AWS Storage Blog
From raw to refined: building a data quality pipeline with AWS Glue and Amazon S3 Tables
Organizations often struggle to extract maximum value from their data lakes when running generative AI and analytics workloads due to data quality challenges. Although data lakes excel at storing massive amounts of raw, diverse data, they need robust governance and management practices to prevent common quality issues. Without proper data validation, cleansing processes, and ongoing maintenance, organizations may struggle with missing values, incorrect entries, outdated information, and inconsistent formatting. These quality issues directly impact the accuracy and reliability of analytics workloads and AI systems, potentially leading to less effective data-driven decisions and reduced model performance. According to Harvard Business Review, 49% of organizations are prioritizing data quality improvement for generative AI and analytics workloads success.
AWS Glue Data Quality offers a serverless, machine learning (ML)-powered solution to measure, monitor, and improve data quality for analytics and AI/ML workloads by computing statistics, recommending rules, and detecting anomalies in both static and streaming data across pipelines. Complementing this, Amazon S3 Tables, introduced with built-in Apache Iceberg support, provides a scalable and performant way to store tabular data on Amazon S3, offering up to three times faster query performance and ten times more transactions per second with automated maintenance compared to self-managed Iceberg tables. Apache Iceberg is an open source table format designed for large-scale analytical datasets in data lakes, providing database-like reliability and features such as ACID transactions, schema evolution, and time travel on top of cloud storage. Optimizing data management and query efficiency allows S3 Tables, in conjunction with Glue Data Quality, to empower organizations to generate faster insights and maximize the value of their data lakes while upholding high data quality standards.
In this post, we show you how to improve data quality by combining AWS Glue Data Quality with S3 Tables. We show how to automatically validate data quality at scale using both prebuilt and custom rules, monitor quality metrics across your data lake, and set up automated remediation workflows. This integration helps you tackle common data quality challenges while reducing manual effort. This enables your teams to spend less time on data maintenance and more time generating valuable insights. Whether you’re training ML models or running analytics workloads, maintaining high-quality data is crucial for accurate results, and we demonstrate how these services work together to help you achieve this efficiently.
Solution overview
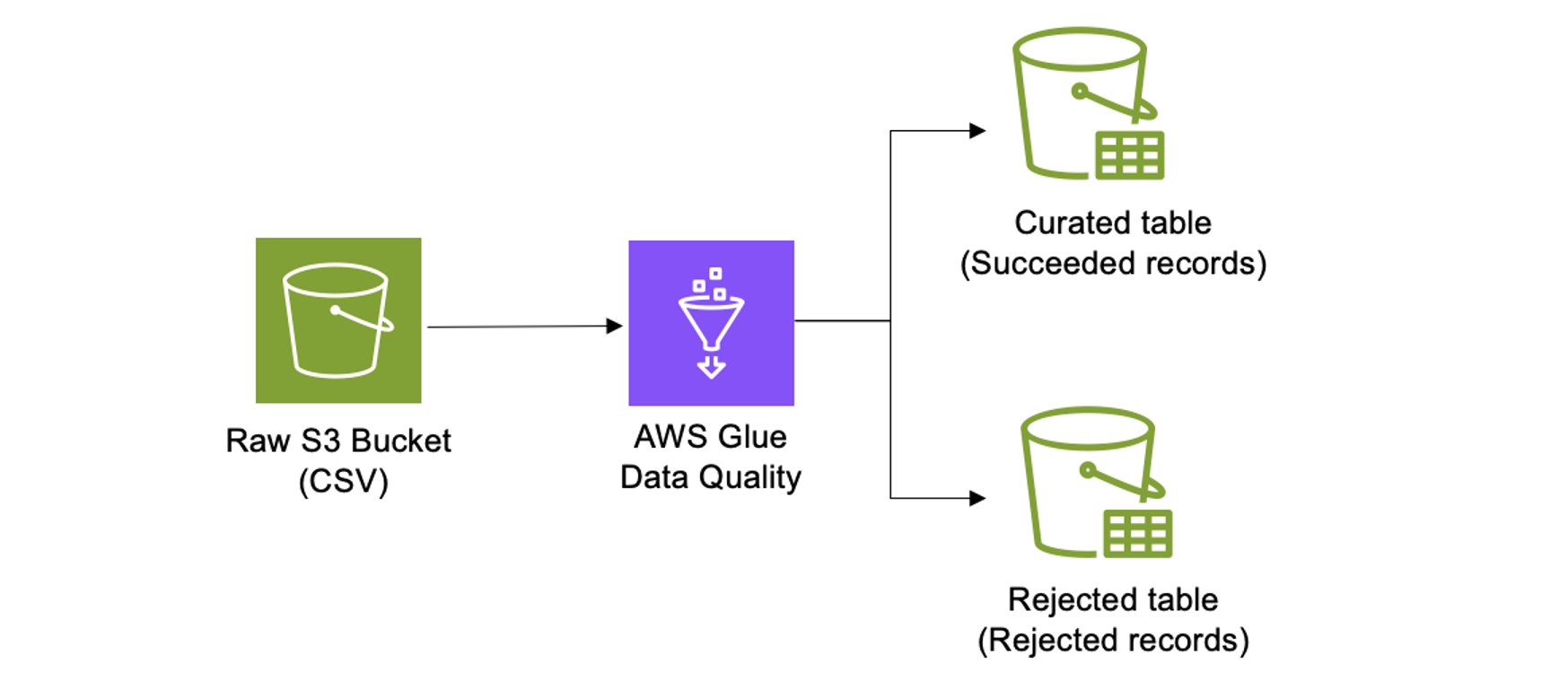
Imagine a scenario where you need to validate the quality of incoming raw data stored in a standard file format such as CSV. The objective is to automatically separate this data into two different tables: one for high-quality records (the curated layer) and another for records that do not meet your quality criteria (the rejected layer).
This approach streamlines downstream analysis by making sure that only high-quality data is used, while also making it easier to manage and review low-quality records. Furthermore, using S3 Tables allows you to eliminate the need to worry about complex table data layouts, further streamlining data operations.
The diagram shows a data quality validation workflow using AWS Glue. First, raw CSV files are stored in an S3 bucket. Then, these files are processed by AWS Glue Data Quality, which applies validation rules. Records that pass validation are saved in a curated table, while records that fail are directed to a rejected table for further review.
Prerequisites
The following prerequisites are necessary to follow along with this solution.
- Create a table: Getting started with S3 Tables
- An Amazon S3 table bucket integrated with the AWS analytics services
- Integrating ETL jobs on Amazon S3 Tables with AWS Glue
- AWS Glue version 5.0 or higher
Walkthrough
This initial code block configures our AWS Glue Studio Notebook environment, setting worker specifications, timeout parameters, and Iceberg configurations, as shown in the following code snippet.
#Adding required notebook configurations
%idle_timeout 60
%glue_version 5.0
%worker_type G.1X
%number_of_workers 5
%%configure
{
"--datalake-formats": "iceberg"
}This code imports several modules to set up an AWS Glue job integrated with Apache Spark and Iceberg tables. It includes Apache Spark-related modules (pyspark.context and pyspark.sql) to create a Spark session, manage contexts, and perform SQL operations. These imports collectively enable the code to process and analyze data stored in Amazon S3 using Iceberg tables, as shown in the following figure.
# Import the EvaluateDataQuality transform from AWS Glue Data Quality module
from awsgluedq.transforms import EvaluateDataQuality
# Import Spark and AWS Glue context related modules
from pyspark.context import SparkContext
from awsglue.context import GlueContext
# Import Spark SQL specific modules
from pyspark.sql import SparkSession
from pyspark.sql.functions import concat_ws
# Initialize Spark Session with AWS S3 Tables (Iceberg) configurations
spark = SparkSession.builder.appName("glue-s3-tables-rest") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.defaultCatalog", "s3_rest_catalog") \
.config("spark.sql.catalog.s3_rest_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.s3_rest_catalog.type", "rest") \
.config("spark.sql.catalog.s3_rest_catalog.uri", "https://s3tables.us-east-1.amazonaws.com/iceberg") \
.config("spark.sql.catalog.s3_rest_catalog.warehouse", "arn:aws:s3tables:us-east-1:222222222222:bucket/amzn-s3-demo-bucket") \
.config("spark.sql.catalog.s3_rest_catalog.rest.sigv4-enabled", "true") \
.config("spark.sql.catalog.s3_rest_catalog.rest.signing-name", "s3tables") \
.config("spark.sql.catalog.s3_rest_catalog.rest.signing-region", "us-east-1") \
.config('spark.sql.catalog.s3_rest_catalog.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') \
.config('spark.sql.catalog.s3_rest_catalog.rest-metrics-reporting-enabled', 'false') \
.config('spark.sql.parquet.enableVectorizedReader', 'false') \
.getOrCreate()
# Create GlueContext using spark.sparkContext
sc = spark.sparkContext
glueContext = GlueContext(sc)Three distinct namespaces are established in S3 Tables: a raw zone for incoming data, a curated zone for validated data, and a rejected zone for records that fail quality checks.
# Create namespaces for Amazon S3 Tables if they don't already exist
# These namespaces organize data at different stages of processing:
# - 'raw': for incoming, unprocessed data
# - 'curated': for cleaned and transformed data
# - 'rejected': for data that failed quality checks or processing
spark.sql("CREATE NAMESPACE IF NOT EXISTS raw")
spark.sql("CREATE NAMESPACE IF NOT EXISTS curated")
spark.sql("CREATE NAMESPACE IF NOT EXISTS rejected")
A verification step displays all created namespaces, as shown in the following figure.
# List all namespaces in the s3tablesbucket catalog
spark.sql("show schemas").show()The source store details data loads from a CSV file in Amazon S3 into a Spark DataFrame, with header recognition and automatic schema inference enabled, as shown in the following figure.
# Read CSV file from S3 bucket into a Spark DataFrame
load_data_df = spark.read.csv("s3://datalake-<AccountId>-<Region>-data/raw/sample_datasets/store_details.csv", header=True, inferSchema=True)An initial S3 Table structure is defined in the raw zone, specifying columns for store information such as ID, name, location details, and operational dates, as shown in the following figure.
# Create S3 Table in raw namespace
spark.sql("""
CREATE TABLE IF NOT EXISTS raw.store_details(
store_id STRING,
store_name STRING,
store_city STRING,
store_state STRING,
store_zip STRING,
store_open_date STRING,
store_closed_date STRING
) USING iceberg
""")A temporary SQL view of the data is created, loaded into the raw Iceberg table, and displayed to verify successful data ingestion, as shown in the following figure.
# Create a temporary view of the DataFrame for SQL operations
load_data_df.createOrReplaceTempView("temp_view")
# Insert data from temporary view into the target Iceberg table
spark.sql("""
INSERT INTO raw.store_details
SELECT * FROM temp_view
""")
# Query and show the contents of store_details raw table
spark.sql("select * from raw.store_details").show()
Data is retrieved from the raw S3 Table and stored in a spark DataFrame for quality validation processing.
# Read data from S3 Table into a Spark DataFrame
raw_data_df = spark.sql("select * from raw.store_details")Two key steps are performed here. First, three key validation rules are established: making sure that store IDs are not empty, verifying store states match an approved list, and checking ZIP codes don’t exceed five characters.
# Define data quality ruleset for store details validation
EvaluateDataQuality_ruleset = """
Rules = [
IsComplete "store_id",
ColumnValues "store_state" in ["AZ", "WA", "IL", "CO", "CA", "NC", "PA", "FL", "NY", "TX", "DC", "IN", "OH"],
ColumnLength "store_zip" <= 5
]
"""Second, the defined quality rules are applied to the data, evaluating each row against validation criteria without metrics publishing or caching, as shown in the following figure.
# Execute data quality evaluation on the source DataFrame
res = EvaluateDataQuality().process_rows(
frame=raw_data_df,
ruleset=EvaluateDataQuality_ruleset,
publishing_options={
"dataQualityEvaluationContext": "EvaluateDataQualityMultiframe",
"enableDataQualityCloudWatchMetrics": "false",
"enableDataQualityResultsPublishing": "false"
},
additional_options={
"performanceTuning.caching": "CACHE_NOTHING"
}
)
This step extracts the row-level quality check results and transforms them into a DataFrame format, setting up the data for subsequent separation of valid and invalid records based on the evaluation outcomes, as shown in the following figure.
# Extract the row-level outcomes from the EvaluateDataQuality result
row_level_outcomes_df = res['rowLevelOutcomes']The code separates records based on quality check results. Valid records are filtered into one DataFrame while failed records go into another DataFrame with added failure reason details, as shown in the following figure. This segregation enables distinct handling of clean and problematic data.
# Store information columns
columns_to_include = ["store_id", "store_name", "store_city", "store_state", "store_zip", "store_open_date", "store_closed_date"]
# Filter rows that passed all data quality rules
good_rows_df = row_level_outcomes_df.filter(row_level_outcomes_df["DataQualityEvaluationResult"] == 'Passed') \
.select(*columns_to_include)
# Filter rows that failed at least one data quality rule
bad_rows_df = row_level_outcomes_df.filter(row_level_outcomes_df.DataQualityEvaluationResult == "Failed") \
.select(
*columns_to_include,
concat_ws(", ", "DataQualityRulesFail").alias("failure_reason")
)
This code is creating two similar S3 Tables in different namespaces (“curated” and “rejected”) using Spark SQL with Iceberg table format. The “curated” table stores valid store details, while the “rejected” table includes another column, “failure_reason”, to track why certain records failed validation, suggesting this is part of a data quality validation rules, as shown in the following figure.
# Create S3 Table in curated namespace for passed records
spark.sql("""
CREATE TABLE IF NOT EXISTS curated.store_details(
store_id STRING,
store_name STRING,
store_city STRING,
store_state STRING,
store_zip STRING,
store_open_date STRING,
store_closed_date STRING
) USING iceberg
""")
# Create S3 Table in rejected namespace for failed records
spark.sql("""
CREATE TABLE IF NOT EXISTS rejected.store_details(
store_id STRING,
store_name STRING,
store_city STRING,
store_state STRING,
store_zip STRING,
store_open_date STRING,
store_closed_date STRING,
failure_reason STRING
) USING iceberg
""")The code writes the segregated data to their respective destinations: valid records are stored in the curated S3 Table, and invalid records are saved in the rejected S3 Table, as shown in the following figure.
# Write successful records to the curated s3 Table
good_rows_df.writeTo("curated.store_details") \
.tableProperty("format-version", "2") \
.append()
# Write failed records to the rejected s3 Table
bad_rows_df.writeTo("rejected.store_details") \
.tableProperty("format-version", "2") \
.append()The chosen statement retrieves and displays all records from the curated table that successfully adhered to the AWS Glue Data Quality rules, as shown in the following figure. These specific rules include: making sure that store_id is not null, validating that store_state values match against an approved list of state codes, and confirming store_zip lengths are exactly five digits. This query enables a comprehensive review of high-quality data that passed these validation checks, making sure of data integrity for downstream analytics and business processes.
# Query and show the contents of store_details curated table
spark.sql("select * from curated.store_details").show(truncate=False)
Lastly, the chosen statement retrieves and displays records from the rejected table that failed one or more AWS Glue Data Quality rules, along with their specific failure reasons, as shown in the following figure. The common validation failures include: store_id being null, store_state containing invalid state codes not present in the approved list, and store_zip lengths exceeding five digits. The failure_reason column explicitly captures these validation errors, making it easier to identify and remediate data quality issues upstream.
# Query and show the contents of store_details reject table
spark.sql("select * from rejected.store_details").show(truncate=False)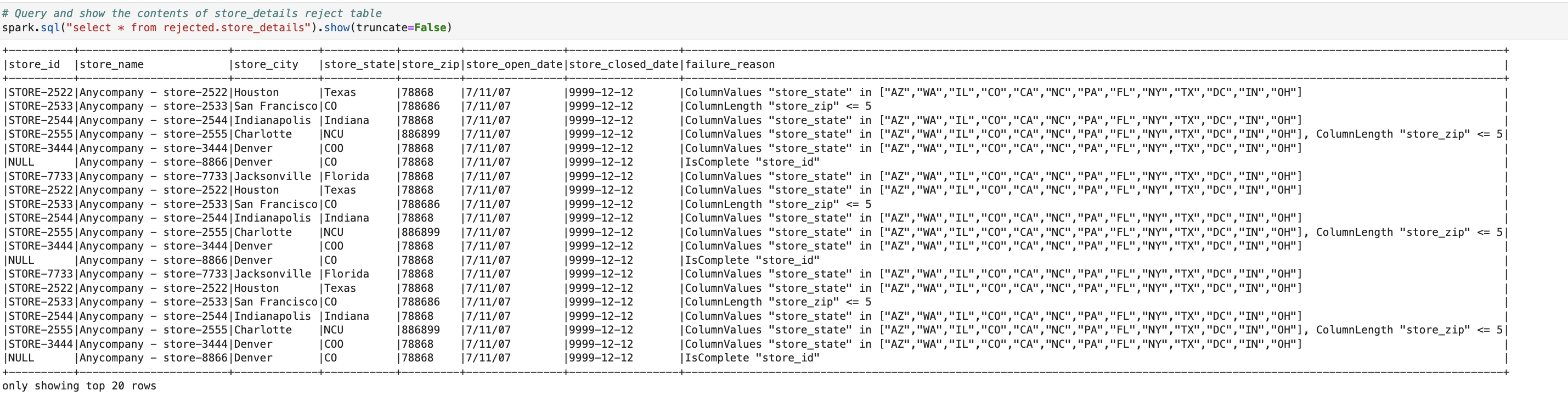
Cleaning up
If you no longer need this solution, then you can delete the following resources created in this tutorial:
- S3 Table bucket (arn:aws:s3tables:<Region>:<AccountId>:bucket/<bucket_name>)
- Glue IAM role
- AWS Glue Studio Notebook/job
- Data Catalog databases and tables created as part of this solution
Conclusion
This data quality management solution demonstrates a robust approach to handling store information using AWS Glue Studio Notebook and Amazon S3 Tables. CSV data is effectively ingested, configurable quality rules are applied, and records are automatically routed to appropriate storage locations based on validation results. Data quality is made sure of through the maintenance of separate zones for raw, curated, and rejected data, while clear visibility into validation failures is provided for further investigation and remediation.
Thank you for reading this post. To explore these concepts in more detail, learn more about Amazon S3 Tables, AWS Glue Studio Notebooks, AWS Glue Data Quality, and Apache Iceberg.