AWS Public Sector Blog
No-code AI development: Using Amazon SageMaker AI and Amazon Kendra for smart search chatbots

Organizations have the opportunity to greatly benefit from machine learning (ML) chat-based assistants because they provide an efficient way to gain valuable business insights. In the case of nonprofit organizations, by analyzing user interactions, chat assistants can identify trends, donor preferences, and common inquiries, enabling these organizations to tailor their fundraising strategies and outreach efforts through natural questions. Additionally, these assistants offer real-time data analysis, helping nonprofits make informed decisions, optimize resource allocation, and enhance stakeholder engagement.
AI-supported analytics allow data-driven decision-making for all users with insights that are accessible and actionable. Even vague inquiries asked in natural language are met with comprehensive and contextual answers that explain data with visuals and stories in detail to help members explore data and gain deeper understanding. In this post, we walk through creating a Retrieval Augmented Generation (RAG)–powered chat assistant using Amazon SageMaker AI and Amazon Kendra to query donor data on Amazon Web Services (AWS).
How nonprofits benefit from AWS
Through the Amazon SageMaker Canvas chat-based experience, customers can interact directly with foundation models (FMs) from Amazon Bedrock and Amazon SageMaker JumpStart in a chat-based UX, without needing to know about topics like generative AI, APIs, endpoints, tokens, parameters, and chat interfaces. The chat interface is built into the Amazon SageMaker Canvas app, which users are already familiar with in the ready-to-use models tab.
After the Amazon SageMaker Canvas chat experience is launched, users can start interacting with FMs in the chat interface, asking questions and providing prompts. Users can choose which model they want to interact with, from either Amazon Bedrock (Amazon and third-party models) or Amazon SageMaker JumpStart (open-source models). Users can also compare multiple models at one time to select which style of answers fits best for their requirements.
Answers generated by large language models (LLMs) aren’t always grounded. SageMaker Canvas provides integration with Amazon Kendra to achieve no-code RAG workloads, which means that customers can query their own documents and generate answers from the most relevant snippets. After a cloud administrator has configured Amazon SageMaker Canvas to access an Amazon Kendra index, all that a user is required to do is turn on Query your documents in the chat interface and select the index to query. Amazon SageMaker Canvas takes care of forwarding the query to Amazon Kendra and using the retrieved snippets with the selected LLM or LLMs to generate the answer. Amazon SageMaker Canvas also points to the sources that led to the generated response, and you can preview them on the side of the screen if the source is a .PDF file.
Architecture
The major components of the solution are an Amazon Simple Storage Service (Amazon S3) bucket, Amazon Kendra, and Amazon SageMaker Canvas. The following diagram shows the high-level architecture you will build by following the steps in this post.
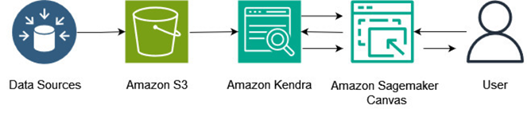
Figure 1. Architectural diagram of the solution
Prerequisites
To perform the solution, you need to have the following prerequisites in place:
- An active AWS account.
- AWS Identity and Access Management (IAM) with appropriate permissions to access Amazon S3, Amazon Kendra, and Amazon SageMaker. For more information, refer to Create an IAM user in your AWS account.
Solution walkthrough
The following sections demonstrate how to perform the solution.
Load data to Amazon S3
Download the donor data files from these public links:
- Role of Non Profit Organization in Building a Harmonious Society
- Trust Issues: Navigating Donor Intent in a Changing World
- The impact of Artifical Intelligence on Donor Engagement For Non Profit Organizations
Follow these steps to upload the donor data files to an Amazon S3 bucket:
- In the AWS Management Console, type “S3” in the search bar and select the Amazon S3 service.
- Choose Create Bucket.
- For Bucket name, enter
kendra-docs-us-${AccountID}, as shown in the following screenshot. Replace{AccountID}with your own information and leave every other thing as default. - Scroll down and choose Create bucket.
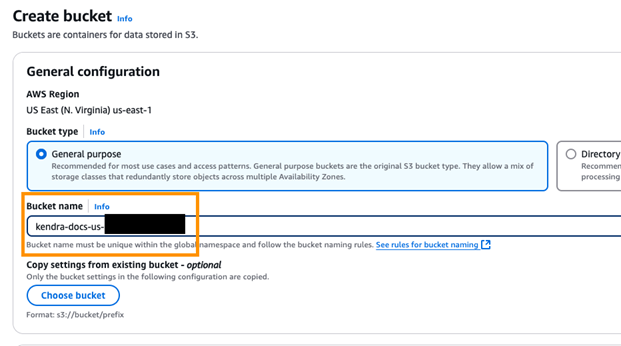
Figure 2. Enter a bucket name
- Under General purpose buckets, select k
endra-docs-us-${AccountID}. Replace{AccountID}with your own information. - Choose Upload.
- In Upload, choose Add Files and select the files you want to upload to the bucket.
- Choose Upload to save.
- After the upload is complete, you should see the uploaded files listed on the bucket details page.
Provision Amazon Bedrock model access
Before using LLMs, you need to configure model access permissions. Here are the setup steps:
- On the AWS Management Console, type “Amazon Bedrock” in the search bar to navigate to the Amazon Bedrock console page.
- On the Amazon Bedrock console, choose Get started.
- In the left navigation pane, under Bedrock configurations, select Model access, as shown in the following screenshot.
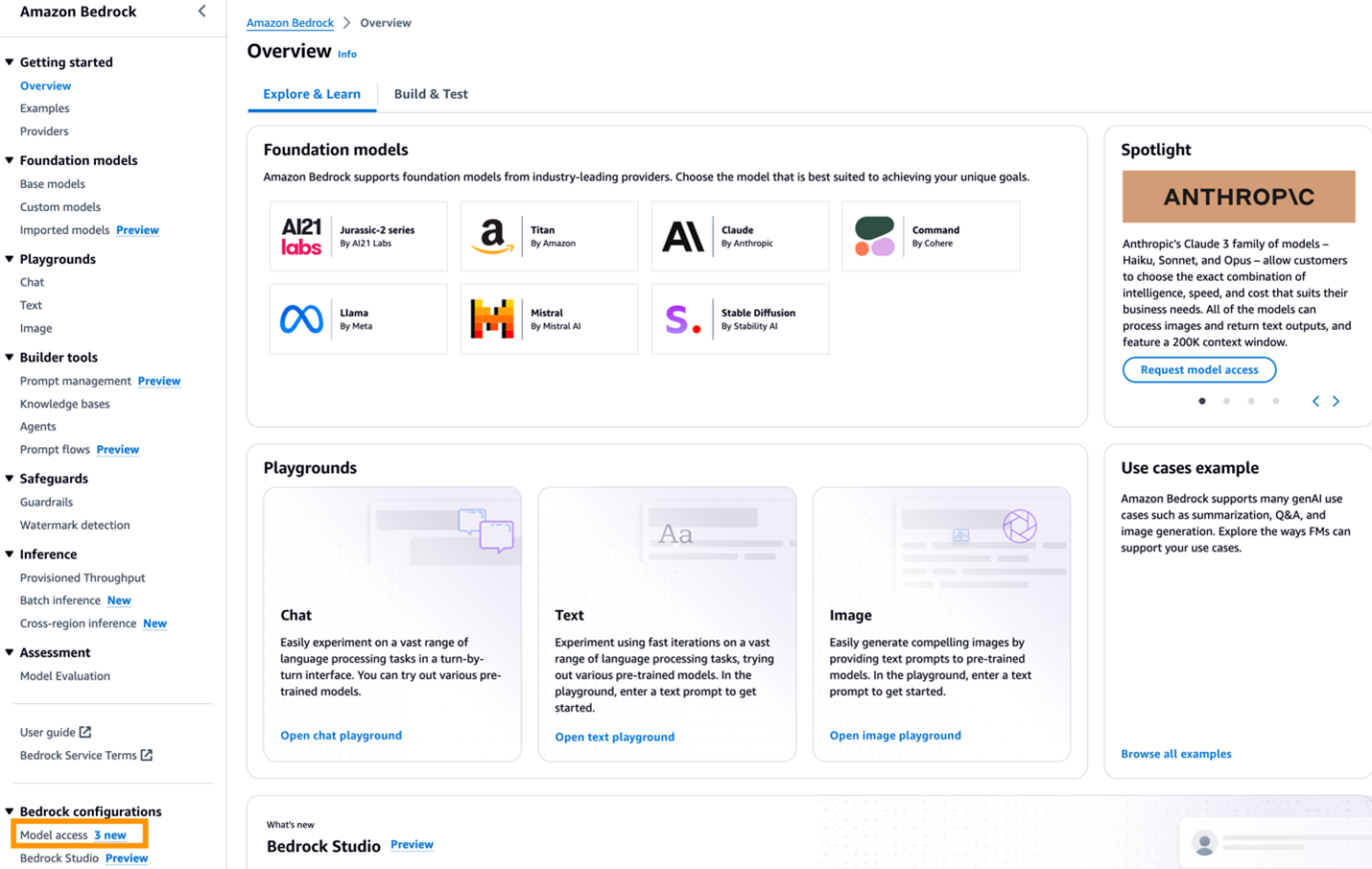
Figure 3. Model access
- Under What is Model access? choose Enable specific models.
- Under Anthropic, select Claude Instant. Then choose Next.
- On the Review and submit screen, to review and submit model, select Submit. This process takes less than 2 minutes. When the access request is granted, the status will show as Access granted.
Create Amazon Kendra index
Amazon Kendra is an intelligent search service that helps find relevant information from your documents. It works by:
- Creating a searchable index of your documents
- Connecting to data sources that store your documents
- Allowing direct document uploads using an API
The service can automatically sync with your data sources to keep the index current. In this section, Amazon Kendra index is synced after data has been added to your data source. Follow these steps:
- On the AWS Management Console, in the search bar, type “Amazon Kendra” and navigate to the Amazon Kendra
- On the Amazon Kendra console, choose Create an Index.
- In Specify index details, under Index name, enter
MyKendraIndex. - Under IAM role, choose Create a new role (Recommended) and name it.
- Choose Next, as shown in the following screenshot.
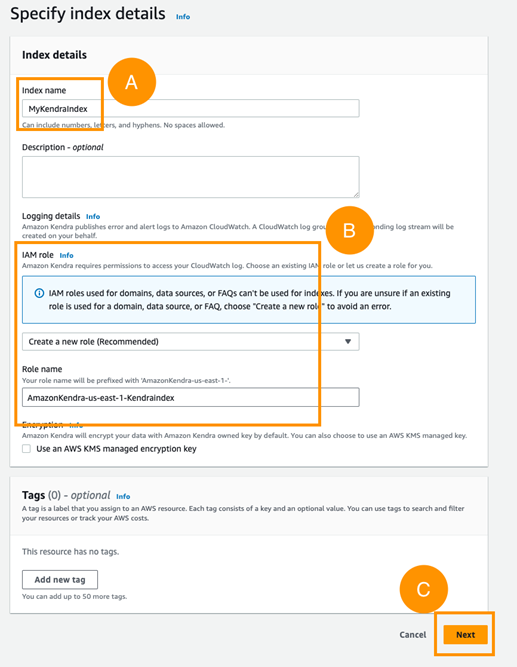
Figure 4. Naming and setting up the IAM role for your index
- Choose Next on the next screens until you reach the Review and create screen, then choose Create. It takes about 30 minutes for the index to be created.
- On the MyKendraIndex page, in the left navigation pane, under Data management select Data sources.
- On the Data sources page, choose Add connector button, as shown in the following screenshot. You need to wait for your index to finish creating before adding a data source.
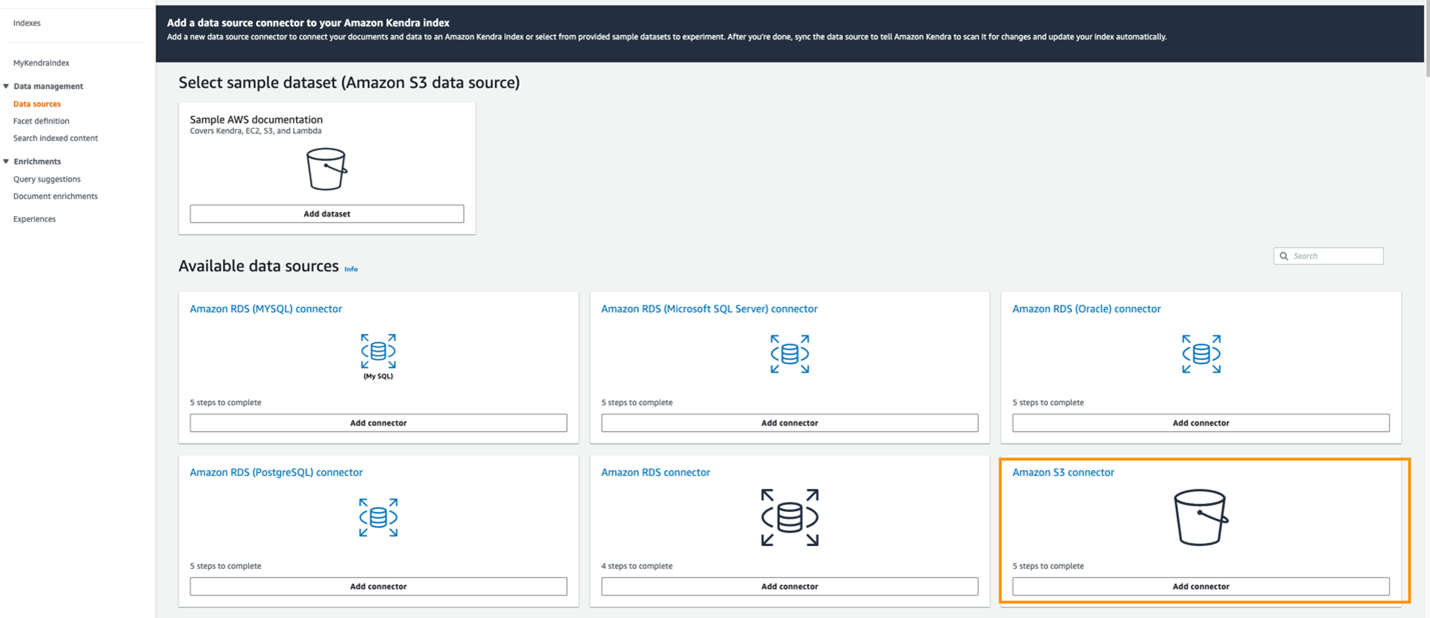
Figure 5. Adding an Amazon S3 connector
- In the Specify data source details section, in Data source name, enter
S3DataSource. Choose Next. - In the IAM role section, select Create a new role (Recommended) and enter a Role Choose Next.
- In the Configure sync settings section, choose Browse S3 and select
kendra-docs-us-${Account-ID}. - Under Sync run schedule, select Run on demand and choose Next, as shown in the following screenshot.
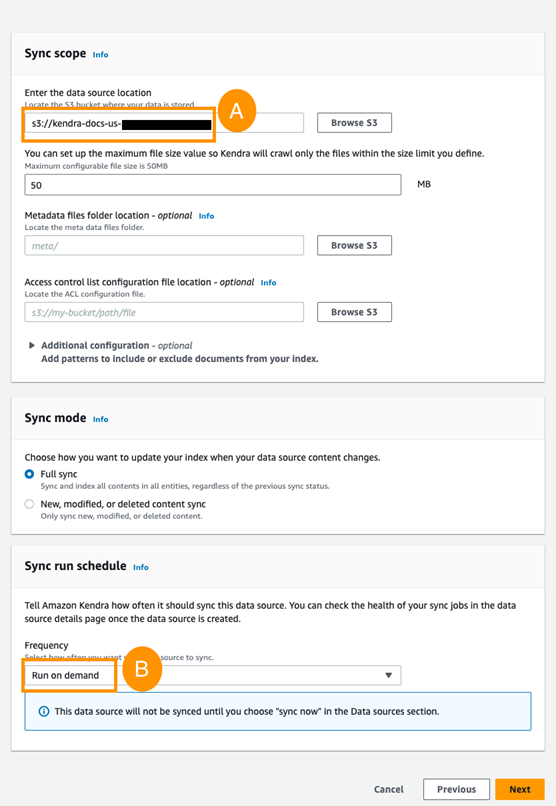
Figure 6. Specifying the data source location and frequency
- Choose Next on the next screens until you can choose Add data source, as shown in the following screenshot.
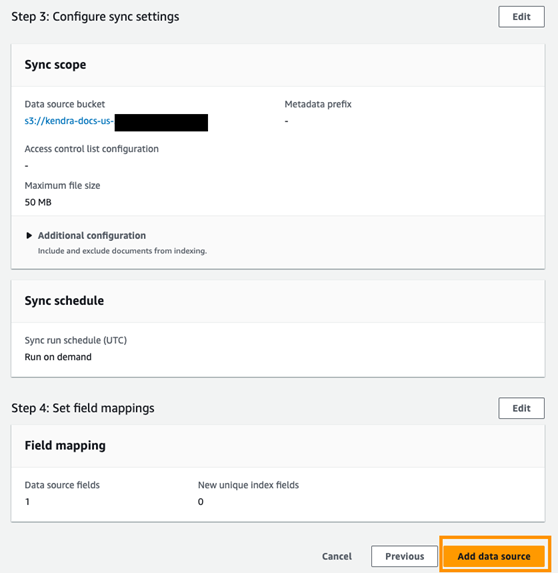
Figure 7. Add data source
- Under Data sources, select S3DataSource and choose Sync now to sync your data source with the Amazon Kendra index.
This will allow Amazon Kendra to crawl and index the files you just uploaded to Amazon S3. Allow about 2 minutes for this process to complete. The Current sync state will display a status of syncing-crawling or syncing-indexing and will change to Idle when the process is completed.
Access Amazon SageMaker Canvas for generative AI apps
To access Amazon SageMaker Canvas for generative AI apps, follow these steps:
- In the search bar, type “SageMaker” and select Amazon SageMaker AI to navigate to the Amazon SageMaker console page.
- On the Amazon SageMaker AI console, under New to SageMaker AI? choose Set up for single user.
- Under Domain details, select App Configurations tab.
- Under Canvas configuration, choose Edit, as shown in the following screenshot.
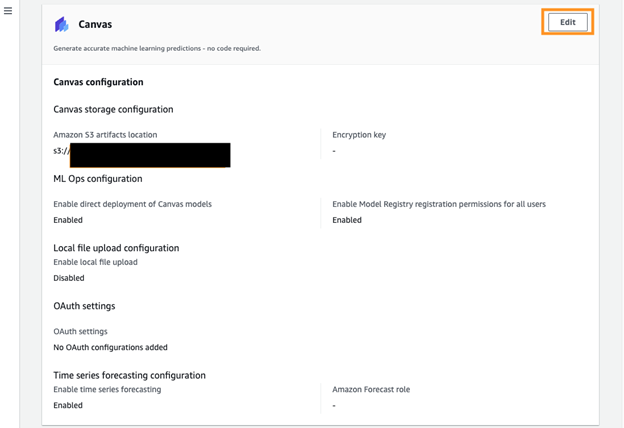
Figure 8. Canvas configuration
- Under Canvas storage configuration, select System managed as the Amazon S3 artifacts location.
- Under Canvas Ready-to-use models configuration, turn on Enable document query using Amazon Kendra.
- Choose
MyKendraIndex. - Under Amazon Bedrock role, turn on Create and use a new execution role, as shown in the following screenshot.
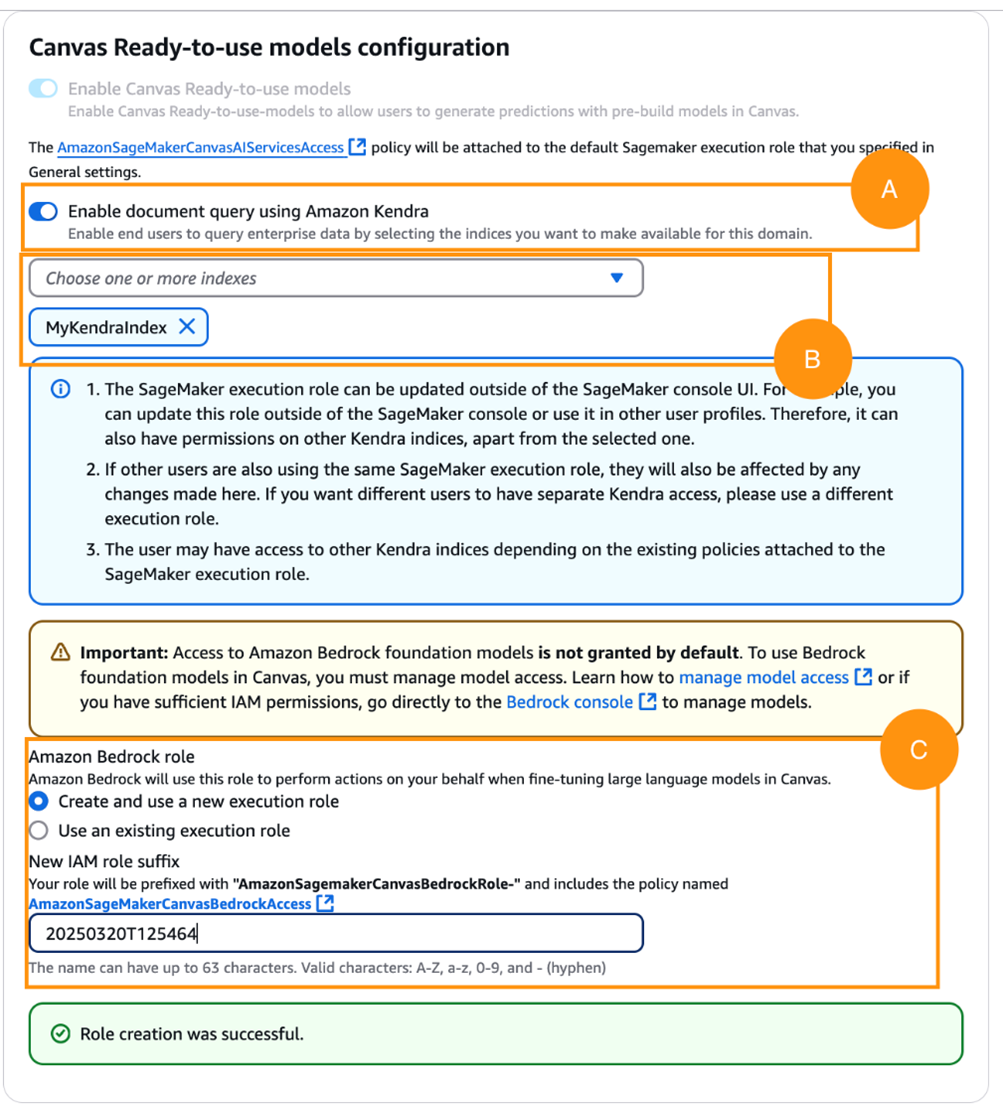
Figure 9. Turn on querying with Amazon Kendra and create a role for Amazon Bedrock
- Leave the other settings as default and choose Submit
- In the dialog box, choose Yes, Confirm change.
- Type “confirm” in the confirmation field and choose Submit.
Using Amazon SageMaker Canvas generative AI
This section explores how to interact with FMs using natural language and helps you evaluate different models to find the best fit for your specific needs through question-based comparison.
- On the SageMaker Canvas console, in the navigation pane under Application and IDEs, choose Canvas, as shown in the following screenshot.
Figure 10. Choose Canvas on the SageMaker AI console
- Choose Create user profile.
- Choose Next on the next screens until the review page. Scroll to the bottom and choose Submit.
- Choose Open Canvas.
- On the Amazon SageMaker Canvas page, in the left navigation pane, select Gen AI, as shown in the following screenshot.
Figure 11. Select Gen AI
- On the Generative AI page, select Query documents.
Figure 12. Query documents
- Under Select a foundation model, select Claude Instant and choose Select, as shown in the following screenshot.
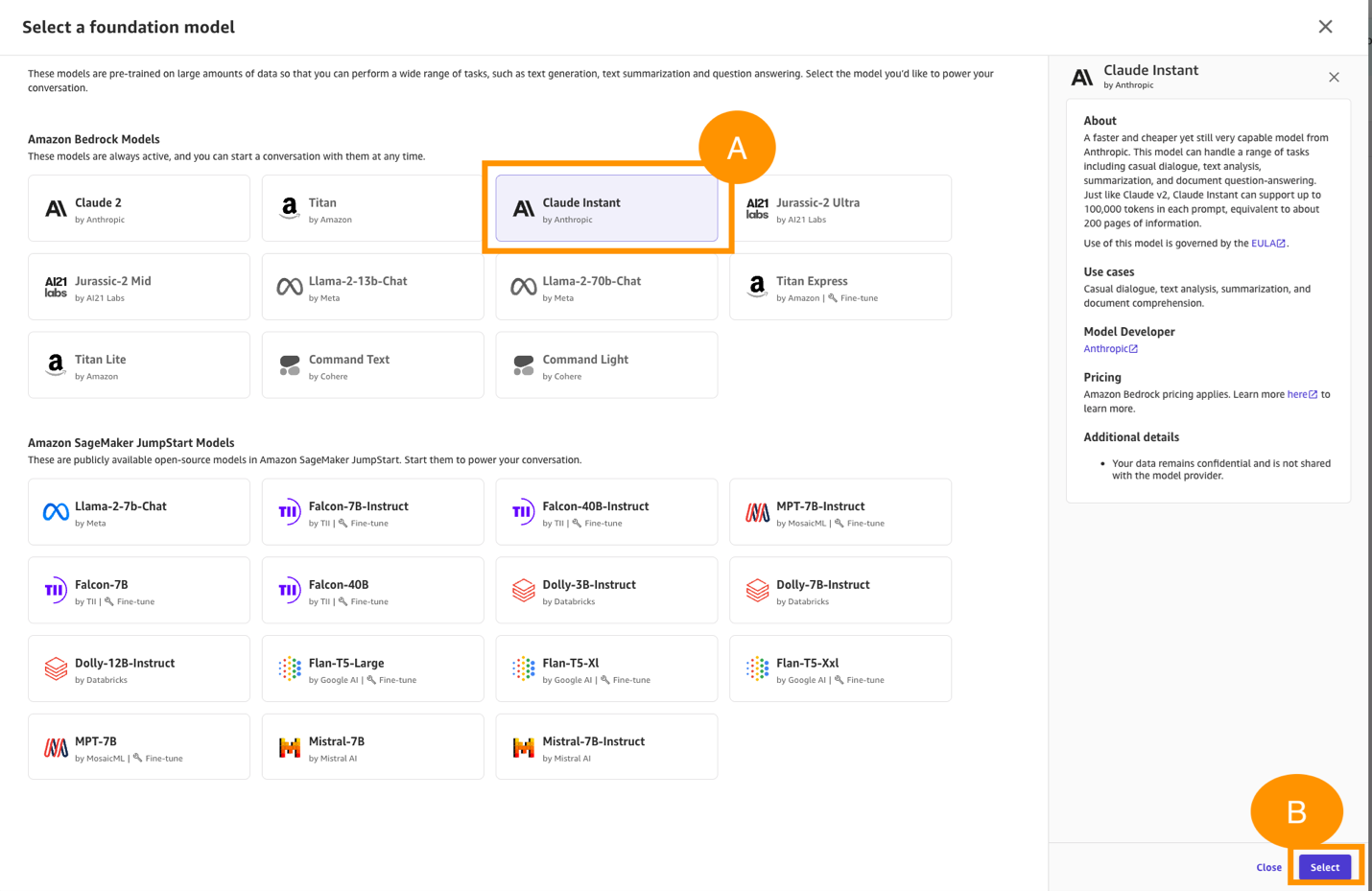
Figure 13. Select Claude Instant as the foundation model
- In the dropdown menu, select
MyKendraIndex. - Enter your question in the Ask me anything… field.
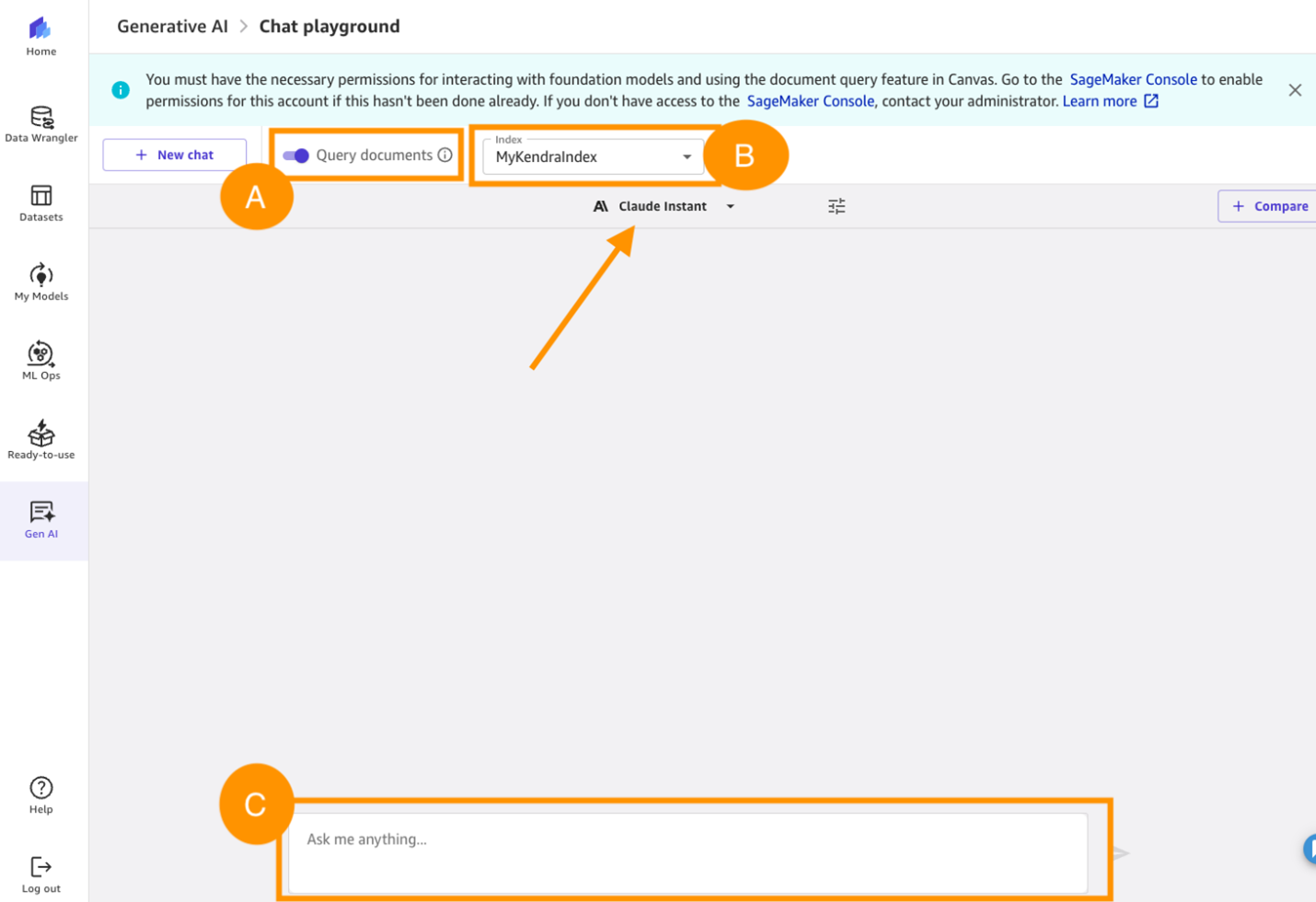
Figure 14. How to query documents
Summarize donor profiles for a nonprofit
To test the responses of the chat assistant, follow these steps:
- Enter the following prompt in the Ask me anything… field:
What are the defining characteristics of non-profit organizations and how do these attributes make them effective in social security roles?
When the assistant replies, you can select the download icon to download the generated content, as shown in the following screenshot.
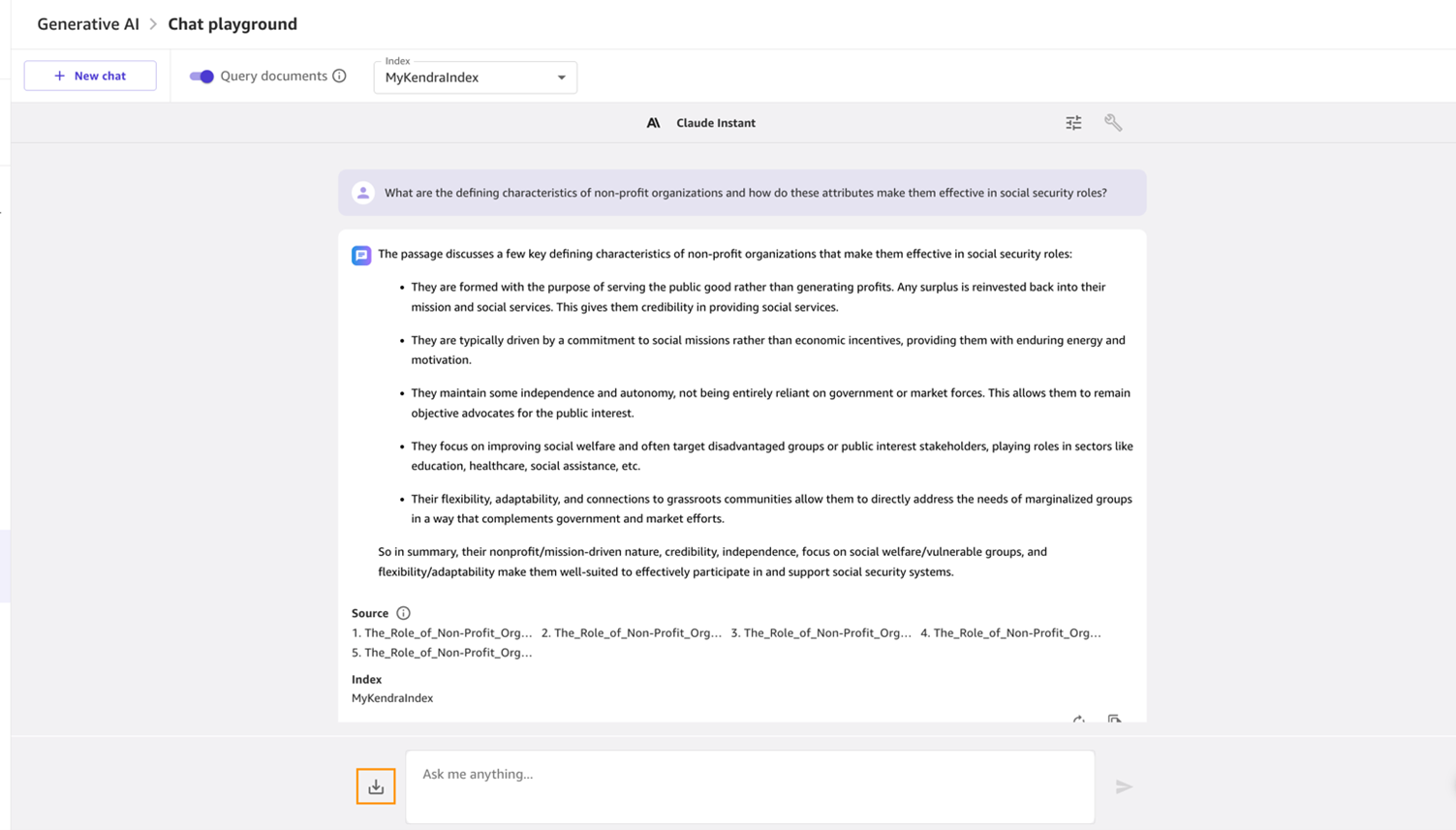
Figure 15. The chat assistant replies, and you can download the content
2. To start a new conversation, choose New chat.
3. Enter the following prompt: How can small nonprofits with limited resources still incorporate personalization into their donor engagement strategy? What are some simple first steps to take?
After the model responds, if you want the model to generate another output, choose the regenerate icon (marked as A in Figure 15). To copy the content generated by the model, use the copy icon (marked as B in Figure 15).
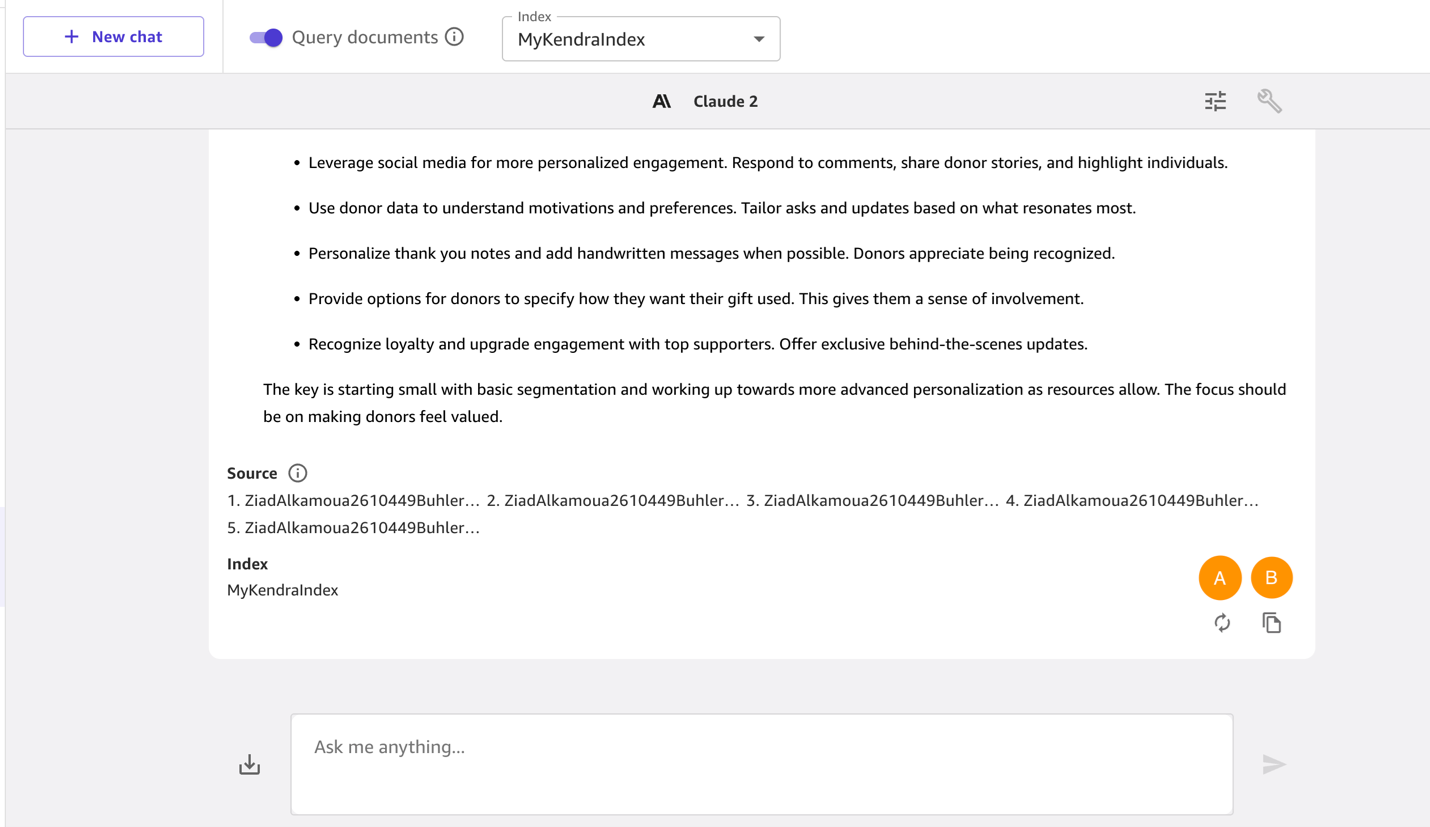
Figure 16. You can copy the response or tell the model to regenerate it
Conclusion
Amazon SageMaker Canvas provides a streamlined approach to implementing AI solutions without requiring deep technical expertise. Through a simplified interface, you can access and compare FMs from Amazon Bedrock and Amazon SageMaker JumpStart. The integration with Amazon Kendra enables document-based queries and RAG, providing source-verified responses and reliable AI implementations. Through this architecture, organizations can implement enterprise-grade AI solutions while maintaining data accuracy and reliability. The combination of these AWS services creates a comprehensive framework for democratizing AI, enabling fine-grained control over model selection and providing accessible, production-ready implementations.