Microsoft Workloads on AWS
Testing 3-tier Windows app resilience on AWS with Resilience Testing
Resilience testing has emerged as a critical practice for organizations seeking to build and maintain resilient cloud applications. As environments grow more complex, more comprehensive testing methods become necessary. Resilience testing principles can be applied to Windows workloads on AWS to create controlled experiments that test system behavior under stress. These experiments can help you in several ways. They can identify hidden vulnerabilities in application architecture and validate fail-over and recovery mechanisms. These experiments can also be used to improve incident response procedures while enhancing overall system reliability and performance.
In this post, we’ll explore how to apply resilience testing practices to Windows applications running on Amazon Elastic Compute Cloud (Amazon EC2). Using a traditional three-tier application as an example, we’ll examine two key scenarios:
- Testing web tier resilience by interrupting an Internet Information Services (IIS) application pool
- Verifying application behavior during a simulated database fail-over
We’ll discuss how to use AWS Fault Injection Service (FIS) as one of the tools available for implementing these tests, along with its integration with other AWS services. By the end of this post, you’ll have a better understanding of how to systematically test and improve the resilience of your Windows applications on AWS, helping your team build confidence in your systems’ ability to withstand unexpected events.
Overview
In this post, we’ll use a traditional three-tier Windows application as our example architecture. This common pattern consists of web, application, and data layers, with clients accessing the application through APIs or web services hosted on IIS servers. The application layer handles business logic and coordinates with a Microsoft SQL Server database running on Amazon Relational Database Service (Amazon RDS), which often includes Windows services for operations like batch processing and reporting. See Figure 1 for a logical diagram.
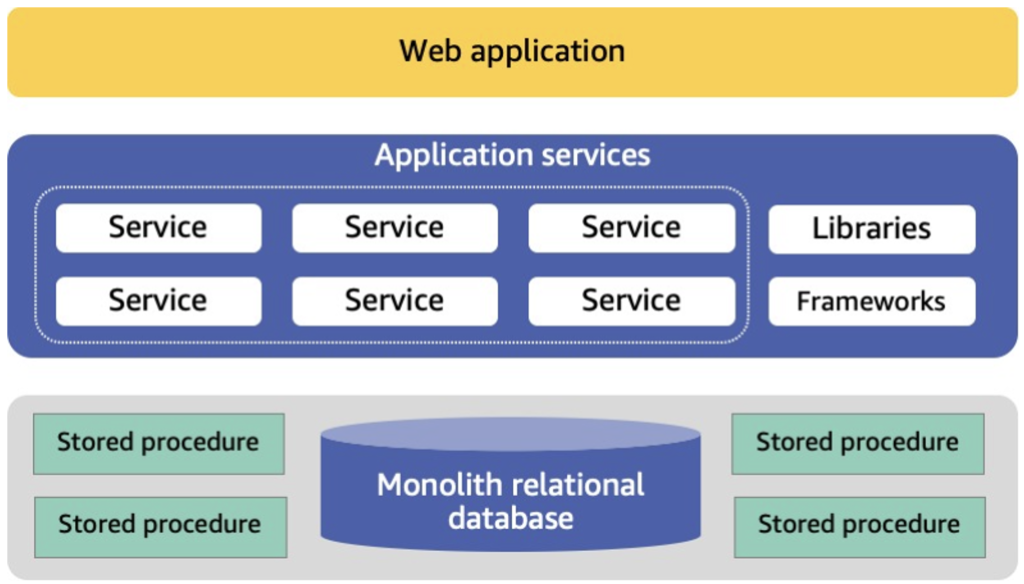
Figure 1: Logical Diagram
To test application resilience effectively, we need to simulate realistic failure scenarios in a controlled manner. We’ll demonstrate this using two complementary approaches:
Service-Level Testing: Using AWS Fault Injection Service (FIS) with AWS Systems Manager (SSM) to test application components. For example, we can use SSM Automation documents with PowerShell scripts to simulate web tier failures by stopping IIS application pools.
Infrastructure Testing: Leveraging FIS’s built-in integrations to test Amazon RDS for SQL Server fail-over scenarios. This allows us to trigger database fail-over events directly, simulating database availability issues in a Multi-AZ deployment.
Each experiment helps validate your application’s ability to detect issues and recover automatically. By running these controlled tests, you can identify potential weaknesses before they impact production workloads.
Scenario
You are a part of an engineering team which has migrated a business-critical windows-based application from on-premises to the AWS cloud. While the long-term strategy includes application modernization, the initial migration included replatforming efforts to leverage AWS managed load balancers and database services
The application consists of a load balancer, backed by a group of Windows-based EC2 instances with IIS enabled, and an Amazon RDS for SQL Server instance. See Figure 2, Application Architecture.
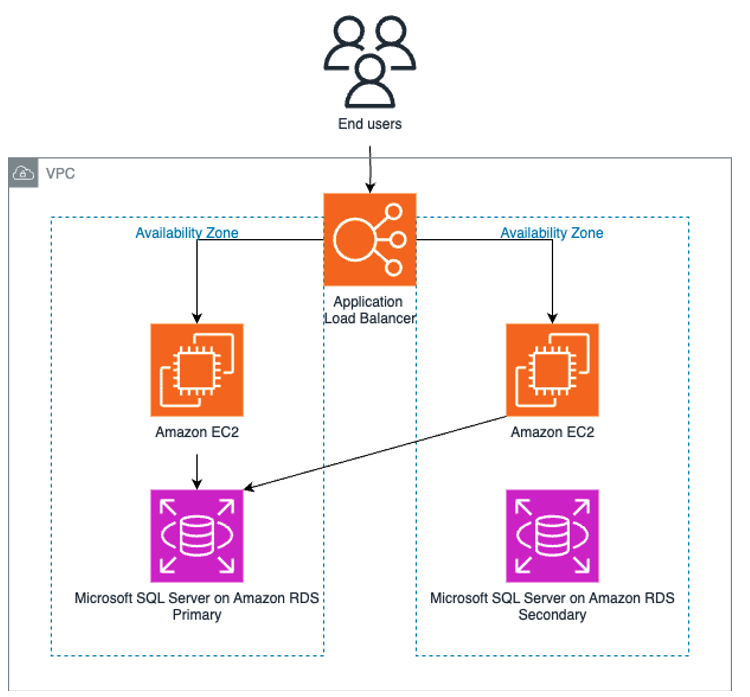
Figure 2: Application Architecture
Your task is to design and implement a series of controlled experiments to:
- Verify that the load balancer can effectively route traffic away from unhealthy instances
- Ensure that the application can handle the loss of an EC2 instance without significant impact to users
- Test the application’s ability to maintain operations during an RDS fail-over event
All of the experiments discussed in this blog are available in the console or through the FIS library. Please see this GitHub repository for detailed deployment instructions.
Experiment 1 – stop IIS web application pool
Windows-based applications traditionally leverage Internet Information Services (IIS) to host web services. When a web application is hosted on IIS, it runs within an application pool that manages its resources and isolation.
For this experiment, we’ll test how the application handles the failure of an IIS application pool on one of our web servers. We form the following hypothesis: If an IIS application pool on one of our web servers encounters an unexpected interruption (such as a simulated crash or resource exhaustion), then the load balancer will route traffic to the remaining healthy servers, allowing the application to continue operating without significant performance degradation.
When the experiment begins, FIS will search for the appropriate resources within the AWS environment. In this case, it will target one of the instances within an Auto Scaling group. This is based on the resource tag applied in the experiment.
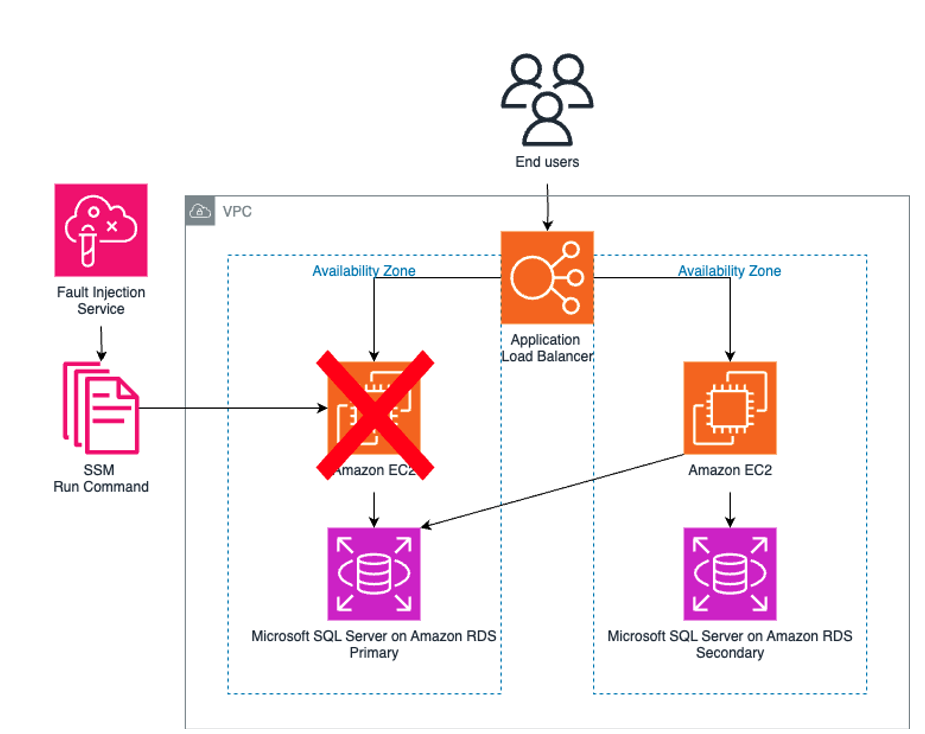
Figure 3: Experiment Overview
When running these experiments, ensure your system is experiencing representative load (through either real user traffic or synthetic load generation). Without adequate load on the system, you may not be able to properly observe the impact of the failure and validate your resilience mechanisms.
For the targeted compute, here is a sample of the PowerShell which will be used to stop and start an IIS web application pool:
try {
Write-Output "Getting IIS Application Pool: {{IISAppPoolName}}"
$appPool = Get-IISAppPool -Name {{IISAppPoolName}}
Write-Output "Stopping IIS Application Pool: {{IISAppPoolName}}"
$appPool | Stop-WebAppPool -Verbose
Write-Output "Sleeping for {{DurationSeconds}} seconds"
Start-Sleep -Seconds {{DurationSeconds}} -Verbose
}
catch {
Write-Output "Failed to stop IIS Application Pool: {{IISAppPoolName}}"
Exit 1
}
finally {
Write-Output "Starting IIS Application Pool: {{IISAppPoolName}}"
$appPool | Start-WebAppPool -Verbose
}
AWS FIS provides stop conditions as critical safety nets during resilience testing. For the IIS application pool test, you can set up alarms to monitor application error rates. If errors exceed predetermined thresholds (e.g., 10% over five minutes), FIS automatically halts the experiment. This safety mechanism lets you test system limits while maintaining control. If performance degrades beyond acceptable levels, the experiment terminates automatically, allowing investigation without risking extended outages. As your team gains experience, you can adjust thresholds and add conditions based on metrics like latency or resource usage, enabling gradually expanded testing while maintaining safeguards.
Expected Results – After running this experiment, the load balancer’s health checks should detect the failure of the IIS application pool on the affected instance. The load balancer will then redirect traffic to the remaining healthy servers, allowing the application to continue functioning with minimal disruption to users.
Testing service failures provides valuable insights into system response and recovery times. Through controlled failure simulations, you can measure application detection speed, failover effectiveness, and monitoring system performance.
Experiment 2 – RDS fail-over
For this experiment, we’ll test how application handles an Amazon RDS for SQL Server fail-over event. Database availability is crucial for business operations, and understanding how your application behaves during a fail-over can reveal important insights about your system’s resilience
Hypothesis – “If a Multi-AZ Amazon RDS instance experiences a failover between availability zones (AZs), then the application will continue to function with minimal disruption, experiencing no more than a few minutes of interruption while maintaining data integrity and service availability.”
This experiment leverages one of FIS’s built-in actions specifically designed for testing RDS fail-overs. Unlike our first experiment, which required custom PowerShell scripts, this test uses AWS’s native failover mechanisms. The process is straightforward but powerful in what it can reveal about your application’s resilience.
When the experiment begins, FIS follows these steps: First, it identifies the target RDS instance using resource tags we’ve specified in the experiment configuration. This targeted approach ensures we’re testing the correct database instance, particularly important in environments with multiple RDS deployments. Next, FIS initiates a failover using the built-in RDS failover action. This causes our primary database instance to switch over to the standby replica in another availability zone, simulating a real-world failure scenario. During this process, the database connection endpoint remains the same, but the underlying infrastructure changes completely.
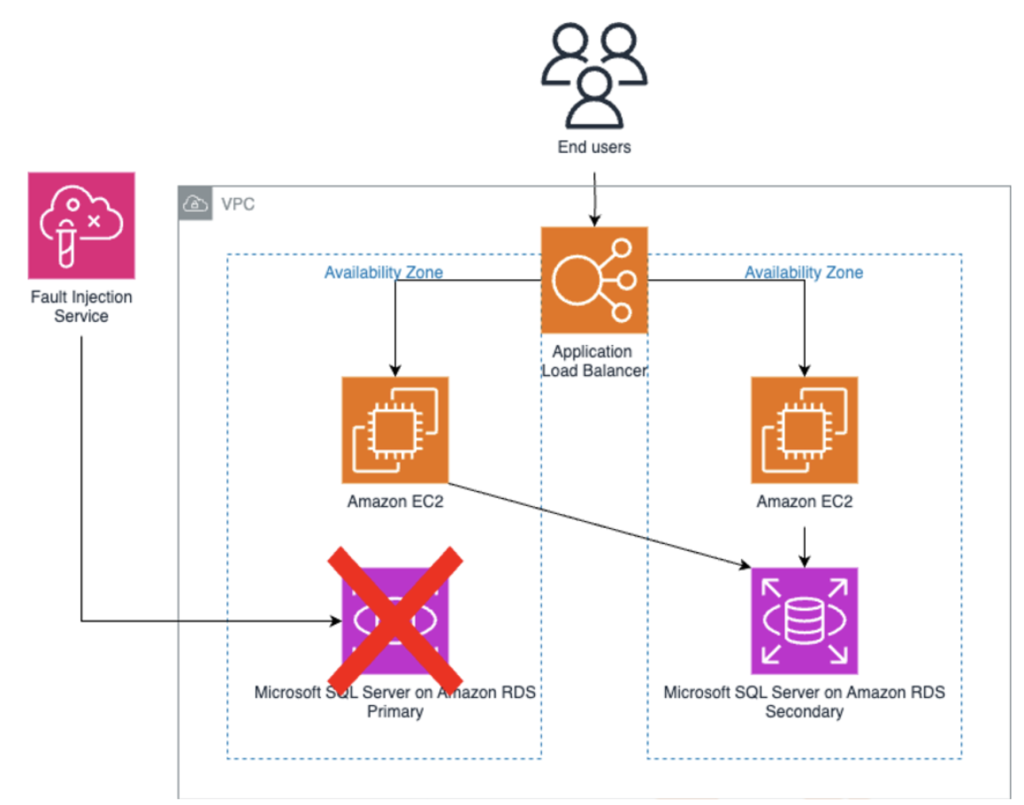
Figure 4: RDS Experiment Overview
Expected Results – After initiating the database failover experiment, you should observe a clear sequence of events. First, the primary RDS instance will become unavailable, and the standby replica will be promoted to primary status. During this transition, your application may experience a brief interruption in database connectivity. Once the failover completes, your application should automatically reconnect to the new primary instance and resume normal operations.
A well-designed application will demonstrate several key behaviors during this test. You should see minimal impact on overall application availability, with automatic reconnection to the database after the failover completes. There should be no data loss or corruption, and normal operations should resume without requiring manual intervention. However, this experiment often reveals areas that need improvement. You might discover inefficient connection pooling that leads to prolonged recovery times, or inadequate error handling that causes cascading failures in dependent services.
Some applications may lack proper retry logic, resulting in failed transactions that require manual recovery. For this database failover test, consider configuring CloudWatch alarms to monitor application error rates, failed database connection attempts, API response times, and transaction failure rates. These metrics provide valuable insights into your system’s behavior during the failover and will trigger automatic experiment termination if thresholds are exceeded. By systematically testing database failover scenarios and carefully monitoring the results, you can continually improve your application’s resilience to database disruptions. Each test provides valuable insights that help ensure better uptime and reliability for your users.
For detailed instructions on replicating this experiment in your account, please see this blog.
Conclusion
Throughout this blog post, we’ve explored how AWS Fault Injection Service (FIS) can be leveraged to enhance the resilience of Windows applications running in the cloud. By walking through two critical experiments – testing IIS application pool failures and RDS failovers – we’ve demonstrated how resilience testing principles can be applied practically and safely to real-world scenarios.
The deep integration between FIS and other AWS services proves particularly valuable. You can monitor experiment impacts in real-time and automatically stop tests if predefined thresholds are breached.
FIS’s automation transforms resilience testing from a manual task into a regular, repeatable process that integrates with your existing operations. Whether you use traditional change management or modern deployment pipelines, FIS adapts to your needs. This systematic testing helps catch issues early, building more resilient systems before problems affect users.
By embracing resilience testing and leveraging AWS service integrations, you’re not just preparing for disasters – you’re actively improving your application’s design, your team’s incident response skills, and ultimately, your ability to deliver reliable services to your users. Start your resilience testing practice today and take the first step towards more reliable, robust applications. For additional experiment templates and real-world scenarios, visit the AWS FIS scenario library in the console, or the FIS Template Library on GitHub today.
AWS has significantly more services, and more features within those services, than any other cloud provider, making it faster, easier, and more cost effective to move your existing applications to the cloud and build nearly anything you can imagine. Give your Microsoft applications the infrastructure they need to drive the business outcomes you want. Visit our .NET on AWS and AWS Database blogs for additional guidance and options for your Microsoft workloads. Contact us to start your migration and modernization journey today.