AWS Storage Blog
Optimizing recommendations and analytics using Amazon DynamoDB and Amazon S3
Today, consumers navigate thousands of products on e-commerce sites, hundreds of shows on streaming platforms, and countless options in digital marketplaces. This choice overload creates decision fatigue, yet consumers continue to demand more variety and make more purchases online. As a result, personalization has become essential—consumers reward brands that deliver relevant, tailored online experiences. However, delivering personalization has traditionally required massive investments in complex technical architectures, sophisticated ML models, and extensive data pipelines. For gaming companies specifically, internal teams must analyze millions of player interactions, transaction patterns, and behavioral data to optimize these experiences—yet they often struggle with democratizing this data access, forcing teams to juggle multiple platforms for analytics, visualization, and enrichment.
Amazon Web Services (AWS) empowers organizations to deliver personalized experiences through integrated data solutions. AWS services such as Amazon S3, Amazon DynamoDB, Amazon Athena, Amazon EMR, AWS Glue, and Amazon Redshift break down data silos and build a unified platform for analytics and personalization. This integrated approach eliminates the need for complex architectures or constant human oversight, enabling businesses to deliver high-performing recommendation systems. By democratizing data access and reducing operational complexity, AWS empowers teams to meet rising consumer expectations for personalized experiences, which in turn drives higher engagement and conversion while minimizing cost.
In this post, we demonstrate how businesses can revolutionize both their internal data analysis capabilities and customer-facing personalization strategies using an integrated AWS solution. We demonstrate how teams can perform everything from complex SQL workloads to natural language data visualization from a unified console, eliminating the operational complexity that has traditionally burdened data teams. More importantly, we show how this streamlined infrastructure enables you to deliver highly effective recommendations and personalized experiences to your users while dramatically reducing costs and technical overhead. You can implement these solutions to transform both your user experience and business outcomes through data-driven personalization that maximizes engagement while minimizing complexity. Try out the demo for yourself using the GitHub repository.
Recommendation system demo
The following is a demonstration of a game recommendation system that showcases how we can achieve sophisticated personalization using AWS Data and AI services. For this demonstration, we generated a synthetic dataset containing 100,000 player records with 25 different fields, including gaming preferences, player demographics, and transaction history. This rich dataset helps us showcase both personalization capabilities and analytical workflows in a realistic scenario. Watch how it delivers personalized recommendations while needing minimal infrastructure setup:
As you can see in the preceding demo, this game recommendation application delivers personalized suggestions based on two key factors: a player’s gaming history and their favorite categories. When users access the platform, they receive targeted recommendations in two sections: ‘Because you have played more games in category X, we recommend games A, B, and C’ and ‘Because you like category Y, we suggest trying games D, E, and F.’ Their complete play history is also displayed at the bottom for reference.
We can peek behind the curtain to see how this works. Unlike traditional recommendation systems that rely on complex, expensive pipelines, this solution uses three powerful technologies working together: generative AI, databases, and vector embedding. Vector embeddings are particularly crucial here: they allow us to represent games and user preferences as mathematical entities that can be efficiently compared and matched. If you’re new to vectors, then think of them as a way to capture the contextual meaning of data in a format that machines can process to find similarities. For example, words like “dogs” and “puppies” are similar, and “love” and “like” are closely related; their corresponding vectors are numerically close. This proximity allows an AI system to recognize that the words are similar in meaning, hence enhancing the result of semantic or similarity searches. You can learn more about vector databases in our technical guide or explore the fundamentals in our What is a Vector Database? overview.
Building truly personalized recommendations necessitates more than just finding similar items, it demands understanding both what customers like and how they behave. The demo shows this by combining the embedding capabilities of Amazon Bedrock with Amazon S3 Vectors—a cost-optimized vector storage with native support to store and query vectors—and DynamoDB to create personalized recommendations tailored to each user.
Solution overview
Our recommendation system operates on a vector-based similarity matching architecture that combines user context with semantic search. Here’s how the backend logic flows:
The system initiates when a user request arrives, triggering a context-aware recommendation pipeline. DynamoDB serves as the source of truth for user behavioral data, providing the personalization context needed to generate targeted queries. These queries aren’t generic—they’re dynamically constructed based on the user’s gaming history and preferences.
The backend logic leverages Amazon Bedrock to transform these personalized queries into 128-dimensional vectors, enabling semantic understanding beyond keyword matching. These vectors are then compared against pre-computed game vectors stored in Amazon S3 using cosine similarity calculations.
The final stage applies user-specific filtering rules from their DynamoDB profile, ensuring recommendations respect their preferences and past interactions before delivering the personalized results.
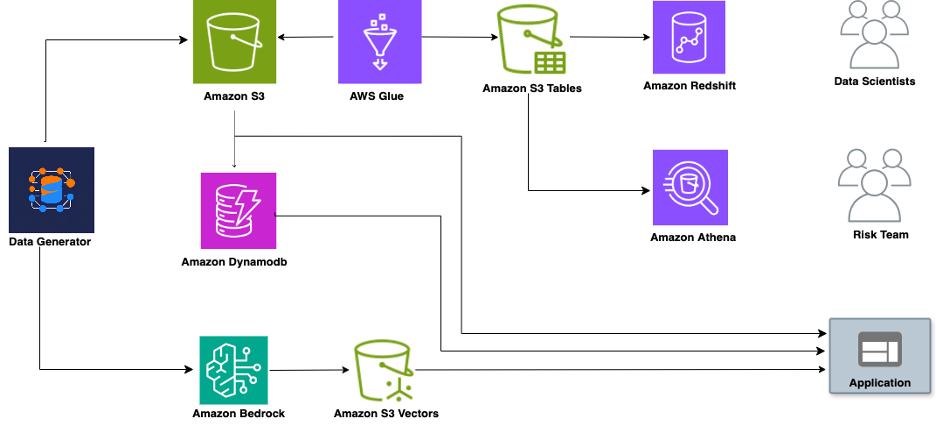
The embedding engine: The dual role of Amazon Bedrock
Amazon Bedrock serves as the intelligent foundation of our recommendation system, playing two critical roles in the vector pipeline. First, it transforms our comprehensive sports game dataset into searchable vectors using the Titan Embed Text v2 model, generating vector representations from game metadata such as names, categories, and attributes. Then, these are stored in S3 Vector indexes for efficient similarity search. Second, during live recommendations, Amazon Bedrock converts natural language queries into vectors using the same embedding model, enabling cosine similarity calculations against the stored game vectors in Amazon S3. This dual approach moves beyond keyword matching to understand deeper contextual relationships.
Adding personal context: Where DynamoDB transforms everything
DynamoDB serves as our system’s reliable data store, maintaining crucial user data such as gaming history, sport preferences, win/loss patterns, and playing habits. This stored information helps our application transform generic similarity matches into personally relevant recommendations.
The power lies in how our solution combines these services. When a user who plays 60% Football and 20% Basketball logs in, our application queries DynamoDB to retrieve their playing patterns and preferences. Using this data, it generates targeted search queries such as “Games similar to Football sports that are exciting and engaging” for their primary interest, “Games similar to Basketball sports that are exciting and engaging” for cross-sport discovery, and “Popular and trending sports games played in New York” for location-based recommendations.
Our application stores and quickly accesses user behavior data in DynamoDB to dynamically generate personalized vector queries rather than relying on generic recommendations. This combination of fast, reliable data access from DynamoDB and intelligent vector search is what enables our system to deliver truly personalized suggestions.
Bringing it all together: Personalized recommendations at scale
This integrated architecture demonstrates how modern recommendation systems solve the personalization puzzle. DynamoDB provides the “who”: understanding individual user contexts and preferences. And S3 Vectors delivers the “what”: finding semantically relevant games through intelligent similarity matching. The dynamic query generation makes sure that every vector search is contextually relevant: users who primarily play Football games get Football-focused recommendations, while Tennis games enthusiasts receive Tennis-specific suggestions. Instead of showing generic “popular games,” users see contextually meaningful suggestions such as games that match their preferred sport intensity, align with their skill progression, or introduce them to new categories based on their demonstrated interests. The system respects individual gaming journeys while creating appropriate discovery opportunities. The demo recommendation engine showcases how combining the scalable semantic search of S3 Vectors with the behavioral intelligence of DynamoDB and the natural language-to-vector conversion of Amazon Bedrock creates a personalization system that goes far beyond similarity matching: it delivers recommendations that truly understand and adapt to each user’s unique gaming preferences.As we’ve seen, modern gaming platforms generate rich datasets that extend far beyond simple play history. Every recommendation, transaction, win, and loss creates valuable data points. While recommendations drive engagement, transaction analysis ensures platform sustainability and player safety. This dual requirement—personalization and financial monitoring—makes unified data architecture essential for gaming platforms.
One dataset, many teams: The S3 Tables solution for data analysis
Our recommendation system generates valuable data that various teams need to access: from basic gaming preferences that power recommendations to detailed analytics about how users interact with these suggestions. Different teams need to consume this data in various ways – some through SQL query engines, others through BI dashboards, and some through custom data pipelines. Traditionally, this would mean replicating datasets across multiple systems, leading to increased storage costs and complex data synchronization challenges.
This is where S3 Tables with Apache Iceberg format comes in. Iceberg excels at serving multiple consumers from a single dataset, providing consistent views of the data regardless of how it’s accessed. S3 Tables build on these capabilities by streamlining table management and optimizing performance. In our solution, all player data flows directly into S3 tables, creating a single source of truth that teams can access through their preferred tools—whether that’s Athena for ad-hoc SQL analysis, Amazon Redshift for complex analytical queries, or Amazon EMR for large-scale data processing.
This unified approach brings value to our recommendation system. Product teams can analyze which suggestions lead to higher engagement, data scientists can tune recommendation algorithms based on user responses, and business analysts can track the impact on player retention. And all of this is working from the same underlying dataset without data duplication or complex ETL processes. Teams can maintain both user data and recommendation results in one place to continuously improve the quality and effectiveness of the personalization system.
Modern gaming platforms are sophisticated digital economies where players make real-money transactions for in-game purchases, virtual currency, and fantasy sports. Our synthetic dataset of 100,000 players includes transaction history fields precisely because recommendation systems must work alongside financial monitoring to ensure both engagement and platform integrity.
In our demo, we are using Amazon SageMaker Unified Studio to run queries on S3 tables. It provides a comprehensive data and AI development environment that brings together the functionality and tools from existing AWS Analytics and AI/ML services—including Amazon EMR, AWS Glue, Amazon Athena, Amazon Redshift, Amazon Bedrock, and Amazon SageMaker AI—to make it easier for users to build, query, and analyze data in one place.
For gaming platforms, different teams need different insights from the same player data:
- Player Safety teams analyze transaction patterns through Athena to identify unusual betting behaviors or suspicious in-game purchases.
- Revenue teams use Amazon Redshift to understand player spending patterns and optimize pricing strategies.
- Product teams correlate financial engagement with game recommendations to maximize both player satisfaction and platform revenue.
We’ve ingested the Apache Parquet data through AWS Glue jobs into S3 tables using Iceberg format to create a unified data layer that supports comprehensive analytical workloads (necessitating full attribute access across millions of records). This setup allows seamless querying with popular engines such as Amazon Redshift, Athena, Amazon EMR, and Apache Spark through SageMaker Unified Studio. Being a fully managed service, S3 Tables offer greater operational efficiency by reducing the complexity and overhead typically involved in managing table storage. For example, compaction, expiring old snapshots or removing unreferenced files to automatically optimize query efficiency and costs over time.
Analyzing player behavior for game recommendations in SageMaker Unified Studio
Understanding player financial behavior—such as deposit patterns for in-game purchases or fantasy gaming—helps identify engaged users who deserve tailored experiences. These analytics not only improve recommendation quality but also ensure safe gaming practices. By analyzing transaction patterns and regional preferences directly within SageMaker Unified Studio, teams can build more effective recommendation systems without switching between multiple tools.
As an example of how SageMaker Unified Studio empowers gaming platforms with unified analytics, let’s explore how to analyze player behaviors that drive better recommendations. In this walkthrough, we’ll demonstrate how gaming platforms can leverage SageMaker Unified Studio to uncover player insights from S3 Tables using both Amazon Redshift and Amazon Athena.
Analyzing player transaction patterns in gaming through Amazon Athena
Step 1: Access Athena in SageMaker Unified Studio.
- Open SageMaker Unified Studio and locate the compute option on the far right side of the interface.
- Under Connections, choose Athena (Lakehouse).
- Choose the relevant database: s3atablecatalog/{s3_table_bucket_name}.
- Under Databases, choose your namespace.
- Select Choose to connect.
Step 2: Run the financial analysis query.
Run the following SQL query to analyses how players interact with the gaming economy through deposits, winnings, and losses from competitive gaming:
SELECT
user_id,
SUM(deposit_amount) as total_deposits,
SUM(amount_won) as total_winnings,
SUM(amount_lost) as total_losses,
COUNT(*) as total_games
FROM "s3tablescatalog/<your-table-bucket>"."<namespace_name>"."<table_name>"
GROUP BY user_id
ORDER BY total_deposits DESC;
AVG(deposit_amount) as avg_deposit,
MAX(deposit_amount) as highest_deposit,
SUM(CASE WHEN deposit_amount > 100 THEN 1 ELSE 0 END) as high_value_games,
SUM(CASE WHEN game_result = 'won' THEN 1 ELSE 0 END) as games_won,
ROUND(SUM(amount_won) - SUM(amount_lost), 2) as net_profit_loss
FROM "s3tablescatalog/<your-table-bucket>"."<namespace_name>"."<table_name>"
GROUP BY user_id
HAVING total_deposits > 50
ORDER BY total_deposits DESC
LIMIT 50;This query identifies your top 50 players by deposit amount, showing their total deposits, winnings, losses, and risk metrics.
Gaming engagement varies significantly by region, with different locations showing distinct patterns in competitive gaming success rates. Understanding these regional differences helps platforms tailor both game recommendations and competitive matchmaking.
Regional analysis with Amazon Redshift, where we find players from each location who won more games than they lost
Step 1: Connect to Redshift in SageMaker Unified Studio.
- In SageMaker Unified Studio, choose the compute option on the far right side.
- Under Connections, choose Redshift.
- Choose the relevant database: {s3_table_bucket_name}@s3atablecatalog.
- Under Schemas, choose your namespace.
- Select Choose to connect.
Step 2: Run the Regional player analysis.
Run the following query to identify locations with successful players:
SELECT
location,
COUNT(DISTINCT user_id) as users_with_more_wins
FROM (
SELECT
user_id,
location,
SUM(CASE WHEN game_result = 'won' THEN 1 ELSE 0 END) as wins,
SUM(CASE WHEN game_result = 'lost' THEN 1 ELSE 0 END) as losses
FROM "<namespace_name>"."<table_name>"
GROUP BY user_id, location
HAVING wins > losses
) winning_users
GROUP BY location
ORDER BY users_with_more_wins DESC;This query identifies regions with successful competitive gamers, helping the platform optimize matchmaking algorithms and recommend appropriate difficulty levels for players in different locations.
To view your table in Data Explorer:
Navigate to Lakehouse → s3tablescatalog → {your-table-bucket} → {namespace_name} → {table}.
Amazon QuickSight integration with S3 Tables: Perform data analysis through natural language
Amazon QuickSight can directly analyze data stored in S3 Tables, which has transformed how organizations derive insights from their data lakes. You can establish a seamless connection between S3Tables and QuickSight to visualize massive datasets without complex ETL processes or data movement. The QuickSight SPICE engine provides lightning-fast query performance even with billions of rows of data.
As part of Amazon Quick Suite (AWS’s agentic AI workspace combining analytics, research, and automation), QuickSight now benefits from deeper integration with AI agents and workflow capabilities. One of its standout features is the Amazon Q natural language querying capability, which allows you to create visualizations through conversational commands. Instead of manually configuring charts and graphs, you can type requests such as, “Show me top 10 user ID who have won the most in category as Volleyball,” or “top 10 category played in 2024,” and QuickSight (via Quick Suite) generates the appropriate visualization. This AI-powered feature democratizes data analysis so that business users without technical expertise can explore data and build compelling visuals through intuitive, natural language interactions.
Ready to transform your Amazon S3 data into actionable insights? Try the natural language visualization capabilities of QuickSight today, and experience firsthand how conversational analytics can revolutionize your data exploration journey. Your next data breakthrough might be just a question away.
Conclusion
This post presents a practical demonstration of building modern recommendation and analytics systems using the latest capabilities of Amazon DynamoDB and Amazon S3. Through a game recommendation application, we demonstrated how the contextual user data of DynamoDB combines with the semantic search of S3 Vectors to deliver intelligent personalization without traditional machine learning (ML) pipeline complexity. The solution showcases dynamic query generation where user behavioral patterns stored in DynamoDB drive targeted vector searches in Amazon S3, creating recommendations that understand individual gaming preferences and discovery patterns. We also explored how multiple analytics teams can use S3 Tables with the Iceberg format—from risk to finance to product development—to access unified datasets through their preferred compute engines without data duplication. Furthermore, we covered how QuickSight can be used to visualize the data and use natural language to perform analytics. The architectural approach demonstrates how AWS managed services transform both recommendation delivery and enterprise analytics, making sophisticated data-driven applications accessible through streamlined infrastructure patterns.
If you’re looking to consider the Amazon S3 features that you’ve seen here, or want to have a chat about the architecture, then get in touch with your Technical Account Manager or your Solutions Architect to discuss a solution specific to your use-case. You can also reach out to AWS Support by creating a case if you’re facing an issue setting up any of the service listed in this post.