Networking & Content Delivery
Best Practices to Optimize Failover Times for Overlay Tunnels on AWS Direct Connect
Introduction
Optimized failover times in hybrid connectivity are critical for meeting availability Key Performance Indicators (KPIs) in modern enterprise workloads. This is particularly important when implementing overlay tunnels over Amazon Web Services (AWS) Direct Connect, such as AWS Site-to-Site VPN using IPSec tunnels, or Connect Attachments using Generic Routing Encapsulation (GRE) tunnels. Proper configuration can reduce failover times from minutes to milliseconds, significantly improving network reliability. Following the ‘Anticipate Failure’ design principle from the Well-Architected Framework Operational Excellence pillar, this post outlines operational best practices to minimize downtime up to 99% while maintaining resilient network connections between on-premises and AWS environments. For example, our analysis shows that simply choosing unpinned over pinned tunnel configurations can reduce failover times by 33%.
A resilient Direct Connect infrastructure forms the foundation for highly available hybrid connectivity. Before diving into overlay tunnel optimization, readers should familiarize themselves with the Direct Connect Resiliency Toolkit and understand Active/Active and Active/Passive configurations. This post uses the Direct Connect High Resiliency: Multi-Site non Redundant Deployment model as the reference architecture to demonstrate these optimization techniques, as shown in the following figure.
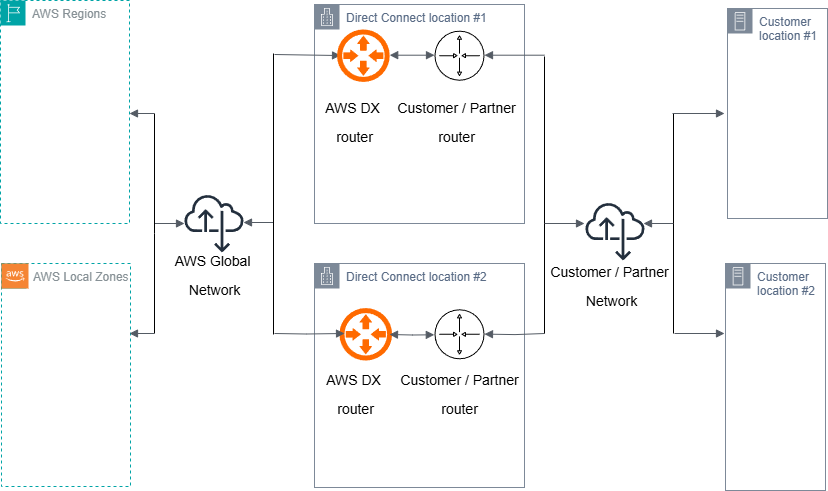
Figure 1: Direct Connect Connections with high resiliency model
When optimizing failover times for overlay tunnels on Direct Connect, there are two key aspects to consider:
- The underlying connection failover speed
- The overlay tunnel behavior.
First, we examine how to optimize BGP timers and implement BFD to improve the underlying Direct Connect failover detection and convergence. Then, we explore how different tunnel configuration approaches—pinned and unpinned—can significantly impact the overall failover performance. Although BGP timer optimization helps detect failures faster at the Direct Connect level, the tunnel configuration strategy determines how quickly your overlay traffic can recover using alternate paths. Understanding and implementing both aspects is crucial for achieving optimal failover times in your hybrid network architecture.
Direct Connect needs Virtual Interfaces (VIFs), which can be either Public, Private, or Transit. Creating a Direct Connect VIF involves two key steps: exchanging VLAN tags and establishing Border Gateway Protocol (BGP) sessions. If you want to learn more about Direct Connect VIFs, then you can refer to our documentation.
In this post we focus on the following two options:
- BGP hold timers
- Tunneling over Direct Connect
BGP timers and their effects on failover timing
Direct Connect VIF failover times primarily depend on BGP failover timing. There are two key timers to consider:
- BGP hold timer: This is the maximum time a BGP router waits to receive a keepalive or update message before declaring a peer dead and terminating the BGP session. On Direct Connect VIF, the default hold timer is 90 seconds, which can be reduced to a minimum of three seconds.
- BGP keepalive timer: This timer determines the interval at which a BGP router sends keepalive messages to its peers to maintain the BGP session and indicate active status. On Direct Connect VIF, the default keepalive timer is 30 seconds, which can be reduced to a minimum of one second.
To improve failover times, users can reduce BGP timers on their routers. AWS automatically negotiates to match these values upon receiving the BGP message. However, BGP timers cannot be configured through the AWS Management Console. Although reducing BGP timer values improves failover times, setting them too low is not recommended, because it may compromise network stability. Overly aggressive timer settings can cause unnecessary BGP session resets during brief network congestion or CPU spikes. Each reset triggers route re-convergence, which potentially impacts network stability and application traffic. This is especially critical in environments with multiple BGP sessions where router resources must be carefully managed.
For faster failure detection and failover, we recommend enabling Bidirectional Forwarding Detection (BFD). Asynchronous BFD is automatically enabled for Direct Connect VIFs on the AWS side. However, you must configure your router to enable asynchronous BFD for your Direct Connect connection. The following is a CLI configuration output showing how to enable BFD on a Cisco ASR 1002-HX device running IOS-XE 16.1.
In the preceding example, Link-Local address is shown. When configuring Direct Connect VIFs, you can specify your own IP addresses using RFC 1918 or use other addressing schemes or opt for AWS assigned IPv4 /29 CIDR addresses. These CIDR addresses are allocated from the RFC 3927 169.254.0.0/16 IPv4 Link-Local range for point-to-point connectivity. These point-to-point connections should be used exclusively for eBGP peering between your customer gateway router and the Direct Connect endpoint. For VPC traffic or tunnelling purposes, such as Site-to-Site Private IP VPN, or AWS Transit Gateway Connect, AWS recommends using a loopback or LAN interface on your customer gateway router as the source or destination address instead of the point-to-point connections. Refer to the Direct Connect documentation for more details.
The key BFD components that affect failover times are:
- Minimum liveness detection interval: This is the minimum interval between received BFD control packets that your router should expect. A shorter interval enables faster failure detection but increases CPU overhead. On Direct Connect, the minimum supported value is 300 msec.
- Minimum BFD multiplier: This is the number of BFD packets that can be missed before a session is declared down. The total failure detection time is determined by multiplying this value by the detection interval. The minimum supported value is 3 (three).
Using BFD on Direct Connect VIFs significantly reduces failover times. A comparison using minimum supported configurable values shows:
- Without BFD: BGP failover time = 3 seconds
- With BFD: Failover time = 3 * 300 ms (0.9 seconds)
This represents a 70% reduction in failover time, making BFD a significantly more efficient solution for failure detection and recovery.
Make sure to consult your network hardware vendor to determine the minimum recommended values of BGP timers and BFD settings for your specific equipment. For detailed information about BFD, refer to RFC5880.
Tunneling over Direct Connect
Direct Connect functions as an underlay connection for users who implement overlay tunnels (Site-to-Site VPN or Connect Attachments) to Transit Gateway. Although these overlay options provide enhanced connectivity features, they introduce more protocol dependencies and timing factors that affect the overall failover performance. Understanding these factors is essential for optimizing failover times in your hybrid network architecture.
Tunnel configuration approaches
In this section we cover two approaches:
- Pinned tunnels: In this configuration, the user side tunnels’ outside IP addresses are routed exclusively over a specific Direct Connect VIF, as shown in the following figure. This typically occurs when users use Direct Connect VIF interface IP addresses as the tunnel outside IP addresses. Users must advertise their Direct Connect VIF interface IP in the BGP session to AWS to make sure of tunnel endpoint reachability. Although AWS automatically advertises the tunnel endpoint IP (Transit Gateway CIDR) across all available redundant Direct Connect VIFs, users must configure appropriate BGP path selection attributes (such as local preference) to make sure of the symmetric routing of the tunnel.
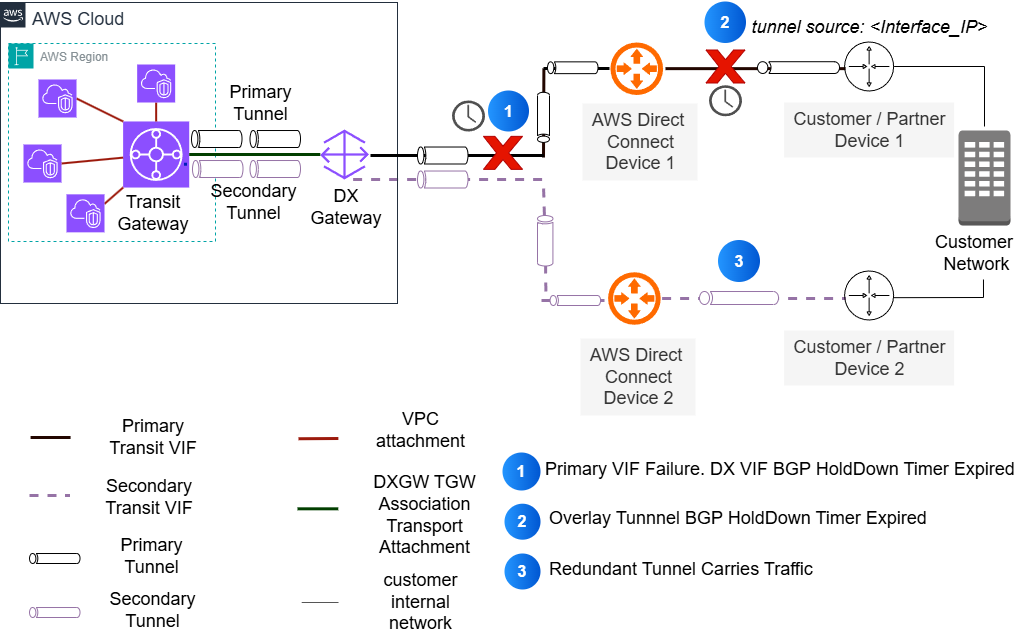
Figure 2: Interface pinned overlay tunnels on Direct Connect
The following is a sample configuration of an interface with pinned overlay tunnels on a Cisco ASR 1002-HX device running IOS-XE 16.1.
This ‘pinning’ of the tunnel to a specific connection has important failover implications. The tunnel is bound to a specific Direct Connect connection, thus traffic cannot immediately use the redundant path during an underlay connection failure. Failover needs the tunnel BGP session to detect the failure through BGP timer expiration. Traffic only fails over after the tunnel goes down. This approach can result in longer failover times. This is because the system must wait for both the underlying connection failure detection and the tunnel protocol timeout before data traffic can fail over to the redundant path.
- Unpinned tunnels: In this configuration, the tunnels’ outside IP addresses originate from logical interfaces (such as loopbacks) configured on user routers, as shown in the following figure. Both the AWS tunnel endpoint IP (Transit Gateway CIDR) and user router loopback IPs are reachable through all available Direct Connect VIFs. This setup necessitates proper configuration of BGP path attributes for advertised and received routes to ensure symmetric routing.
For traffic engineering the underlay path:
- On Public VIFs: Use AS_PATH prepend when advertising loopback routes
- On Private/Transit VIFs: Use BGP Local Preference communities when advertising loopback routes
Refer to Direct Connect routing policies and the BGP communities documentation for more detailed information.
This approach necessitates routing between the user’s redundant routers to exchange loopback reachability information, which is typically implemented through iBGP configuration. This routing is necessary for the loopbacks to be reachable from AWS over redundant Direct Connect VIFs.
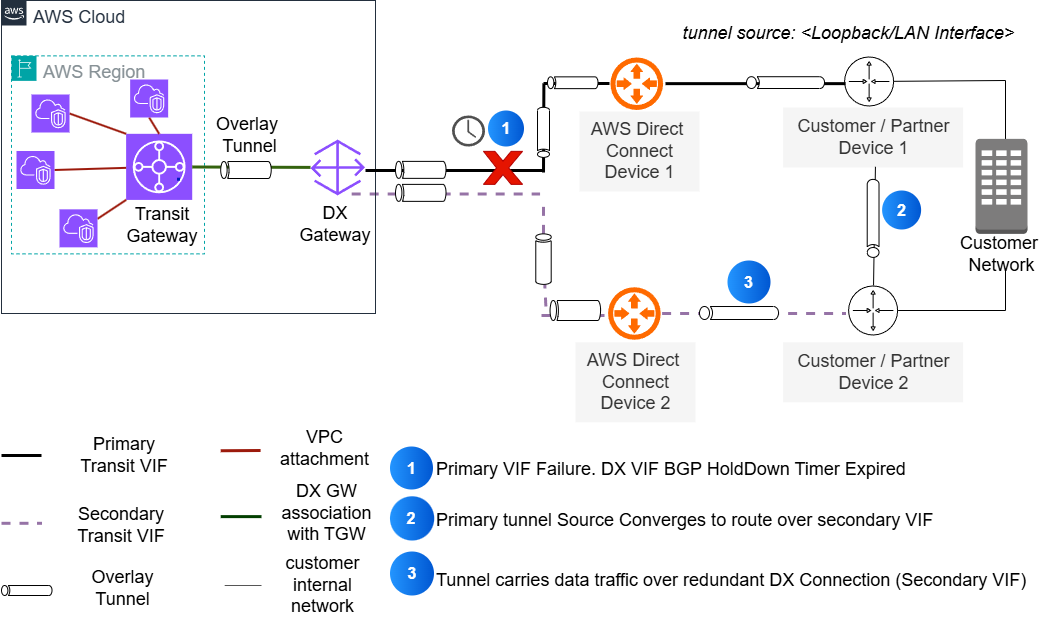
Figure 3: Unpinned overlay tunnels on Direct Connect
The following is a sample configuration of interface loopback sourced overlay tunnels on a Cisco ASR 1002-HX device running IOS-XE 16.1.
Failover time analysis
Different AWS tunneling services use distinct default BGP timer settings. We use Transit Gateway Connect attachments to compare failover times between pinned and unpinned configurations. Transit Gateway Connect uses different BGP timers than Direct Connect VIFs: a 10 second keepalive timeout and a 30 second hold timer. Although similar principles apply to Site-to-Site VPN, other factors such as Dead Peer Detection (DPD) influence failover timing. For DPD details, refer to the Site-to-Site VPN documentation.
To optimize failover times effectively, you must understand how different configurations of underlay and overlay components affect the total failover duration. In the following section, we examine various combinations of Direct Connect configurations (both with and without BFD) and their impact on both pinned and unpinned tunnel architectures.
Failover time comparisons
The following table shows a comparison between these options:
| Tunnel Config Type | Underlay DX VIF Failure Timers | Failure Time | Implementation Complexity | Notes | Considerations | ||
| Underlay (DX VIF) | Overlay (TGW Connect) | Total | |||||
| Pinned | Default BGP Timer | 90 sec | 30 sec | ~ 120 sec | Low | Failover Time = Underlay Failure Time + Overlay Tunnel | Slow Recovery |
| Minimum Supported BGP Timer | 3 sec | 30 sec | ~33 sec | Low | Increased BGP traffic | ||
| Minimum Supported BFD Timer (with multiplier) | 900 msec | 30 sec | ~30.9 sec | Medium | Requires supported hardware for BFD | ||
| Unpinned | Default BGP Timer | 90 sec | Not Triggered | ~90 sec | High | Failover Time = Underlay Failure Time | Complex internal routing |
| Minimum Supported BGP Timer | 3 sec | Not Triggered | ~ 3 sec | High | Increased BGP traffic | ||
| Minimum Supported BFD Timer (with multiplier) | 900 msec | Not Triggered | ~ 900 msec | High | BFD support required and complex internal routing | ||
As shown in the preceding comparison table, while both pinned and unpinned configurations can achieve sub-second failover times with BFD, the implementation complexity varies significantly. To help you successfully implement these optimizations in your environment, the following section examines key considerations that impact your deployment.
Considerations for implementation
When implementing these failover optimization techniques, consider the following key aspects:
- Performance and hardware
Actual failover times may vary based on router hardware capabilities and network complexity. BFD configurations need compatible hardware support and proper capacity planning for CPU and memory usage. Consult your network vendor’s documentation for specific convergence characteristics and recommended timer values.
- Architecture limitations
Although BFD significantly optimizes underlay failover detection, it can only be configured on the Direct Connect VIF, not on overlay tunnels. Remember that overlay tunnel headend failures still depend on tunnel BGP timers. When implementing aggressive timer settings, be aware that BGP session instability and asymmetric routing can occur if not properly configured.
- Implementation and validation
Success relies on methodical implementation and continuous validation. Start with conservative timer values and adjust gradually based on observed performance. Document your baseline failover times before making changes and implement optimizations incrementally. This begins with BGP timers, then enabling BFD if supported, and finally implementing your chosen tunnel configuration.
Regular testing using the Direct Connect failover test and monitoring through Amazon CloudWatch metrics, alongside device-level BFD and BGP state monitoring, help make sure that your configuration maintains optimal performance over time.
Conclusion
This post demonstrated how to optimize failover times for overlay tunnels on AWS Direct Connect. Our analysis shows that pinned tunnel configurations with default timers need 33% more time to fail over when compared to unpinned configurations. This is primarily due to overlay BGP session timeout dependencies. Implementing BFD with unpinned tunnels allows you to reduce failover time from 90 seconds to as low as 300 msec, thus achieving a 99% improvement in recovery time. For users implementing overlay tunnels on Direct Connect, we recommend using unpinned tunnel configurations to minimize impact during failure scenarios. Although this post has focused on underlay connection failure, the principles and configurations discussed can help you build more resilient hybrid network architecture.
For more information about Direct Connect configuration and resiliency options, refer to the Direct Connect User Guide.
An update was made on September, 15, 2025: An earlier version of this post omitted the BFD multiplier when calculating failure time. The post has been updated to correctly reflect the BFD multiplier in the failure time calculation.
About the authors

Azeem Ayaz
Azeem is a Sr Network Specialist TAM in AWS Enterprise Support, focusing on strategic enterprise customers and their complex cloud networking needs. With 13 years of experience in designing and operating network and security infrastructure, he specializes in crafting scalable architectures that help enterprises maximize their cloud investments and drive measurable business outcomes. Prior to AWS, he built his expertise at industry leaders including Vodafone, Cisco, and Juniper. When not architecting cloud solutions, Azeem enjoys strategic gaming and exploring new destinations with his partner.

Pavlos Kaimakis
Pavlos is a Senior Solutions Architect at AWS who helps customers design and implement business-critical solutions. With extensive experience in product development and customer support, he focuses on delivering scalable architectures that drive business value. Outside of work, Pavlos is an avid traveler who enjoys exploring new destinations and cultures.