AWS Public Sector Blog
PixelGuard: Advancing healthcare data privacy through AI-driven de-identification system for medical imaging research

Medical images play a crucial role in medical research by providing valuable insights that help advance our understanding of human health, disease management, and treatment efficacy. Researchers use medical images to study the structure and function of organs, tissues, and cells in healthy and diseased states. These images are also used to train and educate healthcare professionals, to create educational resources and workshops, and to train medical staff in understanding and interpreting imaging data.
Although medical images play a crucial role in research and medical education, protecting privacy in medical images is of paramount importance to ensure patient confidentiality, trust, and compliance with ethical and legal standards, such as HIPAA and HITRUST. Medical images contain highly sensitive information about a patient’s health, conditions, and prognosis. Maintaining privacy of Personally Identifiable information (PII) and Personal Health Information (PHI) ensures that this information is never disclosed without the patient’s explicit consent while also building patient trust in healthcare.
Furthermore, laws such as the Health Insurance Portability and Accountability Act (HIPAA), Health Information Trust Alliance Common Security Framework in the US, and General Data Protection Regulation (GDPR) in the European Union (EU) set strict guidelines on how medical data such as images should be handled, stored, anonymized, and shared. Violating these regulations can result in severe penalties and can damage the reputation of healthcare providers and their institutions. Moreover, healthcare professionals have a moral and ethical obligation to respect patient privacy.
Digital Imaging and Communications in Medicine (DICOM)
DICOM is the standard format used for storing, transmitting, and sharing medical images and related data. DICOM files hold information structured into image data and other metadata. Each DICOM field is used to describe and categorize various aspects of the medical image such as patient information, study details, and imaging parameters. For example, DICOM fields include patient name, birth date, gender, study date, referring physician, pixel data, series information, equipment manufacturer, model name, software version, study, and diagnosis descriptions, among others.
DICOM files contain Personally Identifiable Information (PII), thus they cannot be used in medical research or training without sensitive information being redacted. However, it is crucial to make sure that the process of redacting sensitive information does not compromise the quality of the information that is not individually attributable. It is also important to minimize the size of the de-identified medical images to reduce storage and processing costs while providing the flexibility save resulting anonymized files as DICOM or JPEG. AWS HealthImaging, the scalable and high performant cloud based DICOM store, provides sub-second image retrieval from anywhere. The total cost of ownership (TCO) of image storage and data transfer can be substantially reduced using the industry standard High Throughput JPEG 2000 (HTJ2K) image encoding.
Solution walkthrough
PixelGuard—built on Amazon Web Services (AWS) and created by Northwestern University Assistant Professor and Founder of Xtasis, LLC, Dr. Adrienne Kline—is an advanced software solution that deidentifies medical images while preserving clinical relevance and efficacy. It uses over 75 state-of-the-art AI-driven models capable of detecting and redacting multilingual, multi-orientation text across all major formats (DICOM, JPEG, PNG, NIfTI, etc.), alongside configurable metadata anonymization. With an intuitive UI, enterprise SSO, and in-tenant deployment (no data egress), PixelGuard delivers secure, compliant, and high-throughput image de-identification. PixelGuard is available on AWS Marketplace. ScaleCapacity—an AWS Partner—was instrumental in the development of the UI, cloud infrastructure, and deployment to AWS Marketplace.
Ingestion layer
The ingestion layer provides a user interface and an API to submit a medical image for de-identification. The API can also be used by a third-party medical device manufacturer to provide the redaction ability. Prior to the ingestion, the web UI and API can be secured with enterprise identity provider based authorization. Along with ingesting the image needing de-identification, this layer must also capture the specific de-identification configuration, which defines which fields need to be redacted from the image. For common redaction scenarios such as redaction to comply with HIPAA regulations, predefined field sets are defined and recorded.
Pre de-identification layer
The storage layer is used to store the image prior to the de-identification. Furthermore, the storage layer may also store a compressed file containing several images needing de-identification. Moreover, this layer also stores metadata pertaining to the de-identification job such as the job ID, submission time, specific fields being redacted, format of the file provided, etc.
Processing layer
The storage layer identifies the format of an image needing de-identification and based on the specific de-identification configuration, the image metadata defined by the DICOM tags and the Pixel-level de-identification is undertaken. Furthermore, the image can be compressed for storage optimization and a crosswalk file referencing a unique ID is created. The crosswalk file makes it possible to do a reverse lookup of the original file if it is ever needed. Care should be exercised to secure the crosswalk file and store it separate from the de-identified file.
De-identification pipeline
The de-identified storage layer stores the processed de-identified medical image, which can be used by medical researchers as part of a study. Furthermore, the image can be generated in various formats consistent with the needs of the research study.
De-identified output layer
The de-identified images can be created in conjunction with a crosswalk file that can maintain a mapping between an identifier in the de-identified image and a relevant identifier in the original image. The crosswalk file is maintained separately and encrypted to allow only authorized individuals to trace the de-identified image back to its original source if needed.
Auditing, monitoring, and observability
The auditing, monitoring, and observability layer stores access logs to make sure that records of who accessed what, when, and how can be stored for record keeping purposes. Furthermore, detailed error logs if any can be stored to enable troubleshooting if certain medical images could not be de-identified.
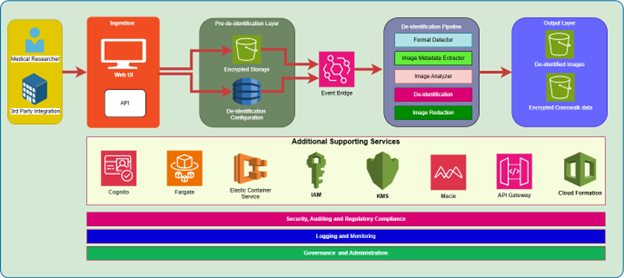
Figure 1. PixelGuard logical solution architecture
The de-identification of medical images necessitates metadata and pixel data scrubbing. In some situations, the metadata may need to be anonymized rather than removed entirely. When the metadata is anonymized rather than removed, the anonymization process must not in any way dilute the research value of the image. For example, a medical image of a 20-year-old cannot be anonymized to indicate that the image belongs to an 80-year-old, because that may dilute the research value.
To scrub pixel data, optical character recognition (OCR) to detect burned-in text can be used. This must be used in conjunction with machine learning (ML) models to locate and blur areas with identifying information. ML models can also be used to generate a confidence score associated to the blurring of information. For images where the confidence score is below a certain pre-defined threshold, a human review queue can also be defined for investigation and possible approval.
Tools and frameworks
Ingestion: The ingestion layer can be handled with a Web UI and an API that can be exposed through the API Gateway and that can perform request validation, authentication, and authorization along with security rule enforcement. The API Gateway integrates with Amazon Cognito to enforce fine-grained authentication and authorization.
Pre-de-identification storage: This layer can store pre-defined image de-identification profiles such as those for HIPAA, and can store it to an Amazon Simple Storage Service (Amazon S3) bucket or to a combination of an S3 bucket and Amazon DynamoDB.
De-identification: De-identification is a multi-step process that can use DICOM parser libraries such as pydicom and scrubbing tools such as dicom-anonymizer. Amazon Textract, and Amazon Comprehend Medical can also be used to identify embedded text within images.
Output: Post de-identification medical images can be compressed, converted to a different format, and stored with identifiers that can be mapped to the original source if needed. The storage can be handled with S3 buckets or file systems as needed with or without compression.
Other supporting services: Other supporting services play a critical role in enabling security, scalability, manageability, and infrastructure automation. Services such as Amazon API Gateway make it possible to enforce AuthN/AuthZ policies consistent with organizational needs. AWS Key Management Service (AWS KMS) provides a secure way to manage cryptographic keys and protect your data. AWS Fargate can be used to run thousands of containers without the need to manage servers or clusters of Amazon Elastic Compute Cloud (Amazon EC2) instances.
Furthermore, services such as Amazon Macie can add a secondary layer of protection to identify sensitive data and to protect it in conjunction with other remediation services. Moreover, services such as AWS CloudFormation enable the defining of AWS infrastructure resources in a declarative way, using templates in the JSON or YAML format and can automate the creation, configuration, and management of these resources, acting as an infrastructure as code (IaC) tool.
The following images provide an overview of the image redaction experience using PixelGuard.
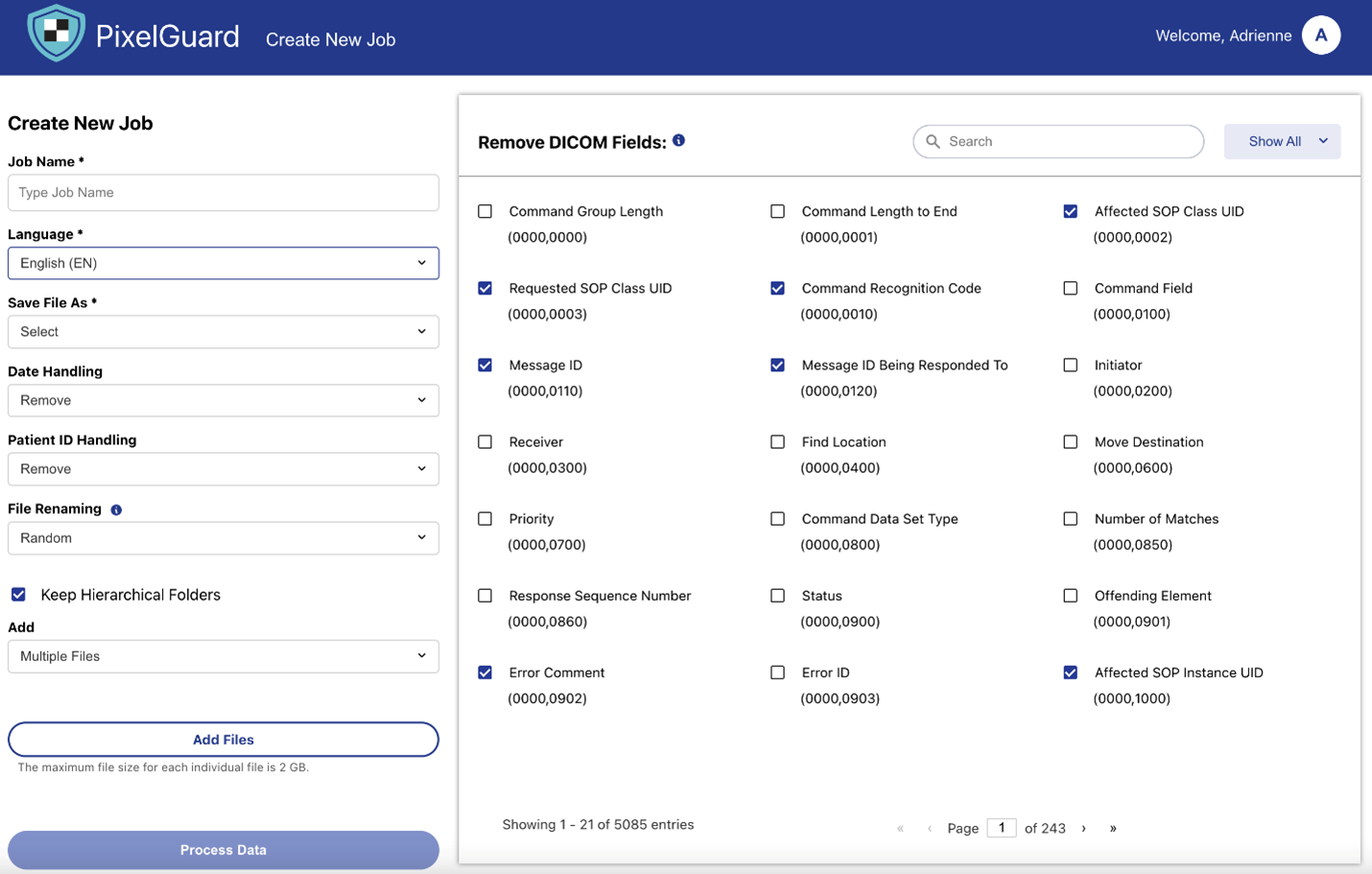
Figure 2. Configuring fields for redaction in medical images
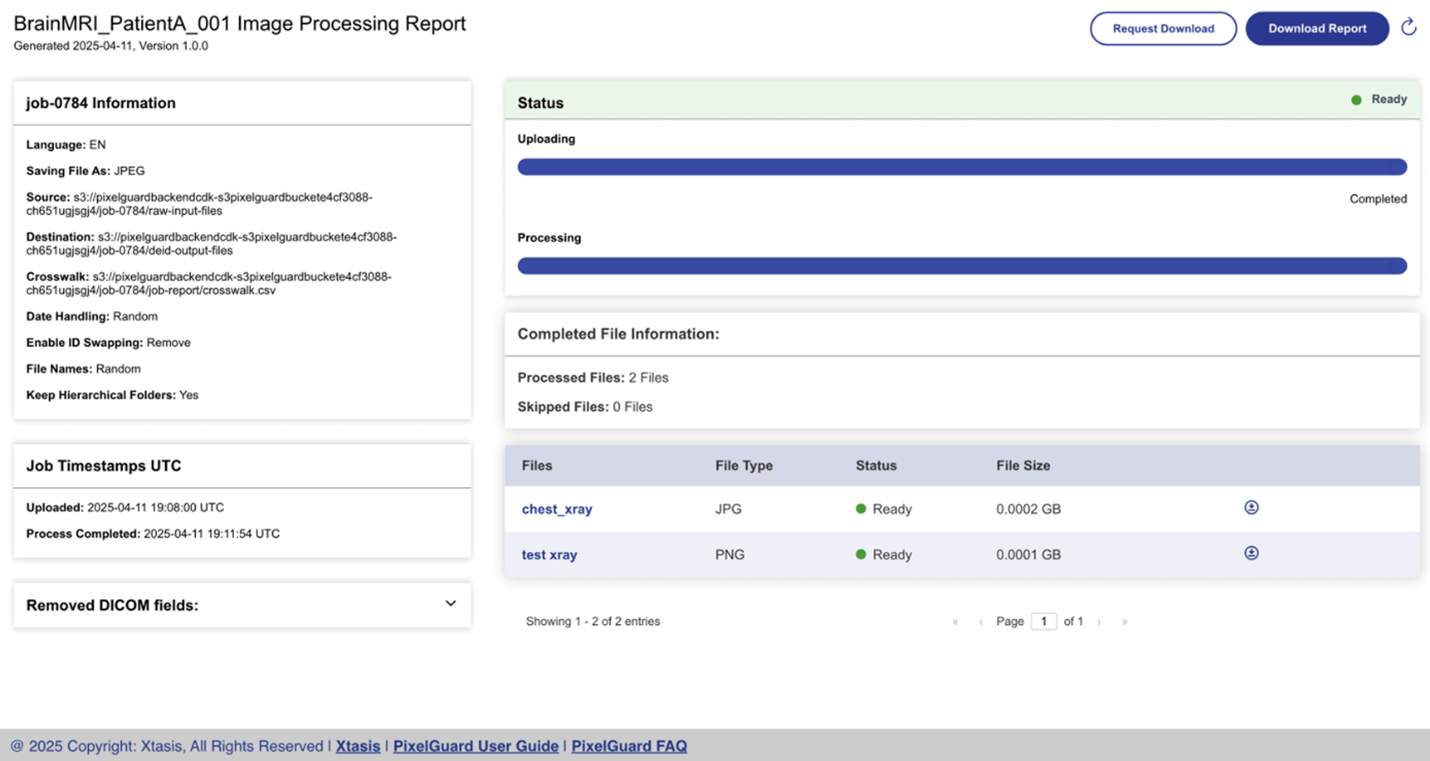
Figure 3. Redaction job completion report
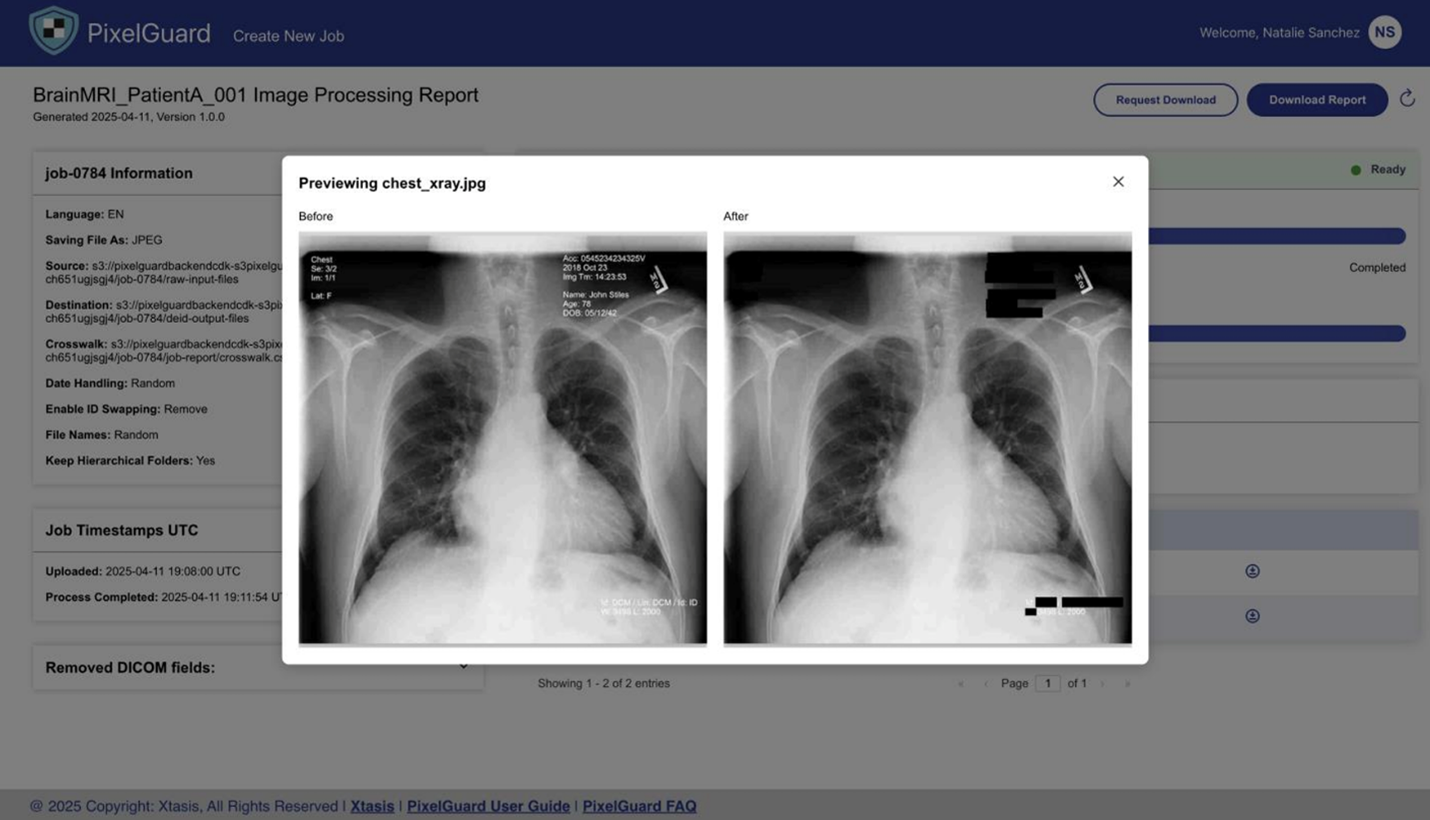
Figure 4. Previewing unredacted and redacted images together
Conclusion
De-identifying medical images is a crucial need in medical research and training. It ensures that the de-identified image cannot be linked back to an individual. A sound technical architecture for de-identifying medical images is crucial for the safe and compliant use of medical images for research and medical discovery. This architecture can make sure that PII is reliably removed or obscured protecting patient privacy without compromising the utility of the data.
PixelGuard as a solution built on AWS enables flexible de-identification, thereby enabling compliance with privacy laws, enhancing security, and reducing risks. At the same time, it facilitates data sharing and collaboration, ultimately promoting faster medical imaging AI research in public health and medical advancements, all while maintaining ethical and legal responsibilities.
Next steps
- Access PixelGuard on AWS Marketplace
- Read more about solving medical mysteries in the AWS Cloud: Medical data-sharing innovation through the Undiagnosed Diseases Network.
- Read more about how to build an enterprise medical imaging inference pipeline using MONAI Deploy on AWS.
- Read more about how to streamline Medical Imaging AI Deployments with NVIDIA NIMs and AWS Services
- Reach out to an AWS representative if you want to build similar system to accelerate your healthcare systems.