AWS Storage Blog
How to size an Amazon FSx for NetApp ONTAP file system
Understanding Amazon FSx for NetApp ONTAP
Transitioning your business systems and data to the cloud can seem complex, especially if you are new to cloud file storage services. Whether you are moving from traditional on-premises enterprise storage or just getting started in the cloud, sizing your storage correctly is key to avoiding future issues. The right approach enables you to move your files to the cloud even if the cloud is new territory for you and your team.
AWS offers storage solutions such as Amazon FSx for NetApp ONTAP, which provides fully managed shared storage in the AWS Cloud with the popular data access and management capabilities of ONTAP. Native features such as deduplication, compression, and tiering mean that FSx for ONTAP enables you to optimize storage efficiency and costs as data scales. Starting with the right sized FSx for ONTAP file system based on your workload’s needs allows you to maximize built-in data optimization to minimize the necessary capacity and cost. The flexibility and elasticity of FSx for ONTAP allows your storage to adjust with your workload over time, avoiding manual management. Proper planning and use of AWS file services allow you to smoothly and cost-effectively transition file storage to the cloud.
In this post, we walk through how to determine the right storage capacity when moving to cloud storage with FSx for ONTAP. This shrinks your overall storage footprint, saving substantial costs as data grows. The savings apply across use cases such as file shares, repositories, backups, and analytics. Seamless tiering allows easy scaling on-demand. Furthermore, FSx for ONTAP data efficiency capabilities enable you to supercharge your storage, confidently retaining information ready for use. Moreover, you can scale for capacity with FSx for ONTAP , as well as size for throughput by finding baseline metrics, project growth, use compression/deduplication, and scale performance to meet demands cost-effectively. We provide sizing best practices to maximize the value of your data as needs evolve. You can still scale your file system later if you need to make changes, offering flexibility as your requirements change. However, while you can increase storage capacity, you cannot shrink the solid-state drive (SSD) storage when it’s provisioned.
Data efficiencies
FSx for ONTAP provides the ability to tier data between two storage classes: a high-performance SSD tier and a lower-cost fully-elastic Capacity Pool tier. FSx for ONTAP tiering enables seamlessly moving infrequently accessed data from the SSD tier to the more cost-effective Capacity Pool tier automatically based on defined policies. The key benefit is optimized storage costs by tiering colder data to cheaper Capacity Pool storage, while retaining hot active data on high-performance SSDs.
FSx for ONTAP offers sub-millisecond file operation latencies with SSD storage and tens of milliseconds of latency for Capacity Pool storage. It also has two layers of read caching on each file server—non-volatile memory express (NVMe) drives and in-memory—to provide even lower latencies when accessing frequently-read data. For more information on these specifications, refer to this Amazon FSx documentation.
Thin provisioning
All volumes are by default thin provisioned, meaning they consume storage capacity only for the data stored, making them cost efficient. End users see the capacity that they requested while the filesystem only reports the data consumed.
Deduplication, compression, and compaction
Deduplication eliminates redundant data by replacing duplicates with references, which significantly reduces storage needs. Compression is the process of reducing the size of data by encoding it using fewer bits than the original representation. Combined, deduplication and compression provide major data reduction, which improves storage efficiency. FSx for ONTAP brings efficiency to users by eliminating redundant information, keeping capacity needs low, thus keeping costs low. ONTAP uses a 4 KB data block size. However, some applications perform small writes that may not fully use the entire data block. To optimize storage usage, compaction packs multiple compressed and deduplicated data chunks into a single storage block, further making sure of efficient use of the underlying storage. This results in reduced raw storage requirements, translating to lower storage costs.
Example: storage efficiencies
Figure 1: shows how storage efficiencies are applied to data.
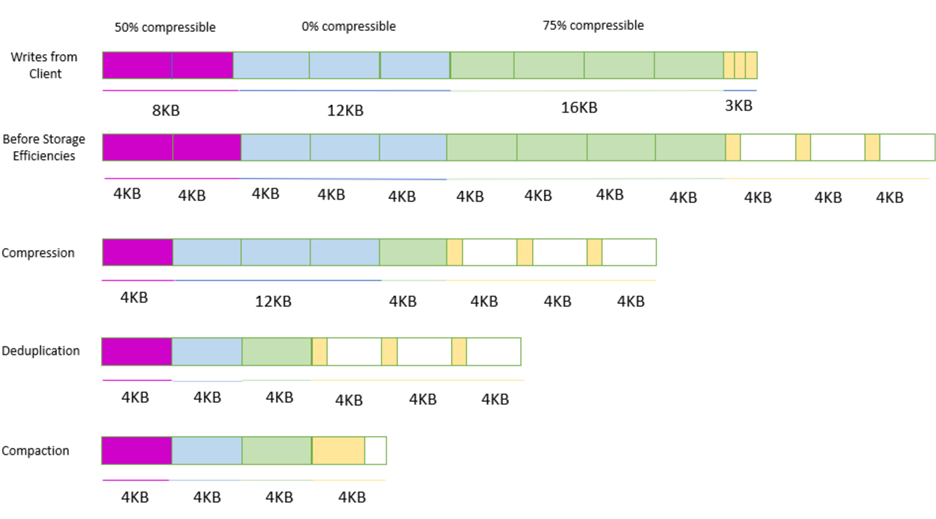
Figure 1: Storage efficiencies graph
The preceding graph breaks down the workflow of compression, deduplication, and compaction step by step. First, data is represented as different block sizes as sent by the client to the FSx for ONTAP volume. Depending on the source of the data, block size could be different depending on the originating write. The second step shows how data would land within the FSx for ONTAP volume, having changed the block size to 4 KB for all received data. The third step shows the effects of compression by reducing the space used within the 4 KB block, leaving empty space on each 4 KB block. The fourth step applies deduplication by identifying and eliminating redundant 4 KB blocks, thus replacing duplicates with references to a single copy of the data. The final step has compaction applied by efficiently using all of the empty space to combine as much compressed and deduplicated data as possible within the blocks to release the now empty 4 KB blocks. All of these storage efficiency processes occur inline before the data is written to SSD storage.
Tiering
When migrating data to FSx for ONTAP, users must analyze the ratio of cold (infrequently accessed) and hot (frequently accessed) data in their existing on-premises environment. To plan for tiering, users should identify their hot and cold data ratios by doing the following:
- Analyzing file access logs and storage analytics tools to determine frequently (hot) and infrequently (cold) accessed files.
- Manually inspecting file metadata like last access times.
- Gathering input from application owners and users on data access patterns.
- Setting up pilot FSx for ONTAP deployments to monitor access patterns.
Regularly reviewing these data access patterns allows users to accurately size the SSD tier for their FSx for ONTAP file systems, thereby optimizing for performance and cost.
Tiering happens transparently in the background according to the tiering policies that you set manually on volumes. There are four options for volume tiering:
- Auto: This policy moves all cold data—user data and snapshots—to the Capacity Pool tier. The cooling rate of data is determined by the policy’s cooling period, which by default is 31 days, and is configurable to values between 2–183 days. When the underlying cold data blocks are read randomly (as in typical file access), they are made hot and written to the primary storage tier. When cold data blocks are read sequentially (for example, by an antivirus scan), they remain cold and remain on the Capacity Pool storage tier.
- Snapshot only: This policy moves only snapshot data to the Capacity Pool storage tier. The rate at which snapshots are tiered to the Capacity Pool is determined by the policy’s cooling period, which by default is set to two days, and is configurable to values between 2–183 days. When cold snapshot data are read, they are made hot and written to the primary storage tier. This is the default policy when creating a volume.
- All: This policy forces all writes to tier immediately to the Capacity Pool. When data blocks are read, they remain cold and are not written to the primary storage tier. When data is written to a volume with the All tiering policy, it is still initially written to the SSD storage tier, and is tiered to the Capacity Pool by a background process. The file metadata always remains on the SSD tier.
- None: This policy keeps all of your volume’s data on the primary storage tier, and prevents it from being moved to the Capacity Pool storage. If you set a volume to this policy after it used any other policy, then the existing data in the volume that was in Capacity Pool storage is moved to SSD storage by a background process as long as your SSD usage is less than 90%. This background process can be sped up by intentionally reading data or by modifying your volume’s cloud retrieval policy. For more information, see the cloud retrieval policies.
When determining the necessary SSD storage capacity for metadata associated with the files planned for storage on the Capacity Pool tier, you should adopt a conservative approach. A recommended ratio is to allocate 1 GiB of SSD storage for every 10 GiB of data intended for the Capacity Pool tier. If you are not familiar with your usage pattern, then you should start with the “Snapshot only” option.
Throughput
FSx for ONTAP allows you to configure the desired throughput capacity when provisioning your file system. You have the flexibility to modify this throughput capacity at any time based on your workload needs. However, to achieve the maximum specified throughput, your file system configuration must meet certain requirements.
Users are billed for the provisioned throughput capacity. Therefore, you should carefully assess performance needs and find the optimal balance between performance and cost. Over-provisioning can lead to unnecessary expenses, while under-provisioning may result in performance bottlenecks.
Users should monitor their workload performance and adjust total capacity as needed to make sure that they’re getting the performance they need without overpaying for unused capacity. AWS provides tools such as Amazon CloudWatch to help monitor and optimize these settings.
Use cases
Here are some common workload types that can benefit from the data efficiency capabilities of FSx for ONTAP:
- File shares: Corporate file shares such as home directories and shared team drives contain lots of redundant documents and files. FSx for ONTAP deduplication saves significant storage space.
- Backups: Backup data contains a lot of redundancy across versions that can be deduplicated. FSx for ONTAP makes retention of backups more efficient.
- Source code repositories: Software repositories have duplicative code across versions and branches. FSx for ONTAP reduces the repo storage footprint.
- Media archives: Media libraries with video footage, images, and audio have high visual and signal redundancy. FSx for ONTAP compression reduces media archive sizes.
- Electronic design automation: Design files for semiconductors and electronics have duplicate blocks. FSx for ONTAP deduplicates these redundant design components.
- Big data analytics: Raw data ingested for analytics creates duplicates during ETL preprocessing. FSx for ONTAP saves space before loading into HDFS.
- Genomics research: Genomic sequencers generate datasets with duplicative DNA data. FSx for ONTAP makes retention of these large research datasets more affordable.
The FSx for ONTAP data reduction capabilities enables these diverse workloads to optimize storage efficiency and reduce costs as data volumes grow. The following table gives estimates on data efficiencies that FSx for ONTAP can achieve.
| Type of workload | Compression only | Deduplication only | Compression + deduplication |
| General-purpose file shares (home directories) | 50% | 30% | 65% |
| Virtual machines and desktops | 55% | 70% | 70% |
| Databases | 65-70% | 0% | 65-70% |
| Engineering data (EDA type workloads) | 55% | 30% | 75% |
Assessing your workload
Before you can size your FSx for ONTAP file system, you must understand the characteristics of your on-premises workload. This includes gathering information about the following:
- Data volume: Determine the total amount of data that you need to store, such as both active and inactive data.
- Performance requirements: Assess the expected throughput, Input/Output – Operations per Second (IOPS), and latency requirements for your workload.
- FSx for ONTAP provides sub-millisecond file operation latencies with SSD storage, and tens of milliseconds of latency for Capacity Pool storage.
- Growth patterns: Analyze the historical growth patterns of your data to estimate future storage and performance needs.
- Access patterns: Understand how your users and applications interact with the data, such as the frequency of read and write operations.
Step 1: Determine the storage capacity
Start by estimating the total storage capacity needed for your workload. This includes not only the current data volume but also any anticipated growth over the lifetime of your file system. Remember to factor in more space for metadata, snapshots, and other file system overhead.
Step 2: Choose the appropriate file system configuration
FSx for ONTAP offers various file system configurations, each with its own set of storage and performance capabilities. Based on your workload requirements, choose the configuration that best fits your needs. This may include considerations such as storage throughput, IOPS, and the number of storage volumes.
FSx for ONTAP file systems provide high availability and durability across AWS Availability Zones (AZs). Multi-AZ file systems have two file servers in separate AZs, while Single-AZ file systems have one or more file server pairs in the same AZ. Data is automatically replicated across file servers for redundancy. FSx for ONTAP continuously monitors for failures and automatically replaces components, with failover and failback typically within 60 seconds, ensuring continuous data availability
When choosing between FSx for ONTAP scale-up and scale-out systems, consider your workload requirements. Scale-up systems, with a single high availability pair offering up to 6 GB/s throughput and 200,000 IOPS, are ideal for most standard workloads such as general file sharing and content management. For more demanding, compute-intensive ONTAP workloads such as large-scale electronic design automation, seismic analysis, clustered databases, or high-performance computing applications, opt for scale-out systems. Both options allow seamless migration of ONTAP workloads to AWS without modifying existing applications, tools, or workflows. Choose scale-out when you need performance beyond what a single high availability pair can provide, enabling you to use the ONTAP data management features for an even broader range of high-performance use cases in AWS.
Step 3: Evaluate storage and performance options
FSx for ONTAP provides a range of storage and performance options to choose from. These include different storage types, storage capacity, and throughput/IOPS settings. Carefully evaluate these options to make sure that your file system can deliver the needed performance for your workload.
Step 4: Plan for scalability
One of the benefits of FSx for ONTAP is its ability to scale up as your needs change. Anticipate future growth and plan for the ability to easily expand your file system’s storage capacity and performance as needed.
Step 5: Optimize for cost-effectiveness
While making sure that your file system meets your workload requirements, also consider the cost implications. FSx for ONTAP offers various pricing options, such as on-demand deployment that can help you optimize your costs based on your usage patterns.FSx for ONTAP offers a flexible, pay-as-you-go pricing model with no minimum fees or set-up charges. Although prices are quoted monthly, you’re billed based on your average hourly usage over the month, making sure that you only pay for what you actually use. The service’s pricing structure is composed of six key components: SSD storage, SSD IOPS, Capacity Pool usage, throughput capacity, backups, and SnapLock licensing. These elements allow you to tailor your storage solution to your specific needs, balancing performance, capacity, and cost. Considering these components carefully allows you to optimize your FSx for ONTAP deployment to achieve the best balance of performance and cost-efficiency for your workloads.
Step 6: Test and validate
Before deploying your FSx for ONTAP file system in production, conduct thorough testing and validation to make sure that it meets your performance and data protection requirements. This may involve running benchmark tests, validating data integrity, and monitoring the system’s behavior under various workloads.
Migration
When analyzing the needed capacity of the FSx for ONTAP, consider how much data is cold as opposed to hot. Most users, when analyzing their data, learn that they have a ratio such as 80/20—80% cold and 20% hot. Knowing this allows you to set the size of the SSD tier when you deploy the filesystem. To determine if a user’s data is hot or cold, the key factors to consider are how frequently the data needs to be accessed and the criticality of low-latency access. Hot data refers to datasets that must be immediately available with minimal latency, such as real-time transaction data or telemetry streams. This type of data typically needs to be stored on high-performance storage media such as SSDs. In contrast, cold data encompasses historical or archival data that is infrequently accessed and has more relaxed latency requirements. Cold data can be stored on the lower-cost, higher-latency Capacity Pool tier. Understanding the data access patterns and performance needs enables you to properly categorize their data as hot or cold and recommend the appropriate storage configuration. To optimize for cost, you should size your FSx for ONTAP SSD tier as small as possible to support the needs of your workThere are a few ways to approach this:
- When choosing target datasets, consider their size in relation to the SSD storage capacity of the FSx for ONTAP file system. The dataset should be smaller than the available SSD storage to make sure of efficient performance and avoid potential bottlenecks. This allows the FSx for ONTAP inline dedupe and compression to work and not increase the used capacity of the filesystem. You do not have to size for actual capacity.
- This is used in case the dataset being copied to FSx for ONTAP is bigger than the filesystem size.
- Multiple processes happen in the background for the system to be as efficient as possible. Processes can take approximately 15 days within the SSD tier to be completely deduped and compressed.
- Set your volume policy accordingly. If the data you are ingesting is meant for the capacity tier or does not need the performance of the SSD tier, then set the volume policy to ALL.
- Continuously monitor the available capacity in your SSD tier throughout the project by setting up CloudWatch alarms. If the SSD aggregate approaches its maximum capacity, then data tiering is automatically disabled to prevent any further data from being promoted to the SSD tier. This safeguard mechanism makes sure that the SSD aggregate does not completely fill up, which could lead to performance degradation or potential data unavailability.
Conclusion
In this post we showed how to configure FSx for ONTAP to provide highly available and durable shared file storage for your applications. Following the steps outlined in this post enables you to navigate the sizing process with confidence and make sure that your file system is optimized to meet the needs of your on-premises workloads, thereby maximizing performance and efficiency while minimizing unnecessary overhead.