AWS Storage Blog
Implementing conversational AI for S3 Tables using Model Context Protocol (MCP)
In today’s data-driven world, the ability to interact with your data through natural language is becoming increasingly valuable. By combining the power of conversational AI with Amazon S3 Tables, organizations can democratize data access and enable individuals across technical skill levels to query, analyze, and gain insights from their data using simple conversations.
Model Context Protocol (MCP) represents a transformative advancement in the agentic AI ecosystem, offering a standardized way for AI applications to access and utilize contextual information. An MCP server is a lightweight program that exposes specific capabilities through the standardized Model Context Protocol. Host applications (such as chatbots, IDEs, and other AI tools) have MCP clients that maintain a 1:1 connection with MCP servers. MCP servers can access local data sources and remote services to provide additional context that improves the output generated from models. Common MCP clients include agentic AI coding assistants such as Amazon Q Developer, Cline, Cursor, or Claude Code, as well as chatbot applications like Claude Desktop, with more clients coming soon.
Now with MCP Server for Amazon S3 Tables, your AI applications and data lake users can interact with tabular datasets using natural language interfaces without needing to write SQL queries. Amazon S3 Tables deliver the first cloud object store with built-in Apache Iceberg support and the easiest way to store, query, and manage your tabular data at scale. The MCP Server for S3 Tables has tools that use Daft, a distributed query engine natively integrated with PyIceberg, that your AI assistant can use to read managed Iceberg tables in S3 Tables.
This blog will guide you through implementing a conversational AI solution that uses the S3 Tables MCP Server to interact with your structured data in Amazon S3. With the MCP Server, you can easily experiment and accelerate your projects by giving your AI assistants access to frameworks that help them correctly interact with your data in Amazon S3 Tables. Developers and data engineers can now use natural language to handle table creation, schema definition, data import/export, query operations, and more.
Use cases and solution overview
The MCP Server for S3 Tables provides a standardized way for AI assistants to interact with your S3 Tables data. It has capabilities such as:
- Creating and managing table buckets and namespaces
- Defining and modifying table schema
- Importing data from various sources
- Querying data using SQL
- Appending and updating records
Here is a simplified process flow diagram depicting how the interactions happen behind the scenes from the time when you initiate a query using natural language prompts to when you get a response back from S3 Tables. The whole process completes in seconds providing you a quick way to interface with S3 Tables without needing SQL statements or manually issuing any API calls.
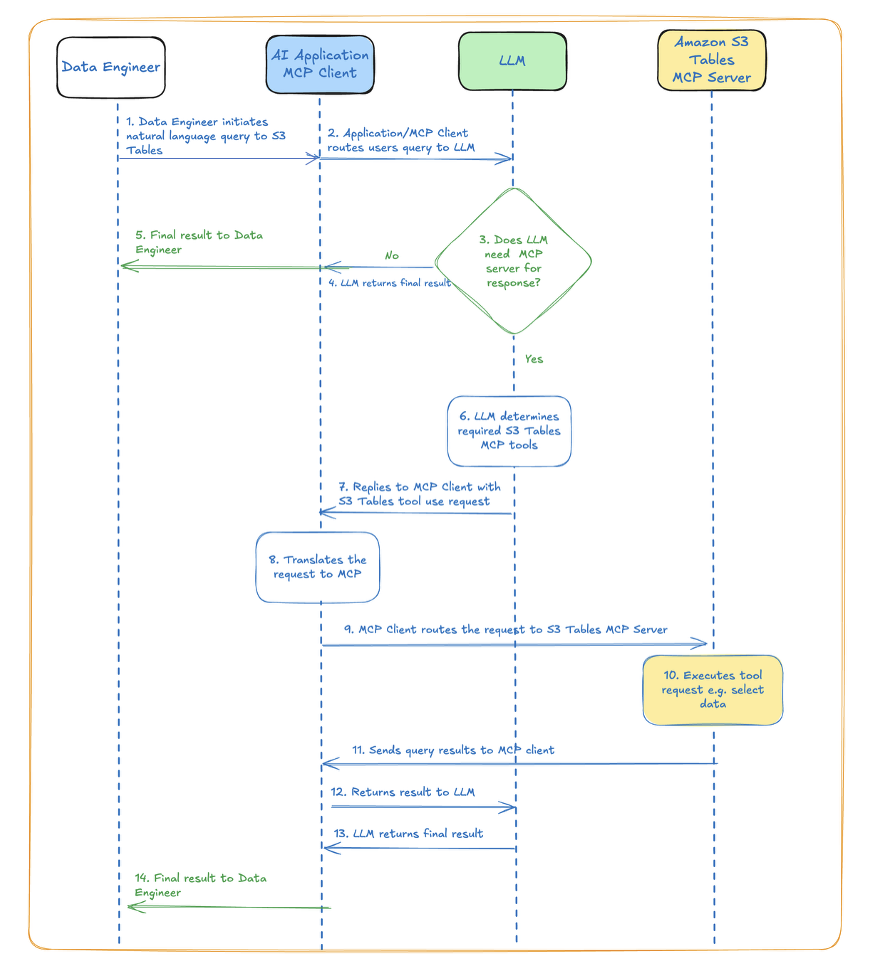
In this blog, we use Cline as an AI coding assistant to walk through setting up the MCP Sever for S3 Tables step by step, from configuring the AWS environment to implementing the conversational interface in Cline. To demonstrate the MCP Server’s capabilities using conversational AI, we will show you how to create, append, and query S3 Tables.
The AI assistant will have the tools to perform the following S3 Tables related work using natural language, including:
- List S3 table buckets, namespaces, and tables
- Create new S3 table buckets, namespaces, and tables, and append data to tables
- Import data from a CSV file into an S3 table. This tool reads data from a CSV file stored in S3
- Query and get insights from S3 Tables
- Get details about the maintenance configuration and status for a table
- Read the latest metadata of an S3 Table
- Rename an S3 table or move it to a different S3 namespace
- Commit data to an S3 Table
- Derive the table schema from an existing file in a general-purpose S3 buckets
Prerequisites
You must set up the appropriate IAM roles and permissions as well as handle delete and table maintenance operations separately, as these tasks are not exposed through the MCP Server for S3 Tables interface. You can use the AWS CLI, or use infrastructure-as-code tools like AWS CloudFormation or Terraform, or AWS Management Console to manage the complete S3 Tables infrastructure.

For the purposes of getting started with the MCP Server for S3 Tables, we set up these prerequisites:
- An AWS account
- Install AWS Command Line Interface (AWS CLI) and set up credentials
- Install prerequisites and setup as per awslabs 3-tables-mcp-server readme
- Set up model access to Claude Sonnet 4 Model. Please note the MCP tool is not constrained to use Amazon Bedrock or this model. You may use the Amazon Bedrock foundation models or choose a different model as per your needs.
- For the purposes of this blog, we have an example data engineer persona as a user. To simulate and follow through the steps illustrated in this demo, you can create a similar user and attach this S3Tables IAM policy to the IAM role you use. This policy provides explicit permissions to create, append, and query S3 Tables and explicitly denies any delete operations. Please note that whenever you use IAM policies, make sure that you follow IAM best practices. For more information, see Security best practices in IAM in the IAM User Guide.
- Configure access to AWS environment from Cline AI as per prerequisites
- Access settings
a. Click the gear icon in the top-right corner of the Cline interface
b. This will open the settings menu - Select API provider
a. From the provider options, select “Amazon Bedrock” - Configure authentication
a. Choose one of the following authentication methods:
– AWS Credentials (Access Key ID and Secret Access Key)
– AWS Profile (if you have configured profiles locally)
Make sure that your chosen authentication method has the necessary Amazon Bedrock access permissions - Model selection
a. Choose your preferred language model from the available options
b. Click “Save” to confirm your selection - Optional advanced configuration
a. Enable/disable extended thinking mode
b. Use Prompt VPC endpoint
c. Use cross-origin inference
d. Use prompt caching
- Access settings
- To follow along with this demo, you may download the sample csv files from the following links into your S3 bucket as sample data to be imported into S3 Tables.
End-to-End Demo Workflow
In this section, we will execute natural language prompts to interact with Iceberg tables managed by S3 Tables. Remember, you must complete the setup and prerequisite steps to configure your AI Assistant to work. Below is a sample mcp_config.json file. Please change the directory, profile, and region as per your own configuration. Note that the S3 Tables MCP Server runs over “stdio” mode as shown in the below mcp_config.json.
{
"mcpServers": {
"awslabs.s3-tables-mcp-server": {
"command": "uvx",
"args": ["awslabs.s3-tables-mcp-server@latest", "--allow-write"],
"env": {
"AWS_PROFILE": "<Your AWS Profile>",
"AWS_REGION": "<Your AWS Region>"
}
}
}
}Once setup is completed and the MCP Server is installed in Cline, you can review its configuration and tools as follows:
Now let’s start with the demo. In the Cline chat, as the data engineer, we start using natural language prompts to ask the AI assistant to perform tasks. As the AI assistant executes these commands, you should review and approve the AI assistant’s operations before it executes the tasks.
In the following steps, we will use natural language prompts to create an S3 Tables bucket, namespace, and two tables containing daily sales data for the years 2024 and 2025. We will import CSV data as tables into the namespace we created. Then we will analyze those tables to determine the highest revenue-generating product under product_category for the years 2024 and 2025 based on the daily sales as defined by sales_amount.
Prompt: Create a new table bucket called ABC_Revenue with namespace daily_sales and import the two table names daily_sales_2024.csv and daily_sales_2025.csv in the namespace daily_sales.
The following intermediate steps are then generated by the AI assistant Cline as it executes the task as required by the prompt.

The data engineer approves the create_table_bucket action, and the AI assistant proceeds with creating the table bucket.

The operation is successful, and the abc_revenue S3 table bucket has now been created. The AI assistant wants to create a namespace next.

The data engineer approves this operation, and the AI assistant proceeds with the namespace creation.

The operation is successful, and the daily_sales namespace has now been created associated with the S3 table bucket abc-revenue.

Now the AI assistant proceeds to review the two CSV files: daily_sales_2024.csv and daily_sales_2025.csv to create these tables in table bucket abc_revenue in the namespace daily_sales.

The AI assistant reviews the CSV file and its schema and creates the schema for daily_sales_2024 S3 table.

The data engineer approves these actions, and the AI assistant proceeds with the create table operation. The operation is successful, and the daily_sales_2024 and daily_sales_2025 tables are created. Now the AI assistant proceeds to use import_csv_to_table MCP Server tool to import CSV data from an S3 general purpose bucket to S3 Table bucket abc_revenue in the daily_sales namespace.

The import operation is successful. Then, the AI assistant is going to import the 2025 data.

All tasks from the first prompt have now been completed without any manual intervention from the data engineer except for approvals on the tasks to perform the operations required. The model using the MCP Server-used tools such as create_table_bucket, create_table_namespace, create_table, and import_csv_to_table to perfom all tasks required to execute this prompt successfully. Summary of the tasks performed are as below:

Next, the data engineer wants to gather insights from this data and proceeds with the next prompt.
Prompt: Give me the highest revenue generator in 2024 and 2025 based on daily_sales in a single query.

The AI assistant uses the query_database tool from the MCP Server which uses PyIceberg/Daft to query the S3 Tables:
{
"warehouse": "arn:aws:s3tables:us-east-1:<your-account-no>:bucket/abc-revenue",
"region": "us-east-1",
"namespace": "daily_sales",
"query": "WITH combined_data AS (SELECT '2024' as year, product_category, SUM(sales_amount) as total_revenue FROM daily_sales_2024 GROUP BY product_category UNION ALL SELECT '2025' as year, product_category, SUM(sales_amount) as total_revenue FROM daily_sales_2025 GROUP BY product_category), ranked_data AS (SELECT year, product_category, total_revenue, ROW_NUMBER() OVER (PARTITION BY year ORDER BY total_revenue DESC) as rank FROM combined_data) SELECT year, product_category, total_revenue FROM ranked_data WHERE rank = 1 ORDER BY year",
"uri": "https://s3tables.us-east-1.amazonaws.com/iceberg",
"catalog_name": "s3tablescatalog",
"rest_signing_name": "s3tables",
"rest_sigv4_enabled": "true"
}

The AI assistant successfully provides insights that “Electronics” was the highest revenue generating product_category in both 2024 and 2025. The second prompt is successfully executed.
Next, the data engineer has new data from the second half of both years and wants to append the data to the existing tables.
Prompt: Import daily_sales_2024_additional.csv to daily_sales_2024 table and daily_sales_2025_additional.csv to daily_sales_2025 S3 table.

The operation for importing additional data is successful.

The AI assistant successfully imports additional data by appending them in the S3 Tables. Both tables have full year coverage and are ready for further revenue analysis.

In only three prompts to the AI Assistant, this demo shows that the data engineer was able to create table bucket and namespace as well as import the structured data from S3 general purpose bucket to S3 Tables. The data engineer was also able to gain insights from the tables by querying them and finally manage importing additional data by appending them to the same tables. You can now start using your AI assistant with the MCP Server for Amazon S3 Tables, to safely create, populate, and query S3 Tables using natural language. The MCP Server for S3 Tables has a limited set of tools. If you wish to run other operations not supported by the MCP Server, we recommend you use the AWS CLI or SDK for S3 Tables. Even though, this example was in Cline, we found the experience to be similar in Amazon Q Developer CLI and Claude desktop.
Logging and traceability
With S3 Tables MCP Server, you will have three ways to audit your operations on your S3 Tables. First, this will be available locally by default or you can provide a directory path via your MCP Sever log using the “–log-dir” MCP configuration. This local log file logs your request to the MCP Server with configuration arguments, the response and error events. Second, you can use CloudTrail data events to get information about your bucket and table-level requests made via your AI assistant using the S3 Tables MCP Server. All S3 Tables operations via the MCP Server using PyIceberg will have “awslabs/mcp/s3-tables-mcp-server/<version#>” as the user agent string. You can filter your logs by this user agent string to trace back actions performed by the AI assistant. Finally, AI client software, such as Cline, which provide MCP Server support also provide “history” data that records the natural language requests and responses from LLM, and the instructions the LLM provided to the MCP Server over a certain period. You can archive the history information to trace back and audit the operations performed through the MCP Server.
Cleanup
To clean up the resources used for this experimentation, you will need to assume the admin role or work with your S3 Tables administrator to do the following:
- Delete the sample S3 table bucket and all the resources it contains including namespace and table
- Remove access from the foundation model used in this experiment from Amazon Bedrock
- Cleanup the data engineer IAM Roles and policies
Conclusion
In this post, we demonstrated a simple yet powerful use case for using the MCP Server for S3 Tables to interact with your Apache Iceberg S3 Tables. Now, you use the MCP Server with S3 Tables to simplify access to your Iceberg data lakes. It enables you to use your data assets more effectively, reducing the technical barriers to query and analyze your data. Security and compliance are always paramount. We recommend you use least privileged access and provide strong data security parameters via access control policies for AI assistants when they interact with your data in Amazon S3. As the landscape of AI and data analytics continues to evolve, solutions like MCP Server for S3 Tables will play a crucial role in helping organizations harness the full potential of their data.
To learn more about Amazon S3 Tables, Amazon Bedrock, and MCP architecture, please visit: