亚马逊AWS官方博客
为 Direct Connect 维护事件构建弹性,最大限度减少停机时间
对于依赖 Amazon Web Services (AWS) Direct Connect 实现混合云连接的企业来说,构建能够承受计划内与计划外维护事件的高弹性网络架构至关重要。当业务高度依赖本地环境与 AWS 之间持续、可靠的连接时,掌握如何在维护期间进行架构设计便成为必修课。
本文属于 300 级深度技术内容,默认读者已具备 AWS Direct Connect 及 BGP 路由协议的基础概念与实践经验。如果您刚接触 Direct Connect,请先阅读《Direct Connect 入门指南》。
阅读本文后,您将收获:
- 定义弹性
- 构建高弹性网络以减轻维护事件影响的实操指南
- 优化现有网络的弹性态势
- Direct Connect 维护活动类型
- 维护期间系统行为概览
- 维护事件的通知机制
- 维护期间的弹性架构设计
- 维护前的准备工作
- 弹性能力验证方法
本文分享的最佳实践,将帮助您在计划内与紧急维护场景下,对 Direct Connect 环境进行架构优化,最大限度降低业务中断风险。
定义弹性
1) 引言
在谈论弹性时,必须明确弹性与冗余并非同义词。拥有冗余,例如一条主用、一条备用的 Direct Connect 连接并不天然等同于具备弹性。冗余(备份系统)只是弹性的一部分。真正的弹性还包括:提前准备并检测故障、故障发生时快速响应、在故障或维护期间持续运行并恢复、事后复盘并持续改进,从而在整个生命周期内始终保护生产工作负载。
2) 理解维护可能引发中断的场景
充分的网络弹性规划是避免昂贵停机与业务中断的前提。要落实有效的保护措施,首先得厘清自身应用与业务的特定需求。以下两个假设场景可供参考:
- 场景 A:您正在承载一场具有全球可见性的关键直播活动,组织职责是为终端用户提供零中断的广播服务。对于此类实时内容分发,若未配置足够弹性,任何潜在中断都将带来重大业务冲击。
- 场景 B:您运营一家金融交易平台,低延迟与极高可用性至关重要。该场景下,任何中断都必须压缩到最短时长。
3) 落地最佳实践
您应对故障和维护两种场景都进行建模,评估剩余容量是否足以让您安心继续运营。
例如,在场景 A 中,由于直播面向全球,哪怕短暂中断也会导致负面客户体验,因此无法容忍。为确保足够弹性,需在每个接入点额外部署连接,以实现无缝 failover。同理,在场景 B 中,即便故障只带来毫秒级延迟抬升,也可能严重干扰交易,因此除了主连接外,还需在同一位置部署第二、甚至第三条线路,确保单点故障时既能继续运营,又不会因切换到远端节点而引入额外延迟。
核心结论:冗余虽是弹性的重要组成,但真正的弹性需求由应用与业务特性驱动。唯有深入分析这些需求,才能设计出匹配自身场景的弹性架构。从需求出发反向推导,而非套用一刀切方案,才是确保架构贴合业务的关键。
Direct Connect 维护期间到底发生了什么?
AWS 将 Direct Connect 维护分为两类:计划内维护(Planned Maintenance)与紧急维护(Emergency Maintenance)。如需了解维护类型详情,请参阅《Direct Connect 维护文档》。
在计划内维护中,AWS 会分两个阶段把流量从受影响的端点迁出:
- AS-Path prepend:AWS 在 BGP 路径属性里额外追加 3 个 AS 路径,使该路由变得更不优先,给你的网络留出反应时间。与此同时,Direct Connect 也会把从你本地设备学来的路由在 AWS 内部降权。
- 路由撤销: 等待 60 秒后,AWS 撤销所有向你本地设备通告的路由,确保你的网络在维护动作开始前完成切换。此阶段,Direct Connect 也会把从你本地学来的路由从 AWS 内部撤销。 除设备重启瞬间外,BGP 会话本身保持 Established 状态,不交换路由,仅用于监控。
在实施任何变更前,AWS 会通过全面的预检捕获设备状态,包括流量检查,确认该设备已不承载客户流量后,才对端点动手。
维护窗口内,网络端点会接受必要的更新(配置变更、系统升级),处理这些变更及完成重启时可能出现短暂中断。若你已配置冗余路径,流量会继续走替代线路。变更完成后,AWS 执行后检,并与预检结果比对,确保无意外副作用且设备已可重新投用。
回迁时,AWS 按相反顺序操作:先通告次优路由,60 秒后再通告最优路由;该流程同时适用于向你本地和向 AWS 内部通告的路由。
再次通过后检,确认端点已正常处理流量后,AWS 将流量切回该端点,你会在收到完成通知前看到流量恢复。
全部步骤结束后,AWS 在 AWS Health Dashboard 发送完成通知,告知维护活动已结束。维护通知时间表见《AWS Direct Connect Maintenance》。
若为紧急维护,仅端点的某个组件故障,无法提前迁流,连接将在维护事件中突然中断,请提前做好准备。
如何为维护事件做好架构设计
为确保生产负载在计划内维护及突发故障期间持续运行,Direct Connect 建议按照最大弹性拓扑来构建连接。该方案要求将连接分散到至少两个 Direct Connect 接入点,并在每个接入点内连接到两个独立的物理端口。
最大弹性拓扑的核心目标是为连接提供冗余与高可用(HA)。通过分散物理接入点及端口,架构消除了单点故障对连接的影响,即便遇到计划维护或突发事件,也能保障业务连续性。
该拓扑在计划维护和意外中断时提供多层冗余。每个接入点内的双连接分别终结于不同端口,可确保单端口故障时流量仍留在本地接入点,避免因切换到另一接入点而增加延迟。
在更严重的情况下,若整个 Direct Connect 接入点失效(如图 1 所示),工作负载可无缝切换至另一接入点,从而实现超越单点级别的弹性,为大规模中断提供额外保护。
最大弹性方案的关键优势在于,即使端口失效或整个接入点瘫痪,也能避免服务中断,持续保障业务运行。这种健壮的连接设计是最佳实践,可确保生产负载抵御多种潜在故障场景。
图 1:Direct Connect 接入点故障场景。该图展示流量如何自动从失效的共址设施切换至备用 Direct Connect 接入点,通过地理隔离的路径保持连接。架构在两地部署冗余连接,每地双端口,实现最大弹性。
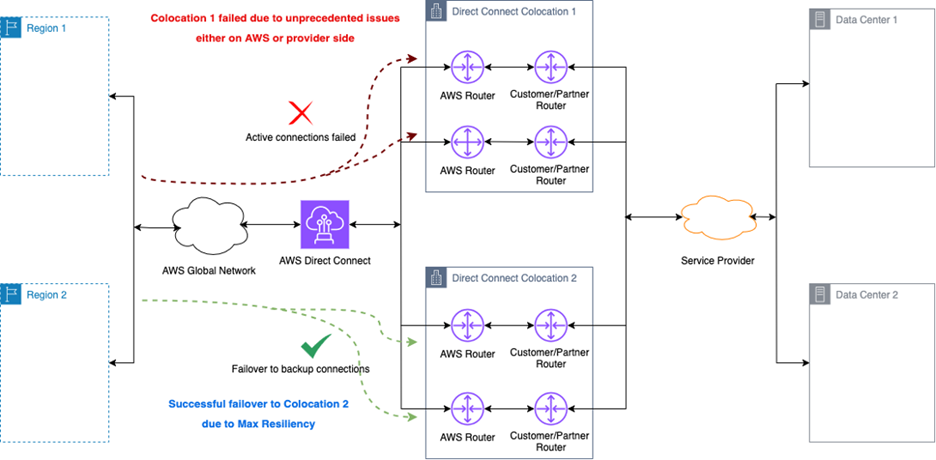 |
图 1:Colocation 1 因突发异常故障
您可以在两地共址设施之间将 Direct Connect 连接配置为主/备或主/主模式。但若采用主/主模式,必须格外留意,避免故障期间出现拥塞。
如图 2 所示,在主/主模式下,两条链路同时承载流量。虽然整体带宽更大,可一旦其中一条失效,剩余链路必须能独自承担全部流量且不被拥塞。为此,必须确保正常运行时双链路的总利用率不超过任一条链路的剩余带宽;否则幸存链路带宽被超限,将导致性能下降甚至服务中断。
成功部署主/主连接需要持续监控与容量规划:既要预先开通足够带宽,也要定期评估实际用量,防止单链路故障后出现拥塞。您可配置 Amazon CloudWatch 告警,实时跟踪利用率,一旦超过设定阈值即收到通知。
图 2:故障场景下的链路过载。该图说明主/主配置若容量规划不足,当一条链路失效时,剩余链路因需承载全部流量而产生拥塞,进而造成性能劣化。图中亦展示可切换至冗余站点,以缓解主连接组的拥塞。
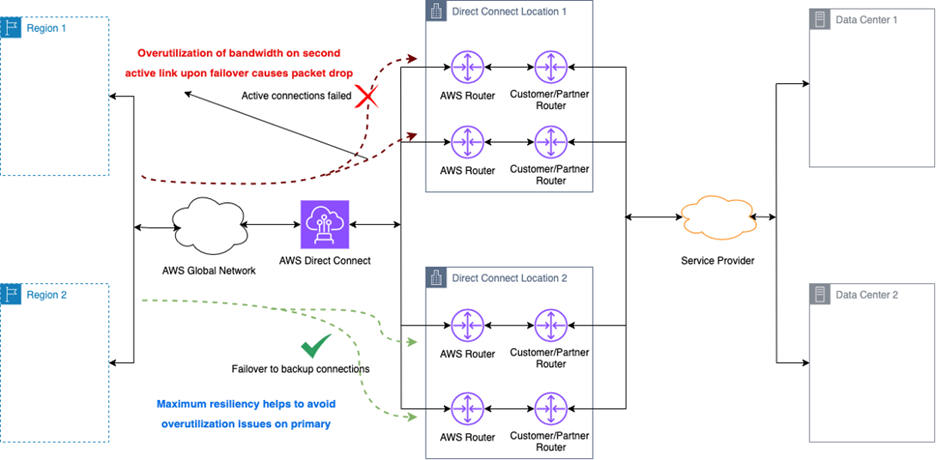 |
图 2:切换至备用链路后链路利用率过高
当 AWS 网络侧与用户或合作伙伴网络侧同时发生故障或维护事件时,最大弹性设计仍能带来收益。如图 3 所示,该架构可将流量无缝切换至第二处 Direct Connect 接入点。
图 3:并发维护场景处理。该架构图展示在 AWS 与用户/合作伙伴同时进行维护的情况下,最大弹性拓扑如何保持连接不断,凸显地理与端口多样性的重要性。
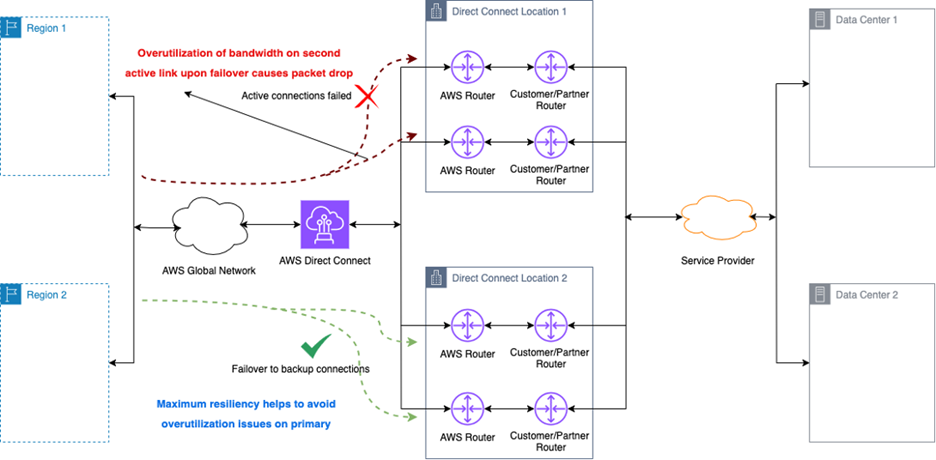 |
图 3:AWS 路由器与用户/合作伙伴路由器同时进行维护
客户如何为维护做好准备
如果您的网络架构已经具备良好的弹性设计,那么在计划内的 Direct Connect 维护期间,通常无需采取任何预防性操作。维护过程中,AWS 会确保被维护的端点不再承载客户流量,业务将自动切换到您剩余的连接上。
在流量迁移的第一阶段,您的设备仍保有有效路由,可继续转发流量。AWS 会给出 60 秒的收敛窗口,随后才从该 Direct Connect 端点撤销路由。
高弹性架构的意义就在于此——无需人工干预,依靠冗余链路与自动 failover 即可在计划维护期间保持业务不中断。这也印证了一开始就按高可用思路设计的长期价值。只要前期投入做好健壮的拓扑,计划维护对运营的影响即可降至最低甚至为零。
若您希望在维护前主动控制流量走向,可借助 Local Preference BGP 团体属性,向 Direct Connect 端点下发不同的本地优先级值,从而决定 AWS 回注您本地网络的路径。
例如,在 AWS 正式维护前,您可自选时间窗做一次配置变更:把主/备连接的优先级互换,或将双活改为单活,确保即将被维护的链路提前清空流量。
采取上述措施后,您可对流量走向拥有更高掌控力,在计划维护全程避免业务抖动。
对于无法提前迁流、且无预警的紧急维护,您可能会遭遇数分钟丢包。其根源常在于 Direct Connect 链路中间存在 L2 设备(如交换机),当 AWS 侧链路失效时,您的端口并不会同步感知,BGP 会话需等 hold-time 超时(默认 180 秒)才拆除,导致路由收敛延迟、中断时间拉长。
要把紧急维护的丢包时间压到最低,AWS 建议为所有虚拟接口(VIF)启用 BFD(Bidirectional Forwarding Detection),详见《Direct Connect BFD 文档》。
BFD 可将 BGP 故障检测时间从默认 180 秒缩短到亚秒级。链路一旦失效,BFD 立即拆除 BGP 会话并撤销路由,网络收敛速度大幅提升。
若不启用 BFD,故障后数分钟的丢包几乎不可避免;而 BFD 把检测时间从分钟降到秒级,能让您的 TCP 会话在突发中断或紧急维护中更快重连,显著缩短业务受损时长。
因此,为所有 VIF 开启 BFD 是应对收敛延迟、减轻意外事件影响的最佳实践,强烈建议纳入标准配置。
如何对自身的弹性态势建立信心?
Direct Connect 连接共享的特性决定了你必须主动验证自己的弹性态势。
链路一侧归 AWS 管理,另一侧归你(或 Direct Connect Partner)管理,端到端配置与行为并非完全透明,这种黑盒部分会让人对故障或维护时的实际表现心里没底。
最佳实践是在批准的维护窗口内,周期性地把流量手动切到冗余链路上,让应用方确认功能与性能依旧符合预期。
你可以利用 AWS 提供的 Local Preference 团体属性控制回注流量。推荐每季度在计划维护时把主/备角色互换一次,既全面锻炼备用链路,也验证双方路由的收发与优选是否正常。另一种办法是直接使用控制台里的 Direct Connect Failover Test 功能,定期做故障演练。
主动验证弹性,即便连接是共享的,也能让你对 Direct Connect 的可靠性有足够信心。定期测试能把潜在问题提前暴露并修复,避免真正故障或维护时手忙脚乱。
责任公担模型决定了你必须亲自下场,确保自己的 Direct Connect 架构足够韧性。周期验证是规避共享连接固有风险的关键一环。
总结
本文阐述了 AWS Direct Connect 维护的运作机制,并介绍了如何在计划内与紧急维护场景下打造高弹性网络。 落地最大弹性拓扑(多 location、每 location 双连接)、启用 BFD 实现秒级故障检测、定期演练 failover,这些措施能确保关键业务在计划窗口或突发事故中依旧在线,满足业务连续性要求。
请记住以下要点:
- 采用 Maximum Resilience:每 location 至少双连接,跨 location 冗余;
- 开启 BFD,把故障检测时间从分钟降到秒;
- 定期测试冗余链路,持续验证弹性态势;
- 设计时始终围绕自身业务需求,量体裁衣。
欲了解更多 Direct Connect 最佳实践,请访问 Direct Connect 官方文档,或浏览 Networking & Content Delivery 频道获取丰富资源。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
校译作者
AWS 架构师中心: 云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
