AWS for Industries
Resolve imperfect data with advanced rule-based fuzzy matching in AWS Entity Resolution
Companies across industries aim to deliver personalized customer experiences and optimized advertising campaigns by resolving customer identities. However, being able to reliably match records across fragmented, inconsistent, and often messy datasets can be hard and complicated.
Organizations using traditional rule-based matching techniques to help match exact records often miss valuable connections due to slight variations in names, email addresses, or home addresses (for example, Jon Smith compared to Jonathan Smith, or 123 Main St., Apt. 4B compared to 123 Main Street #4B). These mismatches can result in underperforming campaigns, limited audience reach, and wasted ad spend.
To respond to these challenges, companies are using Amazon Web Services (AWS) Entity Resolution to match, link, and enhance related records across multiple applications, channels, and data stores. It improves the quality of their data for better understanding and engagement of their customers. AWS Entity Resolution offers multiple, flexible, configurable matching techniques including rule-based matching and machine learning (ML)-based matching.
- Rule-based matching defines deterministic logic using exact conditions across multiple fields. For example, a rule can be used to match on email and last name. This method provides high precision, full transparency, and is often preferred for use cases where explainability is key using pre-defined rules.
- ML-based matching leverages pre-trained models that automatically learn patterns in the data to identify likely matches, even when data is noisy, inconsistent, or lacks a dominant identifier. It reduces configuration effort and adapts well to varied data types, offering higher recall where deterministic rules may fall short.
Today, we announced advanced rule-based fuzzy matching capabilities in AWS Entity Resolution. It enables companies to match records using fuzzy matching algorithms including Levenshtein Distance, Cosine Similarity, and Soundex.
This capability introduces tolerance for variations and typos, enabling more accurate and flexible identity resolution without requiring custom pre-processing. For marketers, this means potentially improving match rates, enhancing personalization, and unifying customer views for effective cross-channel targeting, retargeting, and measurement use cases.
Industry use cases
Advanced rule-based fuzzy matching can help customers across industries solve complex data unification challenges, including:
- Advertising and Marketing: Improve reach and frequency analysis by matching records across disparate datasets, even when identifiers are incomplete or slightly off.
- Retail & Consumer Packaged Goods: Link records in customer relationship management (CRM) data that contain typos or alternate spellings.
- Financial Services: Resolve identity records for Know Your Customer (KYC) verification, fraud detection, or marketing purposes.
Advanced rule-based fuzzy matching overview
AWS Entity Resolution advanced rule-based fuzzy matching bridges the gap between rule-based and ML-based approaches. It introduces probabilistic matching into traditionally strict rule-based frameworks by providing customers the ability to set similarity thresholds on string fields using fuzzy algorithms (such as, Levenshtein Distance or Cosine). This offers a middle ground between the explainability and control of rules, with flexibility of probabilistic matching.
Customers can use the following fuzzy matching algorithms in AWS Entity Resolution:
- Levenshtein Distance: Detects typos or small character edits to match names, emails, or misspelled entries (for example, john@gmail.co compared to jon@gmail.com).
- Soundex: Assesses phonetic similarity to match names that sound similar but are spelled differently (such as, Mary compared to Marie).
- Cosine Similarity: Measures similarity based on word or token overlap. It is used for matching company names or free-text fields with reordered or partial matches (for example, Acme Inc. compared to Acme Corporation).
Customers can now define custom similarity thresholds using algorithms to enable more flexible, accurate matching across noisy or inconsistent data. It combines the control of rule-based systems with the adaptability of ML-based approximate matching—helping you to potentially improve match rates without sacrificing explainability.
Customers can use set rule conditions with the relevant fuzzy matching algorithm and set appropriate thresholds where applicable (see Figure 1).
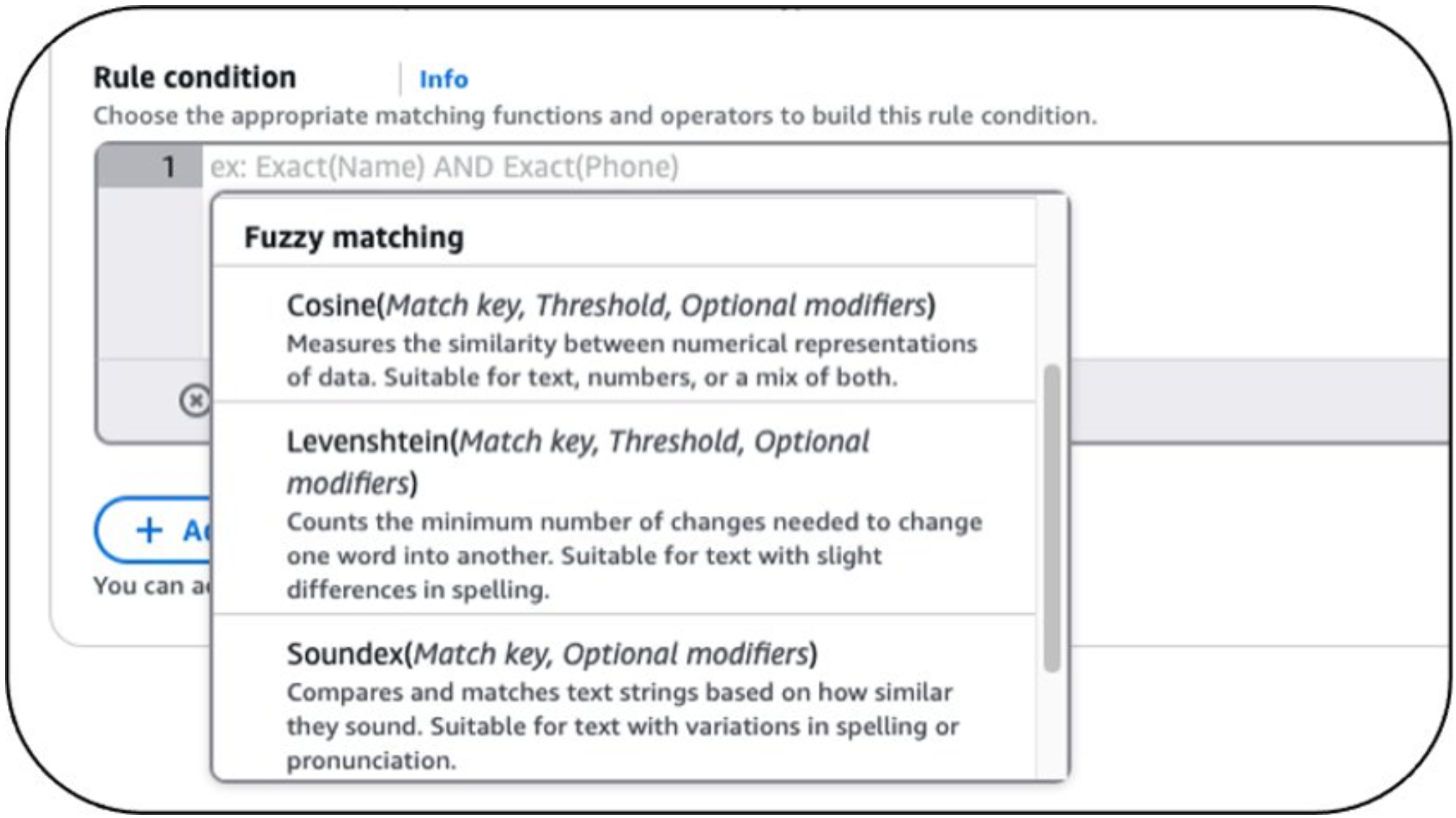 Figure 1: Advanced matching algorithms
Figure 1: Advanced matching algorithms
How it works
To use the new feature of AWS Entity Resolution in a solution, you begin with making sure records across your multiple applications, channels, and data stores are available in a data lake (an Amazon Simple Storage Service (Amazon S3) bucket). An AWS Glue crawler is used to automatically determine the contents of the Amazon S3 data, with the metadata table updated in an AWS Glue Data Catalog.
AWS Entity Resolution resolves the datasets into their appropriate match groups using the rules you defined within the service. The output from AWS Entity Resolution is available in an S3 bucket. Figure 2 is a high-level architecture diagram illustrating the solution.
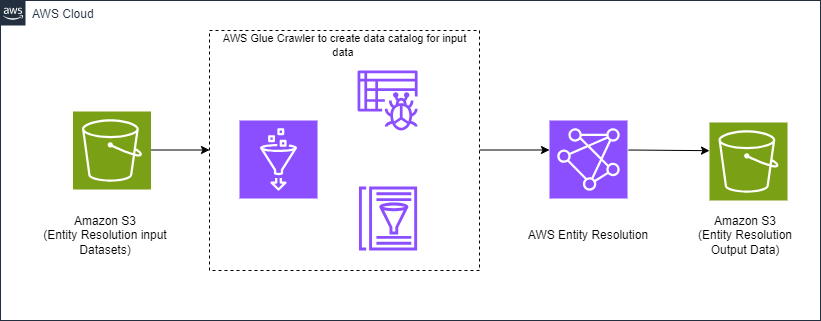 Figure 2: High-level architecture diagram
Figure 2: High-level architecture diagram
Example walkthrough
To demonstrate AWS Entity Resolution’s fuzzy matching rules, we have created a test dataset. This dataset consists of synthetic customer information, formatted as a CSV file and uploaded to S3 bucket.
 Figure 3: Example dataset
Figure 3: Example dataset
The dataset in Figure 3 contains four individual entities. However, it also includes several variations to those individual entities with alterations to the name, address, and phone number fields.
We used the following steps to resolve the sample data’s issues:
- For AWS Entity Resolution to resolve the example data schema, you must first create an AWS Glue Data Catalog table using an AWS Glue crawler. This table points to the S3 bucket that holds the incoming clickstream data.
- You need to define a schema mapping within the AWS Entity Resolution that informs the service on how to interpret the data.
- Within the Create schema mapping screen, choose the appropriate AWS Glue database and table representing the source data. For our example, this is the database named “fuzzymatchingdemo”, which also contains the “fuzzymatchingaerdemo”. This database’s table was created when the AWS Glue crawler was run on the S3 bucket containing the sample dataset.
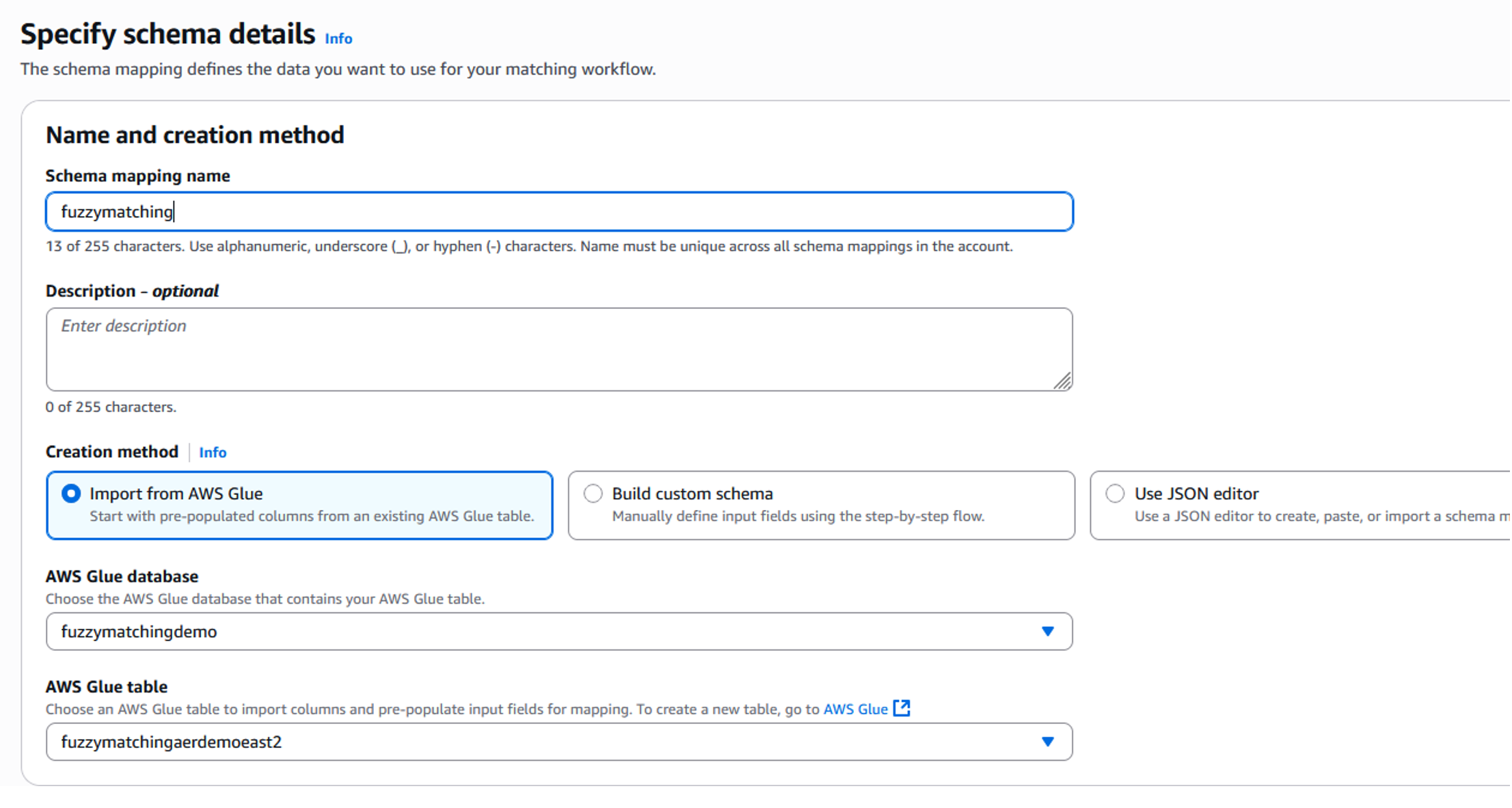 Figure 4: Schema mapping – Setup
Figure 4: Schema mapping – Setup
- Select the Unique ID from the dropdown (Figure 5). The unique ID column should distinctly reference each row of the data—think of this as the primary key column in a database. In this case, it is the uniqueid in the CSV file.
- Scroll down and select the input fields that are required for resolution (Figure 5). In this case the columns address, first_name, last_name, and phone are selected.
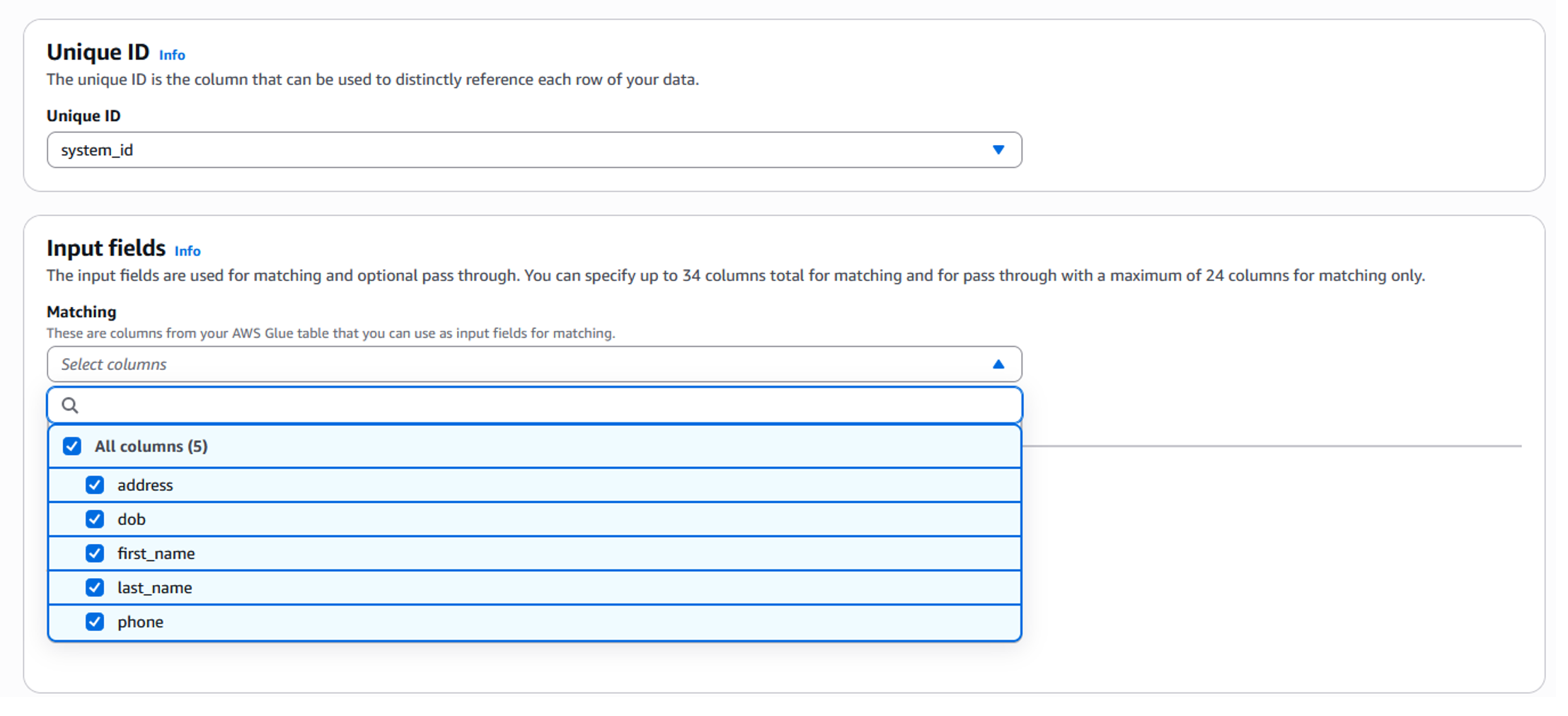 Figure 5: Schema mapping – Input data fields setup
Figure 5: Schema mapping – Input data fields setup
- Now map the selected input fields to their appropriate data types and match keys. Specifying the input type (such as name, email, address, and so on). This informs AWS Entity Resolution on how to interpret the data in each column and, optionally, what normalization rules can be applied on that column. The match key determines which fields are similar and needs to be considered as a single unit during the matching process.
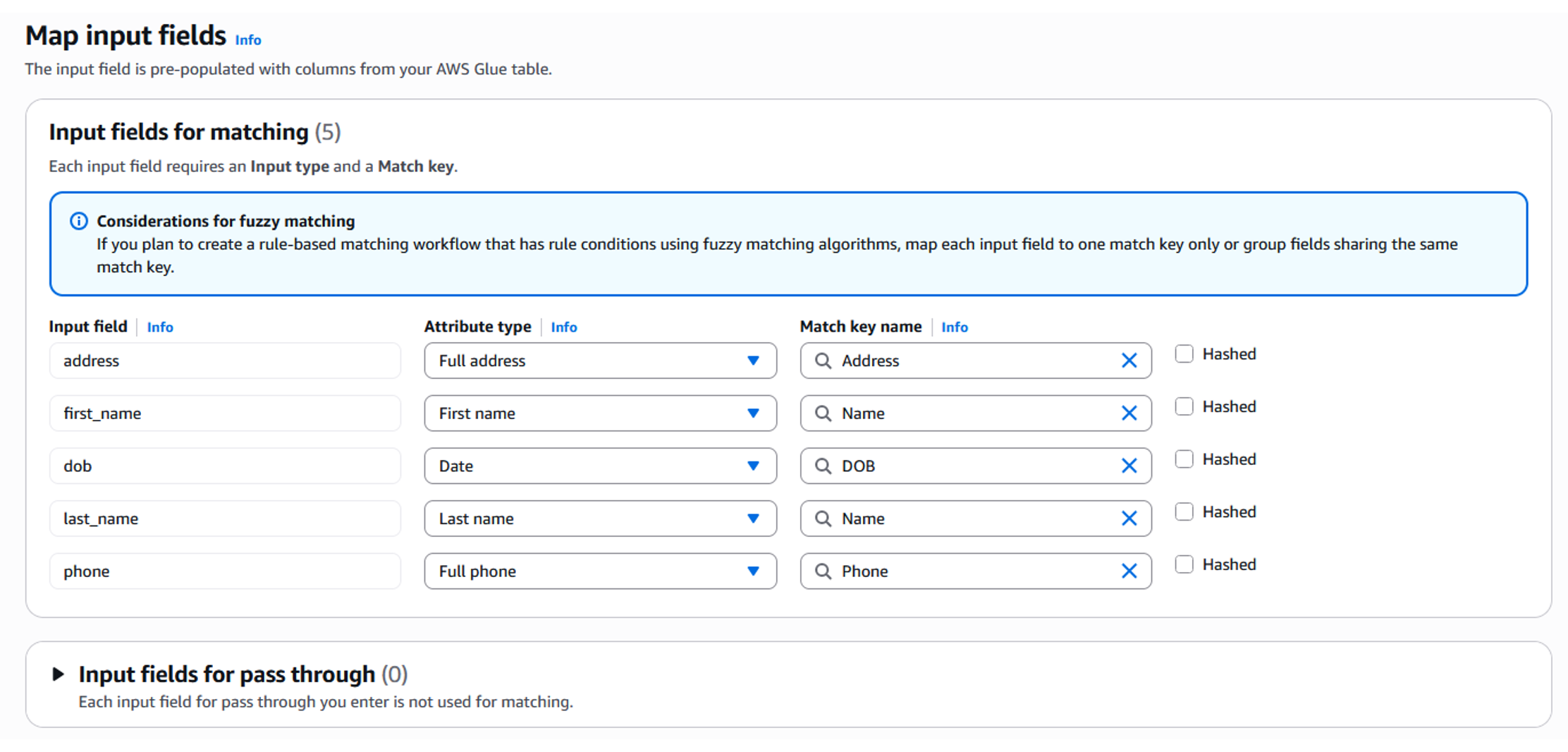 Figure 6: Schema mapping – Map index fields
Figure 6: Schema mapping – Map index fields
- Click next to proceed to creating a group. A group is a set of related input fields (such as First Name and Last Name) under a single “Name” column. Doing this will enable AWS Entity Resolution to compare them collectively, rather than individually during matching and similarity calculations—typically resulting in more accurate matches.
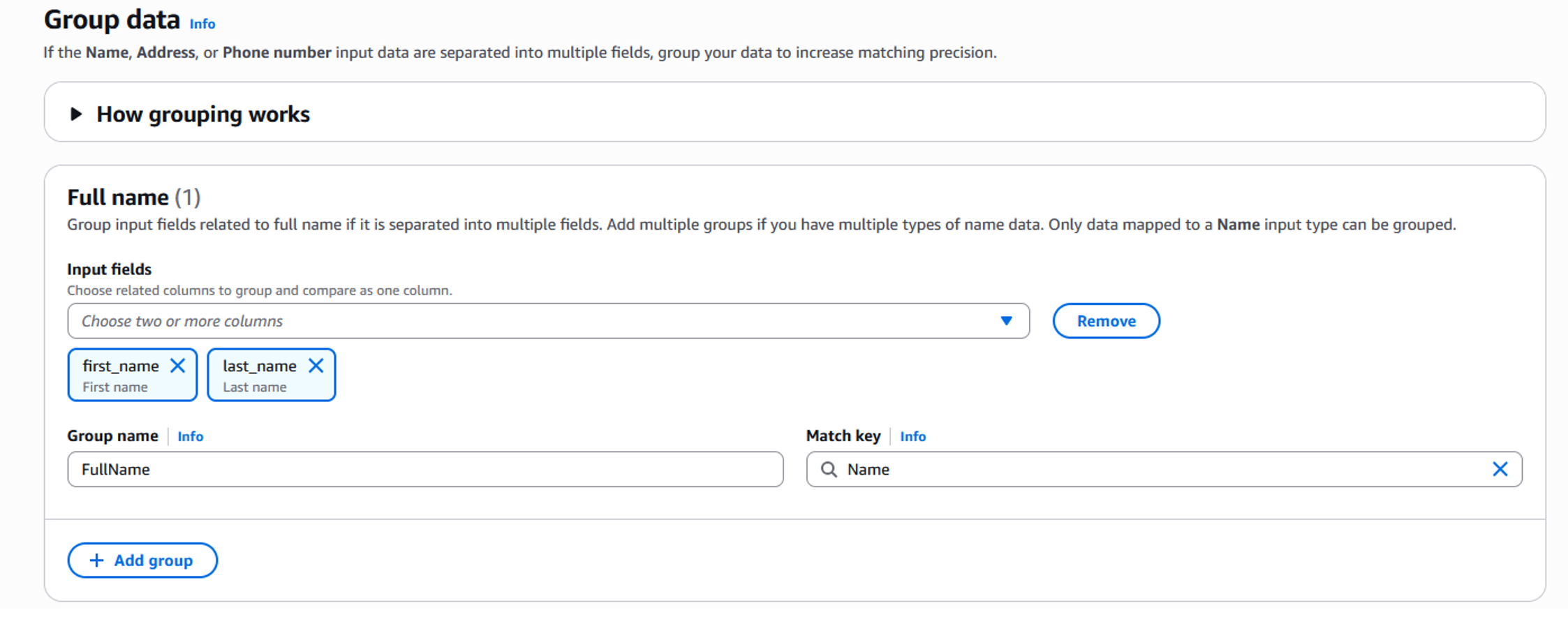 Figure 7: Schema mapping – Group fields
Figure 7: Schema mapping – Group fields
- Once the group configuration is set, click Next to navigate to the Review and Create
- Review all the configurations and click on Create schema mapping. This will create the schema mapping.
- Once the schema mapping has been created, the next step is to create a matching workflow. A matching workflow helps define the input the associated matching technique, rule, or machine learning need to match and link records across the sources. To create a matching workflow, select Matching from under the Workflows dropdown, located in the left side menu, and click on the Create matching workflow In the Specify matching workflow details screen add the workflow name. Our example is “Fuzzymatchingdemo”. Under the Data input area, you will need to select your appropriate AWS Glue database table, and schema mapping, which was created in the previous step (Figure 8).
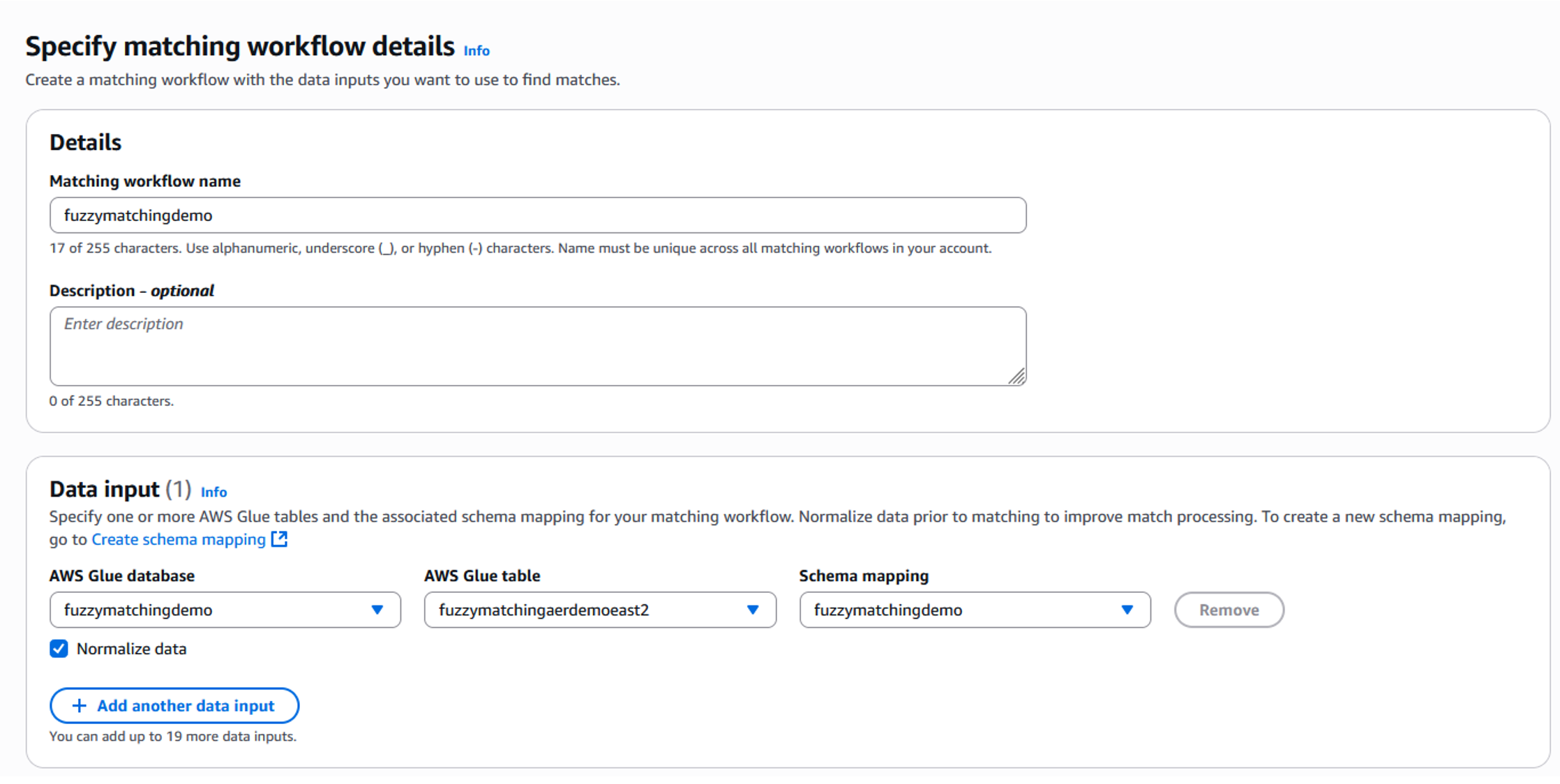 Figure 8: Matching workflow
Figure 8: Matching workflow
- In the Matching technique, select Rule-based matching and then select Advanced- new as the Rule type to use fuzzy matching algorithms.
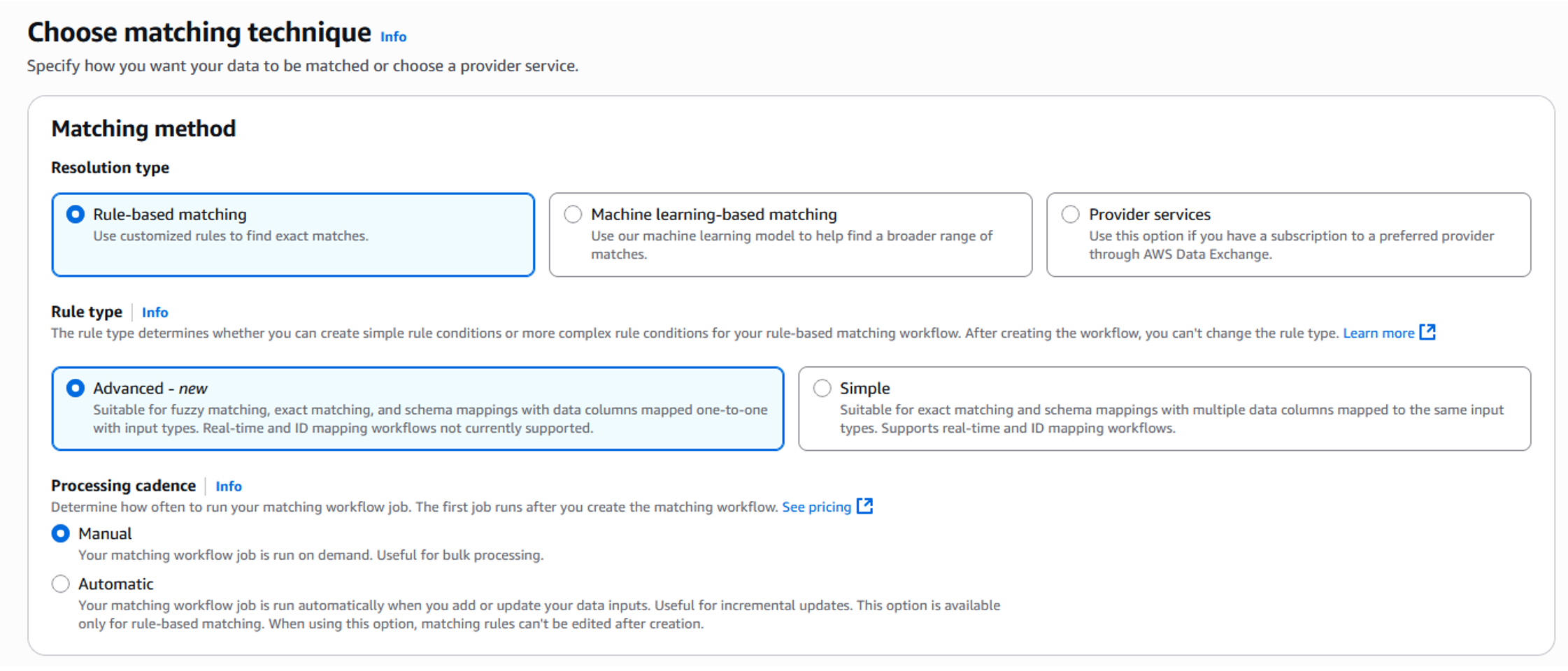 Figure 9: Matching technique
Figure 9: Matching technique
- In the Matching rules section, you can create rules and define conditions by choosing matching algorithms and appropriate thresholds for the algorithms from the dropdown list that align with your matching objectives (Figure 10). The advanced matching rule builder enables multiple matching algorithms to be applied to specific fields. You can combine two different algorithms using an “OR” condition to maximize match resolution accuracy. For example, you can apply both Soundex and Cosine algorithms to the “Name” attribute to capture different types of variations. Figure 11 shows a rule that we used to effectively deduplicate the example dataset.
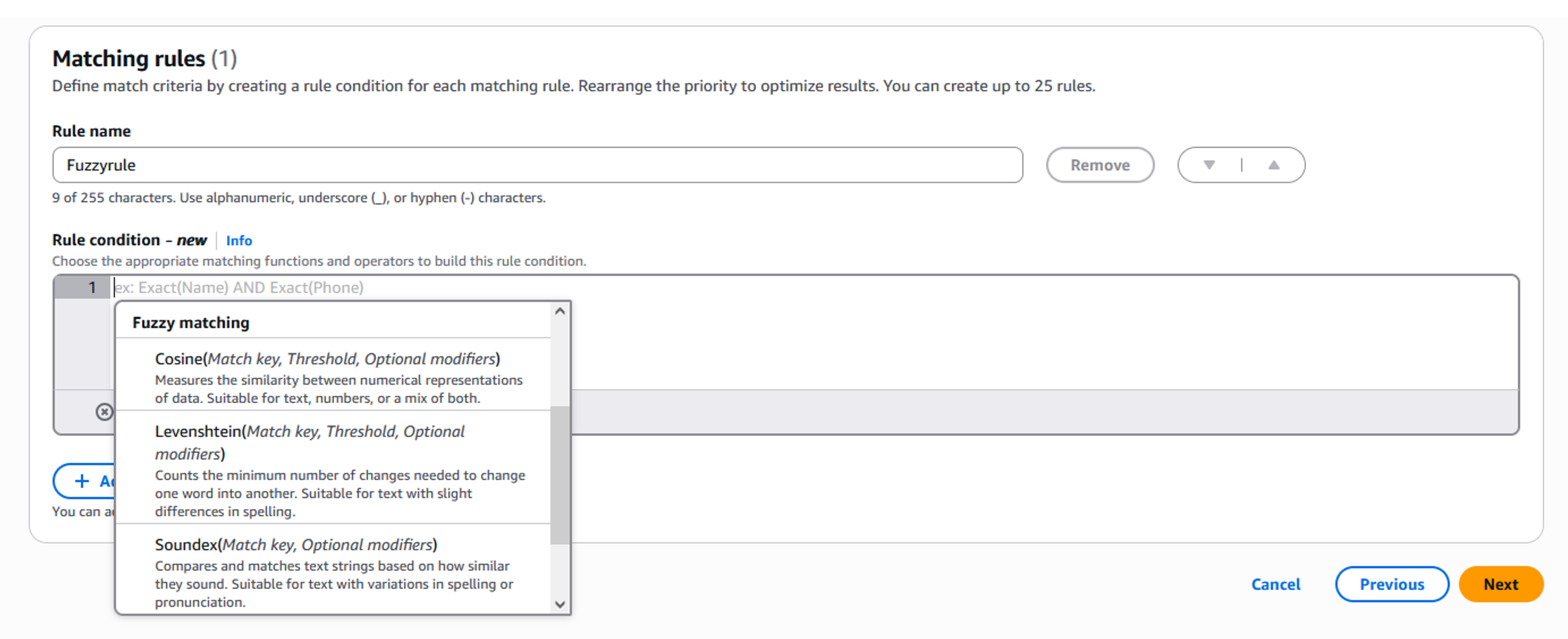 Figure 10: Fuzzy matching technique setup
Figure 10: Fuzzy matching technique setup
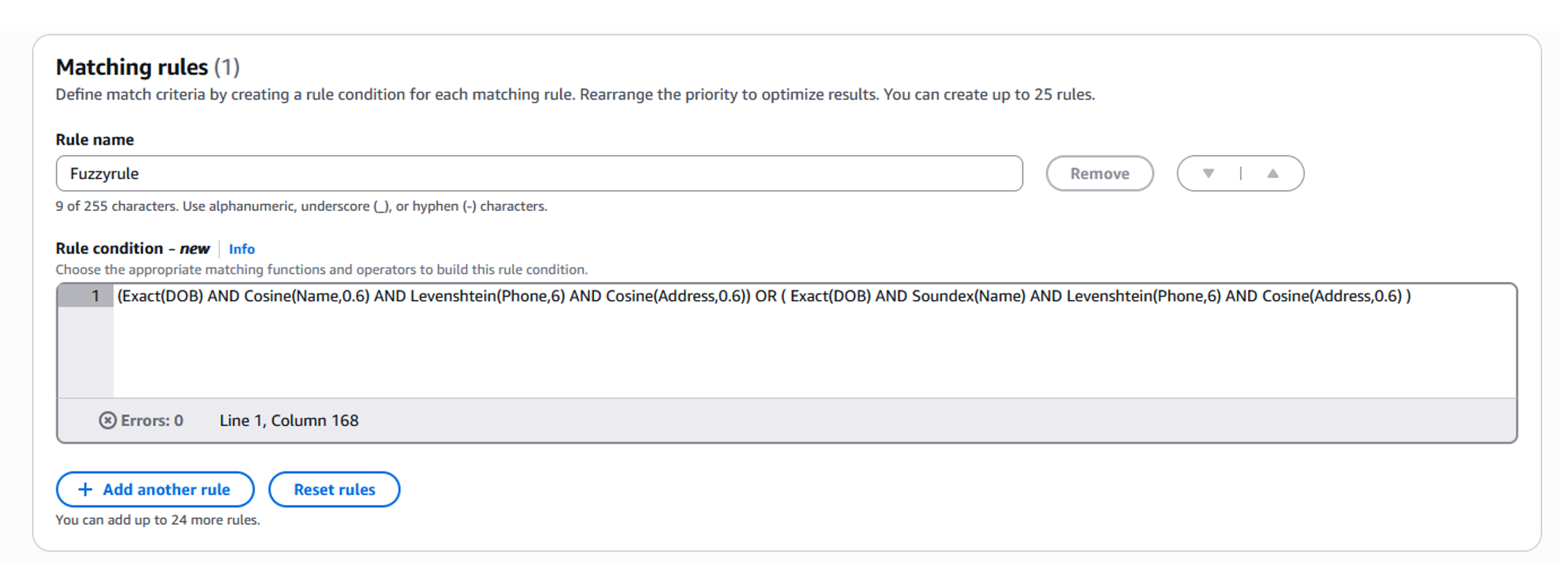 Figure 11: Fuzzy matching rule
Figure 11: Fuzzy matching rule
- As the final step, prior to creating the workflow, review all the configuration settings to confirm they accurately reflect your matching requirements, and click Create and run. This will create the matching workflow and initiate the first run.
After allowing some time for the job to complete (Figure 12), job metrics will show the number of input records processed, and the number of uniquely matched IDs generated. The output is written to the configured S3 bucket. You may navigate to the specified output S3 location and download the output files to analyze the result.
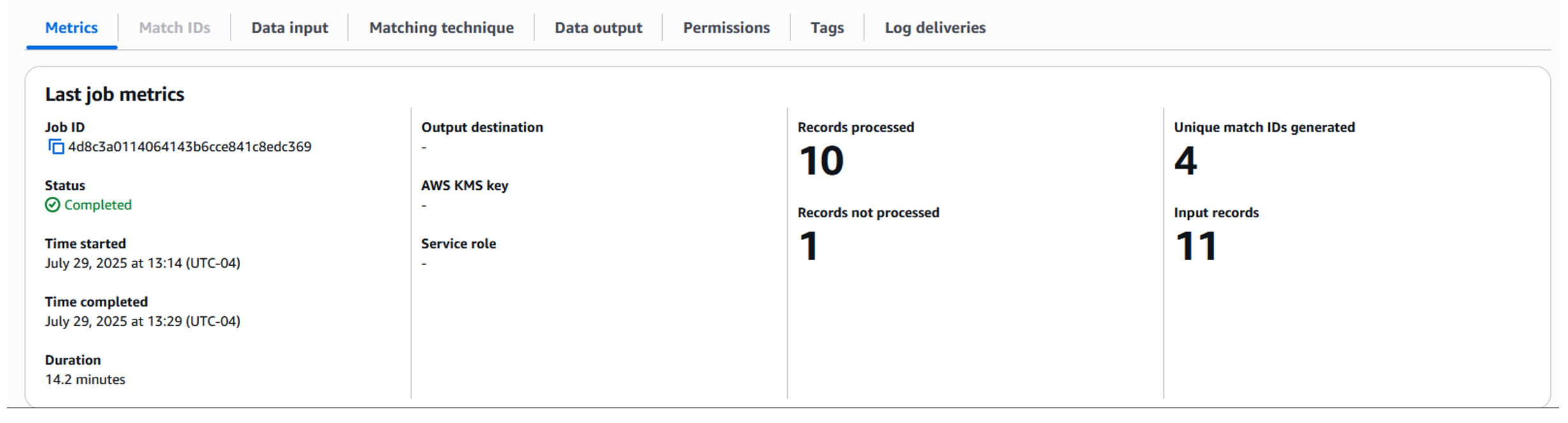 Figure 12: Fuzzy matching job metrics
Figure 12: Fuzzy matching job metrics
In the output data (Figure 13), each record in the output data receives an AWS Entity Resolution assigned MatchID. The matching records represent deduplicated entries from the dataset that meet the criteria defined in the MatchRule. The MatchRule field indicates which specific rule was applied to generate each matched record set.
 Figure 13: Fuzzy matching workflow output
Figure 13: Fuzzy matching workflow output
For the example dataset shown in our walkthrough, the AWS Entity Resolution fuzzy matching workflow generated four unique match keys that group related records together. The matching workflow successfully deduplicated records containing variations in Name, Address, and Phone fields, resolving them into four distinct entities.
Conclusion
AWS Entity Resolution advanced rule-based fuzzy matching delivers more flexibility to match real-world, imperfect data using fuzzy logic—without needing to write custom code. Whether you’re working in advertising, retail, finance, or healthcare, this feature can help you uncover hidden relationships in your data. Customers can now control and set appropriate thresholds on fuzzy logic for matching.
It’s a balanced approach for matching that combines the control of rule-based systems with the adaptability of ML-based, approximate matching. It improves match rates without sacrificing explainability.
To get started, visit the AWS Entity Resolution console, enable advanced rule-based fuzzy matching, and begin building intelligent workflows today or contact an AWS Representative to know how we can help accelerate your business.
Additional resources