AWS for Industries
Transforming the operations of Moeve’s Energy Parks with a Data Gathering Digital Plant solution
Background
Moeve, with nearly 100 years of experience, has established itself as one of the leading energy companies globally. For much of its history, the company has been a leader in the oil and gas sector, but today it is undergoing a transformation toward clean and sustainable energy, which is essential for combating climate change and reducing carbon emissions. Its sustainability strategy, called “Positive Motion,” not only promotes the production of green molecules, but also directly contributes to the decarbonization of hard-to-electrify sectors, such as air transport, while creating quality jobs and supporting sustainable development in key regions.
One of the major milestones of this strategy is the modernization of the legacy systems for control and data processing. Data acquisition from Moeve’s Energy Parks plays a key role in operating efficiently and reliably when it comes to mission critical infrastructure—where hundreds of thousands of signals are generated per minute. This project is laying the foundation for all AI-driven innovations by collecting, structuring, and optimizing vast amounts of operational data from sensors, IoT devices, and manufacturing systems. In this way, Moeve is unlocking new AI capabilities, such as advanced analytics, machine learning (ML)-driven optimizations, and autonomous systems, driving the company’s digital transformation.
 Picture 1. Location for Moeve’s Energy Parks
Picture 1. Location for Moeve’s Energy Parks
Problem statement
The main challenges that Moeve had to address with the new solution are:
- Obsolescence of their data persistence systems (historians) with technical limitations to their ability to make data available. For example, Data Gathering Digital Plant consumes metadata from the origin to enrich incoming real-time data. However, the former legacy system had a completely separated and manual database that, over time, was no longer in sync with the origin.
- Availability rate of historians and performance penalties due to the load imposed on them by third-party applications that demand data. From April to September 2024, the legacy system suffered 57 service interruptions and 5 crashes.
- Lack of standardization and flexibility to serve data through different communication protocols. As technologies advance, new sensors and instruments equip communication protocols designed for the IoT environment that are not reconcilable with the classic protocols that lead to the control system or the operator panel. For example, new vibration sensors equipped with batteries and LoRaWAN, IEEE802.15.4 (aka Zigbee), or BLE (Bluetooth Low Energy) for predictive maintenance in rotative equipment such as pumps, ventilators, conveyors, etc. For these use cases, for example new monitoring networks for reliability on dynamic non-critical assets relevant for production, having a modern gateway-edge enables new and flexible dataflows from the site to the cloud.
- Limitations on making data available to applications running in cloud platforms. For example, business units use multiple dashboards to monitor the performance of the factories and other processes to consume it for ML processes, among others. Therefore, having data in real-time and a system that recovers automatically helps monitoring, performance, and predictions.
- High recurring and perpetual costs that legacy data systems need regardless of their use or value contribution. Just in maintenance support, Moeve invested 1800 hours/year. Furthermore, when historical data was requested to refill a gap of data, it used to take several weeks before having it available. The new solution ingests it automatically when the system is recovered.
The Moeve Data Gathering Digital Plant solution addresses these challenges and is transforming how Moeve operates their Energy Parks. The solution has been developed and deployed in production in Amazon Web Services (AWS) Cloud with a collaboration between Moeve, Galeo, and AWS. The first new Data Gathering Digital Plant deployment has been completed at its La Rábida Energy Park (EPLR). Moeve selected AWS for this, given the unmatched portfolio of AWS cloud services and its alignment with Moeve’s approach.
Solution architecture
Data Gathering Digital Plant is a high availability solution that enables the extraction and ingestion of data at a scale of hundreds of thousands of signals per seconds, from the field to the AWS Cloud. The architecture includes a number of components to 1. capture data in real time from the field, 2. process the data in the AWS Cloud using AWS IoT services, and 3. send the processed data to Knolar—Moeve’s data platform—for storage, analysis, and visualization.
The following figure shows the solution architecture. It benefits from the operational savings of a fully serverless architecture on AWS Cloud.
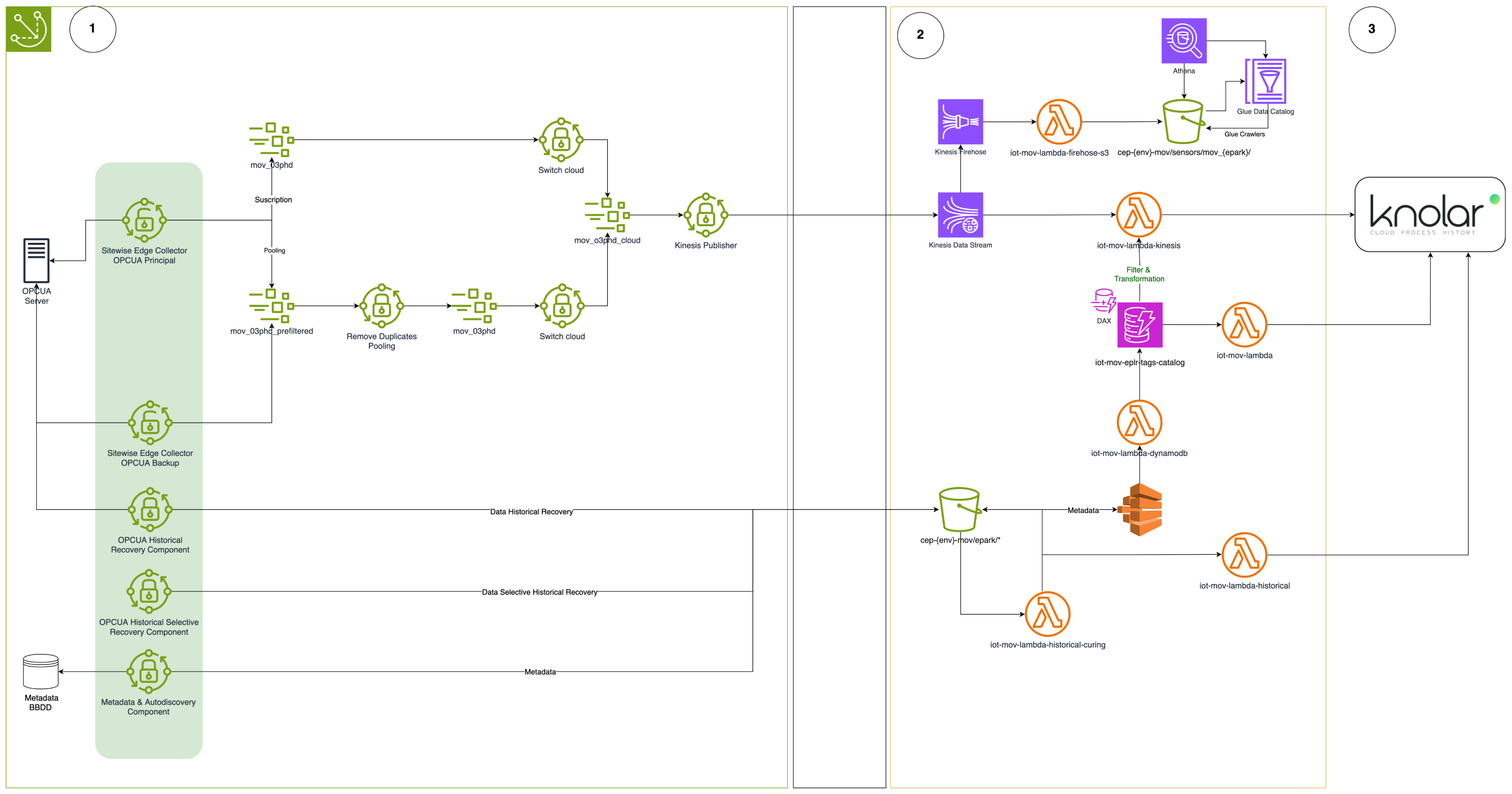
Figure 1. Solution architecture end to end
The Data Gathering Digital Plant architecture solution spans across three areas or domains, marked with the circled numbers 1, 2, and 3 in the preceding figure.
1. Edge
This is the Energy Park in La Rábida where the industrial signals originated. At the edge we have the data sources and a number of AWS IoT GreenGrass components, as described next.
A. Data sources
There are several servers at the central data extraction level:
- OPCUA Server: It emits signals in real-time at the request of clients, and by subscription.
- Historical server: It returns historical data at the request of clients. The historical server stores the last 6 months, from the current date of each of the signals enabled on the OPCUA server.
- Metadata server: It contains the database with aggregated signal information.
B. AWS IoT GreenGrass components
AWS IoT Greengrass is an open source Internet of Things (IoT) edge runtime and cloud service that helps you build, deploy, and manage IoT applications on your devices. You can use AWS IoT Greengrass to deploy components to devices or groups of devices. You use deployments to define the components and configurations that are sent to the devices. AWS IoT Greengrass deploys to targets, AWS IoT things, or thing groups that represent Greengrass core devices.
We have deployed two virtual machines (VMs)—main and backup—close to the data sources on-premises. And we have installed numerous AWS IoT Greengrass components on those VMs. The most important AWS IoT Greengrass components are as follows:
- aws.greengrass.SiteWiseEdgeCollectorOpcua: AWS-provided component enables AWS IoT SiteWise gateways to collect data from local OPC UA servers. In our deployment, it connects to the OPCUA server and obtains signal data by subscription or polling depending on the configuration for each group of tags.
- aws.greengrass.StreamManager: AWS-provided component that enables you to process data streams to transfer to the AWS Cloud from Greengrass core devices.
- iot-mov-greengrass-component-stream-manager-filter: Custom component that filters duplicated data taken by polling.
- iot-mov-greengrass-component-switch-cloud-subscription: Custom component that performs the switch and filtering by families or groups of tags. It activates or deactivates the transmission to the cloud and prevents both machines—main and backup—from sending data simultaneously to the cloud.
- iot-mov-greengrass-component-kinesis-publisher: Custom component that establishes the configuration for the stream to send the data to a Kinesis stream in the cloud.
- iot-mov-greengrass-component-database-connector: Custom component responsible for obtaining the latest metadata present in the metadata server once a day and uploading it to the cloud to synchronize with the rest of the system.
2. AWS Services
The following AWS Services are used:
- AWS Kinesis Data Streams for data collection from the edge, providing real-time data ingestion at a reduced cost. Kinesis Data Streams manages the infrastructure, storage, networking, and configuration needed to stream Moeve’s data at the level of our data throughput.
- Amazon Data Firehose for loading real-time data streams into data lakes, warehouses, and analytics services. In our case, the destination where data is loaded is an Amazon S3 bucket at the top right of the preceding figure.
- Amazon DynamoDB for metadata storage, enriching the collected data before it is sent to Knolar. DynamoDB is a fast and flexible nonrelational database service for any scale.
- AWS Lambda to orchestrate all the processes and to provide high availability for the solution, as described at the Data Flows section.
- IoT SiteWise to collect data from the industrial equipment at the Energy Park. OPC-UA is used as the data source protocol.
3. Destination
This corresponds to the Knolar system.
Knolar is a business unit created by Moeve in 2021 that responds to the new needs of Industry 4.0 in terms of monitoring facilities and making this data available to analysts and data scientists. It runs on AWS (details outside the scope of this post). Knolar receives all of the data collected for further processing, displaying and feeding an ML model.
The following figure shows a capture from Knolar.
 Figure 2. Data display with Knolar
Figure 2. Data display with Knolar
Data flows
In this section, we describe the different data flows across the solution, from the data sources to the Knolar system.
- Real-time data flow: Real-time data is captured from the on-premises OPCUA server using the IoT SiteWise OPC UA collector component that retrieves the data through subscriptions or polling. This connector is deployed into two VMs to have high availability altogether with other custom components. Then, the data is passed through internal Greengrass data streams, filtered for duplicates (if polling mode is used), and sent to a Kinesis stream in the AWS Cloud. From Kinesis, the data is consumed by lambda functions for processing, crossing with tags’ metadata and filtering for active tags that are sent to Knolar. This flow prioritizes the near real-time transfer of operational data. In parallel to the Lambda, which sends data to Knolar, there is a Kinesis Firehose with Lambda transformation and an Amazon S3 sink to store data for quality analysis.
- Metadata synchronization data flow: Metadata, which describes the real-time data signals (tags), resides on the on-premises server. Once daily, a Greengrass component on the primary VM retrieves the latest metadata from this server. Then, this metadata is uploaded to the AWS Cloud on an S3 bucket to be processed by an AWS Batch job to get recursive values based on its relationship with the parent tags. The output is saved in Amazon S3 and loaded to a DynamoDB table where metadata is centralized and consumed by other cloud components. Moreover, the DynamoDB table is sent to Knolar. This flow makes sure that the system has up-to-date information about the tags.
- Historical data flow: Historical data is stored on the on-premises Historical server. The backup Greengrass VM is responsible for retrieving this data. Components on the backup VM query the Historical server for specific data ranges (either for all tags or a selection of tags). Then, this retrieved historical data is uploaded directly to an S3 bucket in the AWS Cloud. The data uploaded to Amazon S3 is curated with a Lambda to filter data based on metadata active tags and applying interpolations (if activated, deactivated by default). Historical recoveries are automatically triggered for full fetches when it is detected that no data has arrived for more than 10 minutes. This mechanism is monitored with several Lambdas, and historical recoveries are logged in a DynamoDB table. The Greengrass components in charge of fetching historical data read the pending jobs from these tables and process them. This flow provides a mechanism for archiving and analyzing past data trends.
Monitoring
Observability is a key component of the deployment. It allows Moeve to gain insights and improve the performance of the Data Gathering Digital Plant solution and its infrastructure. AWS observability means that you can collect, correlate, aggregate, and analyze telemetry in your network, infrastructure, and applications in the cloud, hybrid, or on-premises environments.
The following AWS Cloud Watch Dashboard was built to provide a single pane of glass for different key components of the solution that we explain in the next section.
- OpcUaCollector.IncomingValuesCount
This represents connections to data from the SiteWise Edge Collector OPCUA component. In total there are 15 connections: 14 correspond to the main server families. 1 corresponds to the backup machine, because there is only 1 source that brings all of the data at once per pooling.
In normal operation, our primary machine maintains active connections to all device families in the network. When the primary machine experiences a failure or disconnection, our automated failover system activates the backup machine that establishes direct OPCUA connections. When the primary machine is restored and operational again, the backup machine automatically shuts down, returning the system to its standard configuration.
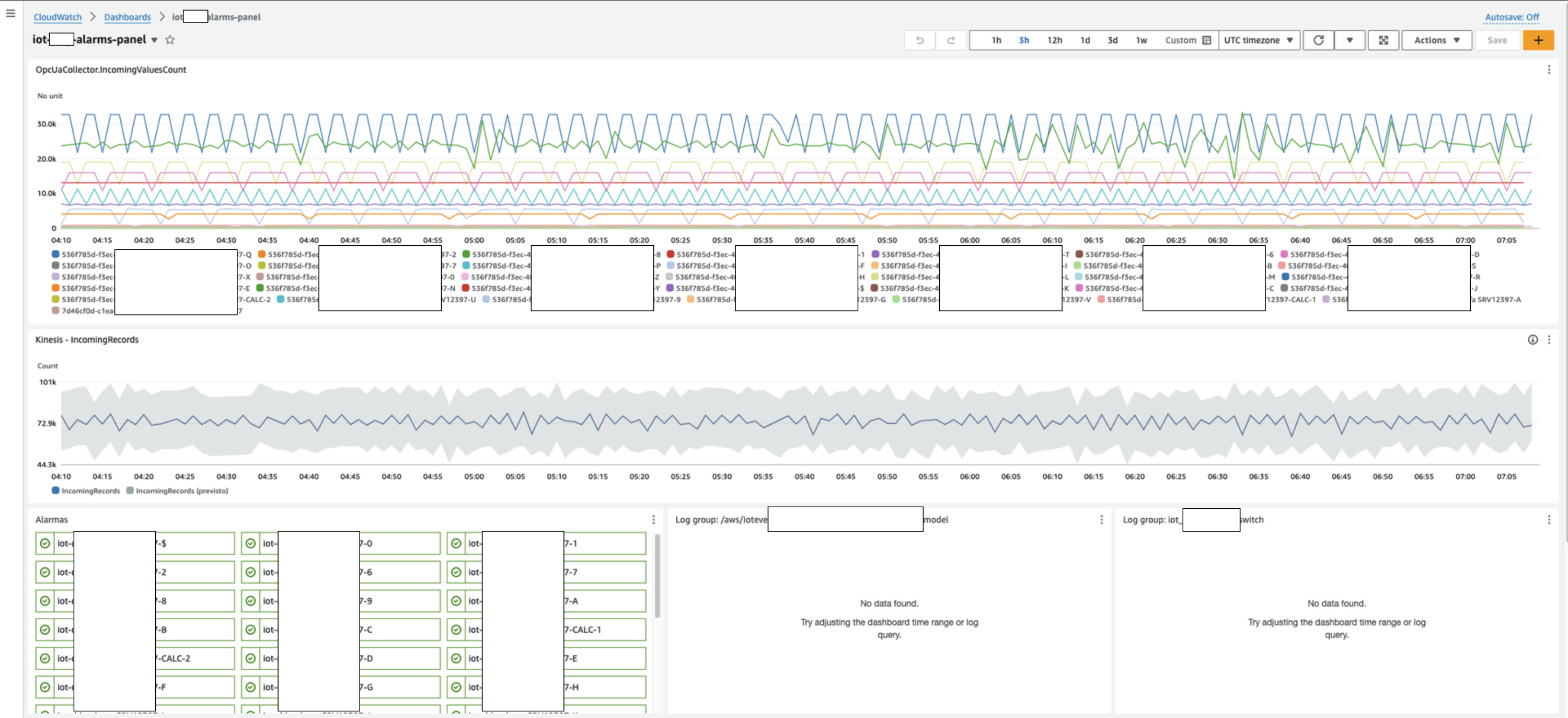 Figure 3. Monitoring dashboard.
Figure 3. Monitoring dashboard.
- Kinesis: IncomingRecords
This shows the data into the Region coming from the Edge. Then, that data is sent to Knolar. - Alarms graphics
This graph shows the alarms for each of the families or sources that the main machine has. The objective is to observe if any of the families on the main machine are offline. Furthermore, the alarm iot-mov-alarms-subscription-tdopplgedg01 represents the set of 14 families that make up the main machine. This alarm is important because it is the trigger for shutdown of the backup machine and for recovery of historical data.
Solution benefits and KPIs
The new solution in production allows users to visualize data in their distributed platforms and devices. Advanced analytics at the edge help users take informed operational decisions in real-time. Moreover, data is consolidated in the AWS Cloud for further analysis and transparent access. Moeve has full control over the management and operation of the solution: operators can add or remove signals on demand from a graphical interface, with more than 70K signals processed and displayable every 20 seconds.
To increase availability and resiliency, the solution supports the detection of outages in the data source systems and automatically triggers the recovery of gaps in the signal history (backfilling). Downtime is reduced and operational continuity is maintained.
In the following table, we show a few KPIs measured in production:
| Metric | Value/Impact |
| Data processed |
● 645 million of signals per week. ● 300 concurrent users ● 120 ms avg latency |
| Availability | ● 100% uptime (period: August 1st 2024 to December 1st 2024) |
| Calls per week |
● + 9 millions of calls per week (Some of them critical for the operation and business). ● 99.96% request success rate |
| Cost reduction | ● Cost reduction is being evaluated but the estimation is approximately 15%-20%. |
Table 1. KPIs measured in production
Conclusions
Data Gathering Digital Plant is a solution designed as a result of the collaborative effort between Moeve, Galeo, and AWS that represents a significant advance in the modernization of energy production plants. The solution provides reliable access to critical data, allowing process plants to unlock a new level of efficiency and analysis capacity and enabling the optimization of all of our industrial processes through ML and AI. Operations at the energy parks are transformed, which reduces costs and improves decision-making capacity through a connected and resilient ecosystem.