AWS Web3 Blog
Optimize tick-to-trade latency for digital assets exchanges and trading platforms on AWS
Digital assets is a rapidly maturing set of asset class, and customers are choosing AWS to build exchanges and trading platforms to differentiate their offerings across this dynamic and growing industry. In this multi part series, we explore the world of centralized exchange (CEX) and market maker (MM) infrastructure on AWS. In Part 1, we establish a summary foundation on CEX and MM concepts, focusing on the fundamental principles of CEX and MM system deployment and the basics of optimizing latency across the associated AWS services and architecture patterns. This post is an entry-level discussion for those looking to understand the basics of cloud-based trading infrastructure.Subsequent parts will dive deep into AWS compute instance selection, testing frameworks, hybrid (on-prem and cloud) deployments, plus OS and application optimization including Linux kernel tuning and advanced networking techniques like kernel bypass, targeting experienced engineers building low-latency trading systems.
Let’s begin with Part 1, where we introduce a modern digital assets trading infrastructure on AWS.
Market participants: Venues, buy-side and sell-side
In digital asset markets, buy-side and sell-side firms are two essential pillars of the trading ecosystem. Buy-side participants—including institutional investors, digital asset funds, retail traders, and proprietary trading firms—acquire digital assets for their investment portfolios, focusing on strategy development, research, and trade execution to generate returns.
Sell-side firms, such as market makers and brokers, facilitate trade execution and order routing, while digital asset exchanges provide the platforms where assets are listed and traded. Together, exchanges and sell-side firms form the core trading infrastructure, ensuring liquidity, matching orders, and offering essential financial services. They generate revenue primarily through fees and bid-ask spreads.
Market Making Strategies: Latency, Jitter and Arbitrage in digital asset markets
High-frequency, low-latency trading (HFT) is rapidly emerging in centralized digital assets trading, and has been a critical component of the financial market infrastructure across equities, commodities, and foreign exchange markets, as well as derivatives markets including futures, for decades. It has a core function in providing market participants increased liquidity, lower transaction costs, price efficiency, and discovery. The two key technical success metrics of HFT platforms are latency and jitter for price discovery, strategy, and order execution. HFT firms operating in digital asset markets strive for low double-digit microsecond tick-to-trade performance in order to remain competitive.
When making a market, an HFT firm is obliged to quote prices to the market on both sides of the book—the bid (MM is buying, counterparty is selling) and the ask (MM is selling, counterparty is buying). In doing this, they are providing liquidity, but also carrying temporary inventory risk. The core function of an MM strategy is to capture the spread (the difference between bid and ask prices) while managing risk and providing the best (fastest) execution. MMs need to execute an extremely high volume of orders in order to provide liquidity to the market and to profit from the spread. HFT firms capitalize on temporary price differences across multiple exchange venues where digital assets trade. Success requires optimized execution and microsecond-level speed, as delays can eliminate arbitrage opportunities. For detailed discussion of crypto arbitrage strategies, visit What is Crypto Arbitrage? How Does It Work?
Fair and equal access in digital asset markets
Fair and equal access ensures that all market participants have the same opportunity to trade and access information on digital asset venues. In mature markets like equities and derivatives, regulatory oversight enforces strict disclosure and equal access requirements, embedded deeply in both the application and infrastructure layers of exchanges. Technically, exchanges achieve fair access by minimizing latency disparities, ensuring all participants experience similar response times within defined tolerances. These tolerances can range from microseconds in high-frequency trading to milliseconds in less time-sensitive environments. This consistency enables market makers, brokers, hedge funds, and proprietary trading firms to participate reliably in price discovery, liquidity provision, and trade execution. In digital asset markets, the concept of fair and equal access is still evolving. Regulatory frameworks are fragmented and still developing, and many digital asset venues are built on cloud platforms designed for broad scalability rather than the precise performance tuning required by the most demanding traders. As the industry matures, providers are working to enhance these capabilities.
At AWS, we are continuously improving our platform to support exchanges and trading firms in achieving greater fairness and equality.
Integrated architecture
Centralized digital asset exchanges optimize their infrastructure on AWS to provide low-latency performance that enables MMs to execute thousands of trades per second. AWS provides a number of optimizations on compute placement and network topologies that reduce the latency and jitter for large liquidity providers trading on AWS Cloud hosted exchanges. The following reference architecture depicts a typical CEX transaction processing hot path for latency-optimized access with an MM.
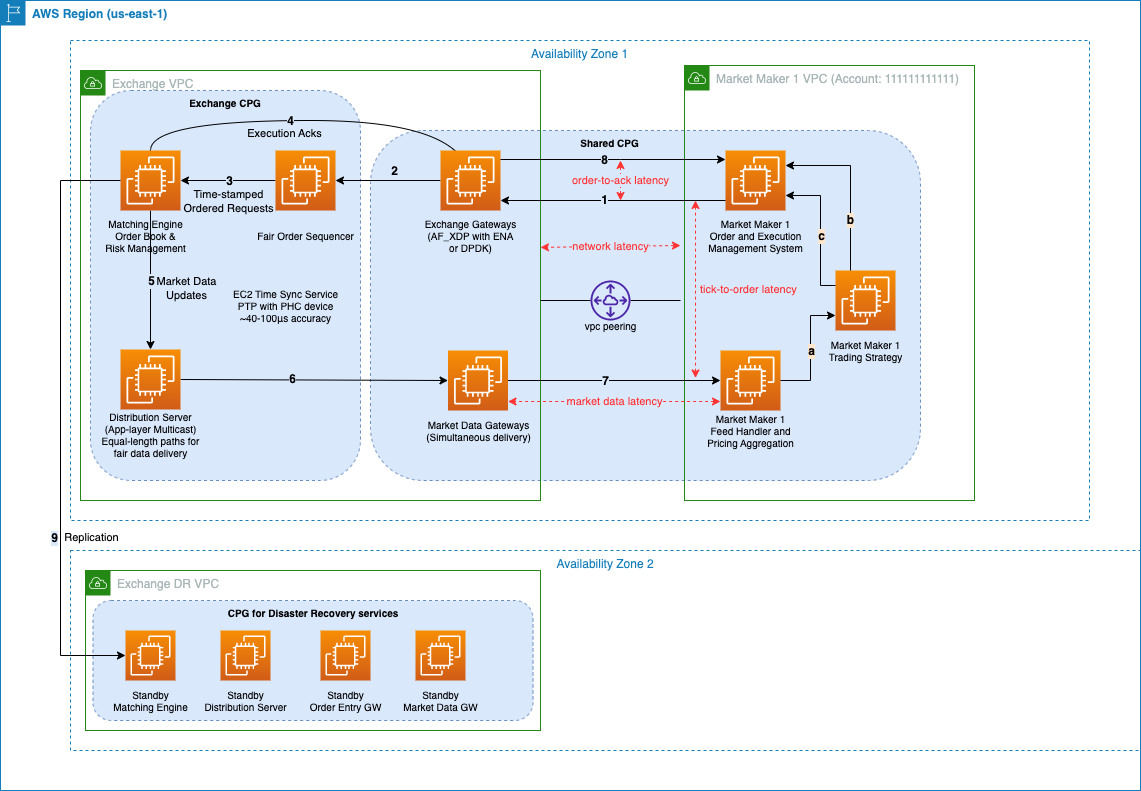
The trade receive and processing flow consists of the following steps:
- An order is submitted to the Exchange Gateway.
- The order is forwarded to the Fair Order Sequencer.
- The sequencer applies batching and sends time-stamped orders to the matching engine.
- The matching engine sends execution acknowledgements.
- Market data updates are sent to the distribution server.
- Updates are sent to the market data gateway.
- Market data is delivered to the HFT feed handler:
- The feed handler sends market data to the trading strategy engine.
- The trading strategy engine generates a signal to provide or take liquidity, which is sent to the order management system.
- The order management system (OMS) sends orders and receives execution confirmations.
- Execution notifications are delivered to the OMS.
- Data are replicated to a secondary Availability Zone or AWS Region to ensure continuous operation in the event of the primary Availability Zone becoming impaired. High availability and disaster recovery approaches vary by exchange venues—ranging from full stack synchronous failover to partial failover of order layers only for position management and reconciliation.
To expand on these high-level steps, in the following sections, we will refer to specific latency and performance optimizations related to the numbered sections of the preceding architecture diagram.
How to approach latency optimization
The preceding diagram illustrates the various hops between components in the architecture where latency and jitter impact performance. HFTs seek to optimize two main holistic latencies: Steps 1–8, known as order-to-ack latency, and Steps 7 and 1, known as tick-to-order latency. The former is a representation of the entire flow of an order transaction through both HFT and exchange platforms, and the latter specifically measures the speed at which an HFT can consume price changes in the market, convert them to a trading signal, and enter or modify their positions in the market accordingly.
The two key technical success metrics of HFT platforms are latency and jitter for price discovery, strategy, and order execution. HFT firms operating in digital asset markets strive for low double-digit microsecond tick-to-trade performance in order to remain competitive. They need to optimize multiple layers of their cloud infrastructure and application stack to achieve and maintain this performance, these fall into four broad categories:
- Network: Latency from the underlying network, including how AWS routes packets, instance placement, and connectivity choices.
- Compute: Latency from Amazon Elastic Compute Cloud (EC2) instance types, including instance selection, kernel and OS tuning, and optimizing Elastic Network Adapter (ENA) performance.
- Application: Latency from business logic and user-space processing, focusing on efficient traffic handling, CPU/memory usage, and minimizing resource contention.
- System: Latency from system-wide processes, such as data distribution, timing services, and overall architecture efficiency.
Optimizing across these layers ensures the lowest possible end-to-end latency for trading and real-time workloads
High-level optimization considerations
In the following sections, we discuss some of the high-level latency topics related to the solution architecture.
CEX and MM hot paths
A CEX and MM each have what they consider to be hot paths.
These are pricing, order, and distribution pathways in their various platforms that should be fully optimized to reduce latency and jitter. A CEX is primarily concerned with providing optimized hot paths for order entry, execution onto the order book, and distribution of market data as a result of order activity by market participants which are defined by steps 2 to 6 in the architecture diagram above. These are critical for a CEX to make sure they provide the best execution and pricing experience to market participants and therefore attract liquidity to the markets they host. For a CEX, the hot path includes functions such as order entry, balance checks, matching, acknowledgements, and the publication of market events.For MMs, tick-to-trade latency (the time between receiving market data, evaluating it for trading opportunities, and placing the trade on the exchange) is a business-critical metric. HFT MMs compete across millions of orders on either side of the order book and are obligated to provide this liquidity, while seeking additional opportunities to extract profits from market movements. Driving the lowest-achievable latency in their hot paths, which include steps 7,8 and 1 in the architecture diagram above, makes sure they build and maintain the most recent view of the market and avoid risk and opportunity cost.
A fundamental principle of building hot paths on AWS between EC2 instances is the use of cluster placement groups (CPGs) to reduce the physical network distance between individual components of a hot path. As shown in the architecture diagram, CEX and MM workloads should be placed in CPGs to localize the placement of instances on the same network spine in an Availability Zone. Using CPGs can provide an average of 37% reduction of P50 and 39% reduction of P90 UDP roundtrip time latencies compared to instances outside CPGs. For more technical details on CPGs and an explanation on how these latencies have been measured, refer to Crypto market-making latency and Amazon EC2 shared placement groups. Latency incurred by hot paths extends from the network into an instance, through the network card, kernel, operating system, and application layers. Some of these concepts are discussed later in this series.
Latency optimization trade-offs: Fast and resilient matching engines
Using CPGs as done in the reference architecture, imposes a number of architectural trade-offs. Although they minimize network latencies, they aren’t compatible with building fully resilient Multi-AZ architectures. The following are some considerations when making these trade-offs.
Matching engines as state machines
Matching engines are typically modeled as deterministic state machines, where the same sequence of input events results in the same predictable state. This correctness and consistency are critical concepts for CEX order books (and many financial systems). For consistency (critical in financial systems), core execution is typical single-threaded to avoid non-determinism, ensuring linear processing of operations. This design makes sure operations such as order matching follow strict causality and are processed in a linear, predictable order.
Distributed state machines for high availability and scalability
Given the preceding constraints, to achieve high availability and scale in larger markets, matching engines are implemented as distributed state machines across several instances. Distributed state machines replicate the same logic across multiple nodes, so that even if some nodes fail, the system remains operational as long as a quorum is maintained. This architecture allows for horizontal scaling by distributing workloads (such as instruments, asset types, and accounts) across multiple replicas while providing consistency through a robust consensus protocol. Consensus protocols like Raft maintain consistency by electing a leader to coordinate log replication ensuring quorum-based fault tolerance.
Messaging, consistency, and low latency
To distribute messages across nodes with minimal latency while also providing consistency, consensus protocols are often combined with messaging protocols or products. Some customers will design and implement their own messaging layers closely tuned for the specific workload environment and use case, whereas others will use mature and robust offerings like Aeron or Chronicle. These messaging layers are optimized to provide low-latency, high-throughput communication between publishers and subscribers. Consensus and messaging protocols, together, enable deterministic replication of state machine inputs while minimizing latency overhead.
Multi-AZ deployments for high availability and disaster recovery
These consensus and messaging solutions can provide high availability within a single Availability Zone and disaster recovery across multiple Availability Zones or even Regions. They achieve this through log replication to secondary targets or by writing to persistent storage layers that survive the failure modes being designed for as shown in step 9 in the reference architecture.
In addition to hot, warm, and cold clusters of EC2 instances, customers use storage services such as Amazon Simple Storage Service (Amazon S3) or Amazon FSx and distributed databases like Amazon Aurora and Amazon Aurora DSQL as persistent storage layers for their workloads and logs. Raft log replication modes vary based on customer business continuity requirements and can be fully synchronous, near-synchronous, or asynchronous. Aside from high availability and disaster recovery, replicated data is also useful for audit- and compliance-related use cases because it contains the entire history of system interactions.
CPGs and Amazon EC2 capacity fulfilment considerations
When using CPGs and shared CPGs to optimize placement and colocate EC2 instances as done in the reference architecture, you need to manage trade-offs with capacity fulfilment. Because CPGs create an effective deployment boundary beneath a single Availability Zone network spine, the available pool of Amazon EC2 capacity is reduced. This impacts both the amount and type of capacity when making Amazon EC2 deployment decisions and also varies by the size of Availability Zone—in large Regions and Availability Zones, the impact is mitigated, whereas in smaller Availability Zones, it’s heightened. These trade-offs are relevant to both CEXs and HFT MMs. You can manage the associated risks by reserving Amazon EC2 capacity, typically by creating On-Demand Capacity Reservations, either for baseline requirements or for your full footprint. That way you can benefit from reduced latency and improved capacity assurance with shared CPGs. However, shared CPGs add complexity since capacity fulfillment must be coordinated across multiple parties.
This is an emerging concept in AWS Cloud-based colocation, and AWS continues to develop EC2 CPG capacity sharing capabilities with a view that CEXs could potentially abstract for their largest HFT MMs by creating business models around reserving and re-charging for Amazon EC2 compute deployed in shared CPGs.
CEX and MM network boundary latency
The network boundary between a CEX and MM is critical for HFTs seeking low-latency colocation with digital asset exchanges. Since customers can’t control these boundaries, latency and jitter characteristics depends on placement and network design.As mentioned earlier, CPGs are a fundamental building block for latency-optimized placement.
Shared CPGs are key for latency optimization, extending colocation different AWS accounts to achieve the basic principles of cloud colocation within a Region. This pattern has also been applied in the reference architecture above and also discussed in Crypto market-making latency and Amazon EC2 shared placement groups.
Digital asset exchanges can provide several connectivity patterns to HFTs, each with their own latency characteristics, ranging from 50–200 microseconds to over a millisecond, as discussed in One Trading and AWS: Cloud-native colocation for crypto trading.
In general, HFT customers seek the lowest-latency path to exchanges, avoiding Content Distribution Networks (CDNs) and load balancers where possible, and ideally interface with exchange endpoints that are stopped directly on EC2 order gateways either using public IPs or, for the lowest latency, using private IPs across a virtual private cloud (VPC) peering connection.
They also optimize for protocol choice, favoring Financial Information eXchange (FIX) rather than REST or WebSockets while minimizing protocol induced latency. CEX rarely provide binary or proprietary protocols that would further optimize latency for HFTs, although this is an area that is likely to see development as the industry matures.
HFTs monitor latency to CEX endpoints using layered testing, from basic HTTP/TCP pings to end-to-end latency to application-level monitoring for market events and end-to-end order execution.Because CEX endpoints and HFT instances can move within an Availability Zone due to scaling or maintenance, HFTs must continuously optimize placement, balancing latency, availability, and instance selection.
Market data and multicast
As depicted in Steps 5–7 in the architecture diagram, a CEX’s matching engine continuously updates the order book based on incoming orders, cancellations, and matched trades, generating a dynamic view of market activity.
This raw order book state is then transformed into market data through aggregation and normalization processes, where the exchange extracts key metrics like best bid and ask prices aggregated at various levels: at the top of the book (Level 1), for each price level in the book (Level 2), and unaggregated for each order at every price level in the book (Level 3).
Market data is also generated for market orders, which, unlike limit orders, don’t rest on the order book and are immediately matched to the best available bid or ask price. In traditional markets, exchanges typically distribute market data to their HFT MMs using UDP multicast across highly optimized, physically bounded, colocation networks that provide consistent latency to colocated market participants. Cloud-hosted CEXs, however, predominantly distribute real-time market data using TCP unicast WebSocket APIs. In addition to WebSocket APIs, REST APIs are commonly used for on-demand or periodic data retrieval, such as historical trades, candlestick data, or order book snapshots. These are suitable for applications like portfolio trackers or analytical tools that don’t require real-time updates, though polling REST endpoints will introduce higher latency and are subject to more stringent rate limits.For institutional MMs, some CEXs offer real-time market data through FIX gateways, which provide a greater degree of message standardization and often lower-latency access compared to the generally available WebSocket endpoints. The CEXs will often host FIX endpoints on cloud infrastructure that is dedicated to specific institutional MMs, hedge funds, and prop trading firms.
Multicast is not natively supported on the AWS network and requires the use of AWS Transit Gateway as a middle-box to replicate and simulate multicast delivery within or between VPCs. Some smaller CEXs will provide market data through shared transit gateways for consumption by MMs. Although Transit Gateway provides a convenient, managed way to achieve multicast delivery within a Region, it hasn’t been specifically designed for high-frequency, low-latency trading use cases, and imposes a scaling limit for larger CEXs. These customers continue to provide market data through the unicast delivery mechanisms mentioned earlier.
Precision Time and fair and equal order processing
For digital asset exchanges, as has been the case for traditional exchanges and markets for many years, providing fair and equal access to market participants is not only a network infrastructure consideration. Implementing fairness extends into various application components associated with order flow and market data distribution—critical to both is the need for fair order and market event sequencing before and after trade matching. In traditional markets, robust regulatory frameworks such as MiFID II necessitate the need for exchanges to implement such concepts to enforce fairness, and digital asset exchanges are typically built with the same application principles.
Core to a fair order sequencing function is the provision, distribution, and consumption of accurate timing. This allows CEXs to timestamp messages across various distributed components in their order, matching engine and market data layers. Precision time also allows HFT MMs to reflect their internal view of the market to more effectively process events and generate signals that respond more accurately to price and volume moves—this in turn informs strategy execution and risk control.Historically, the most accurate timing services in the cloud, whether provided natively or by third parties, were able to achieve accuracy to hundreds of microseconds or milliseconds. This level of accuracy isn’t sufficient for HFT strategies that expect a view of the market that is accurate to low-digit microseconds.
AWS has significantly enhanced time synchronization and network packet ordering capabilities for EC2 instances. In late 2023, AWS improved the Amazon Time Sync Service, enabling sub-100 microsecond—and often sub-50 microsecond—time accuracy across an expanding range of EC2 instances. This is achieved using the Precision Time Protocol (PTP) and a PTP hardware clock, supported by a dedicated timing network and GPS-disciplined clocks in every Availability Zone.
Further advancing precision, AWS introduced hardware packet timestamping in June 2025. This feature appends a 64-bit, nanosecond-precision timestamp to every inbound network packet at the hardware level.
By leveraging the AWS Nitro System’s reference clock and bypassing software-induced delays, hardware timestamping provides nanosecond visibility on when packets arrive at Nitro Network Interface Card (NIC) for both virtualized and bare metal instances.
This enhanced precision improves the execution and monitoring capabilities of digital asset exchanges and HFT MMs building on AWS, allowing CEXs to implement greater degrees of fairness and enabling HFTs to more accurately measure round-trip and one-way latencies in their trading hot path. Customers can now also use hardware timestamps in combination with kernel and application software timestamps, derived from the Amazon Time Sync PTP Hardware Clock (PHC), to identify where contention exists in their network hot paths. Large gaps between hardware and kernel timestamps indicate contention or queuing in the network stack. Delays between kernel and application timestamps suggest CPU or application-level bottlenecks.
For more information on PTP, refer to Precision clock and time synchronization on your EC2 instance and Gaining Microsecond Advantage: How Amazon EC2’s Precision Timekeeping Empowers Flow Traders.
Further reading
- Crypto market-making latency and Amazon EC2 shared placement groups
- Reserve compute capacity with EC2 On-Demand Capacity Reservations
- One Trading and AWS: Cloud-native colocation for crypto trading
- Precision clock and time synchronization on your EC2 instance
- Gaining Microsecond Advantage: How Amazon EC2’s Precision Timekeeping Empowers Flow Traders
- It’s About Time: Microsecond-Accurate Clocks on Amazon EC2 Instances
Conclusion
In the first part of this series, we explored some high-level areas of consideration for optimizing tick-to-trade latency in centralized digital asset trading workloads hosted on AWS. We focused on centralized exchanges and HFT MMs, covering foundational concepts across network, compute, application, and system layers. In the following parts of this series, we will dive deeper into areas of network, compute, operating system and application optimization.
Now go, validate your deployment and networking configuration and start optimizing for latency!