AWS Public Sector Blog
Research at the speed of discovery: AWS cloud bursting eliminates computational bottlenecks

Imagine you’ve just made a promising discovery in your genomics research that could lead to a breakthrough in cancer treatment. Your preliminary results are compelling, but running the full analysis would tie up your university’s entire GPU cluster for three weeks. Meanwhile, other researchers are lined up behind you with equally urgent projects. Do you wait, potentially losing momentum on a time-sensitive discovery? Or do you scale back your analysis and risk missing critical insights?
This scenario plays out across research institutions daily, forcing an impossible choice between ambition and available resources.
The research computing dilemma
Research computing demands are inherently “bursty”—involving periods of intense computational need during breakthroughs, grant deadlines, or conference submissions, followed by analysis phases requiring less compute. This creates a fundamental mismatch with traditional high performance computing (HPC) infrastructure.
Most university HPC systems are under-provisioned by design, as budget constraints force institutions to amortize system costs over a 3-5 year lifetime, which means they can only afford systems sized for average demand, not peak demand. This under-provisioning is most acute for specialized resources like GPU nodes and high-memory systems, where you often face days or weeks in queue waiting for access to the specific hardware your workloads require.
Why traditional approaches fall short
Fixed-capacity systems cannot accommodate when hundreds of researchers experience computational bursts at unpredictable times. Even systems running at high utilization cannot accommodate overlapping burst demands from the research community, creating systemic queue backlogs.
Budget constraints force difficult trade-offs between serving current researchers and staying current with rapidly evolving hardware. When specialized hardware for peak demand must be justified over multi-year periods, institutions inevitably under-invest in the resources researchers need most. Meanwhile, you watch your research momentum slow as breakthrough discoveries wait for computational resources. The performance gap widens continuously. While on-premises systems remain static between major refresh cycles every 3-5 years, cloud infrastructure evolves constantly with the latest hardware innovations, as illustrated in the following figure.
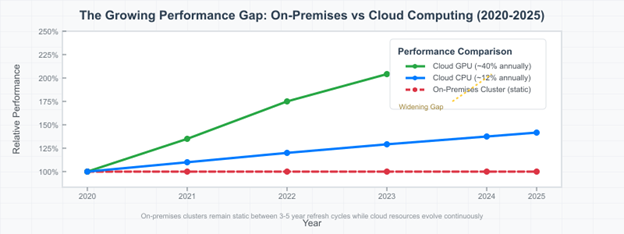
Figure 1. Hardware evolution
How HPC bursting works
AWS has leveraged the expertise of Pariveda Solutions, an AWS Premier Consulting Partner, to develop a flexible HPC bursting solution that dynamically extends your on-premises infrastructure into the cloud. This approach provides stable core HPC infrastructure with the flexibility to handle peak demand without massive capital investments.
Pariveda’s expertise in hybrid cloud architectures and deep understanding of academic research workflows enables this solution to bridge the gap between on-premises infrastructure and cloud scalability while maintaining familiar tools and processes.
The solution leverages the open source AWS Plugin for Slurm, which integrates seamlessly with Slurm to automate cloud resource provisioning and cleanup. Slurm and the plugin provide budget control and guardrails to ensure responsible cloud usage.
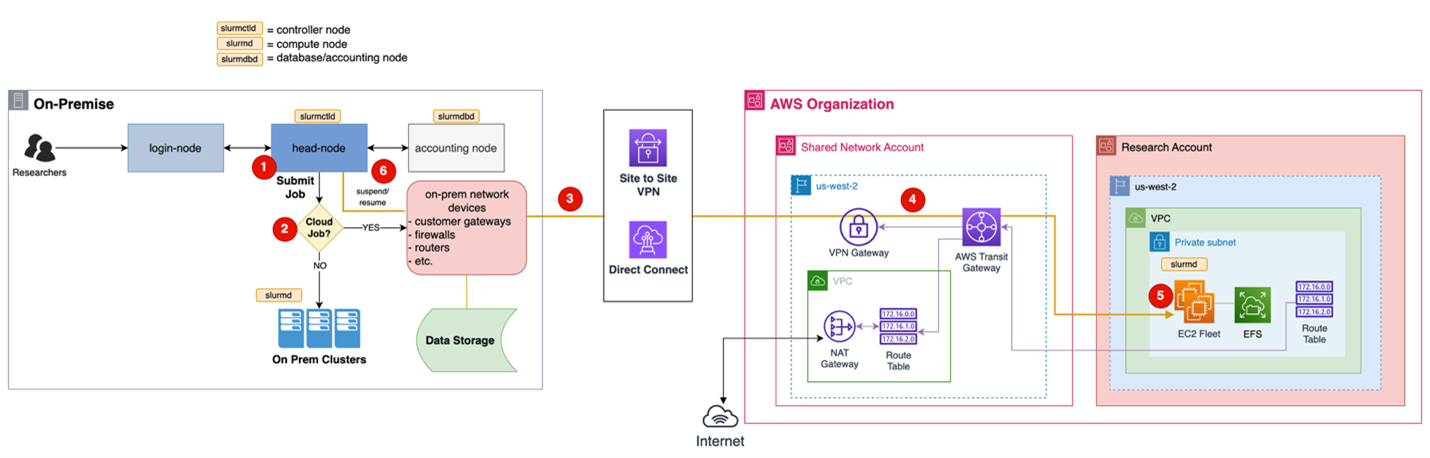
Figure 2. HPC bursting architecture overview
As shown in the preceding figure, your workflow remains virtually unchanged. You submit jobs to existing on-premises clusters using familiar tools. You decide whether to burst to AWS based on your research needs, queue conditions, and available resources. When cloud resources are needed, jobs travel through secure Site-to-Site VPN or AWS Direct Connect. AWS automatically provisions Amazon Elastic Compute Cloud (Amazon EC2) instances tailored to your job requirements, executes the work, and shuts down instances after completion to minimize costs.
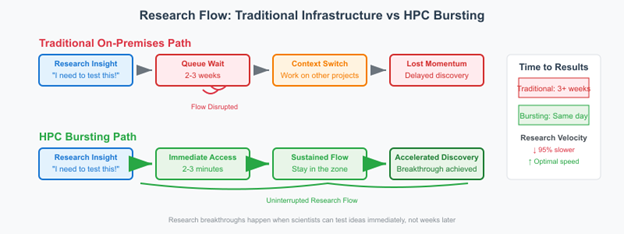
Figure 3. Research flow comparison
As shown in the preceding figure, researchers experience dramatically reduced wait times while maintaining their familiar workflows.
Beyond capacity: Access to cutting-edge resources
HPC bursting addresses fundamental under-provisioning by enabling “time shifting” of workloads. Instead of waiting days or weeks in queue for specialized resources, you access the enormous scale of AWS immediately. Additionally, bursting provides access to cutting-edge resources often unavailable on-premises, including:
- Latest NVIDIA GPUs
- Intel and AMD CPUs with the newest architectures
- ARM-based Graviton processors for cost-optimized workloads
- AWS Trainium and Inferentia chips for AI/ML acceleration
- FPGAs for specialized computational tasks
- Quantum computing systems through Amazon Braket
Seamless data access
Critical to HPC bursting success is maintaining consistent data access regardless of where jobs execute. The architecture extends on-premises storage into the cloud through multiple approaches: Amazon Elastic File System (EFS) mounts as a network drive on-premises while supporting multiple independent AWS accounts for cross-research group collaboration, Amazon Simple Storage Service (Amazon S3) provides scalable object storage for large datasets, Amazon FSx for Lustre delivers high-performance parallel file systems optimized for HPC workloads, or direct mounting of on-premises storage systems, as depicted in the following figure.
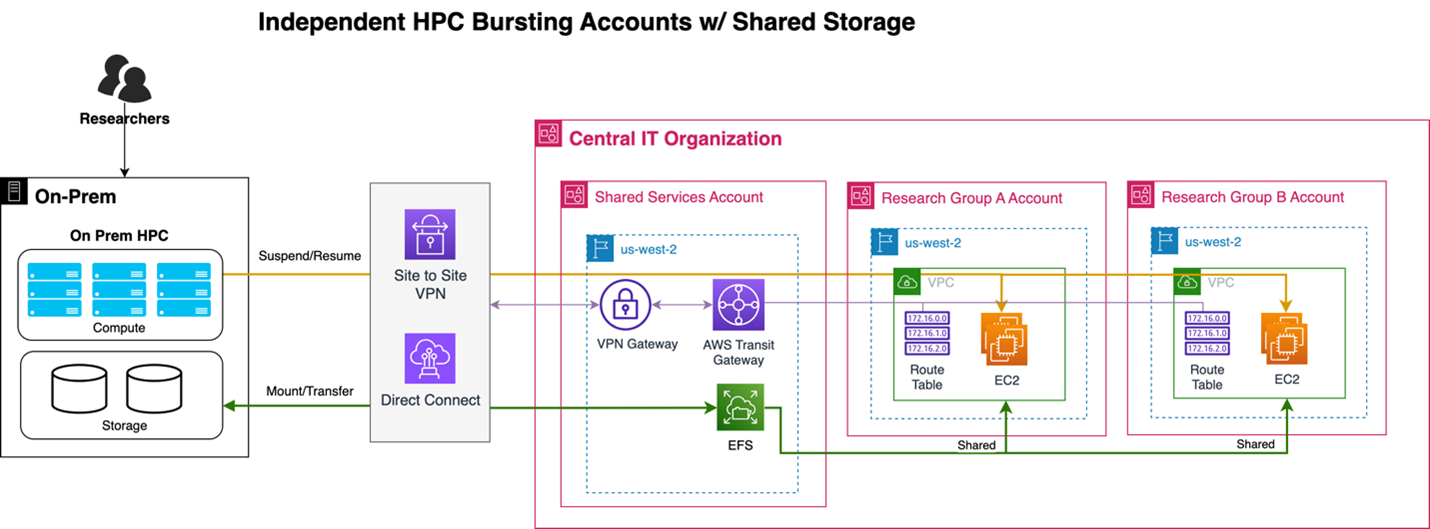
Figure 4: Storage architecture with EFS integration
Real-world impact
HPC bursting has delivered significant impact for research and IT teams. For example:
- Climate modeling teams run ensemble forecasts in hours instead of weeks.
- AI research groups access the latest NVIDIA GPUs, maintaining research velocity.
- Computational chemistry labs scale from 100 to 10,000 cores for drug discovery.
- Materials science researchers combine traditional HPC with quantum computing.
Benefits for research and IT teams
For researchers, HPC bursting delivers a near-zero learning curve, with cloud environments mirroring your familiar on-premises systems, allowing scripts and workflows to function without modification. Your existing authentication methods remain unchanged.
Most importantly, HPC bursting allows institutions to maintain research velocity by saying “yes” to ambitious projects. Rather than forcing you to scale back your ambitions or wait weeks for hardware upgrades, IT teams can provision the exact resources you need immediately. This preserves research momentum and prevents the productivity loss that comes when you must context-switch between projects while waiting for resources.
For IT teams, this translates to sustained research velocity through intelligent load balancing across local and cloud environments. The pay-as-you-use model eliminates expensive specialized hardware purchases that may only be needed occasionally, while unified monitoring provides comprehensive oversight of hybrid resources.
Understanding the economics
Burst computing typically costs 60-80 percent less than purchasing equivalent specialized hardware, with most institutions seeing ROI within 6-12 months. Instead of large capital expenditures every 3-5 years, institutions can plan for operational expenses that scale directly with research activity.
Getting started
Implementation follows three phases:
- Assessment – Identify pilot research groups, assess network requirements, and review security considerations.
- Infrastructure setup – Configure secure connections, deploy cloud integration, and establish monitoring systems.
- Pilot deployment – Begin with select research groups to validate workflows and optimize performance.
Jobs typically launch in cloud resources within 2-3 minutes, while data synchronization happens transparently in the background. Network bandwidth requirements are modest for most workloads, though data-intensive applications benefit from AWS Direct Connect.
The future of research computing
This hybrid approach represents the future of research computing as demands become increasingly data-intensive and computationally complex. Emerging compute paradigms like quantum become accessible through cloud bursting, ensuring your institution stays at the forefront of computational research.
HPC bursting eliminates computational bottlenecks that break research momentum, ensuring breakthrough discoveries aren’t delayed by infrastructure limitations. In an era of growing computational demands, maintaining research velocity becomes the key differentiator for leading institutions.
Research teams that once planned projects around hardware availability now plan around scientific opportunity.
Ready to explore how HPC bursting could transform your research computing environment? Pariveda Solutions, an AWS Premier Consulting Partner with deep expertise in hybrid cloud architectures and academic research workflows, can help assess your institution’s unique requirements and accelerate your research mission.
Learn more about technical implementation through the AWS Plugin for Slurm GitHub repository.