Migration & Modernization
Escaping Legacy Database Constraints: Modernize Business Rule Processing with AWS Cloud Technologies
Are you struggling with legacy database-based applications that feel like they’re holding your business back? Many organizations find themselves unable to move forward with digital transformation. They are trapped in a complex web of traditional relational databases to address both transactional and analytic data processing. These monolithic database architectures, built around intricate stored procedures and tightly coupled system integrations, create significant barriers to scalability, agility, and innovation.
In this blog, we’ll explore how businesses can break from these legacy constraints and modernize their traditional data engineering and data processing applications on AWS. We’ll dive into strategies for transforming traditional integrated relational database -based analytic data processing systems into flexible, cloud-native solutions. This transformation can help your organization move faster and adapt more quickly to changing business needs.
Figure 1 illustrates a traditional SQL Server-centric architecture for car insurance premium calculation. This architecture is a monolithic database that uses direct database connections (DB links) across multiple source systems to retrieve policy, insurance request, car, and driver details. The premium calculation logic is complex, and based on multiple business rules is implemented through multiple stored procedures and orchestrated through SQL jobs. The records with calculated premium are finally made ready for querying by the reporting application. Historically, such systems have relied on monolithic database architectures as a one-size-fits-all solution for storing business logic, system integrations, reporting data, and transaction records. This monolithic approach creates significant challenges for modern businesses seeking scalable and agile solutions.
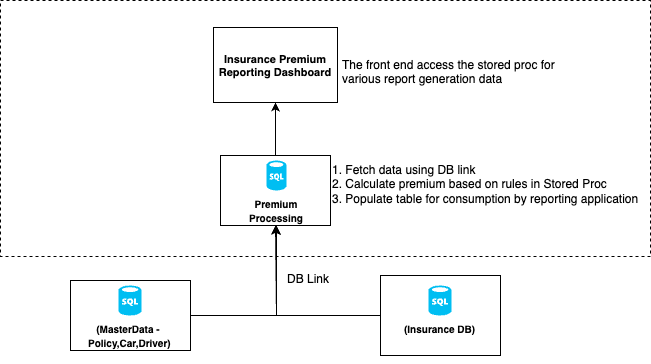
Figure-1
Our example, insurance premium calculation system, demonstrates common pain points faced by organizations:
- Complex Business Logic Management
- Stored procedures containing intricate, hard-to-maintain calculation rules
- Limited visibility into logic implementation
- Difficult to track changes through version controls
- Performance and Scalability Limitations
- Sequential data processing preventing parallel processing
- Potential risks to meeting performance Service Level Agreements (SLAs)
- Inefficient data retrieval for reporting purposes
- Integration and Flexibility Constraints
- Tightly coupled database systems with multiple linked servers
- Rigid architectures preventing rapid business adaptation
- Querying relational database for reporting, creating additional complexity
- Time to process large datasets or queries for report generation may be protracted
Using a stepwise approach is a recommended strategy to modernize applications like these. Through iterative development, we intend to transform the application by creating a more agile and scalable system. The transformation will support parallel processing, large scale aggregation, and decrease commercial database licensing constraints. This should also reduce the operational burden for maintenance.
Modernization strategy:
- Bounded context decomposition: We decomposed the data processing from the existing legacy system into three distinct functional contexts:
- Data Ingestion: Retrieves transactional data like car, policy, driver, and insurance request, by using complex database joins and cross-database connections using DB links.
- Data Pre-processing: Filtering and aggregation techniques are applied to prepare and refine data for subsequent business rule calculations.
- Data Processing: Calculates insurance premiums by applying predefined business logic and rules.
- Intelligent data source selection: We select purpose-built database solutions by analyzing the data access patterns, performance requirements, and operational complexity. Analytic applications require running complex queries on large volume of data (when to use OLAP vs OLTP). We use Amazon S3as our data lake. This provides scalable performance, flexible data storage, robust security features, and efficient data retrieval. Raw and processed data are stored in the Apache Parquet format in an Amazon S3 bucket. This helps the reporting application with large scale aggregation and fast querying through Amazon Athena.
- Layered data lake architecture: Based on the data quality, accessibility, and significance of the data we adopted a layered data lake architecture with three layers. The first layer hosts raw and unprocessed data in an S3 bucket (bronze layer). The second layer is the staging layer with pre-processed and aggregated data in a different S3 bucket (silver layer.) The third layer is the analytic layer or the curated layer. This holds the final processed data and is primarily used for reporting applications. It is typically stored in a third separate S3 bucket (gold layer.)
- Parallel processing strategy-When the data is contained within a single calculation set, it is a candidate for parallel processing. For example, with row wise data processing, parallelization is a good modernization strategy that also reduces the time to complete. In the rule-based insurance premium calculation use case, the pre-processed data is contained within one dataset (row). This makes it a good candidate for parallel processing of the rule-based calculations.
- Business rule management – A business rule engine framework is a pattern that is used for transforming the static value-based business rules from stored procedures and tables. This will help in the management of business rules through a version control repository. This includes benefits for auditing and maintenance. We have selected Drools as a business rules management system. This is an open source Java Spring boot framework for rule management. In this design, the rules will be transformed and codified into the Drools rule engine DRL files. Other open source business rule engine frameworks that can be used include a Python rule engine from pypi, or a JavaScript based rule engine called nools.
The target architecture of this modernized solution is a serverless solution on the AWS.
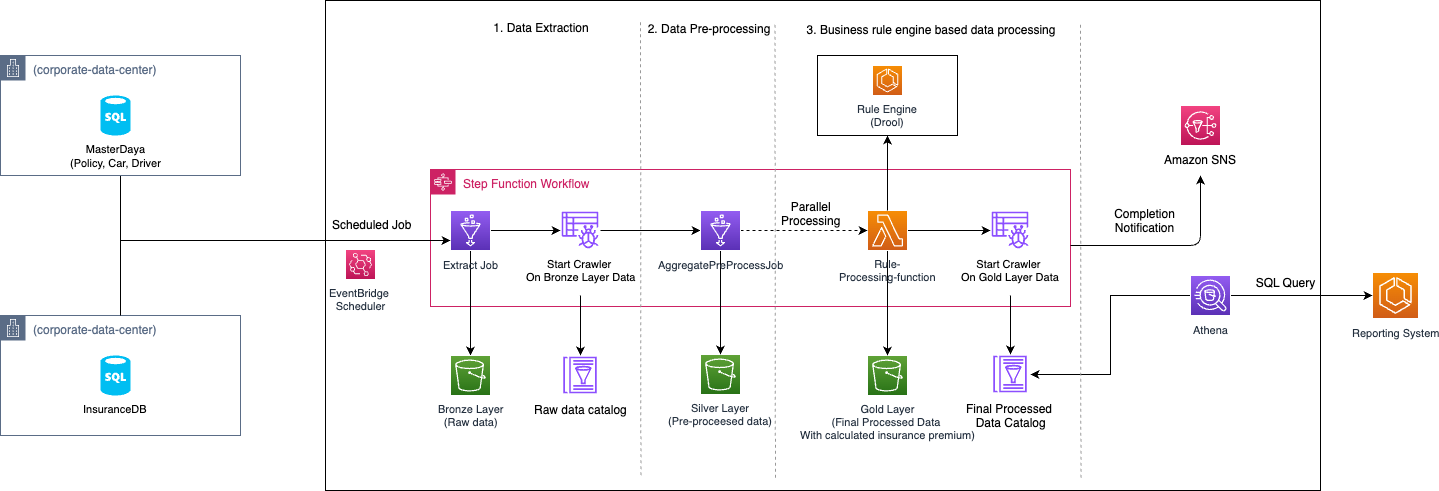
Figure-2
AWS Step Functions are used to orchestrate different AWS services for data ingestion, data pre-processing, and the final data processing. These steps used the bounded context decomposition strategy explained earlier in this blog. AWS Step Functions are based on state machines, which are also called workflows. Workflows are composed of a series of event-driven steps. Using these workflows, we can create a comprehensive data processing pipeline. This pipeline uses AWS Glue ETL jobs for data extraction, runs AWS Glue Crawler to generate Data Catalog tables, and manages complex data processing stages.
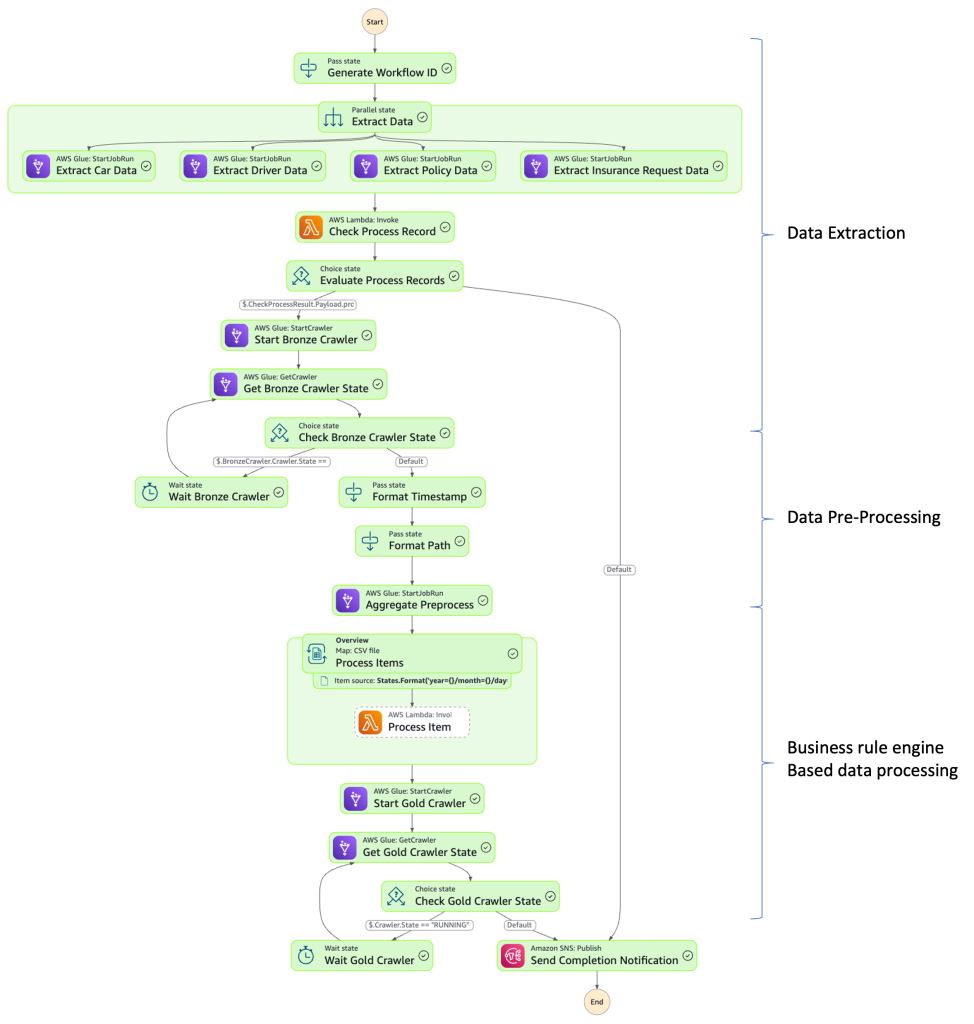
The workflow stages include:
Serverless data integration: Bronze Layer Processing
- Extract transactional data from legacy system databases using the AWS Glue JDBC connector
- Use AWS Step Functions to parallelize the data extraction and reduce the processing time
- Automatically create and update Data Catalog tables with AWS Glue Crawler
- Wait for crawler completion
Data aggregation and pre-processing: Silver Layer Processing
- Conduct data aggregation and pre-processing ETL jobs using AWS Glue
- Use PySpark’s parallelization for large-scale data transformation
- Store pre-processed data in the staging layer or silver layer
- Prepare data for advanced analysis
Business rule engine-based data processing: Gold Layer Processing
- Perform parallel processing of pre-processed data using AWS Step Functions’ distributed map feature
- Crawl the final processed data
AWS Glue serves as our serverless data integration service, automating complex data discovery and transformation.
Technical Implementation:
Visit the GitHub repository for the complete solution, clone the CDK code and follow the implementation guide. You can also customize the solution for your specific use case.
Data Extraction:
We will use PySpark based AWS Glue ETL scripts along with AWS Glue JDBC connections to connect the source system’s databases and extract the data. With the help of the parallel state of the AWS Step Functions workflow we will orchestrate multiple AWS Glue data extraction jobs in parallel. We will use the AWS Glue extension for the Apache Spark ETL job to perform the data extraction. This ETL job will also be used for the transformation of the data from the source system’s SQL tables into the Apache Parquet format. This extracted and transformed data will be loaded into the bronze layer Amazon S3 bucket. The PySpark script (sql_data_extract_from_table.py) has the common extraction logic for all the source system’s SQL tables. The Glue ETL job uses the table names and the AWS Glue JDBC connection options as arguments in the code for data extraction. It creates an AWS Glue DynamicFrame for the records present in the SQL tables. The extraction job writes this DynamicFrame object into the raw data layer (bronze layer S3 bucket) in an Apache Parquet format.
# Read source data from SQL Server
source_df = self.glueContext.create_dynamic_frame.from_options(
connection_type="sqlserver",
connection_options=self.get_connection_options(),
transformation_ctx=f"datasource_{self.table_name}"
)
# Process and write data
processed_df = self.process_dynamic_frame(source_df)
self.write_to_s3(processed_df)
# Log execution metrics
end_time = datetime.now()
duration = (end_time - start_time).total_seconds()
self.logger.info(f"Job completed successfully. Duration: {duration} seconds")To optimize data extraction efficiency, we implement AWS Glue job bookmarks, a feature that enables incremental data retrieval. Our Cloud Development Kit (CDK) configuration script (data-processing-stack.ts) dynamically generates AWS Glue ETL jobs for data extraction. Using the primary key columns from the source table as hash identifier, we can configure the job bookmarks to extract only newly added or modified data. This minimizes redundant processing and helps to improve overall Data Pipeline performance.
// Create Glue job for Car data extraction
this.extractCarGlueJob = new glue.CfnJob(this, 'CarTableExtractJob', {
name: 'sql-server-car-extract-job',
role: glueJobRole.roleArn,
command: {
name: 'glueetl',
pythonVersion: '3',
scriptLocation: `s3://${glueBucket.bucketName}/scripts/sql_data_extract_from_table.py`
},
workerType: 'G.1X',
numberOfWorkers: 10,
executionProperty: {
maxConcurrentRuns: 1
},
defaultArguments: {
// Default arguments for Glue job goes here
// ...........
'--S3_OUTPUT_PATH': `s3://${props.bronzeBucket.bucketName}/`,
'--TABLE_NAME': `Sales.Car`,
'--HASH_COL_NAME': `CarID`,
'--job-bookmark-option': 'job-bookmark-enable',
'--enable-job-bookmarks': 'true',
'--METRICS_TABLE_NAME': props.jobMetricsTable.tableName
},
glueVersion: '4.0',
maxRetries: 0,
connections: {
connections: ['sql-server-connection']
},
timeout: 2880,
});
We store ETL job extraction metadata in Amazon DynamoDB, a key-value pair database, to support selective data processing. This is done by storing the unique identifier of the first extracted record for each data extraction iteration into the DyanmoDB table (job metrics table) as a checkpoint. This approach helps downstream data processing systems process only the new data, preventing duplicate processing, and reducing overall pipeline processing time.
Data aggregation and pre-processing:
We use Amazon Athena for large-scale data aggregation and pre-processing of bronze layer data in Amazon S3. The workflow involves an AWS Glue ETL job running Athena queries against Data Catalog tables created by the bronze layer Glue crawler. The aggregation script (aggregate-pre-process.py) performs complex SQL-based record aggregation, storing the output in the silver layer S3 bucket. We generate partitions to optimize processing efficiency for the subsequent distributed parallel processing step.
def execute_athena_query(athena_client: boto3.client,
query: str,
database: str,
output_location: str) -> str:
"""Execute Athena query with retry mechanism."""
MAX_RETRIES = 3
INITIAL_BACKOFF = 1 # seconds
for attempt in range(MAX_RETRIES):
try:
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={'Database': database},
ResultConfiguration={'OutputLocation': output_location},
WorkGroup='primary'
)
return response['QueryExecutionId']
except Exception as e:
if attempt == MAX_RETRIES - 1:
raise
time.sleep(INITIAL_BACKOFF * (2 ** attempt)) # Exponential backoff
Data processing – Business Rule Engine integration:
We implement distributed parallel data processing for premium calculation using AWS Step Functions’ distributed map state. This supports a high-performance and scalable data processing framework. We create a distributed MAP state (We have configured the distributed MAP state child workflows with a concurrency limit of 1,000. Each concurrent workflow processes items in batches of 100 items.


Each child workflow in our distributed map state invokes a serverless AWS Lambda function designed to run the premium calculation logic. The Lambda function iterates through batch items, invokes the Drools rule engine (rule-engine-drool) running inside an Amazon ECS cluster to perform the car insurance premium calculation. This is based on the predefined business rules.
The AWS Lambda function (RuleEngineClientFunction) uses the data organization strategy using the partition metadata including year, month, and day. The partition metadata is provided as a batch input from the distributed MAP state. After running the premium calculation through the rule engine, the Lambda function persistently stores the calculated premium and associated information within the gold layer Amazon S3 bucket. This storage approach also uses the Apache Parquet format. It maintains a structured, partitioned directory hierarchy that facilitates efficient data retrieval and analysis.
def lambda_handler(event: Dict[str, Any], context: LambdaContext) -> Dict[str, Any]:
logger.info("Received event", extra={"event": event})
try:
if not event.get('Input'):
raise KeyError("Event object missing 'message.Items' structure")
input_data = event.get('Input')
logger.info(f"Processing payload with {len(input_data.get('Items', []))} items")
partition_info = input_data.get('BatchInput', {}).get('partition_info', {})
validate_partition_info(partition_info)
processed_results = process_items(input_data['Items'], rule_engine)
# Convert results to DataFrame and then to Parquet
df = pd.DataFrame(processed_results)
table = pa.Table.from_pandas(df)
# Generate unique filename using timestamp
timestamp = datetime.utcnow().strftime('%Y%m%d_%H%M%S')
s3_key = generate_s3_key(partition_info, context.aws_request_id, timestamp)
# Save to S3
s3_handler.save_parquet(table, s3_key)
The serverless Lambda function serves as a critical component. It integrates the distributed map state workflow with the business rule engine (Drools) based calculation process. This design supports a scalable architecture with consistent premium calculations. This also maintains granular data management principles. By dynamically generating partition-specific storage paths, the function supports a comprehensive data lineage and enables downstream reporting and analytics processes.
After processing the insurance premium calculation for the records concurrently, an AWS Glue crawler updates the Data Catalog tables in the gold layer S3 bucket. This enables the reporting application to query the large dataset using Amazon Athena.
If your data processing occurs on a less frequent basis, the Athena query result reuse feature can be used with the reporting query. This feature stores query results in cache, reducing the need for repeated data scanning and lowering query costs.
We have scheduled the data processing pipeline using Amazon EventBridge, with an email notification sent via Amazon Simple Notification Service upon successful completion.
Conclusion:
In this blog post, we’ve shared an approach to modernize legacy commercial OLTP database-based data processing systems for reporting using AWS. By adopting an open-source business rule engine framework and implementing distributed parallel processing for business rule calculations, we were able to improve the overall performance. This example demonstrates how to decompose a monolithic, complex database architecture and modernize with an agile, scalable, and cost-effective data processing solution.