亚马逊AWS官方博客
基于亚马逊云科技托管 Flink 的开发系列 — MySQL CDC 写入数据湖篇
 |
1. 概述
上文讲述了在亚马逊云科技托管的 Apache Flink 中如何读取基于 SSL 通讯的 Apache Kafka,并写入到 Amazon S3。这篇文章将继续讲述 Flink 开发的一个场景:利用 Flink CDC 读取 MySQL 数据,并写入基于 Apache Hudi 数据湖格式的 Amazon S3 中。这是在亚马逊云科技上构建实时数据湖的常用方案之一,可以将业务数据库的数据实时的写入到数据湖中,以供进一步分析和使用。
2. Apache Flink CDC
 |
Flink CDC(Change Data Capture)是一种基于 Apache Flink 的数据同步和流处理技术,它能够捕获数据库中的变更数据并实时处理。Flink CDC 的核心目标是将数据库中的增量变化(如插入、更新、删除操作)实时捕获并传递到目标系统中,支持在流式计算中对这些变更数据进行处理和分析。
Flink CDC 基于数据库的日志捕获机制(如 MySQL 的 binlog,PostgreSQL 的 WAL 日志)来捕获变更数据。Flink CDC 通常利用 Debezium 作为变更数据捕获的引擎。Debezium 可以捕获多种数据库的变更事件,支持主流的数据库如 MySQL、PostgreSQL、Oracle、MongoDB 等。Flink CDC 的应用场景主要包括:
- 实时数据同步:
-
- 在数据库与 Kafka、Elasticsearch、HDFS 等系统之间同步数据。
- 实时分析:
-
- 将实时捕获的数据库变更数据与其他流数据结合,用于实时 BI 报表和数据分析。
- 事件驱动架构:
-
- 捕获数据库的事件,用于驱动业务逻辑的自动化处理(如订单状态变化触发消息)。
- 数据库迁移:
-
- 将数据库的数据和变更迁移到新的存储系统。
3. Amazon RDS MySQL 数据库准备
我们这里已 Amazon RDS MySQL 为例,首先为 MySQL 开启 binlog,并设置正确的格式。
启用自动备份
可以参考附录中链接 [3],通过启用 RDS 的自动备份功能,会自动打开 binlog。注意,启用时数据库会下线并立刻执行备份。
设置 binlog 格式
可以参考附录中链接 [4],通过修改参数组来设置 binlog_format为ROW。此参数为动态参数,无需重启数据库即可生效。ROW 格式的日志内容会非常清楚的记录下每一行数据修改的细节,这样通过日志就可以得到新增或修改的记录了。
验证 binlog 设置
执行以下命令可以确认 binlog 的相关设置:
设置合适的 binlog 保留时间
系统将会把 binlog 以文件形式存放在磁盘中,这可能会占用大量的空间。另一方面,如果保留时间太短,可能下游还没来得及消费,binlog 就被清除了,这会导致下游数据丢失。请根据实际需求设置保留时间,以下是一个保留 7 天的示例:
创建读取 binlog 的用户
下面命令是创建一个名为 debezium 的用户,并赋予相应的权限,以读取 binlog。真实生成场景中请使用高强度密码,并将 IP 限制为可信来源地址。
4. 创建数据库和实验数据
以下部分内容来自于Apache Flink 官方文档 [附录链接 2]。
首先创建一个 db_1 的数据库,并创建两张表 user_1 和 user_2,并分别插入一条数据:
然后再创建数据库 db_2,同样创建两张表 user_1 和 user_2,插入两条数据:
这样,数据库这边的准备工作就完成了。
5. 制作 Fat Jar 文件
如上篇文章中提到,我们需要将 Flink 作业中依赖的 Jar 文件都打包成一个 Fat Jar。这里涉及到 flink-sql-connector-mysql-cdc 和 hudi-flink1.15-bundle,以及依赖的 hadoop-mapreduce-client-core。具体步骤可以参考上篇文章,对应的 POM 文件可以在附录链接 [1] 的 github 代码中 pyflink-examples/MySQLCDCToHudi/fat-jar-pom 目录下找到。
通过执行:
如果一切顺利,会得到一个 Fat Jar文件:FatJar-CDC-Hudi-0.14-1.0-SNAPSHOT-combined.jar。
6. 开始测试程序
接下来我们来演示如何读取 MySQL 的 CDC 数据,然后以 Hudi 格式写入 Amazon S3。其中有关本地程序写入 S3 的特殊设置,可以参考本系列之前文章的设置。由于之前亚马逊云科技的官方示例程序中没有包含相关内容,所以以下代码可以从附录链接 [1] 中取得,可以使用 git 命令将代码克隆到本地。
6.1 准备相关 Java 包
本次演示程序在 MySQLCDCToHudi 目录中,我们已经把上文生成的 FatJar-CDC-Hudi-0.14-1.0-SNAPSHOT-combined.jar 文件放到了 lib 目录中。
6.2 更新应用属性
修改 MySQLCDCToHudi/application_properties.json 文件中配置,修改 MySQL 的主机名,用户名和密码,以及最后文件输出的 S3 桶名。
6.3 修改运行配置
在 mysql-cdc-to-hudi.py 文件上右键选择 Modify Run Configuration…
在 Run 下面的 interpreter 中选择之前配置的 flink-env,在 Environment variables 中增加两个变量,中间用分号相隔,其中 HADOOP_CONF_DIR 后面路径即是 PyFlink 安装目录的 conf 路径,请按照实际目录修改:
IS_LOCAL=true;HADOOP_CONF_DIR=/home/ec2-user/miniconda3/envs/flink-env/lib/python3.8/site-packages/pyflink/conf
最后如果配置了额外的 Amazon Command Line Interface (Amazon CLI) profile,要选择相应的 profile。
6.4 运行程序
现在我们就可以开始运行程序了,在右上角的运行栏中选择 mysql-cdc-to-hudi.py,点击右边绿色三角形按钮就可以开始运行程序了。
如果一切顺利,下方 Run 框里面没有错误信息,并且可以看到 S3 插件的相关信息:
6.5 验证结果
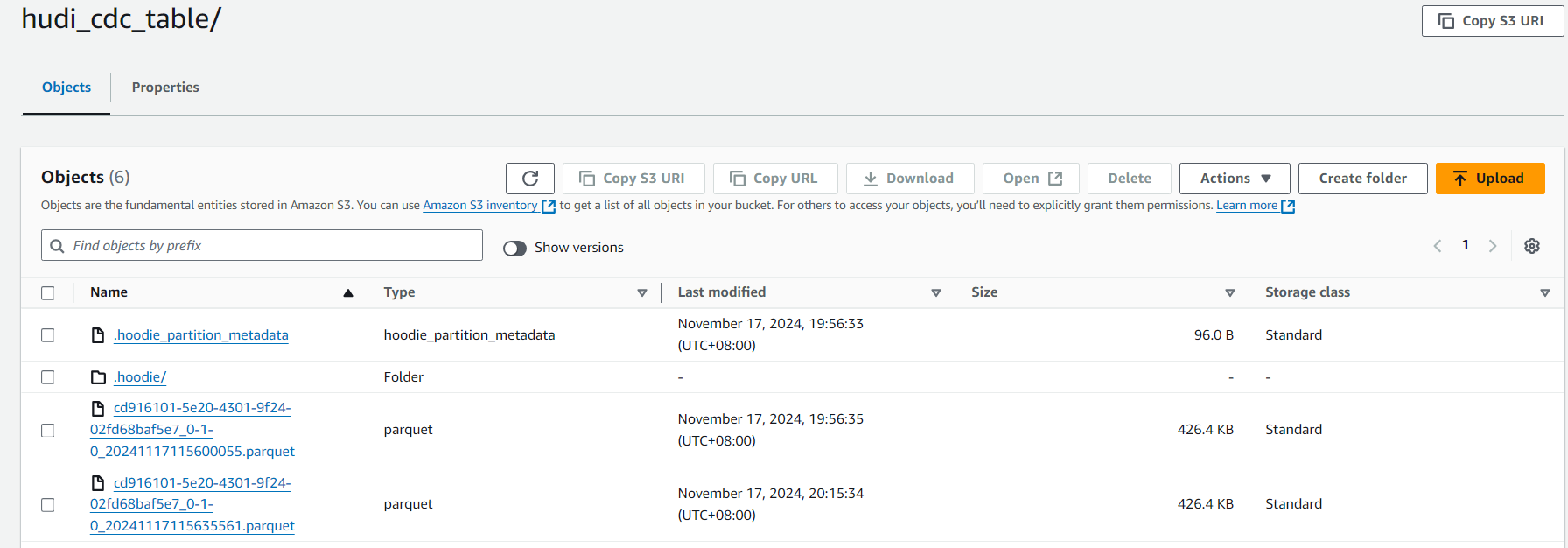
运行一段时间后,转到亚马逊云科技的控制台,选择 S3 服务,在之前设置的 Bucket 里面,进入 hudi_cdc_table 目录,可以看到 .hoodie 目录和 parquet 文件,这就是 Flink 写入成功了。
 |
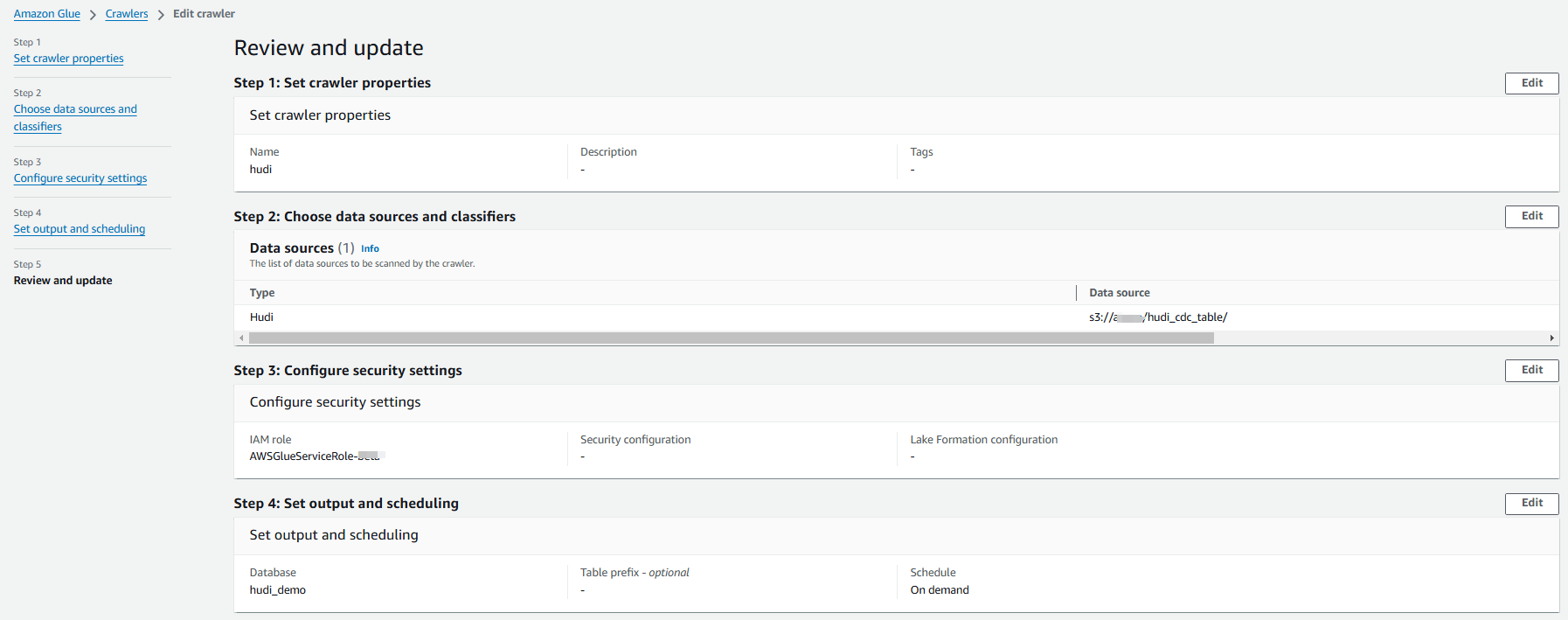
6.6 用 Glue Crawler 来创建 hudi 表
为了在 Athena 里面通过 SQL 语句来查询表数据,我们需要在 Glue Catalog 中创建一个 Hudi 表。我们可以直接用 SQL 语句来创建,也可以通过 Glue Crawler 爬取 S3 上文件来创建 Hudi 表,这样就无需手动写 SQL 语句。具体参数可以参考如下截图:
 |
当 Glue Crawler 运行完成后,就可以看到 hudi_cdc_table 了。
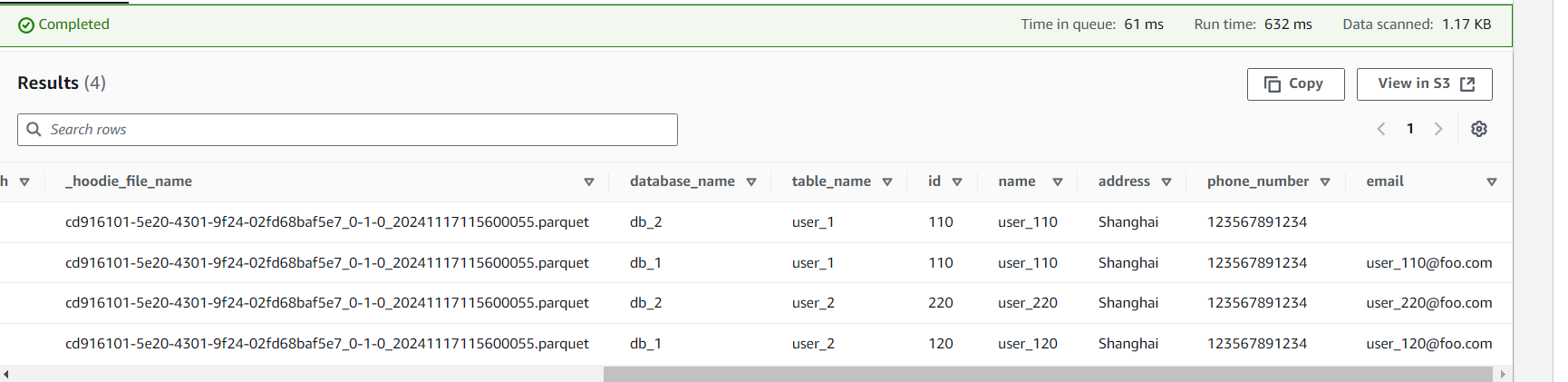
6.7 用 Athena 来查询数据
在 Athena 中选择数据源为 AwsDataCatalog,数据库为 hudi_demo,然后执行下面语句,就可以查到该 hudi 表的数据了:
 |
接下来我们模拟对源 MySQL 的记录进行插入:
然后稍等片刻,再执行上面的查询语句,就可以看到新增的记录了。
 |
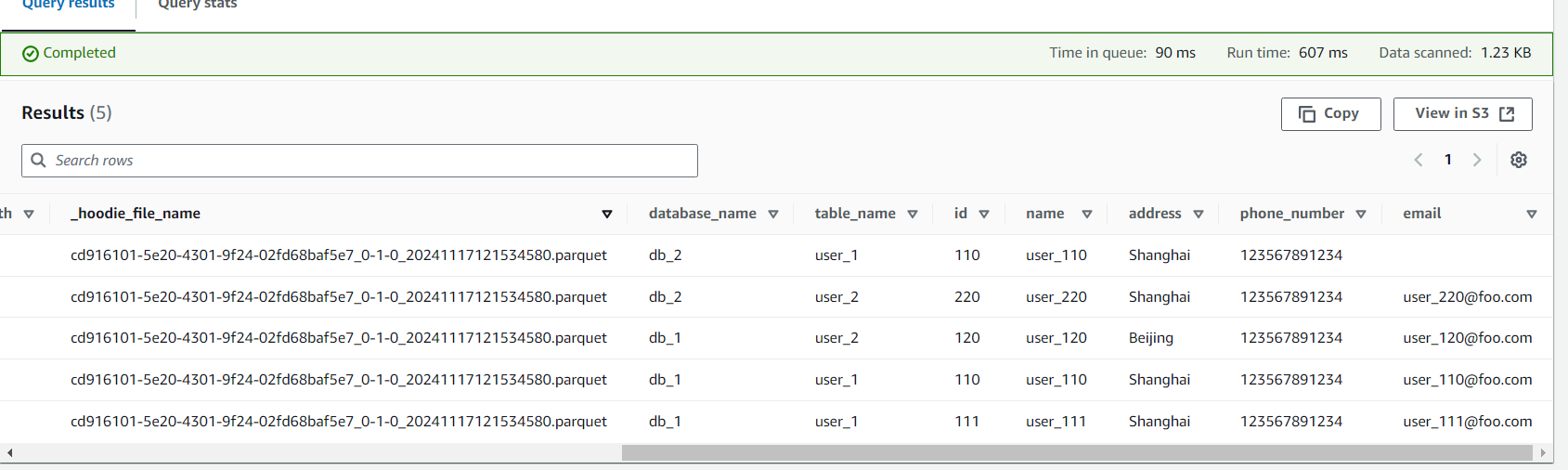
我们再模拟对记录进行更新操作:
然后稍等片刻,再执行上面的查询语句,就可以看到更新的记录了。
 |
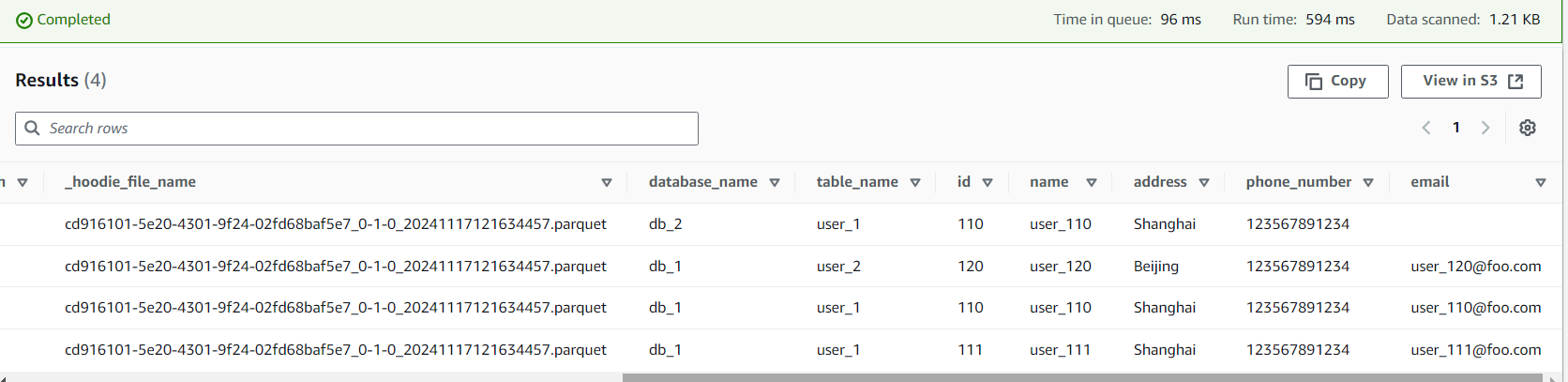
最后我们再模拟删除记录的操作:
然后稍等片刻,再执行上面的查询语句,就可以看到记录被删除了。
 |
7. 结束语
本文演示了 Apache Flink 从 MySQL 读取 CDC 的记录更新数据,再以 Apache Hudi 的格式写入到 Amazon S3 的过程,包含了数据的新增,修改和删除等操作,实现了基本的数据入湖。
本篇是该系列的最后一篇,非常感谢阅读和支持,欢迎交流和指导。
参考链接
[1] https://github.com/xmubeta/pyflink-getting-started/