AWS Public Sector Blog
Aligning education state standards to content for K12 with GraphRAG on AWS

In the K12 education sector, where education technology (EdTech) companies serve millions of students, the manual alignment of educational content to state standards creates significant operational bottlenecks and quality concerns. Content teams managing vast repositories of assessment items across hundreds of courses face a labor-intensive process that impacts both efficiency and educational outcomes. The current manual approach requires subject matter experts to meticulously examine and map each piece of content to specific learning standards—a task made more complex by varying state requirements and annual standard updates. Without automated solutions, content teams rely on basic tools such as spreadsheets, leading to inconsistencies, duplicated efforts, and delayed response times to market demands.
The challenge intensifies when dealing with cross-subject content or when standards undergo revisions, forcing teams to repeatedly modify existing materials. This manual process not only consumes valuable time that could be spent on content creation and improvement, but also increases the risk of alignment errors that directly affect student learning. The lack of standardized tools and interoperability between content platforms and standards databases makes it difficult to scale alignment efforts efficiently. For EdTech providers, this translates to slower product development cycles, increased operational costs, and challenges in rapidly responding to requests for proposal (RFPs). Most critically, these alignment inefficiencies hamper the ability to deliver personalized learning experiences that meet both student needs and compliance requirements.
In this post, we explore how we’re transforming educational content alignment by combining the graph database capabilities of Amazon Neptune with large language models (LLMs) accessible in Amazon Bedrock. With other Amazon Web Services (AWS) services, we will be moving beyond graph-based Retrieval Augmented Generation (GraphRAG) approaches. We will dive into the choice of this hybrid architecture for curriculum alignment challenges.
Solution architecture
The reference architecture presents a comprehensive cloud-native solution that addresses the core requirements while incorporating scalability, adaptability, and responsible AI principles. At its heart, the system uses Amazon Neptune as a graph database to manage complex relationships between educational standards and content, enabling automatic mapping and quick incorporation of new standards. The frontend layer combines static Amazon Simple Storage Service (Amazon S3) hosting with, for example, TypeScript to provide a robust, user-friendly interface for reviewing and adjusting AI-generated alignments.
The solution’s scalability is provided through multiple components: Amazon CloudFront for content delivery, Application Load Balancer for traffic distribution, and containerized services running on AWS Fargate for both REST API and asynchronous processing. The system’s adaptability is demonstrated through its microservices architecture, with distinct Amazon Simple Queue Service (Amazon SQS) queues (such as Injest, Enrich, Align, or Review) managing different aspects of content processing. This separation of concerns allows for independent scaling and updating of components as requirements evolve. The architecture provides secure processing through a Amazon Virtual Private Cloud (Amazon VPC) endpoint with private subnet configuration, while Amazon Cognito handles authentication and access control, meeting enterprise security standards.
The solution incorporates responsible AI principles through several key mechanisms. The LLM and embedding model, Amazon Bedrock, works in conjunction with Amazon OpenSearch Service as a vector store to provide intelligent content analysis while maintaining transparency and explainability in its decisions. The architecture implements a human-in-the-loop approach through its review and validation workflows so that AI-generated alignments are verified by subject matter experts before being finalized. This approach is crucial for maintaining accuracy and addressing potential biases in the AI system. The solution’s monitoring and feedback loop, implemented through Amazon CloudWatch logs and the API, enables continuous learning and improvement of the AI model based on expert feedback. The system’s ability to handle multiple content types (text, video, interactive elements, and images) is supported by the async workers running on Fargate, while the Amazon Elastic Container Registry (Amazon ECR) facilitates rapid deployment of worker engines.
Since we’re working with structured inputs, applying RAG semantics directly would have introduced unnecessary complexity and risk by offloading schema inference burden on the LLM. The model would be required to infer structure, relationships, and context from flattened or serialized text. This increases risk of hallucination and reduces accuracy, transparency and control. Therefore, the recommended approach in the architecture is to combine a graph database (Amazon Neptune) with Retrieval Augmented Generation (RAG), (hence, GraphRAG), because it offers a scalable and semantically rich framework. Using this hybrid approach, we model relationships explicitly while using RAG to deliver context-aware responses, making it a strong fit for both engineering reliability and product impact.
This comprehensive approach is designed so that the solution can scale effectively while maintaining high standards of accuracy and responsibility in its AI-driven decisions, making it suitable for enterprise-level educational content alignment needs.
In the reference architecture, the current school curriculum (including subjects, lessons, topics, and standards) is assumed to be in a relational database and accessible using an API such as MySQL with Amazon Elastic Compute Cloud (Amazon EC2) or Amazon Relational Database Service (Amazon RDS). (Data preparation, data engineering, extraction, and transformation of data from the relational system into Amazon Neptune is outside the scope of this post.)
The following diagram illustrates the solution architecture.
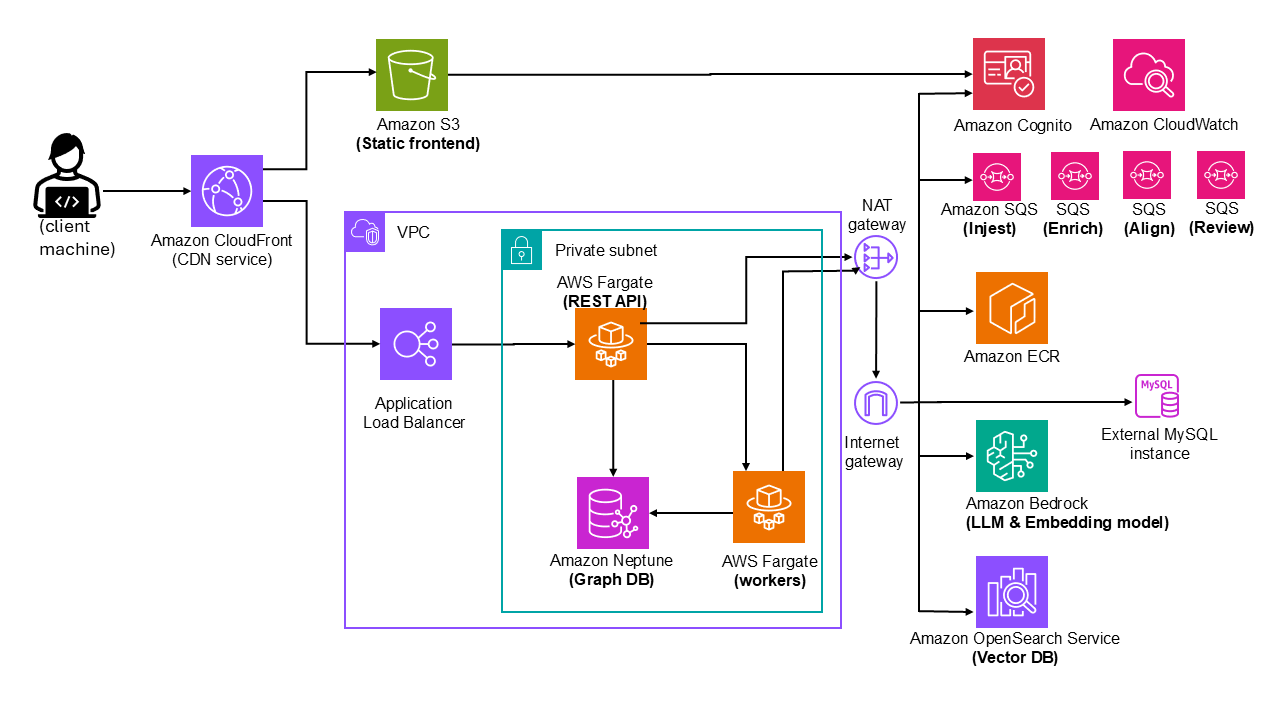
Figure 1. Diagram showing the solution architecture
Context workflow
The end-to-end workflow for aligning educational content with academic standards is built around four key stages: ingest, enrich, align, and review. These stages are designed to scale across thousands of educational elements and multiple sets of standards while maintaining transparency, reusability, and human validation.
Ingest
The purpose of this phase is to transform structured content and standards trees from relational format into graph and vector structures. In education, content and standards are typically maintained in structured relational databases.
Note: It may be possible that in the education domain, critical elements such as content, academic standards, student progress, lessons, and assessments often inherently interconnected are already modeled as graph relationships in a graph database like Amazon Neptune or similar. In such a situation, customers can bring their own graph data as custom “bring-your-own Knowledge Graphs” (BYOKG) to retrieve relevant context, enabling LLM to generate more accurate answers and reduced overhead. The details of the BYOKG are outside the scope of this blog and will be covered in a later post.
In our reference architecture the ingestion step involves extraction and transforming these structured relational systems in graph trees into a dual-representation system consisting of a graph structure (Amazon Neptune) to capture parent-child relationships and support topological reasoning and a vectorized representation (OpenSearch Service) to enable semantic similarity searches.
The key steps in the ingest phase are as follows:
- The worker nodes connect to relational data API to retrieve hierarchical JSON trees for either subjects, lessons, and topics or for standards.
- The Fargate worker’s break down each node from JSON to edges.
- A job is placed on the ingest SQS queue, including metadata such as ID course_101, tree root ID, type (content or standard), and schema version.
- Fargate worker nodes are subscribed to the ingest queue:
- The worker nodes retrieve the tree using internal APIs.
- The workers then parse and load structural identity (for example, lessonID_123) nodes into Amazon Neptune (for graph structure).
- They workers store raw content (for example, descriptions, instructions, and metadata) in OpenSearch Service under original_content.
- The Vector field is then initialized as a zero-vector placeholder (to be enriched later).
Why it matters: This separation maintains both structural fidelity (which lesson belongs to which unit) and semantic representation (what the lesson is about), enabling powerful hybrid search and retrieval downstream.
Enrich
The purpose of the enrich phase is to add semantic meaning to nodes through LLMs accessible using Amazon Bedrock. Descriptions, learning goals (often referred to as competencies in educational settings), and vector embeddings are added to raw educational content to facilitate matching and reuse. The enrichment process typically has three steps:
- Describe
- List competencies
- Embed
The objective of the describe step is to use LLMs with Amazon Bedrock to summarize and contextualize each node. It operates in a bottom-up fashion in which it starts with leaf nodes such as slides or activities, then summarizes parents using the already summarized children. This prevents repeated LLM calls on duplicate material and produces an llm_description field that standardizes language across disparate materials.
The objective of listing the competencies is to extract latent learning goals embedded in the content. LLMs are prompted to generate abstract educational competencies the content addresses. These aren’t tied to a standards framework (such as Common Core or California Common Core State Standards), allowing alignment across different systems. The following is an example output:
``json
[
"Solving multi-step word problems using whole numbers",
"Interpreting data from bar graphs and tables",
"Applying estimation strategies in real-world scenarios"
]
``
The embed step converts competencies into high-dimensional vectors through embeddings models. Workers concatenate competency lists and use Amazon Bedrock for embedding generation, storing them in OpenSearch Service, the vector database in the reference architecture. This enables efficient similarity-based retrieval for alignment tasks. The embedding process starts when ingestion completes, with enrichment triggering for each subtree, such as lessons or topics. The API sends a message containing the root node ID to the enrich SQS queue. Fargate workers then pick up the job and execute several key operations: they traverse child nodes in a bottom-up manner, query Amazon Bedrock LLM for node descriptions and educational competencies, and use Amazon Bedrock’s embedding model to create vector representations. Finally, Fargate workers write the enriched data to OpenSearch Service, completing the embedding process.
Why this matters: By stripping away standards-specific language and surfacing generalized learning goals, we can map content to any standards tree—past, present, or future.
Align
The purpose of the align phase is to map content to standards using semantic similarity and LLM judgment from Amazon Bedrock. The alignment process primarily works in three main steps. First, we perform vector prefiltering and retrieve about 40 semantically similar standard nodes for each content node. This helps to filter out irrelevant standards early. This improves the performance and accuracy of the alignment.
Next, we conduct LLM judgment. We show the content and filtered standards list to the LLM, which sorts them into alignment levels. It marks each match as strong, moderate, weak, or not aligned.
Finally, we create edge inferences. We add labeled edges with confidence tags in Amazon Neptune. These edges help us generate reports and guide human review of the matches.
The align phase follows these key steps:
- The API queues an alignment job (for example, align lesson 201 with California math standards) to the align SQS queue.
- A Fargate worker retrieves enriched content and standards from OpenSearch Service and Amazon Neptune.
- The Fargate worker runs vector similarity search and creates a short list of candidates (for example, 40 nodes).
- The Fargate worker prompts the Amazon Bedrock LLM to evaluate relevance and categorize each node as strong, moderate, weak, or none.
- The Fargate worker writes inferred edges with labels and confidence scores back into Amazon Neptune.
Why it matters: Education standards vary in wording, granularity, and taxonomy. These two-step semantic filtering and judgment process mappings are accurate, explainable, and context-aware.
Review
The review phase ensures human-in-the-loop validation and quality assurance of AI-inferred alignments for trust and compliance. The UI is hosted in Amazon S3, allowing users to inspect and approve inferred edges, especially those marked as strongly aligned. Users can then queue batch review prefetching using a review SQS queue, which decouples real-time UI review from backend traversal and filtering. Workers retrieve and preload sets of inferred edges (for example, the top 10 “strongly aligned” per lesson) into a cache layer or summary document. From their UI experience, users can confirm mappings, which can be stored with prefixes in Amazon Neptune. This workflow significantly reduces manual review by focusing on the most likely candidates instead of a high number of possibilities.
This workflow reduces manual review from high number of possibilities to just the most likely candidates.
Why it matters: The review phase provides accountability in use cases—educational alignment impacts compliance reporting, instructional design, and ultimately student learning outcomes.
Reporting (optional)
The reporting phase helps educators generate exportable alignment reports (such as JSON or CSV files or spreadsheets) summarizing how content maps to standards to support compliance, curriculum planning, and content reuse. The key steps in reporting are as follows:
- When a user requests a report (such as coverage for grade 4), the request is posted to the report SQS queue (not shown in the reference architecture).
- A reporting Fargate worker traverses both trees from the specified roots.
- A reporting Fargate worker gathers confirmed edges and aggregates coverage stats.
- A reporting Fargate worker generates downloadable JSON files (or CSV if configured).
- A reporting Fargate worker stores the result in Amazon S3 and updates report availability in the UI.
Why it matters: Schools, districts, and states need traceable alignment data for audits, grants, curriculum development, and instructional improvement. Automating this reporting process provides significant time savings and accuracy improvements.
Summary
The reference architecture and end-to-end context workflow are purpose-built to solve persistent challenges in curriculum alignment by combining structured graph models, semantic embeddings, and asynchronous AI-driven processing.
The solution achieves scalability by aligning thousands of content items and standards across multiple jurisdictions through automated ingestion, enrichment, and alignment pipelines. It adapts by extracting generalized educational competencies and removing dependency on state-specific language, making it compatible with various learning taxonomies such as Common Core, Texas Essential Knowledge and Skills (TEKS), Next Generation Science Standards (NGSS), and custom district frameworks.
The solution also enables transparency by incorporating a human-in-the-loop review model, applying detailed edge labeling (e.g. inferred or confirmed), and tracking graph-based lineage. This makes each alignment decision explainable and auditable—crucial for educational accountability and reporting. By automating the alignment process and narrowing the review to a high-confidence subset of matches, it allows educators and content teams to focus on strategic curation instead of repetitive tagging.
If you’re facing the complexity of aligning diverse educational content to ever-evolving standards, this reference architecture offers a proven, scalable, and intelligent path forward that you can use as your launch pad.