AWS Storage Blog
Building multi-writer applications on Amazon S3 using native controls
Organizations managing data lakes often require additional infrastructure to support concurrent writes from multiple applications. Traditional approaches require external systems for coordination, adding infrastructure overhead, costs, and potential performance bottlenecks. Developers typically implement client-side locking mechanisms using databases or dedicated lock services, resulting in complex multi-step workflows.
Amazon S3 offers capabilities to address these concurrent write challenges without needing external coordination systems. Through conditional writes and its bucket-level policy enforcement, organizations can implement data consistency validation directly within their storage layer. Overwrite protection is central to this capability. An ETag reflects changes in the object’s content, making it ideal for tracking object state. Using a native approach, such as conditional writes with ETag removes the need for separate databases or coordination systems while maintaining reliable data consistency.
In this post, we explore how to build a multi-writer application using S3 conditional write operations and bucket-level policy enforcement. We demonstrate how to prevent unintended overwrites, implement optimistic locking patterns, and enforce consistency requirements, all without the need for separate databases or coordination systems. By implementing these patterns, you can simplify your architecture, reduce costs, and improve scalability while maintaining data integrity.
Solution overview
In a typical data lake scenario, you manage both datasets and their metadata. For example, you may have a bucket with the following structure:
mybucket/ datasets/ customer_profiles/ year=2024/month=01/day=01/profile_data_001.parquet location_events/ year=2024/month=01/day=01/location_events_001.parquet metastore/ dataset_registry.json
This structure serves a data analytics platform with two critical datasets:
- The
/datasets/prefix stores the actual parquet files with customer and location data./customer_profiles/stores customer information such as IDs, names, email addresses, signup dates, and activity data./location_events/capture geographic data points with customer IDs, coordinates, and timestamps.
- The
/metastore/prefix contains thedataset_registry.jsonfile which tracks metadata about all the datasets, such as the file locations, partitioning information, record counts, schema versions, and last update timestamps.
We can examine how data consistency has traditionally been managed in data lake environments. In older Hive-style implementations, two key consistency requirements exist:
/datasets/: When data pipeline processes ingest information from multiple sources, you need to prevent duplicate uploads of the same data file. Without proper controls, these processes might inadvertently overwrite the data file./metastore/: Whenever a dataset is updated, the corresponding metadata in the registry must be updated to reflect this change. Multiple applications must be able to update the registry while making sure that each sees a consistent view. Without proper controls, one application might overwrite changes made by another application, causing the registry to become out of sync with the actual data files.
Maintaining this synchronized relationship between datasets and their metadata is essential for data integrity and necessitates external systems to coordinate access, which increases latency and operational costs. For example, consider the following flow, as shown in Figure 1:
- Client attempts to acquire a lock through an external service.
- If successful, then client reads the current state from S3.
- Client performs their modifications.
- Client writes back to S3.
- Client releases the lock in the external service.

Figure 1: How data has consistency has traditionally been managed in data lakes, with data flow between locking system, applications, and S3 data lake
The S3 conditional writes allow you to address two distinct consistency requirements directly in the storage layer, creating a coordinated workflow between dataset files and their registry entries:
For dataset files (first step in the workflow):
- Applications prevent duplicate uploads using If-None-Match conditions. This creates write-once semantics where attempts to upload the same data file fail if it already exists. Data pipeline processes can safely retry operations without creating duplicates.
For registry files in the metastore (second step in the workflow):
- After a dataset file is successfully uploaded, applications must update the registry to reflect this change. Applications implement compare-and-swap operations using If-Match with ETag allowing registry updates to succeed only when the registry’s ETag matches what the application originally read. Multiple applications can safely update the registry without external coordination.
These two operations work together as a logical unit. First, they make sure that dataset files are written exactly once, and second, they make sure that the registry accurately reflects the current state of all dataset files. This coordination is critical because the registry serves as the source of truth for all applications accessing the data lake. Without this coordination, applications might see inconsistent views of available data or miss newly added datasets entirely. These consistency requirements can be enforced through bucket policies at both bucket and prefix levels. The same registry update can now be accomplished through a streamlined process using native S3 controls:
- Retrieve the registry directly from S3.
- Perform necessary modifications to the registry contents.
- Upload the modified registry using the If-Match condition to maintain atomic compare-and-swap operations.
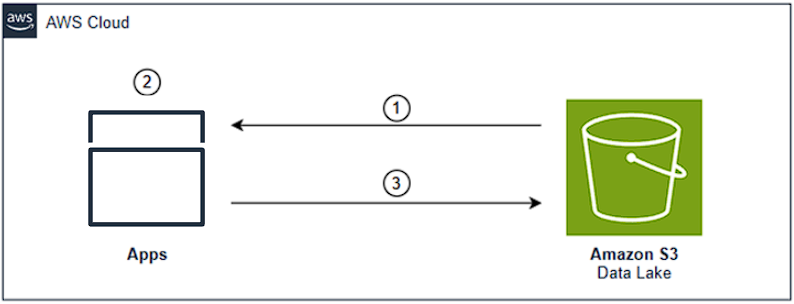
Figure 2: Amazon S3 conditional requests in a data lake environment
Implementation patterns in a data lake environment
In this section we dive into a practical demonstration of implementing these patterns in a data lake environment. We explore three common scenarios that showcase the ability of conditional writes:
- Bucket policy enforcement for conditional writes: maintain data integrity by validating write operations against predefined policies.
- Object creation using If-None-Match: manage partition boundaries while preventing duplicate entries.
- Concurrent metadata updates using If-Match: safely handle multiple clients updating shared metadata simultaneously.
To see these patterns in action, go to the GitHub repository that walks through a simulated data lake environment. The demonstration shows examples of multiple clients interacting with shared datasets and metadata using conditional writes.
Scenario 1: Bucket policy enforcement
Before performing concurrent write operations, we establish a bucket policy to enforce conditional write requirements. Bucket policies enforce conditional write requirements essential for consistency in shared environments. A key challenge arises when mixing conditional and non-conditional requests — non-conditional operations can bypass conditional logic when multiple requests target the same object simultaneously. Without enforcement, one application’s conditional approach can be undermined by another’s non-conditional write. True concurrency control requires all requests to follow identical rules.
Conditional writes can be enforced at bucket or prefix levels in your bucket or IAM policy, requiring all PutObject operations to include specific headers (If-None-Match or If-Match). This prevents non-conditional requests while streamlining application development by enforcing consistent practices across all writers without external mechanisms.
The following bucket policy can be used in a single account scenario (bucket and writer are in the same AWS account) to deny object upload requests to specific prefixes if they do not contain the If-None-Match and If-Match conditions.
- For the
/datasets/prefix, we need the If-None-Match condition to prevent duplicate uploads. - For the
/metastore/prefix, we need the If-Match condition for atomic updates.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BlockNonConditionalObjectCreationOnDatasetsPrefix",
"Effect": "Deny",
"Principal": {
"AWS": "arn:aws:iam::111111111111:role/role1"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-bucket/datasets/*",
"Condition": {
"Null": {
"s3:if-none-match": "true"
},
"Bool": {
"s3:ObjectCreationOperation": "true"
}
}
},
{
"Sid": "BlockNonConditionalObjectCreationOnMetastorePrefix",
"Effect": "Deny",
"Principal": {
"AWS": "arn:aws:iam::111111111111:role/role1"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-bucket/metastore/*",
"Condition": {
"Null": {
"s3:if-match": "true"
},
"Bool": {
"s3:ObjectCreationOperation": "true"
}
}
}
]
}This example bucket policy assumes that the AWS Identity and Access Management (IAM) entity contains an IAM Policy that allows the s3:GetObject and s3:PutObject actions on the bucket.
In the simulation, we observed the bucket policy effectively preventing unauthorized writes to both the /datasets/ and /metastore/ prefixes. Any attempt to write without the necessary conditions (If-None-Match for datasets and If-Match for the metastore) was denied with a 403 AccessDenied response.
Scenario 2: Preventing duplicate uploads (check if object exists using If-None-Match)
The If-None-Match condition implements a “write-once” pattern that prevents overwriting of existing objects. When you include the if-none-match:* header in your PutObject request, you can expect the write to succeed if the object doesn’t already exist in the bucket. This is particularly useful in scenarios where multiple applications are writing to shared storage and you need to verify each object is written exactly once. In a data lake environment, when creating objects, we can use If-None-Match to allow only one thread to succeed in creating the marker. For example, in the simulation we observed the following:
- The first thread to attempt the operation succeeds in creating the partition marker.
- All other concurrent threads receive a PreconditionFailed error:
- S3 Response Code: 412
- S3 Response: PreconditionFailed
- S3 Message: At least one of the preconditions that you specified did not hold.
- S3 Key:
datasets/customer_profiles/year=2024/month=01/day=01/profile_data_002.parquet.
The threads that attempted to create objects faced PreconditionFailed errors because the object already existed, thus preventing duplicates. This allowed objects to be created only once, maintaining data consistency. Threads that encountered PreconditionFailed caused the script to stop retrying the request as this response indicates the object already exists. When an object is successfully created using If-None-Match, S3 returns an ETag in the response. Applications can store this ETag for future reference or validation. However, for write-once scenarios such as object creation, the PreconditionFailed response alone confirms the object’s existence.
Scenario 3: Metadata updates with multiple writers (optimistic locking and compare and swap with If-Match)
In this scenario we make concurrent updates to the registry. In the simulation, there are three concurrent threads attempting to update the dataset_registry.json file. Each thread attempts to read the current state, make modifications, and upload the updated registry using the If-Match condition.
Notice how the S3 conditional writes handle concurrent updates:
- One thread succeeds immediately with its initial attempt because it’s the first to write:
- Initial Attempt with its current ETag
- Result: Success
- The remaining threads encounter precondition failures because the registry’s ETag has changed:
- S3 Response Code: 412
- S3 Response: PreconditionFailed
- S3 Response Message: At least one of the pre-conditions you specified did not hold.
- Condition Details: The ETag in the request doesn’t match the current S3 object ETag.
- The threads that encountered errors are configured to retry the request with a redrive strategy that fetches the latest ETag and retries the request with the update ETag.
- Resolution Strategy:
- Fetch the current registry to get the latest ETag.
- Retry with the updated ETag.
- Resolution Strategy:
When multiple threads attempt to update the registry, only one can succeed while others typically receive a 412 PreconditionFailed response. This occurs because the If-Match condition fails when the object’s ETag has changed since it was last read. Using the If-Match condition means that only one thread can successfully update the registry when the object matches the expected state, maintaining consistency across updates. The threads that fail initially retry and redrive the operation using the updated ETag. Through this feedback loop from S3, all threads eventually succeed in updating the registry with retry with redrive strategy.
Best practices
When implementing conditional writes and bucket-level enforcement, there are several important considerations.
- Concurrent operations: This refers to the timing aspect when multiple requests target the same object simultaneously. Regardless of whether they use conditional headers, these concurrent operations create race conditions where the last request processed typically wins. When non-conditional requests are processed before conditional ones, this can lead to unexpected results. In environments with high-frequency writes to the same objects, this risk increases significantly. To mitigate this, use the bucket policy mechanism described earlier to enforce conditional writes across all applications accessing the bucket.
- Mixed request types: This refers to an inconsistent approach across different applications. In scenarios where both conditional and non-conditional requests are allowed, there’s a risk of data inconsistency, even when operations aren’t concurrent. For example, if Application A uses If-Match for updates while Application B doesn’t use conditional headers, then Application B overwrites changes without checking the object’s current state. This creates a gap where non-conditional requests can bypass consistency controls. This is especially problematic in environments where multiple applications access the same data. To mitigate this, you can implement a bucket policy that explicitly denies any PutObject operations that don’t include conditional headers (If-None-Match and/or If-Match), thus enforcing all applications to follow the same consistency rules.
- Multipart uploads: Special consideration is needed for multipart uploads, as they involve multiple requests. To mitigate this, the bucket policy should account for both direct PutObject operations and CompleteMultipartUpload requests to maintain consistency.
For both concurrent operations and mixed request types, the enforcement of conditional write requirements becomes critical in shared environments where data consistency is essential to application functionality.
Error handling
Error handling necessitates careful consideration, particularly for 409 Conflict and 412 Precondition Failed responses in multiple writer scenarios. A 409 Conflict occurs when multiple writers attempt to modify the same object simultaneously, while a 412 Precondition Failed indicates the precondition specified in your request was not met. For example, in If-None-Match requests the object already exists, and in If-Match requests the object’s state has changed. In race conditions, you might receive a 409 on your first attempt and a 412 on retry as another writer has modified the object. The application needs to implement appropriate strategies based on the error code:
| Error code | Error name | Scenario | Recommended strategy |
|---|---|---|---|
| 409 | ConditionalRequestConflict | Multiple simultaneous updates.
For If-Match conditions, this indicates concurrent operations are competing for the same resource. |
Redrive: Fetch latest state and construct new request. In race conditions, you might receive a 409 on your first attempt and a 412 on retry as another writer has modified the object. The application needs to implement redrive or retry strategies based on the error code. |
| 412 | PreconditionFailed | For If-Match: Object was modified since read.
For If-None-Match: Object already exists. |
|
The application needs to implement appropriate retry or redrive strategies:
- Retry strategy: Automatically attempt the same operation again with exponential backoff. This works well for operations where timing conflicts are temporary, and the original request remains valid.
- Redrive strategy: First fetch the current state using HeadObject or GetObject APIs to get the latest ETag, then construct and submit a new request based on the current object state. This is necessary when the original request’s conditions are no longer valid due to object changes.
For multipart uploads, conditional write validation occurs during the CompleteMultipartUpload operation. When the CompleteMultipartUpload request includes an If-Match condition, S3 validates the ETag at completion time. If the condition fails, then you must implement a redrive strategy that:
- Fetches the current object state.
- Determines whether to end the existing multipart upload.
- Potentially initiates a new upload with updated conditions.
import os
import boto3
import requests
from math import ceil
from botocore.exceptions import ClientError
import time
import xml.etree.ElementTree as ET
def generate_presigned_url(s3_client, operation_name, params, expires_in=3600):
try:
url = s3_client.generate_presigned_url(
ClientMethod=operation_name,
Params=params,
ExpiresIn=expires_in
)
return url
except Exception as e:
print(f"Error generating presigned URL for {operation_name}: {e}")
raise e
def upload_part(s3_client, file_path, bucket_name, object_name, upload_id, part_number, chunk):
try:
# Generate presigned URL for upload_part
url = generate_presigned_url(
s3_client,
'upload_part',
{
'Bucket': bucket_name,
'Key': object_name,
'PartNumber': part_number,
'UploadId': upload_id
}
)
# Upload the part using the presigned URL
headers = {'Content-Type': 'application/octet-stream'}
response = requests.put(url, data=chunk, headers=headers)
response.raise_for_status()
return {
'PartNumber': part_number,
'ETag': response.headers['ETag'],
'ChecksumSHA256': response.headers.get('x-amz-checksum-sha256')
}
except Exception as e:
print(f"Error uploading part {part_number}: {e}")
raise e
def get_object_etag(s3_client, bucket_name, object_name):
try:
url = generate_presigned_url(
s3_client,
'head_object',
{
'Bucket': bucket_name,
'Key': object_name
}
)
response = requests.head(url)
if response.status_code == 404:
return None
response.raise_for_status()
return response.headers['ETag']
except requests.exceptions.RequestException as e:
if e.response is not None and e.response.status_code == 404:
return None
raise e
def parse_upload_id_from_xml(xml_content):
root = ET.fromstring(xml_content)
# Define the namespace
namespace = {'s3': 'http://s3.amazonaws.com/doc/2006-03-01/'}
# Find the UploadId element
upload_id = root.find('.//s3:UploadId', namespace)
if upload_id is not None:
return upload_id.text
raise Exception("Failed to parse UploadId from response")
def multipart_upload_to_s3(file_path, bucket_name, object_name, max_retries=3, chunk_size=5 * 1024 * 1024):
s3_client = boto3.client('s3')
retry_count = 0
while retry_count <= max_retries:
try:
# Get current ETag before starting upload
existing_etag = get_object_etag(s3_client, bucket_name, object_name)
# Generate presigned URL for create_multipart_upload
create_mpu_url = generate_presigned_url(
s3_client,
'create_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name
}
)
# Initiate multipart upload
response = requests.post(create_mpu_url)
response.raise_for_status()
# Parse the XML response to get the upload ID
upload_id = parse_upload_id_from_xml(response.content)
print(f"Initiated multipart upload with ID: {upload_id}")
# Upload parts
parts = []
file_size = os.path.getsize(file_path)
num_parts = ceil(file_size / chunk_size)
with open(file_path, 'rb') as f:
for part_number in range(1, num_parts + 1):
chunk = f.read(chunk_size)
part = upload_part(
s3_client,
file_path,
bucket_name,
object_name,
upload_id,
part_number,
chunk
)
parts.append(part)
print(f"Uploaded part {part_number}/{num_parts}")
# Generate presigned URL for complete_multipart_upload
complete_url = generate_presigned_url(
s3_client,
'complete_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name,
'UploadId': upload_id
}
)
# Prepare completion XML
completion_xml = '<CompleteMultipartUpload>'
for part in parts:
completion_xml += f'<Part><PartNumber>{part["PartNumber"]}</PartNumber><ETag>{part["ETag"]}</ETag></Part>'
completion_xml += '</CompleteMultipartUpload>'
# Complete multipart upload with If-Match header
headers = {
'Content-Type': 'application/xml',
'If-Match': existing_etag
}
response = requests.post(complete_url, data=completion_xml, headers=headers)
response.raise_for_status()
# Parse the completion response XML to get the ETag
def parse_complete_multipart_upload_response(xml_content):
root = ET.fromstring(xml_content)
namespace = {'s3': 'http://s3.amazonaws.com/doc/2006-03-01/'}
etag = root.find('.//s3:ETag', namespace)
return etag.text if etag is not None else 'N/A'
final_etag = parse_complete_multipart_upload_response(response.content)
print(f"File uploaded successfully.")
print(f"Final ETag from S3: {final_etag}")
return {'ETag': final_etag}
except requests.exceptions.RequestException as e:
if e.response is not None and e.response.status_code == 412: # PreconditionFailed
retry_count += 1
print(f"ETag mismatch detected (Attempt {retry_count} of {max_retries})")
# Generate presigned URL for abort_multipart_upload
if 'upload_id' in locals():
abort_url = generate_presigned_url(
s3_client,
'abort_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name,
'UploadId': upload_id
}
)
requests.delete(abort_url)
if retry_count <= max_retries:
print("Object was modified during upload. Retrying with updated ETag...")
time.sleep(2 * retry_count)
continue
else:
print("Max retries exceeded")
raise Exception("Failed to upload file after maximum retries")
else:
raise e
except Exception as e:
print(f"Error during multipart upload: {e}")
if 'upload_id' in locals():
abort_url = generate_presigned_url(
s3_client,
'abort_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name,
'UploadId': upload_id
}
)
requests.delete(abort_url)
raise e
if __name__ == "__main__":
file_path = "/tmp/large_file"
bucket_name = "my-bucket"
object_name = "large_file"
try:
multipart_upload_to_s3(file_path, bucket_name, object_name)
except Exception as e:
print(f"Upload failed: {e}")
}When working with versioned buckets, other considerations come into play such as the handling of delete markers and version-specific ETags. Applications need to be designed with awareness of these behaviors, especially when implementing version-aware workflows or when maintaining audit trails of object modifications. We recommend testing your application’s behavior under various concurrent access patterns and error conditions. This includes simulating multiple writers attempting concurrent modifications, testing both retry and redrive strategies for different error scenarios, verifying proper handling of multipart upload conflicts, and validating version-specific ETag handling in versioned buckets.
Cleaning up
To clean up resources used in this post, navigate to the S3 console, select the bucket that you created, choose Empty to remove all objects. Once empty, select the bucket again and choose Delete to permanently remove it.
Conclusion
In this post, we demonstrated how S3’s native capabilities can address multi-writer challenges without external coordination systems. We explored three key implementation patterns: bucket policy enforcement to control write operations, If-None-Match conditional writes to prevent duplicate dataset uploads, and If-Match’s optimistic locking capabilities to enable safe concurrent metadata updates in a shared registry.
The S3 conditional writes and bucket-level enforcement provide robust data consistency in multi-writer environments without external coordination systems. These native features eliminate the need for external databases and custom concurrency controls, offering five key advantages:
- Architectural streamlining: Remove complex coordination systems for clearer architectures.
- Enhanced data integrity: Prevent race conditions with atomic compare-and-swap operations.
- Improved operational efficiency: Enable parallel processing in ETL workflows.
- Cost optimization: Reduce infrastructure components and operational overhead.
- Better performance: Eliminate database lookups while maintaining consistency.
Whether implementing If-Match for optimistic locking or If-None-Match to prevent duplicates, these capabilities maintain data consistency with direct, efficient architecture.
To start implementing these features today, visit the S3 User Guide and our GitHub repository for code examples.