亚马逊AWS官方博客
使用Amazon Bedrock和Pipecat构建低延迟智能语音Agent
 |
在生成式AI与语音交互技术快速发展的当下,如何高效构建低延迟、个性化、自然对话体验的智能语音Agent,已逐渐成为业界关注的焦点之一。
智能语音Agent的应用领域广泛,包括智能设备语音交互(如具身机器人、智能音箱)、个人助理、自动化客服(如餐厅预订、销售、保险、预约安排)、营销、语言教学(如英语口语学习)、健康医疗以及多模态内容创作等。
本篇博客将首先介绍构建智能语音Agent的核心组件和延迟优化建议,接着将利用Pipecat开源框架和Amazon Bedrock服务,打造一个支持用户打断、多轮上下文管理的实时交互智能语音Agent
一、智能语音Agent核心组件
 |
智能语音Agent结合了基础模型的文本/语音识别、理解和推理能力,旨在提供实时、自然、连续的语音交互体验。一般来说,构建智能语音Agent通常需要包含以下核心组件:
- VAD( Voice Activity Detection ):检测音频中是否存在人类语音
- EOU(End of Turn/Utterance ) :检测说话者是否已经完成了他们的发言
- STT (Speech To Text):也称为自动语音识别(ASR),将给定音频转录为文本
- LLM 和 LLM Agent:大语言模型,如 Amazon Nova/Nova Sonic,DeepSeek,Anthropic Claude系列模型
- TTS( Text To Speech):也称为语音合成,从文本生成自然且清晰的语音
通过将上述组件组合成一条Pipeline,即可构建出智能语音Agent。随着生成式AI技术的进步,业界发展出了端到端语音模型(即Speech to Speech语音模型),该模型可实现语音输入到语音输出的全链路处理,例如Amazon Nova Sonic就是一款由Amazon研发的Speech to Speech语音模型。端到端语音模型内置了VAD、EOU、STT、LLM、TTS等集成功能,能够实现更低的延迟。这类模型使得构建语音Agent更为轻松便捷。
Amazon Nova Sonic 是一款语音理解和生成模型,可提供自然的类人语音对话式人工智能,并且实现了低延迟和行业领先的性价比。该模型提供流畅的对话处理、自适应语音响应、内容审核、API调用和基于RAG的知识库集成,同时提供高度自适应且引人入胜的用户体验。
 |
这两种方案各有优缺点:Pipeline方案可以对各个部分进行精细控制,但其缺点在于语音到文本的来回转换可能导致部分声音信息丢失,并且延迟相对较大。端到端语音模型方案延迟更低,实现更为简单,并且能够更好地感知声音信息,例如非语言线索(如笑声、犹豫)、语调、重音、风格、情绪等,但对语音如何流入和流出Agent的控制相对较少。
需要注意的是,在当前阶段,SOTA LLM(前沿大语言模型)相比于Speech to Speech语音模型,在成本、推理能力、指令遵循和函数调用等方面仍占据优势。但不可否认,Speech to Speech模型是语音Agent的未来。
二、传输协议对比
要构建自然流畅的智能语音Agent,传输协议的选择至关重要,它们直接影响着语音流的传输效率和实时性。常见的传输协议有WebSocket,WebRTC等,它们有各自的特点,详细对比如下。
| WebRTC | WebSocket | |
| 延迟 | Very Low (<200ms) | Low (<400ms) |
| 传输层协议 | UDP | TCP |
| Signal Control | Signaling Layer | Custom |
| 连接模式 | 点对点(P2P) | 客户端-服务器 |
| 优点 | 1. 点对点通讯效率高 2.专为音频和视频流设计:拥塞控制、数据压缩、 自动数据包时间戳 | 兼容性好:通过 HTTP 握手升级到WebSocket 连接 |
| 缺点 | 复杂度高:需信令机制建立连接,使用STUN/TURN/ICE 等技术实现 NAT 穿透 | 需要服务器参与通信,传输性能和延迟不如 WebRTC |
通过对比可以看出,WebSocket兼容性更好,WebRTC对音视频的传输做了很多优化,传输效率更高。一般来说,对于构建原型和轻量级项目,可以选择Websocket,对于中大型生产项目,WebRTC是更优的选择。但WebRTC协议复杂,部署也很复杂,需要实现信令服务器、STUN服务器(公网IP和端口发现),TURN服务器(P2P连接失败时作为媒体中继服务器,实现诸如NAT穿透)。因此构建一个成熟稳定的WebRTC方案,难度比较大。目前市面上有Livekit开源框架,同时也有Amazon KVS、Daily、Livekit Cloud等商业WebRTC服务可供选择。
使用WebRTC有两种主要方式:一是通过云端的WebRTC服务器中转,商业WebRTC服务多采用此模式;二是直接在客户端和语音Agent端之间建立连接。云端服务器模式可以实现直连模式无法提供的诸多特性,例如多方会话、多方录音等。而直连模式则非常适合语音AI Agent的客户端-服务器场景,它减少了服务器中转环节,并且无需维护任何特定于WebRTC的基础设施。
Tips:
自建WebRTC服务可以使用公开STUN服务器:https://gist.github.com/mondain/b0ec1cf5f60ae726202e。可以根据语音Agent的部署位置选择合适的STUN服务器。
WebRTC服务使用UDP协议进行连接,在亚马逊云部署时需要在安全组开放对应的UDP端口。
三、智能语音Agent延迟优化建议
延迟是影响人与语音Agent之间对话体验的关键因素。人类期望在正常对话中获得快速响应,长时间的停顿会显得不自然(人机对话的典型响应时间通常为500毫秒)。因此,延迟优化对于智能语音Agent来说至关重要。
根据作者基于Amazon Bedrock构建智能语音Agent的实践经验,建议综合考虑以下方式优化延迟技术。
- 语音Agent部署尽量靠近用户,减少网络传输延迟。
- 使用传输效率更高、延迟更低的传输协议,如 WebRTC。
- LLM 延迟优化:LLM的延迟在整个语音Agent的延迟中占据主要部分,因此对LLM进行延迟优化显得尤为关键。在满足要求的前提下,可以采用以下手段进行优化。
- 优先选择端到端语音模型,这种模式一般比STT-LLM-TTS的Pipeline模式延迟更低。
- 选择参数量更小/推理速度更快的模型(例如Nova Lite,Claude 3.5 Haiku等)。
- 使用Bedrock上支持延迟优化的模型(例如Nova Pro,Claude 3.5 Haiku等)
- 开启 Prompt caching
- Pre-LLM TTS 填充,在用户对话前预先输出内容(如自我介绍),给用户体感上的快。
- 执行长时间函数调用之前,输出提示信息,例如“处理中,请稍后…”,从而减少客户的等待时间。
- 通过LLM提示词引导,缩短回复内容。
典型的Pipeline模式和端到端语音模型延迟对比如下(请注意,不同方案和组件的延迟差异较大,以下数据仅供参考)。在设计智能语音Agent时,将语音端到端延迟控制在800至1000毫秒是一个不错的目标。
| Task | Pipeline 模式 | 端到端语音模式 |
| Transport | 50 – 100ms | 50 – 100ms |
| VAD | ~20ms | 250 – 1000ms |
| EOU | ~100ms | |
| STT | 100 – 500ms | |
| LLM or Agentic Workflow | 250 – 1000ms | |
| TTS | 100 – 450ms | |
| Total | Best: 620ms Worst:2,170ms | Best: 300ms Worst:1,100ms |
四、使用Pipecat框架构建智能语音Agent
构建一个智能语音Agent并非易事。除了实现上文所述的核心组件,还需要考虑如何存储会话上下文、接入外部知识库或对接后端系统等功能。使用Pipecat 开源框架可以显著简化智能语音Agent的开发过程。
4.1 Pipecat框架介绍
Pipecat是一个开源的Python框架,专为构建实时语音和多模态对话Agent而设计。它能够轻松协调音频/视频流、AI服务、多种传输方式以及对话流程,从而让开发者更专注于打造独具特色的Agent。
Pipecat主要特性包括:
- 低延迟实时交互
- 支持Agentic Workflow,可集成各类工具(tools)
- 支持 WebRTC、WebSocket等传输协议
- 灵活的模型和服务选择,如 Amazon Bedrock,Polly,Transcribe及其它主流的模型。
- 支持用户打断
- 多模态
4.2 方案介绍
接下来,我们将借助一个示例项目,探讨如何基于Pipecat框架,并结合Amazon Bedrock、Amazon Polly和Amazon Transcribe等服务来构建智能语音Agent。Amazon Bedrock是用于构建生成式 AI 应用程序和Agent的托管服务,支持多种自研和第三方大模型,例如Amazon Nova、Nova Sonic、DeepSeek、Anthropic Claude系列模型。Amazon Polly是一项完全托管的服务,可按需生成语音,将任意文本转换为音频流(即TTS),并支持数十种语言。Amazon Transcribe 是一项完全托管的自动语音识别(ASR)服务,自动将语音转换为文本。
该示例项目演示了如下功能:
- 支持Pipeline模式和端到端语音模式(使用Amazon Nova Sonic模型)。
- 使用WebRTC作为传输协议。
- 通过Tools集成知识库,该知识库包含了2025年亚马逊云科技中国峰会的相关内容。
- 提供Web前端,用于与Agent进行语音交互。
完整的示例代码见Github代码仓库: https://github.com/freewine/sample-voice-agent-with-Amazon-Bedrock-and-Pipecat
使用Pipecat构建智能语音Agent的逻辑架构如图所示。
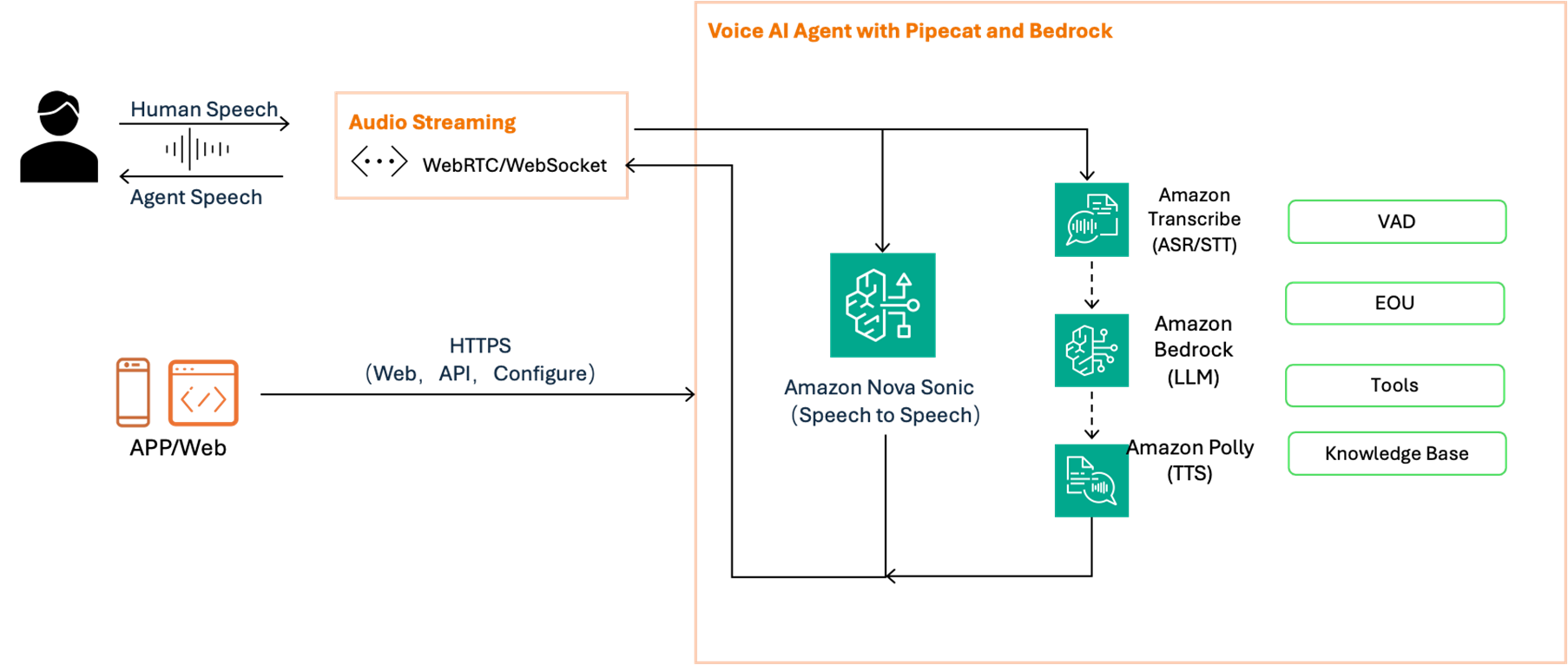 |
4.3 Agent核心代码
使用Pipecat构建语音Agent的关键在于工作流的搭建。以下是Pipeline模式的示例代码,从中可以看出,通过STT、LLM和TTS等服务构建了一条完整的Pipeline。为便于阅读和理解,我们已对代码进行简化,完整代码请访问Github仓库。
如果使用Speech to Speech模型,可以省去TTS和STT,实现端到端语音输入输出。示例代码如下。
4.4 系统提示词最佳实践
语音Agent与文字Agent的系统提示词在核心原则上是相通的,但语音Agent具有其特殊性,需要额外考虑多方面因素,例如口语化的适应、非语言信息的处理、错误纠正和澄清等。以下是作者在构建语音Agent时总结的几点经验:
- 由于STT/ASR模型在实时流中可用的上下文信息有限,语音转录时很可能出现错误。好在当前的LLM已足够智能,在进行推理时可以访问完整的对话上下文。因此,我们可以通过系统提示词告知LLM,输入为用户语音的转录文本,指示其进行相应推理以纠正转录错误。建议在系统提示词添加如下的内容:When you receive a transcribed user request, silently correct for likely transcription errors. Focus on the intended meaning, not the literal text. If a word sounds like another word in the given context, infer and correct.
- 鉴于LLM的推理结果将用于TTS进行语音合成,因此可在系统提示词中要求其避免输出难以发音的内容:Your output will be converted to audio so don’t include special characters in your answers.
- 保持Agent语音输出的简洁性,打造更好的对话体验,建议在系统提示词里添加如下约束:Keep your responses brief, generally two or three sentences for chatty scenarios.
参考文件
- Pipecat: https://github.com/pipecat-ai/pipecat
- Amazon Nova Sonic: https://aws.amazon.com/ai/generative-ai/nova/speech/
- Amazon bedrock:https://aws.amazon.com/bedrock/
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。