AWS Web3 Blog
EKS marks the spot: scaling Circle’s blockchain nodes with a modern Kubernetes stack
This is a guest post by James Fong, VP of Technical Operations at Circle, and Jake Scaltreto, Principal Site Reliability Engineer at Circle, in partnership with AWS.
Operating blockchain node infrastructure at scale is not for the faint of heart. A diverse assortment of blockchain node software with varying requirements and release cycles, and myriad pitfalls present significant hurdles for even the most seasoned operations team. But what if you could do it with less toil and greater efficiency by leveraging the cloud?
At Circle, we operate scores of nodes across dozens of blockchains in order to provide reliable RPC services supporting products such as USDC, Cross-Chain Transfer Protocol (CCTP), Circle Payments Network (CPN), and others. Circle is a global financial technology firm that enables businesses of all sizes to harness the power of digital currencies and public blockchains for payments, commerce, and financial applications worldwide. Circle is building the world’s largest, most-widely used, stablecoin network, and issues, through its regulated affiliates, USDC and EURC stablecoins. We’ve tackled the unique operational complexities of blockchain node infrastructure, from demanding compute and storage requirements to the constant operational effort of keeping them up-to-date and running, by building a robust solution on AWS.
We operate all of our blockchain node infrastructure on AWS, running all of our nodes exclusively in Amazon Elastic Kubernetes Service (Amazon EKS). We believe that the flexible capabilities of AWS and EKS have enabled us to scale more quickly compared to an on-premises solution.
In this post, we share details about how we operate Circle’s blockchain node infrastructure at scale, using AWS services, common off-the-shelf tools, and some custom tooling.
Circle’s blockchain node infrastructure overview
The following diagram provides an overview of Circle’s blockchain node infrastructure on AWS, illustrating the core components, workflows, and AWS services that enable scalable and reliable node operations.
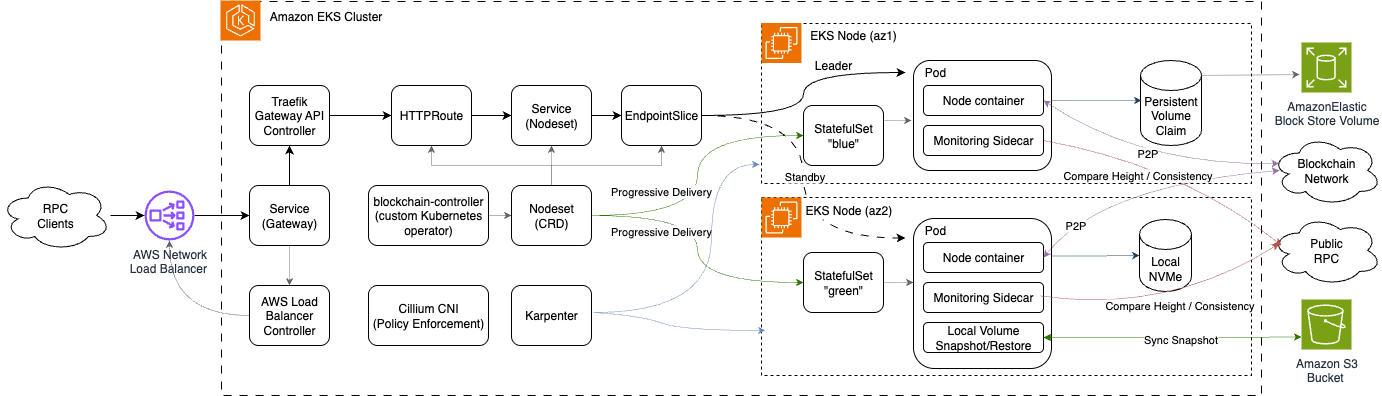
Dynamic Instance Provisioning with Karpenter
Each blockchain has unique requirements for compute, memory, and storage. Some chains run easily on a small instance, while others demand significant resources and terabytes of ultra-low-latency storage. To support these diverse workloads in a multi-tenant EKS cluster, traditional Auto Scaling Group (ASG) based node groups would be challenging to manage.
Instead, we leverage Karpenter to handle our cluster autoscaling needs. With Karpenter, we can simply deploy pods and let Karpenter provision instances to accommodate them. This approach respects CPU and memory requests, pod affinity, and topology spread, allowing our team to focus on the workload’s requirements rather than the specific instance types. Karpenter also helps us keep costs in check by “binpacking” workloads onto more cost-efficient instance types as needed, maximizing the use of our compute resources.
Leveraging StatefulSets for blockchain nodes
With cluster autoscaling managed by Karpenter, our next objective was to determine how to deploy stateful blockchain nodes in EKS. We use Kubernetes StatefulSets to manage our blockchain node pods.
When a new node is launched, the StatefulSet controller automatically provisions a PersistentVolumeClaim. We use the AWS EBS CSI driver to provision Amazon EBS volumes for most of our nodes. Using distinct StorageClasses allows us to fine-tune the EBS configuration based on the chain’s needs; many function well with conservatively provisioned gp3 volumes, while others may require higher IOPS and latency guarantees provided by io2 volumes.
In a few rare cases, certain chains demand even lower latencies than io2 can provide. For these cases, the requirement pushed our team to get creative. Fortunately, AWS offers EC2 instance types with locally attached NVMe storage. To leverage this, we use a custom startup script in our AMI to detect all locally attached NVMe block devices and combine them into a single striped LVM volume. This is a rare case where we are more hands-on with Karpenter, using affinity to select nodes of a particular instance family, such as i4i.
As instance storage is tied to the lifecycle of the EC2 instance, we built a custom tool to handle backing up and restoring node data. The tool runs as a non-terminating initContainer; upon startup, it checks if the local data directory is initialized, and if not, it downloads the most recent snapshot from an Amazon S3 bucket and restores it. When a pod is terminated, the tool creates an archive of the node’s data directory (leveraging XFS’s reflink feature for fast copy-on-write snapshotting) and syncs it to S3.
Customizing pod lifecycle with a CRD
With storage addressed, our next concern was determining how best to manage the lifecycle of the blockchain node pods themselves. We often run multiple nodes with varying configurations for a given blockchain, for example, running multiple execution clients like Geth and Reth, or nodes of different software versions for testing. Running pods with different specifications is not supported by a single Kubernetes StatefulSet resource, so we’ll typically run multiple single-replica StatefulSets supporting a particular chain and network. However, Kubernetes lacks native support for orchestrating the deployment of many StatefulSets in a way that is both automated and safe against unwanted disruptions.
To overcome this, we introduced a higher-level abstraction with a Custom Resource Definition (CRD) called the Nodeset. Each Nodeset represents a set of nodes for a given blockchain and network. An in-house operator, Blockchain Controller, watches for changes to StatefulSets and manages the pods’ lifecycles directly, effectively usurping some of the function of the StatefulSet controller (to achieve this, we configure our StatefulSets to use the OnDelete updateStrategy). The operator includes additional safeguards to ensure availability by monitoring the health of nodes and preventing an outage when a pod is terminated, such as using the Eviction API so that Pod Disruption Budgets are respected.
Ensuring node health with a custom monitor
Monitoring blockchain nodes presents a unique challenge. A simple TCP or HTTP probe can tell us if a node is ready to accept RPC traffic, but it doesn’t necessarily indicate if the node is up-to-date and consistent with the network.
To ensure clients receive timely and accurate information, we developed a custom health monitoring solution, Blockchain Monitor. This runs as a sidecar alongside the node software, continually verifying the local node’s state against trusted public RPCs. The monitor checks if the local node’s block height is within an acceptable tolerance, if block data is consistent, and if the node has sufficient peers to continue syncing reliably.
High-availability ingress
Networking and, in particular, ingress also pose non-trivial obstacles. We prefer to run our nodes in a high-availability (HA) configuration rather than load balancing RPC requests across all nodes for a given chain. This setup provides a “hot spare” that can be promoted if the active “leader” node becomes unhealthy. It also enables zero-downtime updates by applying changes to the standby node first.
To accomplish this, we again leverage the Nodeset CRD and Blockchain Controller. For each Nodeset, the operator provisions all necessary ingress resources: Services, EndpointSlices, and Gateway API HttpRoutes (or GRPCRoutes). Blockchain Controller tracks the active “leader” node in the CRD’s status and can react to changes, such as pod readiness, by switching to a healthy node and updating the EndpointSlice.
For ingress, we selected Traefik Proxy as our Gateway API controller. It has proven highly scalable, comfortably handling thousands of requests per second on just a few pods. Integrated metrics and tracing capabilities provide robust observability patterns, allowing us to see at a glance how our node fleet is performing.
We placed Traefik behind an AWS NLB managed by the AWS Load Balancer Controller. The choice of NLB wasn’t arbitrary; the NLB’s static IP address and support for AWS PrivateLink allow us to provide reliable RPC services wherever clients may be running. Within the cluster, we use Cilium CNI for its highly performant, eBPF-powered traffic management and policy enforcement.
Conclusion
Our journey to scale blockchain node infrastructure on AWS has shown that a modern, cloud-native approach is not just viable, but transformative. By using Amazon EKS and tools like Karpenter, we’ve built a platform that is resilient, performant, and cost-efficient, fundamentally changing how our team operates. The reduction in manual toil through automation has allowed us to shift our focus from day-to-day maintenance to innovation, enabling us to build new custom tooling and solve more complex challenges. This architecture is a testament to how the right combination of AWS services and open-source tools can empower teams and drive innovation.
To learn more about building resilient, scalable platforms, check out Amazon EKS and Circle’s developer documentation for integrating blockchain capabilities seamlessly.