亚马逊AWS官方博客
EMR和S3的跨区域应急备份恢复方案 之一:在存储成本与恢复时效之间取得平衡
 |
序言
近年来,随着数据和算法对企业核心业务的影响日益加深,数据处理系统的可用性与韧性已成为保障业务连续性的关键要素。与此同时,多家云计算厂商在不同时间都曾出现过区域级别的服务中断事件。虽然这类故障发生概率不高,但一旦触发,往往会影响到依赖云上计算与存储的关键任务链路。
对于以批量数据处理和分析为核心的企业而言,即便计算集群(如 EMR 作业)可以在其他 Region 快速启动,如果底层 S3 数据无法在短时间内恢复访问,业务依然无法重新运转。这类风险促使越来越多的企业开始思考:如何在成本可控的前提下,构建一套能够跨区域快速恢复的数据灾备体系。目标是在不牺牲成本效率的情况下,将区域性故障对业务的影响降到最低。
本文结合典型的电商数据处理场景,对 EMR 与 S3 的跨区域应急备份与恢复方案进行了系统分析与量化评估。通过比较多种主流方案在成本、恢复时效与可运维性方面的差异,提出了一种在“成本—时效”之间取得最优平衡的技术路径,旨在为构建更具韧性的数据基础设施提供可操作的参考。
应急故障恢复
1. 需求概述
在现代企业架构中,大数据系统已成为支撑核心业务运行和智能决策的基础组件。区域级故障的发生,不仅会导致大数据平台自身的不可用,更会对依赖其进行数据处理和分析的各类业务产生连锁反应。
其直接影响包括但不限于:CRM 活动邮件无法发送、广告投放策略被迫暂停、补货策略无法及时响应新品销售动态、各类经营与分析报表出现数据缺失等。此外,依托大数据平台的模型训练与更新任务也将被中断,进一步导致搜索推荐、个性化排序等智能化服务无法迭代优化,从而对业务增长和用户体验造成持续性影响。
随着数据量普遍达到 PB 级别,大数据系统的跨区域数据复制与恢复变得极为复杂和耗时。当云计算厂商出现区域级大规模故障时,由于 PB 级数据无法在短时间内完成跨区域同步,业务中断的损失会随故障持续时间线性增长。而在某些情况下,受制于区域间网络连通性问题,数据甚至可能暂时无法复制,导致业务恢复时间呈现“乘数效应”。此时,客户即便尝试通过跨区域切换,也难以在短时间内恢复核心大数据业务。造成这一问题的根本原因在于:大数据系统的数据多存储于对象存储(如 S3)中,而跨区域访问在区域级故障期间往往会受到网络瓶颈及服务依赖的多重限制。
因此,应对区域级极端故障的关键在于建立一套高可用、低成本、可快速恢复的数据灾备与恢复机制。该机制需确保在非故障区域内能够迅速启动 EMR 等数据处理服务,并以合理的存储成本与可控的恢复时间激活跨区域备份数据,使大数据处理业务能够在可接受的时间窗口内恢复正常运行。
综合考虑恢复时效性、数据安全性与成本控制,系统设计应满足以下核心要求:
- 数据完整性与一致性保障:跨区域备份数据应保持高可靠性,确保在恢复时具备完整性与一致性。
- 快速恢复能力:在区域级故障发生后,应能在 5 小时内 完成关键数据的恢复与任务重启,满足业务连续性要求。
- 成本优化设计:备份数据在日常状态下可作为冷数据存储,仅在应急情况下进行激活与检索,显著降低长期存储成本。
通过构建满足上述要求的跨区域灾备与恢复方案,企业可以在成本与恢复时效之间实现平衡,显著提升大数据系统的韧性与整体业务的持续可用性。
2. 架构示例
当前架构,正常运行时:
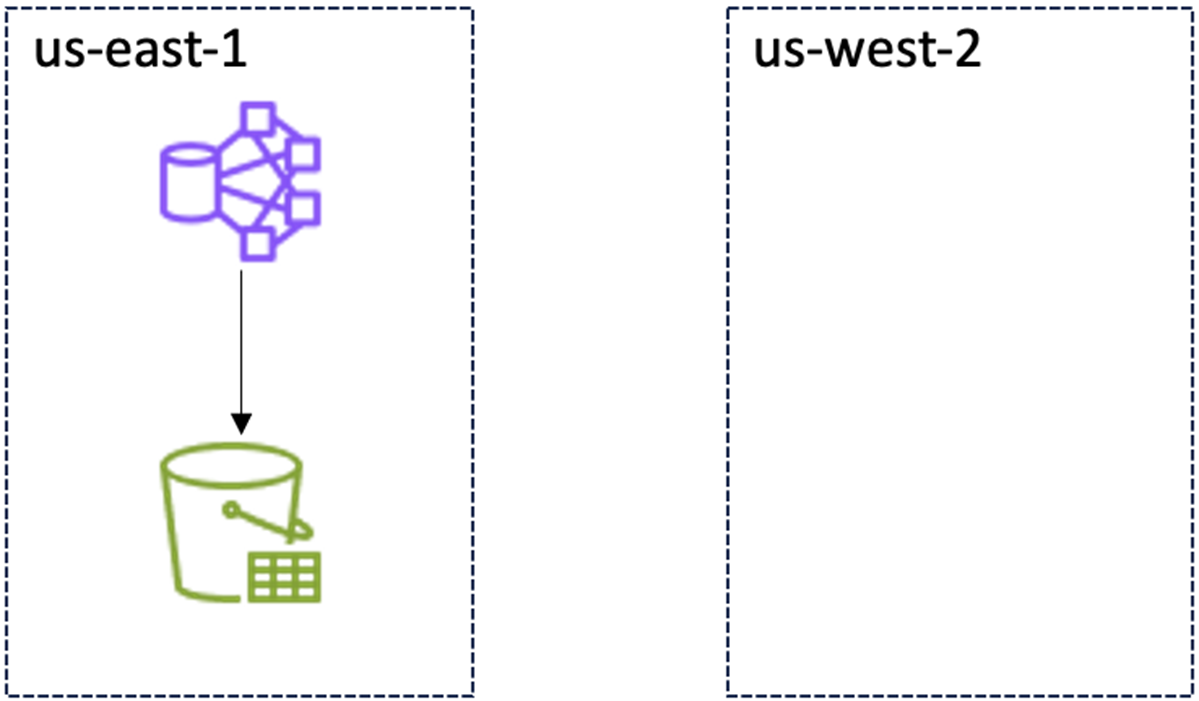 |
当前架构,启动跨Region应急恢复后:
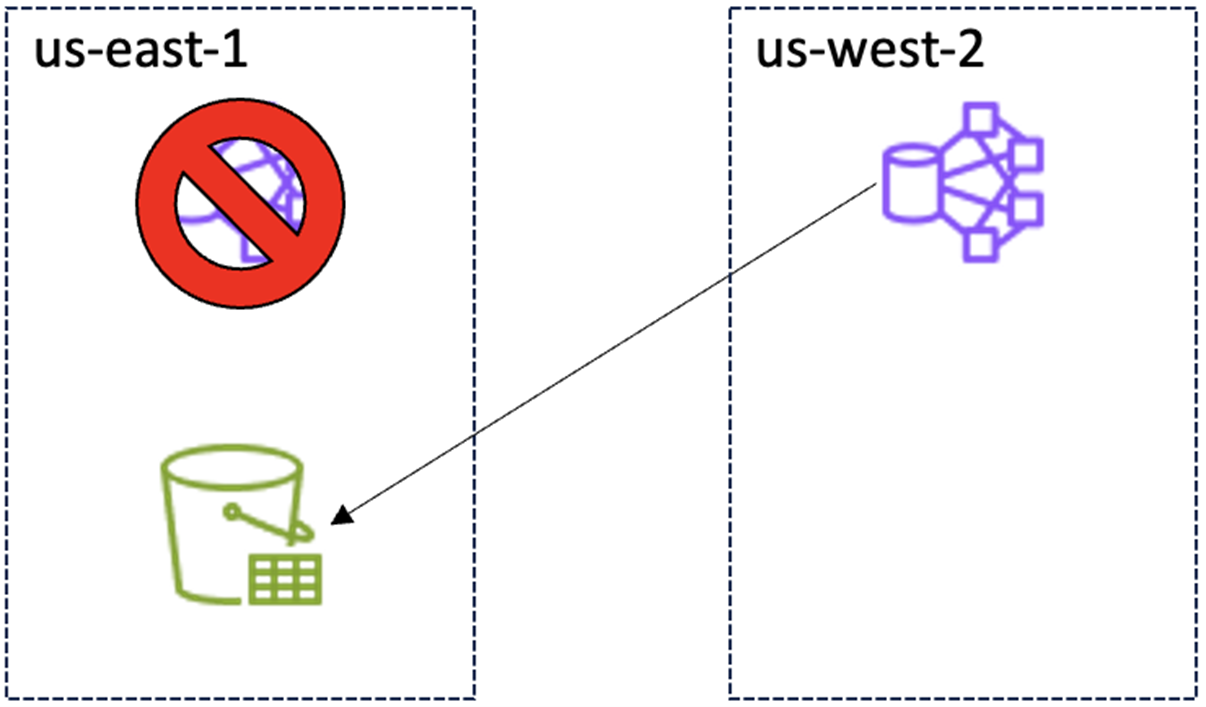 |
实施备份方案后,正常运行时:
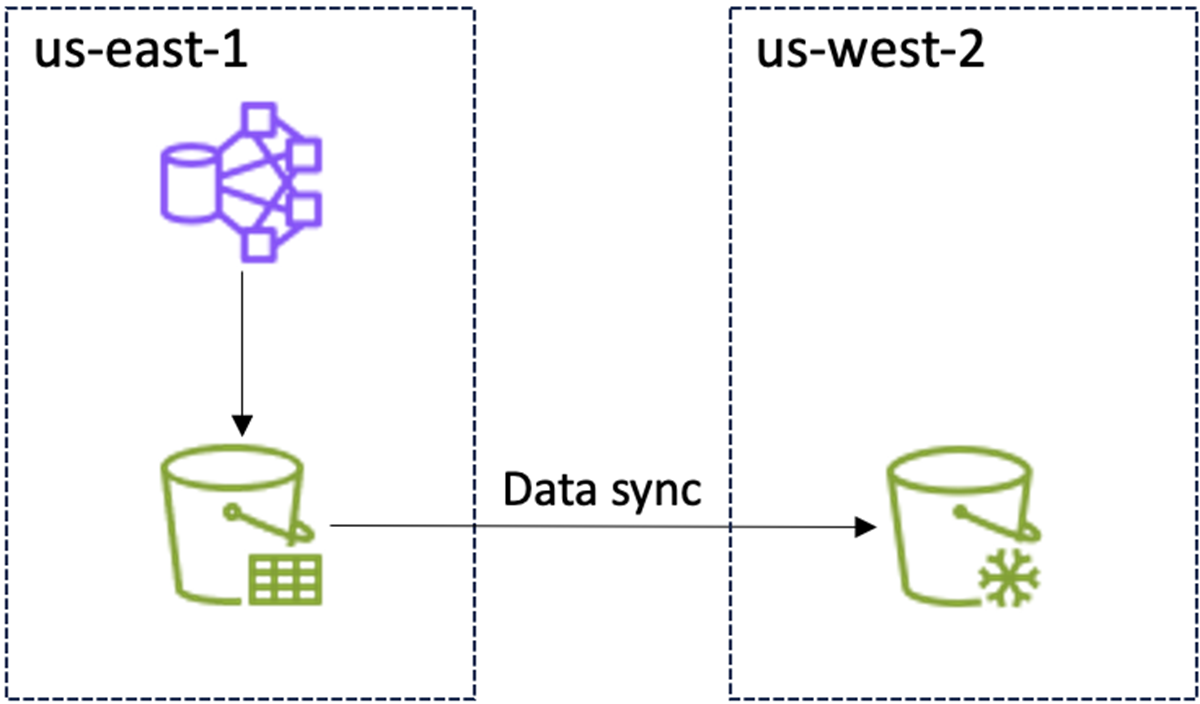 |
实施备份方案后,启动跨Region应急恢复后:
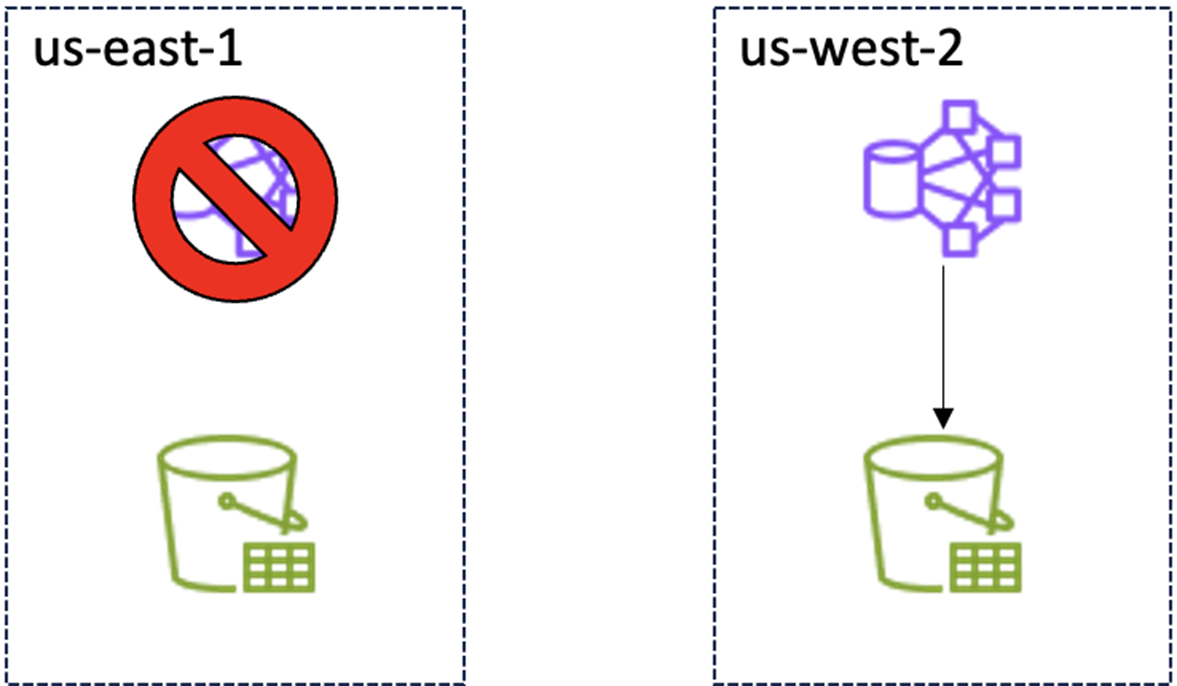 |
3. 数据现状
数系统采用实时与批量相结合的数据处理方式,整体数据规模维持在约 1PB。系统保留最近 6 个月的数据,形成滚动的数据窗口:每月新增约 100TB 增量数据,同时清理最早的一个月数据,以实现周期化管理和稳定的数据规模。
方案选型对比
1. AWS Backup跨区域存储
介绍
AWS Backup 特别适合需要集中化、自动化数据保护策略的企业环境,能够显著简化备份管理并确保合规性。
跨区域恢复
- 自动跨区域备份复制
- 灾难恢复测试
- RTO/RPO 优化
- 恢复验证
- 自动恢复测试
- 备份完整性验证
成本组成
- 跨区域数据传输费用
美国区域间:$0.02/GB
- 备份存储费用
热存储标准费率:$0.05/GB/月(美国西部)
冷存储标准费率:$0.01/GB/月(美国西部)
- 数据恢复费用
热存储恢复费率:$0.02/GB
速度:即时恢复
冷存储恢复费率:$0.03/GB
速度:3-5 小时恢复时间
成本估算示例
根据客户现状,全量数据1PB,每月增量数据100TB,数据管理周期6个月
1.跨区域数据传输费用
- 初始传输:400,000 GB × $0.02 = $8,000
- 每月增量传输:100,000 GB × $0.02 = $2,000
2.备份存储费用(目标区域 us-west-2)
- 月末数据量计算:
- 第1个月:400,000 GB + 100,000 GB = 500,000 GB
- 第2个月:400,000 GB + 200,000 GB = 600,000 GB
- 第3个月:400,000 GB + 300,000 GB = 700,000 GB
- 第4个月:400,000 GB + 400,000 GB = 800,000 GB
- 第5个月:400,000 GB + 500,000 GB = 900,000 GB
- 第6个月:400,000 GB + 600,000 GB = 1,000,000 GB
- 6个月存储数据量计算(按月累积):
- 6个月总计:4,500,000 GB
- 平均每月:750,000 GB
- 平均每月存储费用:
- 热存储:750,000 GB × $0.05 = $37,500
- 冷存储:750,000 GB × $0.01 = $7,500
3.数据恢复费用
- 热存储恢复:1,000,000 GB × $0.02 = $20,000
- 冷存储恢复:1,000,000 GB × $0.03 = $30,000
4.总费用
- 热存储(即时恢复):$8,000(初始化) + $2,000(增量传输) + $37,500(数据存储)+ $20.000(应急恢复)
- 冷存储(3-5小时):$8,000(初始化) + $2,000(增量传输) + $7,500(数据存储) + $30,000(应急恢复)
总体评估
- 优点:自动将备份数据移至冷存储,重复数据删除,压缩优化
- 缺点:成本较高
- 推荐:⭐️⭐️(不推荐)
2. S3 Glacier Deep Archive 跨区域复制
介绍
适用场景:
- 7-10年长期归档
- 合规性数据保存
- 极少访问的数据
- 成本优先考虑
最小存储期限:180天
成本组成
- 跨区域数据传输费用
美国区域间:$0.02/GB
- 备份存储费用
存储标准费率:$0.00099/GB/月
- 数据恢复费用
标准检索:$0.0025/GB + $0.0004/1000请求
速度:12小时内
批量检索:$0.00025/GB + $0.0004/1000请求
速度:48小时内
成本估算示例
根据客户现状,全量数据1PB,每月增量数据100TB,数据管理周期6个月
1.跨区域数据传输费用
- 初始传输:400,000 GB × $0.02 = $8,000
- 每月增量传输:100,000 GB × $0.02 = $2,000
2.备份存储费用
- 月末数据量计算:
- 第1个月:400,000 GB + 100,000 GB = 500,000 GB
- 第2个月:400,000 GB + 200,000 GB = 600,000 GB
- 第3个月:400,000 GB + 300,000 GB = 700,000 GB
- 第4个月:400,000 GB + 400,000 GB = 800,000 GB
- 第5个月:400,000 GB + 500,000 GB = 900,000 GB
- 第6个月:400,000 GB + 600,000 GB = 1,000,000 GB
- 6个月存储数据量计算(按月累积):
- 6个月总计:4,500,000 GB
- 平均每月:750,000 GB
- 平均每月存储费用:
- 750,000 GB × $0.00099 = $750
3.数据恢复费用
- 标准检索:1,000,000 GB × $0.0025 = $2,500
- 批量检索:1,000,000 GB × $0.00025 = $250
4.总费用
- 标准检索(12小时内):$8,000(初始化) + $2,000(增量传输) + $750(数据存储)+ $2,500(应急恢复)
- 批量检索(48小时内):$8,000(初始化) + $2,000(增量传输) + $750(数据存储)+ $250(应急恢复)
总体评估
- 优点:成本最低
- 缺点:数据恢复时间过长,无法满足应急要求
- 推荐:⭐️(不考虑)
3. S3 Glacier Flexible Retrieval 跨区域复制
介绍
适用场景:
- 1-5年中期归档
- 偶尔需要快速访问
- 备份和灾难恢复
- 平衡成本和访问速度
最小存储期限:90天
成本组成
- 跨区域数据传输费用
美国区域间:$0.02/GB
- 备份存储费用
存储标准费率:$0.004/GB/月
- 数据恢复费用
加急检索:$0.03/GB + $0.01/1000请求
速度:1-5分钟内
标准检索:$0.01/GB + $0.0004/1000请求
速度:3-5小时内
批量检索:$0.0025/GB + $0.0004/1000请求
速度:5-12小时内
成本估算示例
根据客户现状,全量数据1PB,每月增量数据100TB,数据管理周期6个月
1.跨区域数据传输费用
- 初始传输:400,000 GB × $0.02 = $8,000
- 每月增量传输:100,000 GB × $0.02 = $2,000
2.备份存储费用
- 月末数据量计算:
- 第1个月:400,000 GB + 100,000 GB = 500,000 GB
- 第2个月:400,000 GB + 200,000 GB = 600,000 GB
- 第3个月:400,000 GB + 300,000 GB = 700,000 GB
- 第4个月:400,000 GB + 400,000 GB = 800,000 GB
- 第5个月:400,000 GB + 500,000 GB = 900,000 GB
- 第6个月:400,000 GB + 600,000 GB = 1,000,000 GB
- 6个月存储数据量计算(按月累积):
- 6个月总计:4,500,000 GB
- 平均每月:750,000 GB
- 平均每月存储费用:
- 750,000 GB × $0.004 = $3,000
3.数据恢复费用
- 加急检索:1,000,000 GB × $0.03 = $30,000
- 标准检索:1,000,000 GB × $0.01 = $10,000
- 批量检索:1,000,000 GB × $0.0025 = $2,500
4.总费用
- 加急检索(1-5分钟):$8,000(初始化) + $2,000(增量传输) + $3,000(数据存储)+ $30,000(应急恢复)
- 标准检索(3-5小时):$8,000(初始化) + $2,000(增量传输) + $3,000(数据存储)+ $10,000(应急恢复)
- 批量检索(5-12小时):$8,000(初始化) + $2,000(增量传输) + $3,000(数据存储)+ $2,500(应急恢复)
总体评估
- 优点:成本较低
- 缺点:暂无
- 推荐:⭐️⭐️⭐️⭐️
4. 综合对比
根据客户现状,全量数据1PB,每月增量数据100TB,数据管理周期6个月
| A | B | C | D | E | F | G | H | |
| 1 | 方式 | 类型 | 数据恢复时效 | 初始化传输 | 增量传输(每月) | 数据存储(每月) | 应急恢复(1PB) | 建议 |
| 2 | AWS Backup | 热存储 | 即时恢复 | $8,000 | $2,000 | $37,500 | $20,000 | 不考虑,成本太高 |
| 3 | 冷存储 | 3-5小时 | $8,000 | $2,000 | $7,500 | $30,000 | 不考虑,成本高 | |
| 4 | Deep Archive | 标准检索 | 12小时内 | $8,000 | $2,000 | $750 | $2,500 | 不考虑,数据恢复时效性不满足 |
| 5 | 批量检索 | 48小时内 | $8,000 | $2,000 | $750 | $250 | 不考虑,数据恢复时效性不满足 | |
| 6 | Flexible Retrieval | 加急检索 | 1-5分钟 | $8,000 | $2,000 | $3,000 | $30,000 | 应急快速恢复 |
| 7 | 标准检索 | 3-5小时 | $8,000 | $2,000 | $3,000 | $10,000 | 时效性要求不高,又有成本要求时考虑 | |
| 8 | 批量检索 | 5-12小时 | $8,000 | $2,000 | $3,000 | $2,500 | 不考虑,数据恢复时效性不满足 | |
| 9 | S3标准存储 | 即时恢复 | $8,000 | $2,000 | $16,500 | $0 |
- 首先,根据数据恢复的时效性要求,使用S3 Glacier Deep Archive进行数据存储,无法在较短的时间内完成数据恢复,不符合本次方案的基本需求,该方式被放弃;
- 其次,使用AWS Backup热存储,存储费用高达05 GB/月,比S3标准存储0.022 GB/月还要高出一倍以上,比Flexible Retrieval存储价格高出十倍以上,因此该方式被放弃;
- 第三,使用AWS Backup冷存储,对比恢复时间相同的Flexible Retrieval标准检索存储,存储成本高出一倍以上,恢复成本高出两倍,也不符合方案的成本最低要求,该方式不建议使用;
- 第四,整体看在恢复时效性和成本上最能满足要求的是S3 Glacier Flexible Retrieval,整体成本较低,也可以满足数据恢复的基本要求,同时提供了加急检索和标准检索两种方式,可以根据实际情况进行选择。
方案实施过程
S3 Glacier Flexible Retrieval 跨区域复制实施步骤
1. 准备工作
启用源桶版本控制:
aws s3api put-bucket-versioning \
--bucket source-bucket \
--versioning-configuration Status=Enabled
创建目标桶:
aws s3 mb s3://target-bucket —region us-west-2
aws s3api put-bucket-versioning \
--bucket target-bucket \
--versioning-configuration Status=Enabled
2. 创建IAM角色
创建信任策略文件(trust-policy.json):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "s3.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}
创建权限策略文件(replication-policy.json):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObjectVersionForReplication",
"s3:GetObjectVersionAcl"
],
"Resource": "arn:aws:s3:::source-bucket/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::source-bucket"
},
{
"Effect": "Allow",
"Action": [
"s3:ReplicateObject",
"s3:ReplicateDelete"
],
"Resource": "arn:aws:s3:::target-bucket/*"
}
]
}
创建IAM角色:
aws iam create-role \
--role-name s3-replication-role \
--assume-role-policy-document file://trust-policy.json
aws iam put-role-policy \
--role-name s3-replication-role \
--policy-name s3-replication-policy \
--policy-document file://replication-policy.json
3. 配置跨Region复制
创建复制配置文件(replication-config.json):
{
"Role": "arn:aws:iam::YOUR-ACCOUNT-ID:role/s3-replication-role",
"Rules": [{
"ID": "GlacierBackupRule",
"Status": "Enabled",
"Filter": {"Prefix": ""},
"Destination": {
"Bucket": "arn:aws:s3:::target-bucket",
"StorageClass": "GLACIER"
}
}]
}
应用复制配置:
aws s3api put-bucket-replication \
--bucket source-bucket \
--replication-configuration file://replication-config.json
4. 验证配置
检查复制状态:
aws s3api get-bucket-replication —bucket source-bucket测试复制:
# 上传测试文件
aws s3 cp test-file.txt s3://source-bucket/
# 检查目标桶
aws s3 ls s3://target-bucket/
aws s3api head-object —bucket target-bucket —key test-file.txt
5. 监控和管理
查看复制指标:
aws s3api get-bucket-replication —bucket source-bucket
aws cloudwatch get-metric-statistics \
--namespace AWS/S3 \
--metric-name ReplicationLatency \
--dimensions Name=SourceBucket,Value=source-bucket
结语
在云计算环境中,区域级故障虽属低概率事件,但对依赖大数据处理与分析的企业而言,其业务影响往往是成倍放大的。通过本方案的系统评估与实践验证可以看出,采用 S3 Glacier Flexible Retrieval 跨区域复制能够在成本与时效之间取得最优平衡:既保证了PB级数据的跨区域备份完整性与可靠性,又在应急情况下实现了可控的恢复时效。结合合理的生命周期管理策略与自动化运维机制,企业能够在保持成本可控的前提下,显著提升大数据系统的韧性与业务连续性,为未来的不确定性建立更稳固的底层保障。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。