亚马逊AWS官方博客
宣布在 Amazon SageMaker AI 中推出 Amazon Nova 定制功能
现在,我们宣布在 Amazon SageMaker AI 中推出一整套适用于 Amazon Nova 的定制功能。客户现在可以在模型训练的整个生命周期(包括预训练、有监督的微调和对齐阶段)对 Nova Micro、Nova Lite 和 Nova Pro 进行定制。这些技术以即用型 Amazon SageMaker 配方的形式提供,可无缝部署到 Amazon Bedrock,支持按需和预置吞吐量推理。
Amazon Nova 基础模型为各行各业的多种生成式 AI 使用案例提供支持。随着客户扩大部署规模,他们需要能够反映专有知识、工作流程和品牌要求的模型。提示优化和检索增强生成(RAG)能很好地将通用基础模型集成到应用程序中,但业务关键型工作流程需要定制模型,以满足特定的准确性、成本和延迟要求。
选择合适的定制技术
Amazon Nova 模型支持一系列定制技术,包括:1)有监督的微调;2)对齐;3)持续预训练;4)知识蒸馏。最佳选择取决于目标、使用案例的复杂性以及数据和计算资源的可用性。您也可以结合多种技术,以性能、成本和灵活性的理想组合实现预期成果。
有监督的微调(SFT)使用特定于目标任务和领域的输入-输出对训练数据集来定制模型参数。根据数据量和成本考虑,可从以下两种实现方法中选择:
- 参数高效微调(PEFT) — 通过 LoRA(低秩适应)等轻量级适配器层,仅更新模型参数的子集。与全面微调相比,它的训练速度更快,计算成本更低。经过 PEFT 适配的 Nova 模型可导入到 Amazon Bedrock,并使用按需推理调用。
- 全面微调(FFT) — 更新模型的所有参数,非常适合拥有大量训练数据集(数万个记录)的场景。通过 FFT 定制的 Nova 模型也可导入到 Amazon Bedrock,并通过预置吞吐量调用进行推理。
对齐可引导模型输出朝着产品特定需求和行为的预期偏好(例如公司品牌和客户体验要求)的方向发展。这些偏好可以通过多种方式编码,包括实证示例和政策。Nova 模型支持两种偏好对齐技术:
- 直接偏好优化(DPO) — 提供一种简单的方法,使用首选/非首选响应对来调整模型输出。DPO 从比较偏好中学习,以针对语气和风格等主观要求优化输出。DPO 提供参数高效版本和全模型更新版本。参数高效版本支持按需推理。
- 近端策略优化(PPO) — 使用强化学习,通过优化期望奖励(如有用性、安全性或参与度)来增强模型行为。奖励模型通过对输出评分来指导优化,帮助模型学习有效行为,同时保持先前学到的能力。
持续预训练(CPT)通过对大量未标记的专有数据(包括内部文档、transcript 和特定业务内容)进行自监督学习来扩展基础模型知识。在 CPT 之后进行 SFT,然后通过 DPO 或 PPO 进行对齐,为您的应用程序提供一种全面定制 Nova 模型的方法。
知识蒸馏将知识从更大的“教师式”模型转移到更小、更快、更具成本效益的“学生式”模型。蒸馏适用于客户没有足够的参考输入-输出样本,并且可以利用更强大的模型来扩充训练数据的情况。该流程将为特定使用案例创建具有教师级准确性以及学生级成本效益和速度的定制模型。
下表总结了不同模态和部署选项下可用的定制技术。每种技术都根据您的实施要求提供特定的训练和推理能力。
| 配方 | 模态 | 培训 | 推理 | ||
|---|---|---|---|---|---|
| Amazon Bedrock | Amazon SageMaker | Amazon Bedrock 按需 | Amazon Bedrock 预置吞吐量 | ||
| 有监督的微调 | 文本、图像、视频 | ||||
| 参数高效微调(PEFT) | ✅ | ✅ | ✅ | ✅ | |
| 全面微调 | ✅ | ✅ | |||
| 直接偏好优化(DPO) | 文本、图像、视频 | ||||
| 参数高效 DPO | ✅ | ✅ | ✅ | ||
| 全模型 DPO | ✅ | ✅ | |||
| 近端策略优化(PPO) | 仅文本 | ✅ | ✅ | ||
| 持续的预训练 | 仅文本 | ✅ | ✅ | ||
| 蒸馏 | 仅文本 | ✅ | ✅ | ✅ | ✅ |
抢先体验客户,包括 Cosine AI、麻省理工学院(MIT)计算机科学与人工智能实验室(CSAIL)、大众汽车、Amazon 客户服务和 Amazon 目录系统服务,已经成功使用了 Amazon Nova 定制功能。
Nova 模型定制的实际应用
下面将向您介绍一个使用现有偏好数据集,通过直接偏好优化定制 Nova Micro 模型的示例。为此,您可以使用 Amazon SageMaker Studio。
在 Amazon SageMaker AI 控制台中启动您的 SageMaker Studio,然后选择 JumpStart,这是一个机器学习(ML)中心,包含基础模型、内置算法和预构建的 ML 解决方案,只需点击几下即可部署。
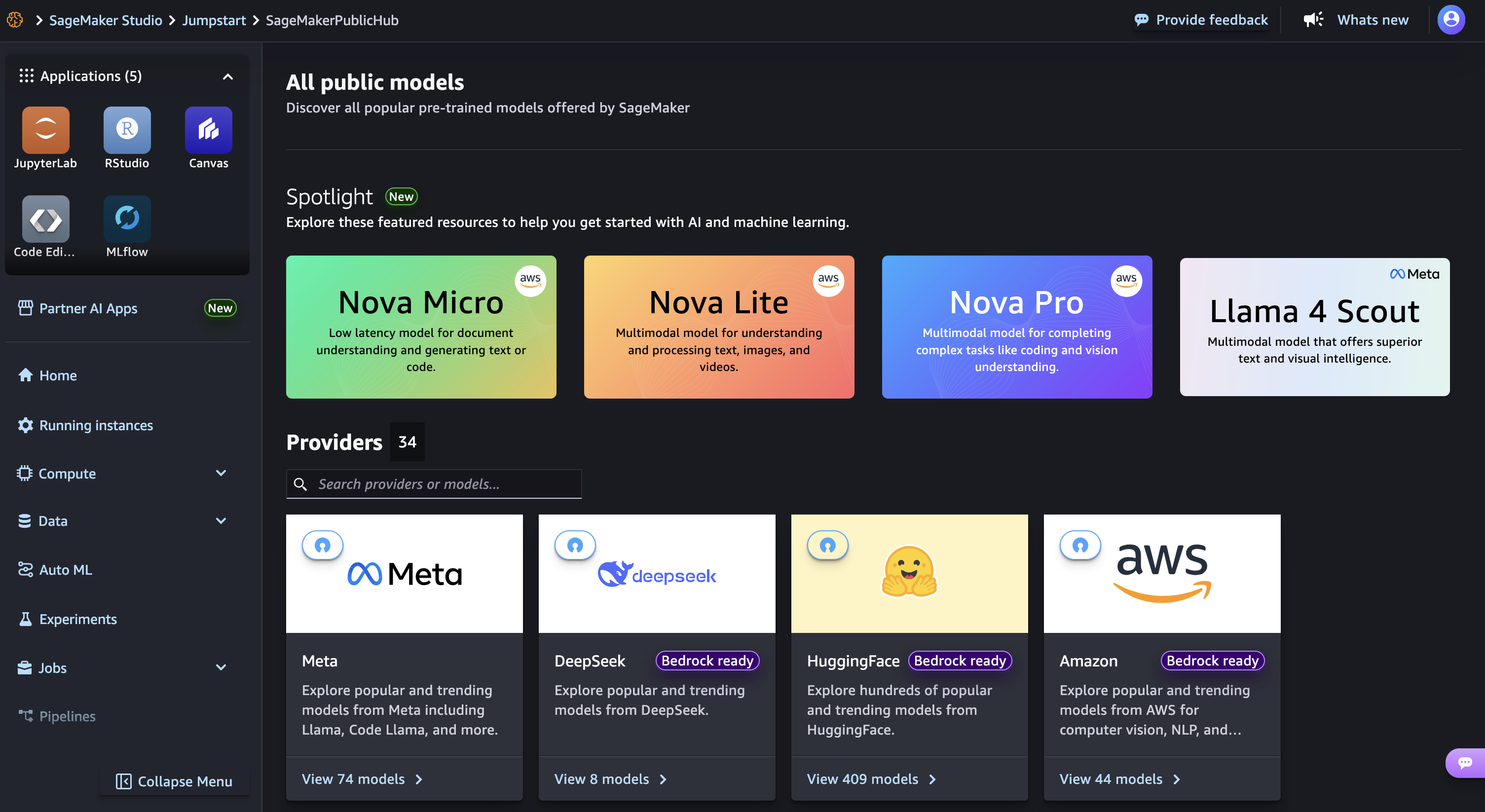
然后,选择 Nova Micro(这是一个仅文本模型,在 Nova 模型系列中以最低的每次推理成本提供最低延迟的响应),然后选择训练。
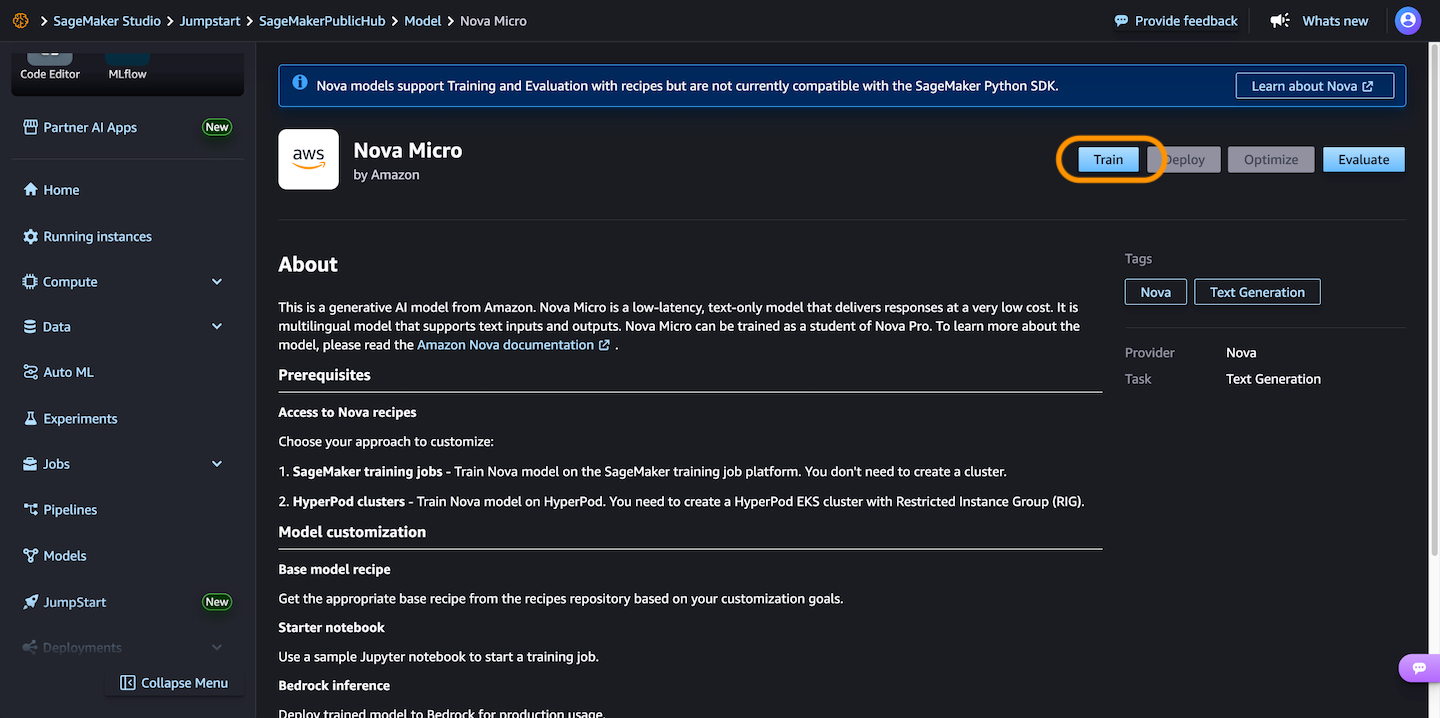
接下来,您可以选择一个微调配方,使用标记数据训练模型,以增强处理特定任务的性能并与期望的行为保持一致。选择直接偏好优化可根据您的偏好轻松调整模型输出。
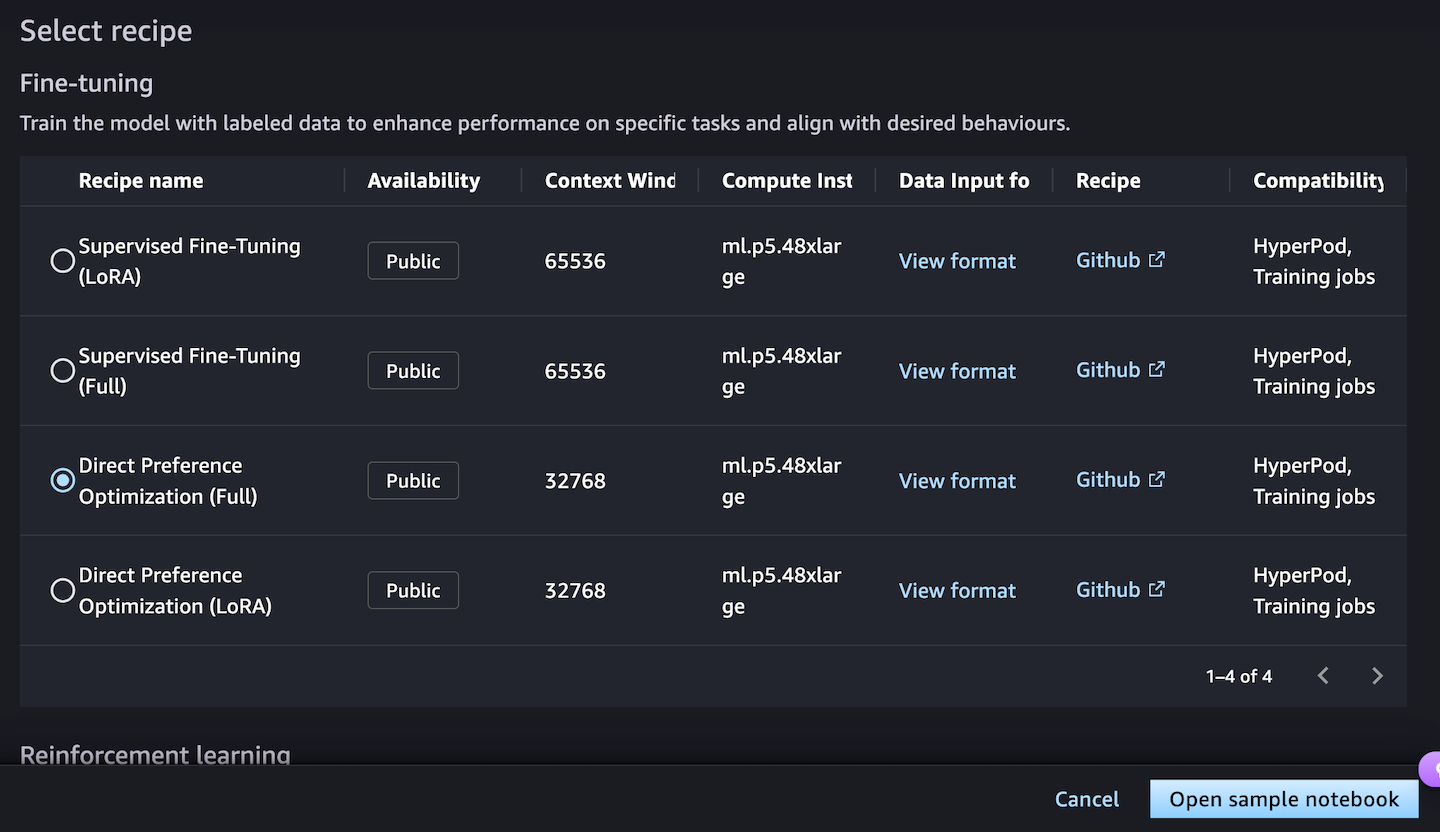
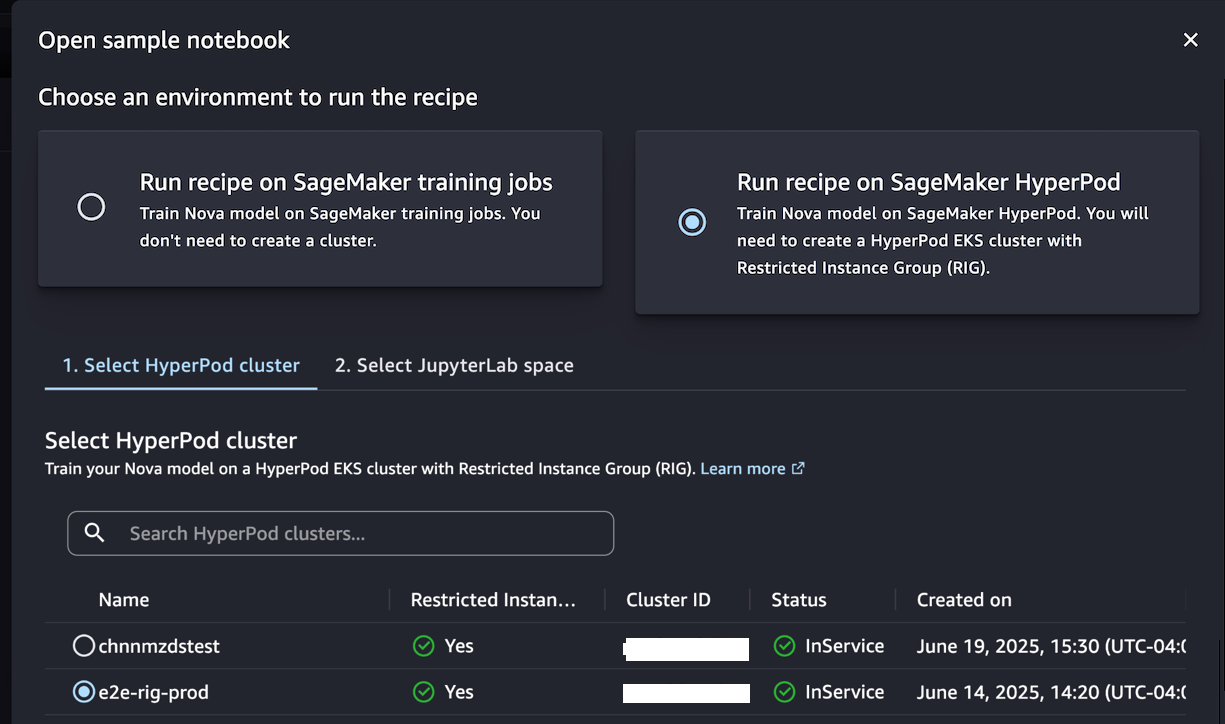
当您选择打开示例笔记本时,可以通过两个环境选项来运行该方案:在 SageMaker 训练作业上运行,或者在 SageMaker Hyperpod 上运行:
当您不需要创建集群时,选择在 SageMaker 训练作业上运行配方,并通过选择 JupyterLab 空间,使用示例笔记本训练模型。
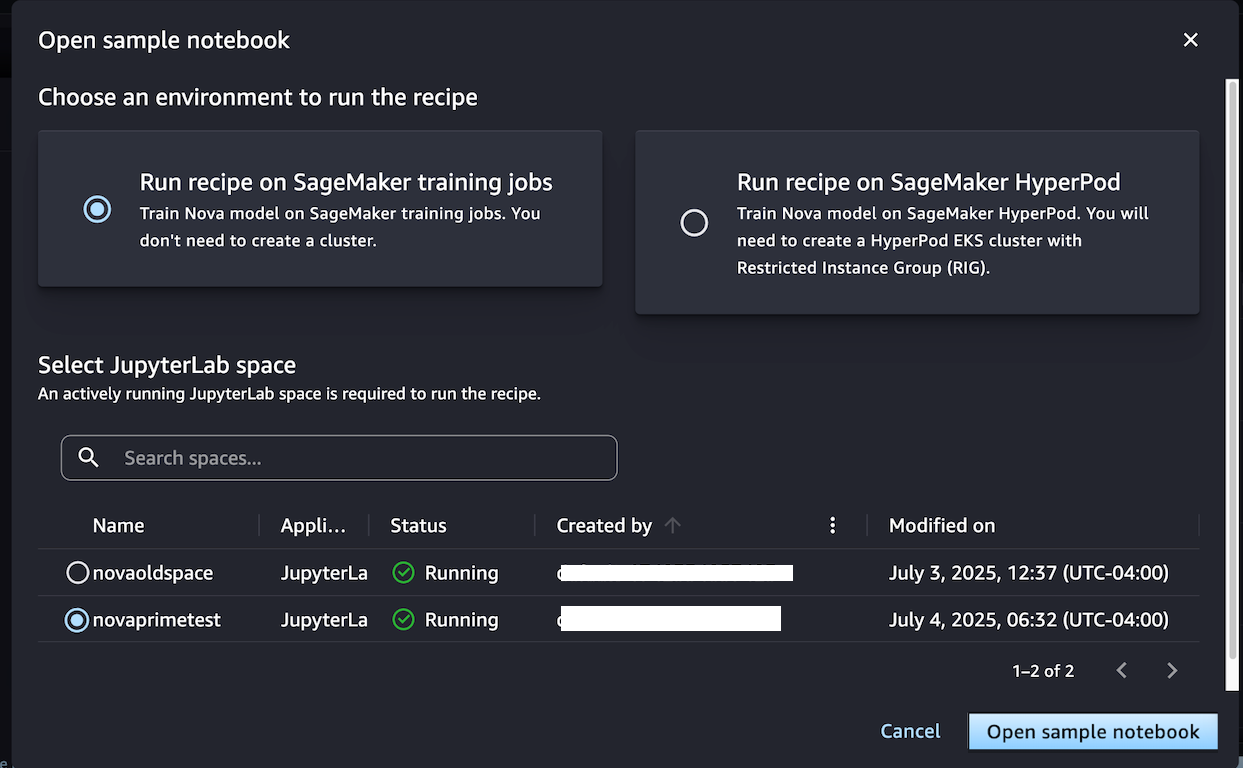
或者,如果您希望拥有一个为迭代训练过程优化的持久集群环境,请选择 在 SageMaker HyperPod 上运行配方。您可以选择一个至少有一个受限实例组(RIG)的 HyperPod EKS 集群,以提供专门的隔离环境,这是此类 Nova 模型训练所必需的。然后,选择您的 JupyterLabSpace 并打开示例笔记本。
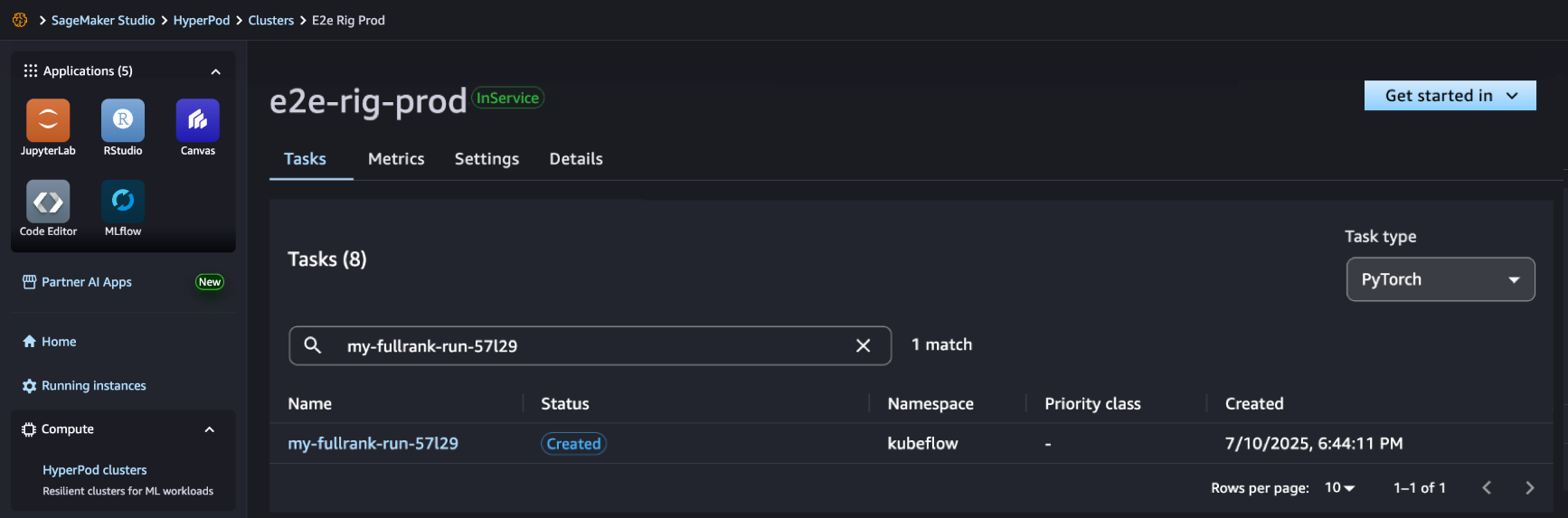
该笔记本提供了使用带有配方的 SageMaker Nova 模型创建 SageMaker HyperPod 作业,并将其部署用于推理的端到端演练。借助 SageMaker HyperPod 配方,您可以简化复杂配置,并无缝集成数据集以优化训练作业。

在 SageMaker Studio 中,您可以看到 SageMaker HyperPod 作业已成功创建,您可以对其进行监控以了解后续进展。
作业完成后,您可以使用基准测试方案评估定制模型处理代理任务的性能是否更好。
有关全面的文档和其他示例实现,请访问 GitHub 上的 SageMaker HyperPod Recipes 存储库。我们将根据客户反馈和新兴的 ML 趋势继续扩展这些配方,确保您拥有成功进行 AI 模型定制所需的工具。
开始使用
适用于 Amazon SageMaker AI 上的 Amazon Nova Recipes 已在美国东部(弗吉尼亚州北部)推出。通过访问 Amazon Nova 定制网页和 Amazon Nova 用户指南了解有关此功能的更多信息,并在 Amazon SageMaker AI 控制台中开始使用。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。