其依赖项:
下载docker-compose文件:
curl -SL https://raw.githubusercontent.com/datahub-project/datahub/master/docker/quickstart/docker-compose.quickstart-profile.yml -o docker-compose.yml
修改docker-compose配置文件,启用GMS的认证模式,同时为OpenSearch增加内存(实验中经常遇到OpenSearch OOM问题)
Line 68:METADATA_SERVICE_AUTH_ENABLED: 'true'
Line 325:memory: '2147483648'
Line 328:OPENSEARCH_JAVA_OPTS: -Xms1024m -Xmx1024m -Dlog4j2.formatMsgNoLookups=true
启动DataHub服务:
datahub docker quickstart --quickstart-compose-file docker-compose.yml
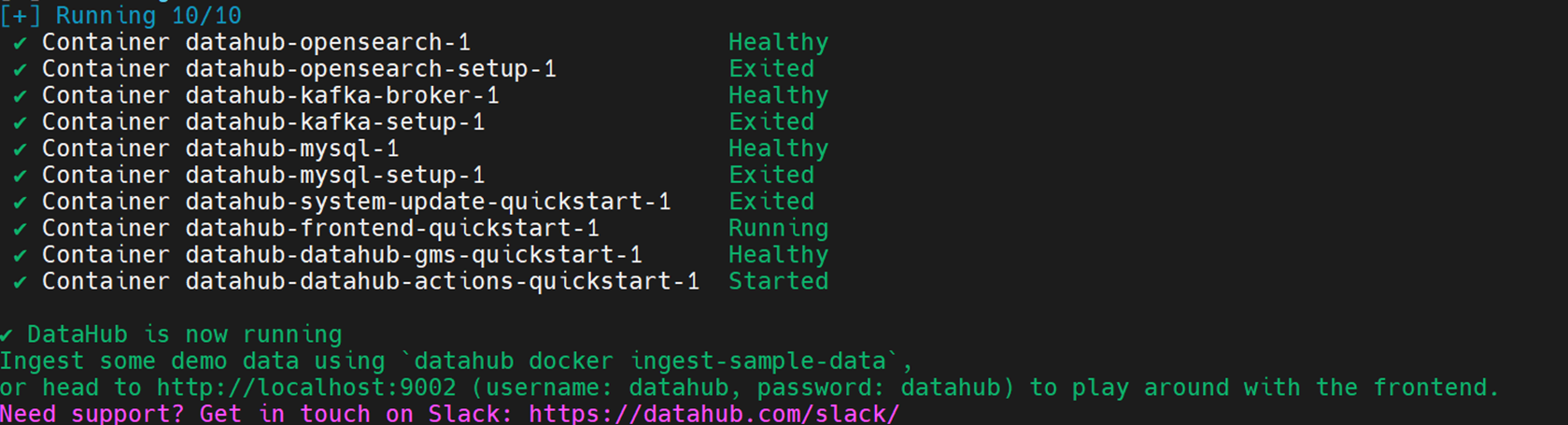 |
3.4. 设置DataHub
打开浏览器,访问http://<ip>:9002。
使用默认用户名和密码登录:datahub/datahub
进入Settings, 创建Access Token,记录下创建的Token。这个就是后续访问GMS所用的认证Token。
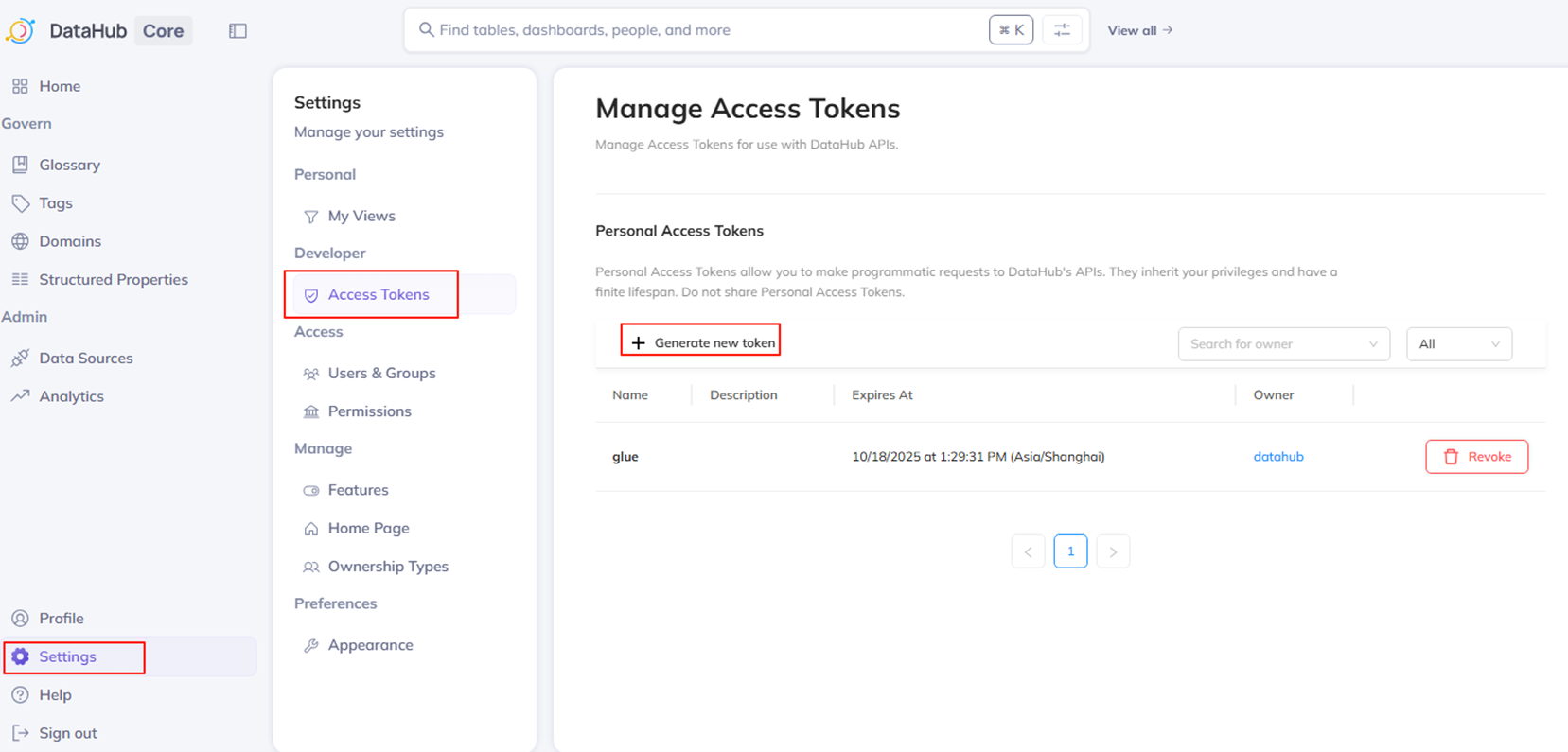 |
4. 摄入Glue元数据
4.1. 安装DataHub客户端Glue插件
pip3 install --upgrade 'acryl-datahub[glue]'
4.2. 修改摄入脚本
创建文件glue_ingestion.py,可以从GitHub下载
然后修改AWS Region,GMS Server和Token。其中GMS Server的地址就是上述安装DataHub的服务器IP地址,端口是8000。
4.3. 运行摄入脚本
python3 glue_ingestion.py
顺利运行完成后,可以看到同步的Glue表的统计信息:
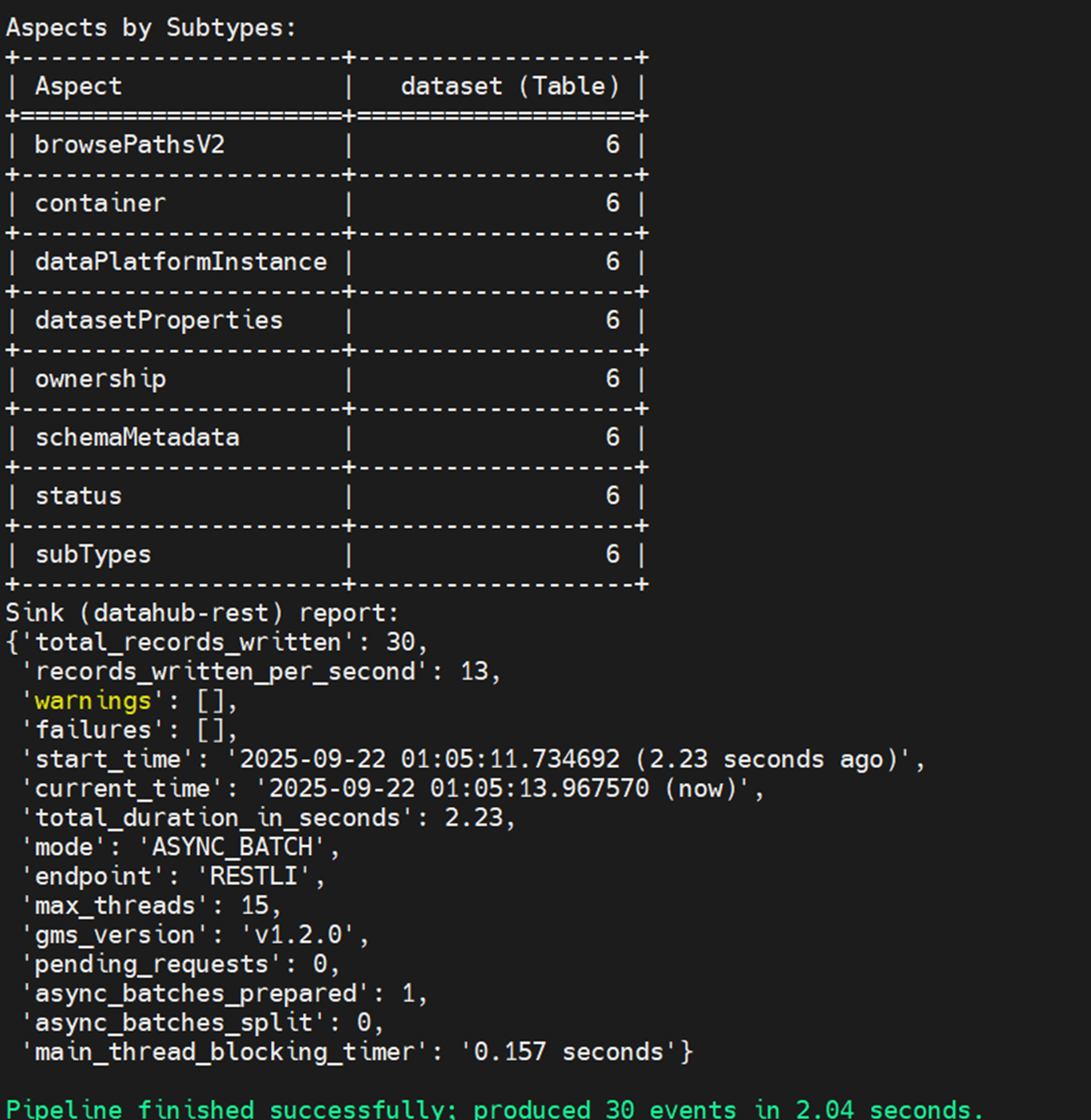 |
此时去DataHub Web界面上Discover里面可以看到Glue的信息:
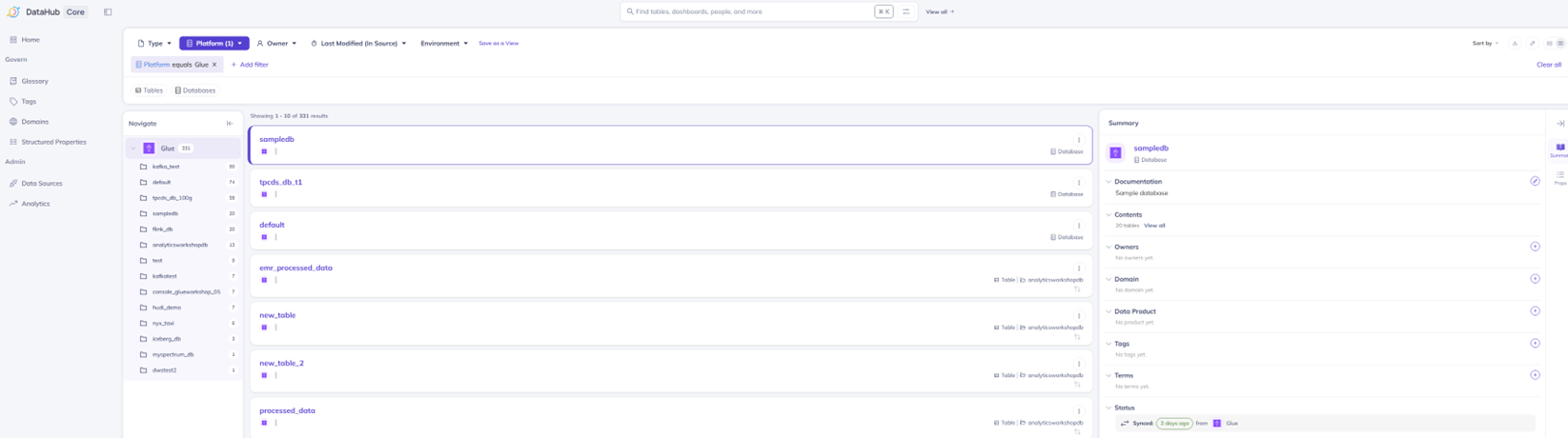 |
5. 捕获数据血缘
上文Glue数据摄入后,只是每个表的单独信息,还没有表与表之间的血缘关系。接下来我们可以通过Glue任务中插入Spark Listener的设置来捕获数据血缘。
5.1. 准备数据
我们下载一个纽约出租车的一个Parquet文件来作为源表。https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page,选择2022年一月 Yellow Taxi Trip Records (PARQUET)
将下载到的parquet文件,上传到s3上: s3://{your_bucket}/trip-data下。
5.2. 创建数据库和表
在Glue中创建一个数据库nyx_taxi
然后到Athena界面,选择nyx_taxi数据库,然后执行以下语句,(修改bucket name)
5.3. 再次同步表信息到DataHub
再次执行3.3的步骤,同步新创建的库和表。
python3 glue_ingestion.py
5.4. 准备Glue任务
下载datahub-spark-lineage 的JAR文件,并放到S3上:s3://{your_bucket}/ externalJar/。记下完整路径:s3://{your_bucket}/externalJar/acryl-spark-lineage_2.12-0.2.19-rc2.jar。此JAR文件是读取Spark任务相关信息,然后同步到DataHub。
下载log4j.properties文件,并放到S3上: s3://{your_bucket}/externalJar/。记录下完整路径: s3://{your_bucket}/externalJar/log4j.properties。此文件用来打开DataHub插件的调试信息。
在Athena中执行以下语句来创建目标表:(修改bucket name)
5.5. 创建Glue任务
为了让DataHub插件能访问到部署在私有网络的DataHub,我们需要为Glue任务创建一个私网的Connection。
创建Glue Connection,选择Network类型,选择与DataHub同一个VPC中的私有子网,选择的安全组中Inbound要有允许安全组自身的规则:
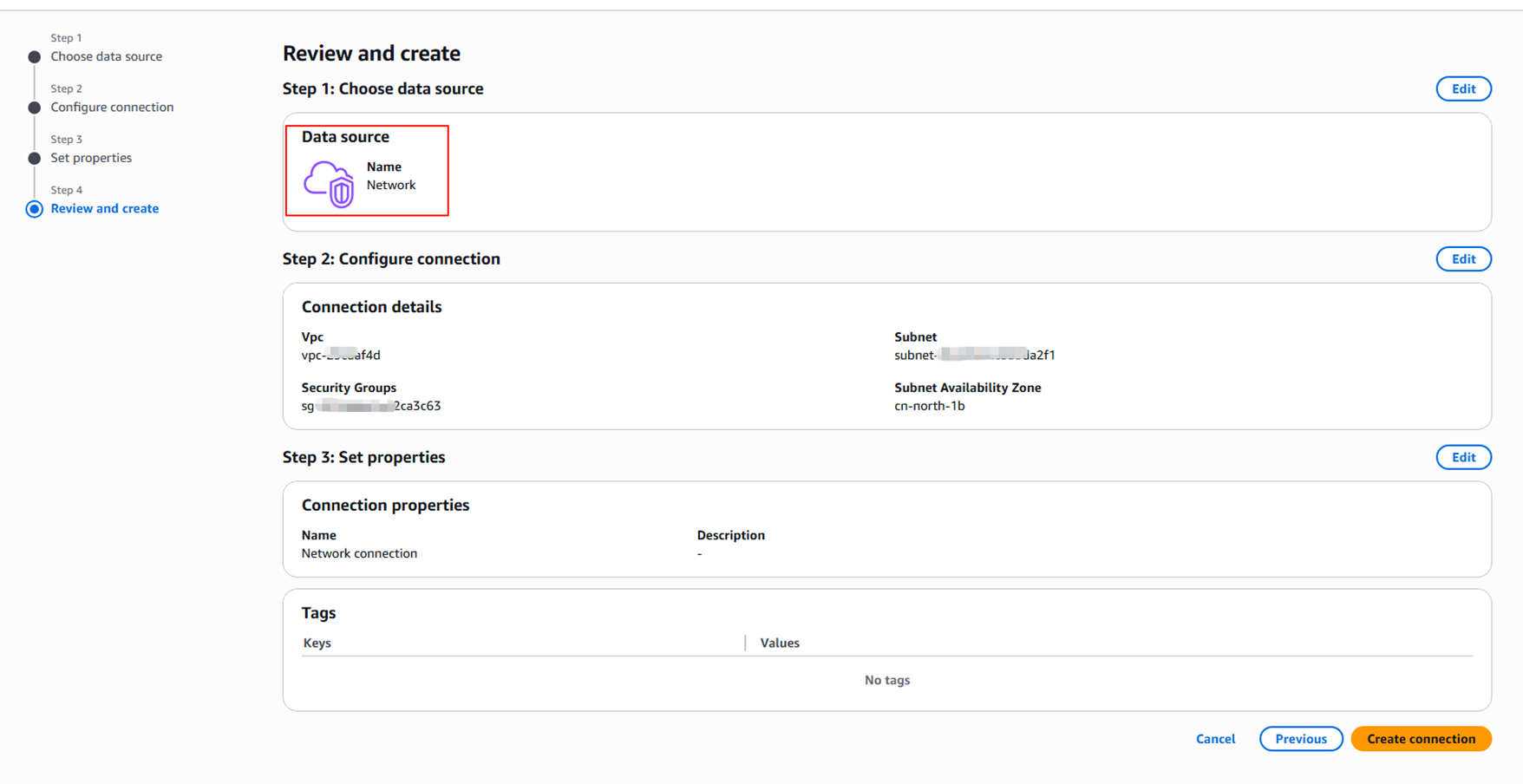 |
下载Glue脚本的任务,这个任务是对源表执行一些基本数据转换,然后写入到目标表中。修改脚本中GMS_ENDPOINT和GMS_TOKEN。
然后设置Glue任务的细节:
选择Glue 3.0和Python 3。
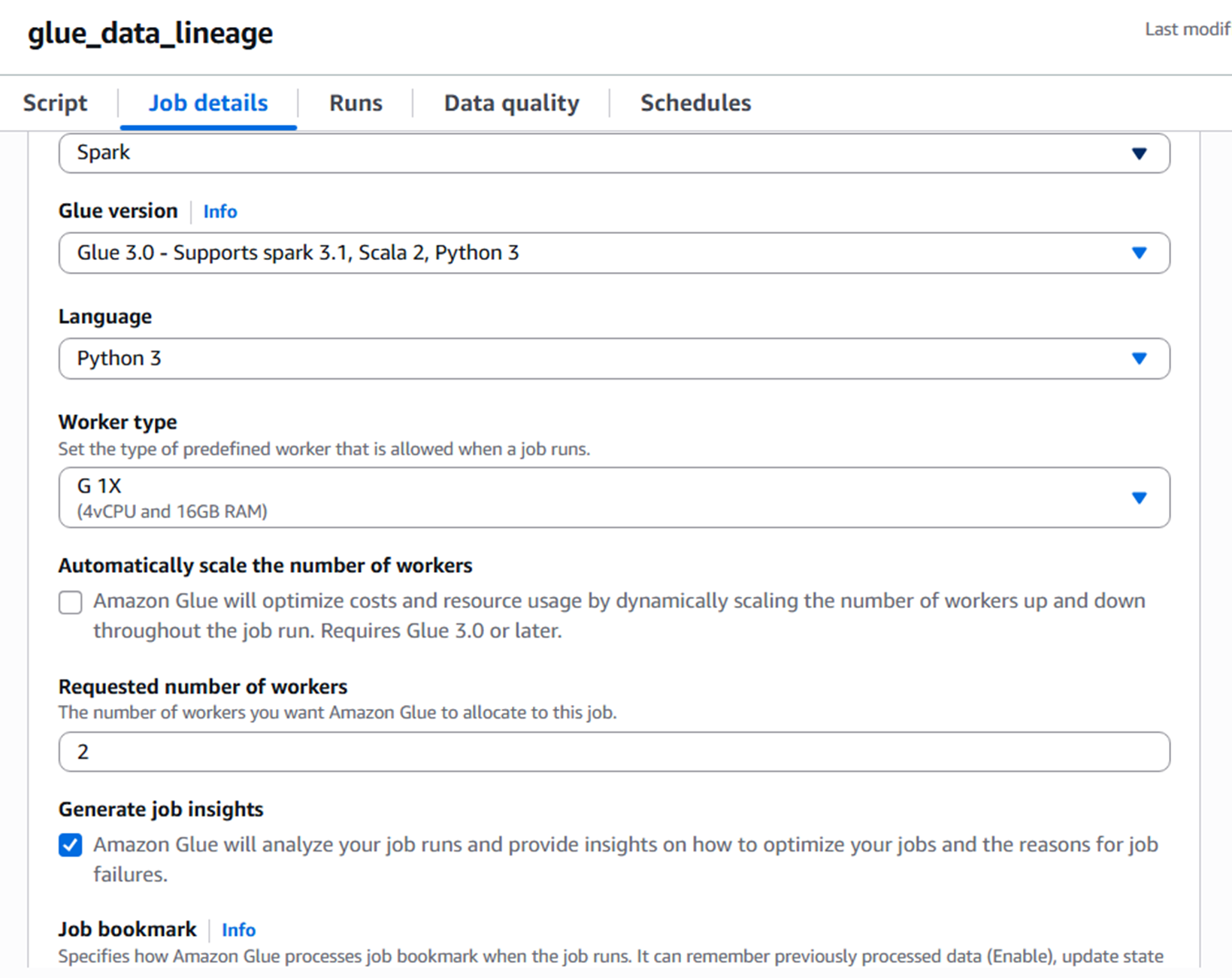 |
在高级选项中做如下设置:
- 设置Network Connection为之前创建的Connection
- 添加JAR文件路径到Libraries中:s3://{your_bucket}/externalJar/acryl-spark-lineage_2.12-0.2.19-rc2.jar
- 添加Log4j配置文件路径:–conf spark.driver.extraJavaOptions=-Dlog4j.configuration=s3://{your_bucket}/externalJar/log4j.properties
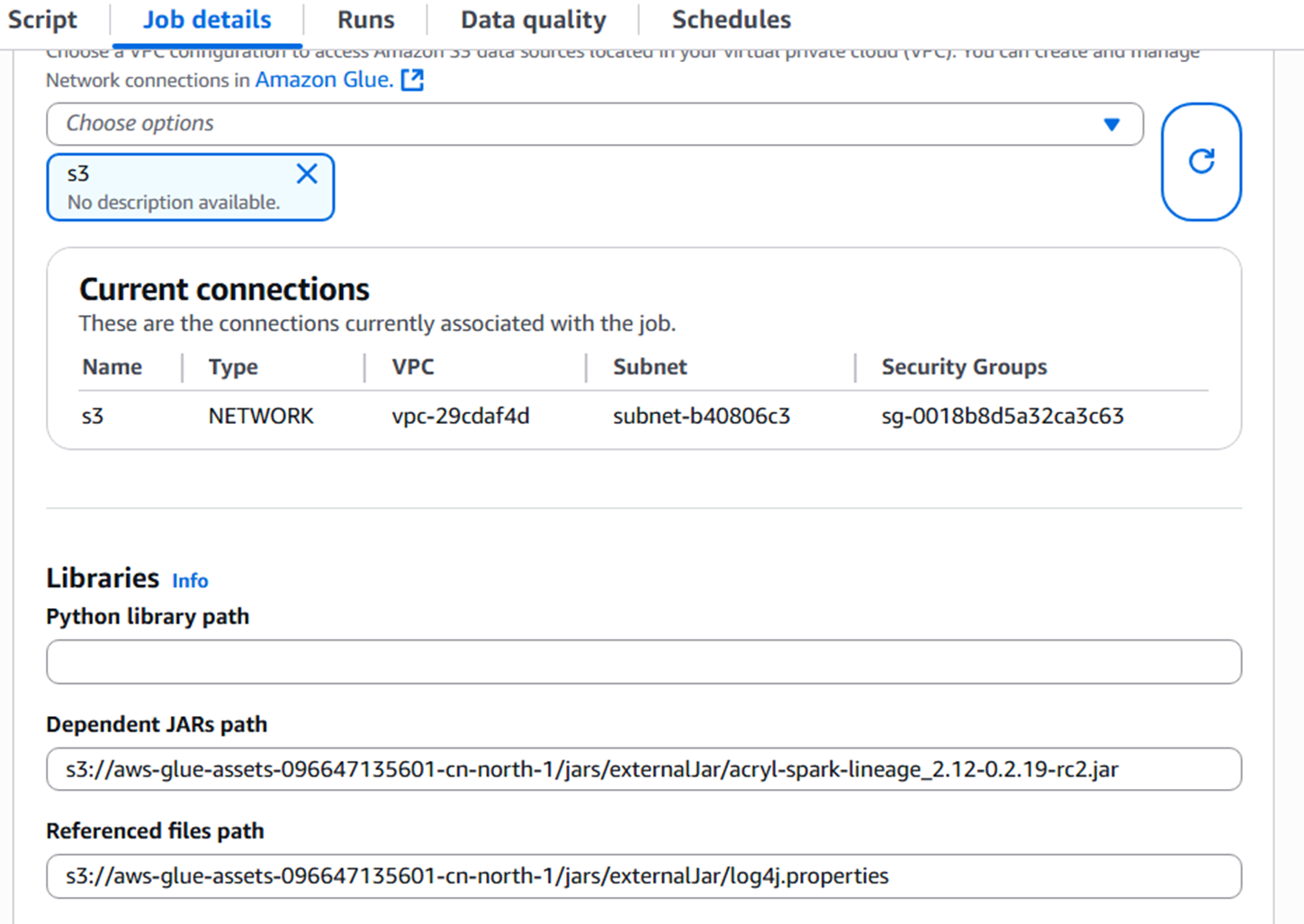 |
该作业从着陆表(landing table)中读取数据作为Spark DataFrame,然后将数据插入到目标表中。这个JAR是一个轻量级Java代理,它监听Spark应用程序作业事件,并实时将元数据推送到DataHub。被读取和写入的数据集的血缘关系(lineage)被捕获。应用程序启动和结束、SQLExecution启动和结束等事件都会被捕获。这些信息可以在DataHub中的管道(DataJob)和任务(DataFlow)下查看。
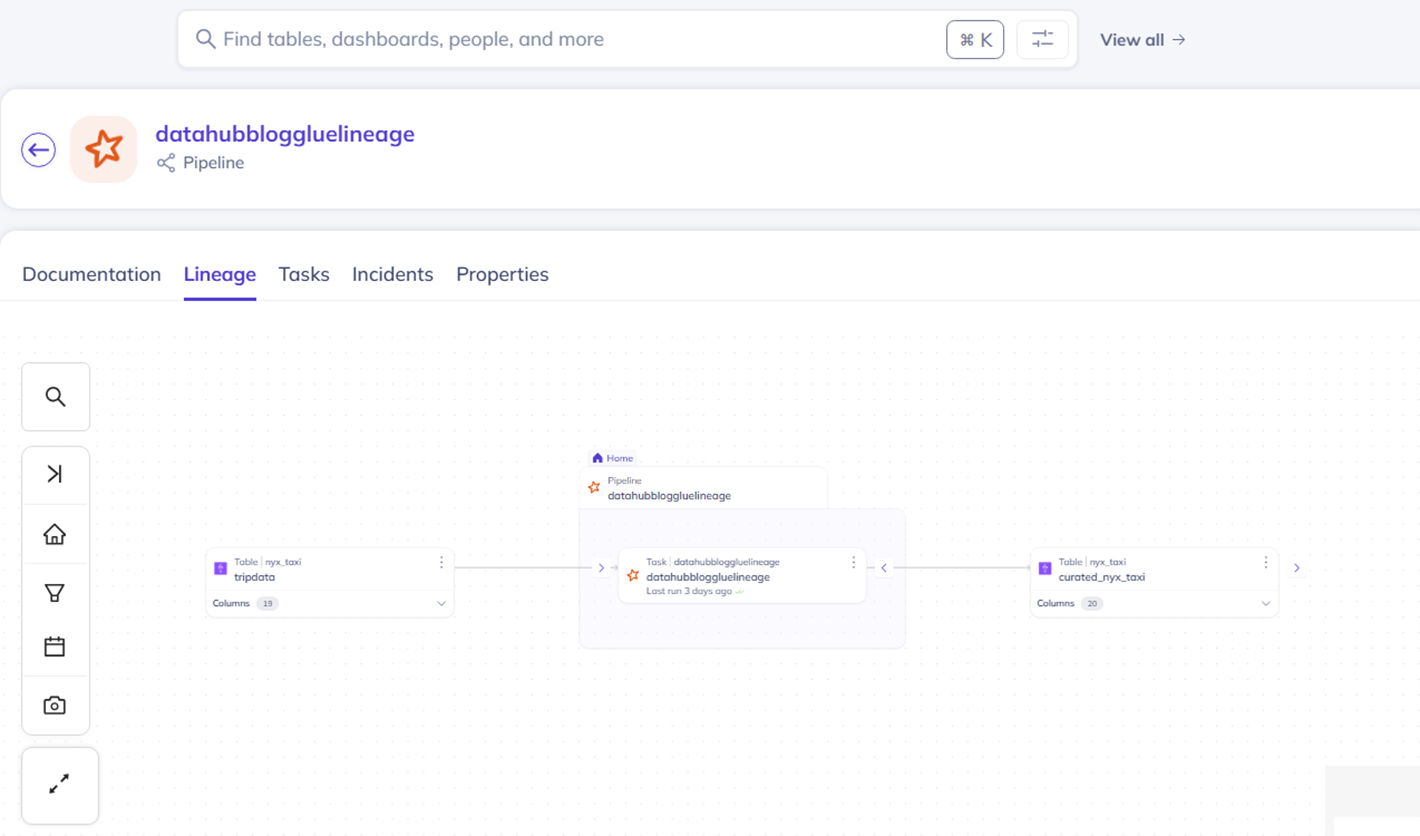
5.6. 运行Glue任务
运行该任务。任务结束后,在DataHub的Pipeline中可以看到该任务和上下游的表。
 |
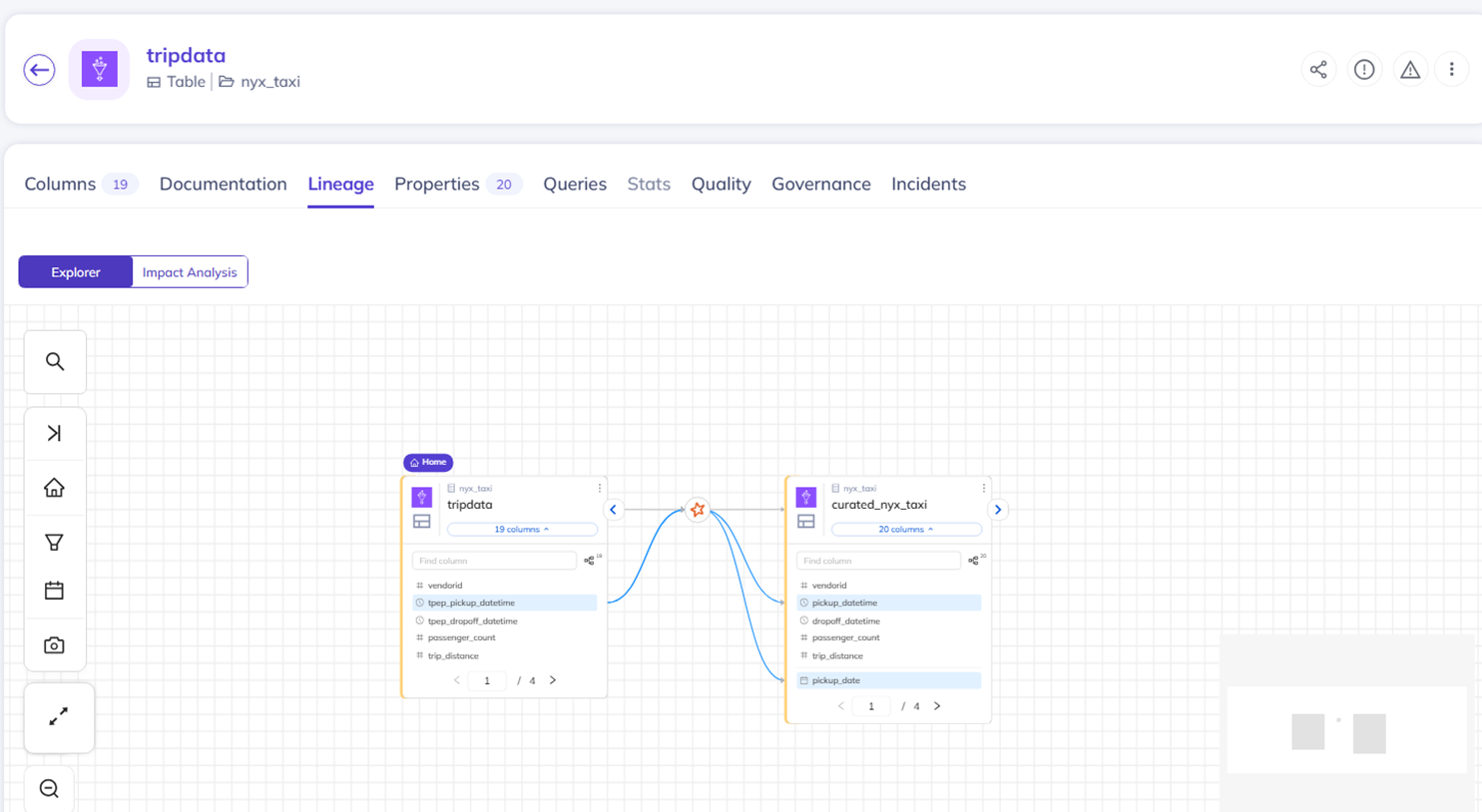
从表信息中,可以看到字段级别的血缘关系。
 |
以下是一个两表Join的例子,仅作为参考,具体步骤不再叙述。
 |
6. 注意事项
- Glue Ingestion的任务需要定期运行,以保持Glue元数据与DataHub同步
- 可以通过设置参数来过滤Glue Ingestion中的数据库和表
- Glue任务需要设置Connection来连接VPC网络
- 不同Glue脚本中的app.name应设置为不同值,以避免血缘关系混乱
7. 总结
本文详细演示了如何将Glue元数据同步到DataHub中,并在Glue脚本任务中自动捕获数据血缘。通过这种方式,您可以在DataHub中全面了解数据流动和转换过程,提高数据治理能力。
同时,这个血缘关系的捕获,也可以适用在Amazon EMR的场景中。
8. 附录
Glue Ingestion.py: https://github.com/aws-samples/deploy-datahub-using-aws-managed-services-ingest-metadata/blob/main/aws-dataplatform-meta-data-ingestion/examples/code/glue_ingestion.py
NY Taix data: https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
NY Taxi data: https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet
DataHub Spark Source plugin: https://repo1.maven.org/maven2/io/acryl/acryl-spark-lineage_2.12/0.2.19-rc2/acryl-spark-lineage_2.12-0.2.19-rc2.jar
Glue data ingestion.py: https://github.com/aws-samples/deploy-datahub-using-aws-managed-services-ingest-metadata/blob/main/aws-dataplatform-meta-data-ingestion/examples/code/glue_data_lineage.py
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。