AWS Open Source Blog
Category: Artificial Intelligence

Embracing natural language processing with Hugging Face
In a previous post, I talked about how open source projects often work backwards from a specific problem or challenge, as one of their key motivators. In this post, I’ll explore another area where open source projects emerge: the need to follow an area of interest, a genuine passion, or an itch that needs to […]

Creating a bridge between machine learning and quantum computing with PennyLane
In this post, Josh Izaac (Xanadu) and Eric Kessler (AWS) explain how the open source PennyLane project helps bridge the gap between the quantum computing and machine learning communities. Today, we are announcing that AWS is joining the steering council of the PennyLane open source project for variational quantum computing and quantum machine learning. Our […]

Deploy fast.ai-trained PyTorch model in TorchServe and host in Amazon SageMaker inference endpoint
Over the past few years, fast.ai has become one of the most cutting-edge, open source, deep learning frameworks and the go-to choice for many machine learning use cases based on PyTorch. It has not only democratized deep learning and made it approachable to general audiences, but fast.ai has also become a role model on how […]
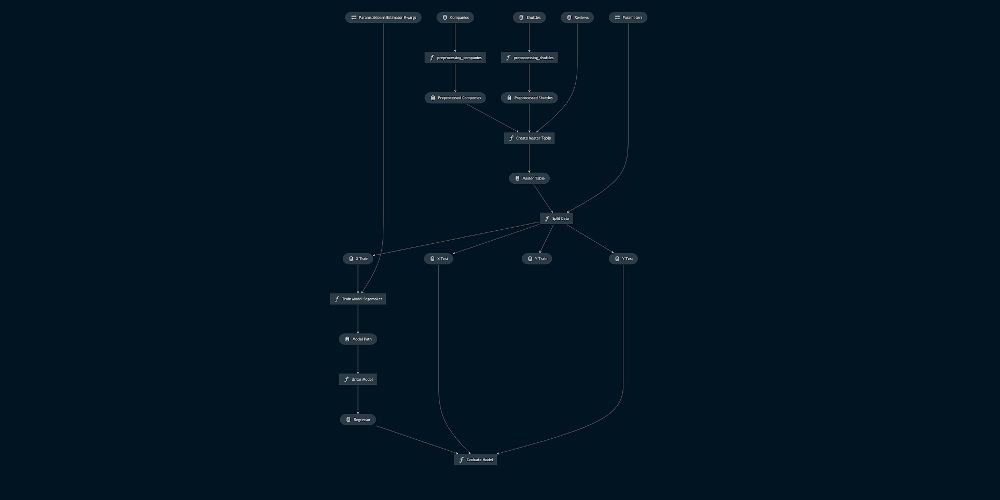
Using Kedro pipelines to train Amazon SageMaker models
Machine learning (ML) and artificial intelligence (AI) adoption is growing at nearly 25 percent per year in a variety of businesses, which results in data scientists and engineers building more analytical models per person with similar levels of resources as last year. To keep up with such high demand, builders need to remove manual and […]

Virtual GPU device plugin for inference workloads in Kubernetes
Machine learning (ML) has become a centerpiece for enterprise transformation. AWS provides a broad and deep set of ML capabilities for builders with all levels of expertise. Developers with no prior ML experience can seamlessly build sophisticated AI-driven applications using AWS AI services. Developers and data scientists can use Amazon SageMaker, a managed machine learning […]

How TalkingData uses AWS open source Deep Java Library with Apache Spark for machine learning inference at scale
This post is contributed by Xiaoyan Zhang, a Data Scientist from TalkingData. TalkingData is a data intelligence service provider that offers data products and services to provide businesses insights on consumer behavior, preferences, and trends. One of TalkingData’s core services is leveraging machine learning and deep learning models to predict consumer behaviors (e.g., likelihood of […]

Running TorchServe on Amazon Elastic Kubernetes Service
This article was contributed by Josiah Davis, Charles Frenzel, and Chen Wu. TorchServe is a model serving library that makes it easy to deploy and manage PyTorch models at scale in production environments. TorchServe removes the heavy lifting of deploying and serving PyTorch models with Kubernetes. TorchServe is built and maintained by AWS in collaboration […]

How Amazon retail systems run machine learning predictions with Apache Spark using Deep Java Library
Today more and more companies are taking a personalized approach to content and marketing. For example, retailers are personalizing product recommendations and promotions for customers. An important step toward providing personalized recommendations is to identify a customer’s propensity to take action for a certain category. This propensity is based on a customer’s preferences and past […]

How to deploy a live events solution built with the Amazon Chime SDK
In this tutorial, I will explain how to deploy an interactive live events solution with which speakers can present to a large pre-selected audience, and moderators can screen attendees to participate in the broadcast. This interactive live events solution, built with the Amazon Chime SDK, addresses many of the shortcomings of traditional online meeting platforms […]
Deploy machine learning models to Amazon SageMaker using the ezsmdeploy Python package and a few lines of code
Customers on AWS deploy trained machine learning (ML) and deep learning (DL) models in production using Amazon SageMaker, and using other services such as AWS Lambda, AWS Fargate, AWS Elastic Beanstalk, and Amazon Elastic Compute Cloud (Amazon EC2) to name a few. Amazon SageMaker provides SDKs and a console-only workflow to deploy trained models, and […]