AWS for Industries
Part 2: How BBVA processes a global data lake using AWS Glue and Amazon EMR
This is the second post of a six-part series detailing how BBVA | The digital bank of the 21st century a global financial services group present in over 25 countries throughout the world, with over 125,000 employees, serving over 76 million customers. On 2023, BBVA after selecting AWS as the cloud vendor for Data has designed, built and migrated a secure, and cost effective Global Data Platform namely ADA (Analytics, Data, AI) at scale with more than tens of thousands of processes, thousands of advanced users running hundreds of Data and AI Operations for the business, all with no service interruptions. A year later, the global cloud data platform is a reality. BBVA has successfully completed the full migration in Europe, Uruguay, Mexico, and Colombia to its ADA cloud platform. Given its success, the BBVA Group is now preparing to expand ADA in 2025 to the other countries in which it operates, including Peru and Argentina.
Read the entire series:
- Part 1: BBVA: Building a multi-region, multi-country global Data and ML Platform at scale
- Part 2: How BBVA processes a global data lake using AWS Glue and Amazon EMR
- Part 3: How BBVA built a global analytics and machine learning platform on AWS
- Part 4: Building a Multi-Layer Security Strategy for BBVA’s Global Data Platform on AWS
- Part 5: BBVA’s unified console: Key to successful global platform deployment
- Part 6: Effective sunset of the legacy data platform in BBVA: the migration methodology
Introduction
In this second installment of BBVA’s migration to a cloud-based data platform, we explore how the bank processes its global data lake using AWS Glue and Amazon EMR. The migration was driven by significant challenges in their on-premises data infrastructure, including computing resource limitations, inefficient data management, and operational constraints. By leveraging AWS services, BBVA aimed to create a more scalable, flexible, and secure data platform to manage its vast data assets and support growing user demands.
The on-premises environment faced several critical challenges, particularly the increasing demand for Spark cluster resources because of growing platform usage. The infrastructure was becoming insufficient, and procurement of additional resources involved lengthy approval processes, hampering agility and innovation. Data management was another major problem, as the lack of a centralized data catalog made it difficult to manage efficiently and discover data assets, leading to reduced productivity and potential data silos. The data lake also suffered from inefficient partitioning and many small files, causing performance bottlenecks.
The migration to AWS addressed these challenges through:
- Elastic computing capabilities that eliminated resource contention
- Improved data management using the AWS Glue Data Catalog
- Enhanced performance through better partitioning strategies
- Greater operational agility in job planning and execution
- Seamless migration using a wide variety of in-house frameworks, which allowed existing jobs to migrate transparently
The transformation leveraged key AWS components including Amazon S3 for centralized storage, AWS Glue Data Catalog for metadata management, AWS Lake Formation for fine-grained access control, and EMR for Spark workloads. This new architecture not only solved immediate challenges but also positioned BBVA to better handle future growth and innovation in their data analytics capabilities, with frameworks that can be quickly adapted to other processing engines like Amazon EMR on EKS or AWS Glue ETL.
Before migration, BBVA’s platform handled 55,000 daily batch jobs and supported over 6,500 sandbox users running clusters for data analysis. The architecture was built on two main components: a Spark-based processing layer and a data query layer to facilitate BI tool access. In modernizing this dual approach, BBVA integrated AWS services like Amazon EMR and AWS Glue for data processing, and Amazon Athena and Amazon Aurora for querying.
The AWS migration offered opportunities to address existing limitations, particularly in data cataloging. BBVA’s lack of a mandatory centralized catalog for on-premises tables created challenges in schema discovery and management, despite having a schema design tool. The absence of a “source of truth” complicated data extraction and schema modifications, requiring manual notification of changes to all data users.
Data access management was also streamlined during the migration. The system used a local storage solution with access controls that were difficult to manage due to frequent cross-departmental requests. These challenges were addressed through AWS services including AWS Glue Data Catalog, AWS Identity and Access Management (IAM), and AWS Lake Formation, providing a more efficient and centralized approach to data governance.
Solution overview
After a comprehensive analysis of technical requirements and proof-of-concept testing, BBVA implemented the following AWS-powered architecture for their ADA (Analytics, Data, AI) platform:
| Component | AWS service | Purpose |
| Storage Layer | Amazon S3 | Central data lake for raw and processed data |
| Metadata Management | AWS Glue Data Catalog | Centralized technical metadata repository |
| Access Control | AWS Lake Formation | Fine-grained data permissions management |
| Interactive Analysis | Amazon Athena | SQL queries for BI tools via JDBC |
| Spark Processing | Amazon EMR | Core Spark execution environment |
| Sandbox Processing | Amazon EMR and AWS Glue | EC2/Serverless Spark for experimental workloads |
| Relational databases | Amazon Aurora | Data storage for additional BI tools data |
Key Architectural Decisions:
- Multi-account strategy, separating production and sandbox environments, enabling safe experimentation before promoting validated solutions through automated pipelines to production
- Data tiering in S3, aligned with access patterns
- Cost optimization using EMR instance fleets with spot instances
Cataloging the data
One of the key requirements during BBVA’s migration was the proper cataloging of data to enhance control, management, and permission handling. To achieve this, BBVA opted for a combination of AWS Glue Data Catalog and AWS Lake Formation. The AWS Glue Data Catalog serves as a managed persistent technical metadata store, allowing BBVA to store, annotate, and share metadata in the AWS Cloud. AWS Lake Formation complements this by providing centralized governance, security, and global sharing capabilities for analytics and machine learning data.
This powerful combination enables secure and centralized access to data lake resources on Amazon S3 and its metadata in AWS Glue Data Catalog, eliminating the need to grant users or roles direct access to S3 data.
To ensure a successful platform migration, BBVA needed to create a centralized catalog in AWS. Although they didn’t have an on-premises catalog, they maintained a centralized registry where each project stored metadata and version history of their file formats. BBVA, in collaboration with AWS and other partners, developed a process to migrate this inventory data, including both initial synchronizations and incremental updates.
The data catalog migration process, described in detail in the part 6 of this series, used Step Functions, SQS queues, and Lambda functions to generate the catalog in AWS Glue Data Catalog from CSV files produced by the BBVA central schema management tool. This efficient process could load over 30,000 tables (some with up to 2,500 columns and over 100,000 partitions) in approximately 15 minutes for a complete initial load.
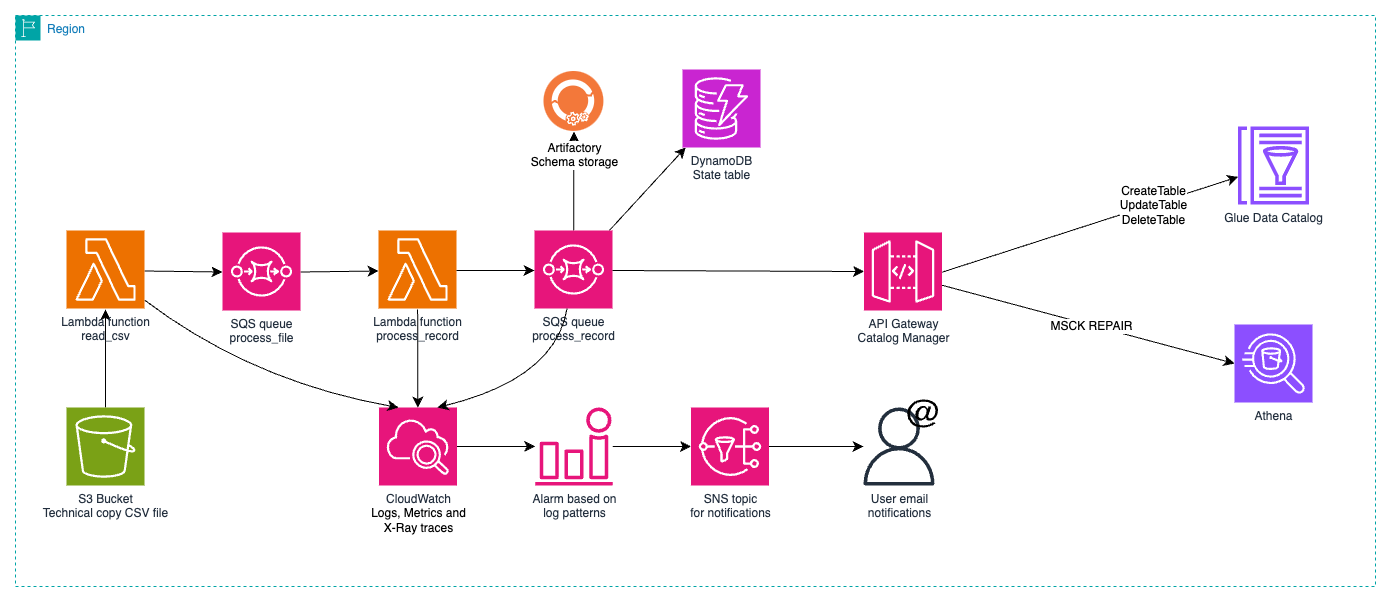 Figure 1 – Catalog migration architecture
Figure 1 – Catalog migration architecture
BBVA’s data flow incorporates several zones where data is transformed according to project needs and requirements:
- Staging-in zone: temporary storage for raw data as generated by source systems (CSV, JSON, etc.).
- Raw zone: temporary storage where data is converted to standard formats (Avro or Parquet) but not yet processed.
- Main zone: contains transformed and normalized data from the raw zone, stored in a common format (Parquet).
- The staging-out zone facilitates data exchange between the main zone and external systems.
A temporary data zone allows processes to use data as required by specific processing and analytics jobs.
BBVA’s ADA platform categorizes data into various security levels, from public to highly confidential, including a tokenized level for sensitive personal information to prevent it from being stored in clear text. To further strengthen data security, all information stored in the ADA platform is encrypted at rest using AWS Key Management Service (KMS) with Customer Managed Keys (CMKs). This approach gives BBVA full control over the encryption keys, allowing for more granular access management and meeting stringent regulatory requirements in the financial sector.
The combination of country, zone, and security level allows for data storage in different buckets, enabling better storage, usage, and auditing of data.

Figure 2 – Data storage zones
Access management for data lake resources is handled through AWS Lake Formation, aligning with BBVA’s organizational structure. To simplify managing permissions across many units and tables, BBVA implements LF-Tags for categorizing data lake objects and assigning permissions to principals. This approach is automated through the ADA console for efficient management at scale. This data access workflow is described in more detail in part 4 of this blog post series.
To streamline catalog management and enhance the user experience, BBVA developed a comprehensive API layer that abstracts the complexity of direct AWS API interactions. This custom API provides a robust set of functionalities for catalog management that align with BBVA’s governance policies and operational requirements. It enables users to perform operations like table creation, schema evolution, and automated partition maintenance through Athena. The API implements intelligent validation rules to ensure data integrity and compatibility during schema modifications, preventing potential issues that could affect downstream processes. A noteworthy feature is its automated handling of cross-business-unit, cross account, data access requests through AWS Lake Formation, incorporating both automated approval workflows for standard scenarios and manual approval processes for special cases that require additional oversight. The API is now central to BBVA’s data governance, processing many catalog management operations daily while ensuring compliance with internal policies and security requirements. Through the ADA Console, users can manage their data assets with point-and-click simplicity, while Datum leverages the API to maintain synchronization between business metadata and technical catalog information. This integration has improved efficiency by reducing the learning curve for users, enforcing standardization across the platform, and implementing consistent security controls while maintaining detailed audit trails of all catalog modifications. The API has become a cornerstone of BBVA’s data governance strategy, processing thousands of catalog management operations daily while ensuring compliance with organizational policies and security requirements.
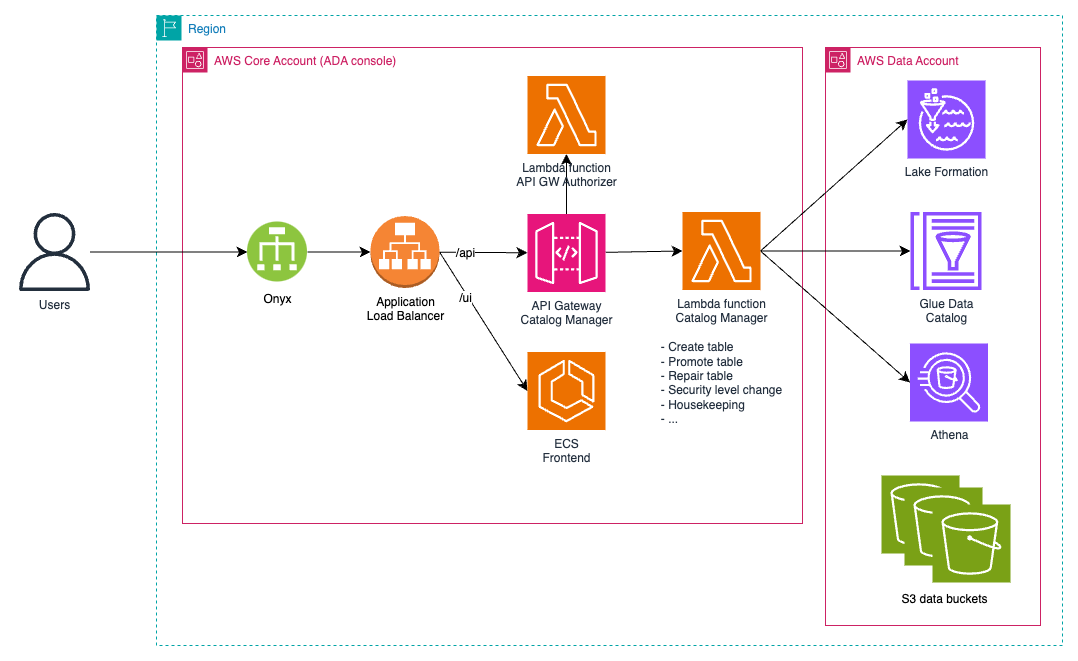
Figure 3 – Catalog Manager API
Storage optimization in ADA is achieved through the strategic use of S3 Intelligent-Tiering, which automatically moves data between access tiers based on usage patterns. This feature is valuable for a data lake of BBVA’s scale, where data access patterns vary across different zones. In the Raw and Main zones, where some datasets may experience periods of frequent access followed by long periods of inactivity, Intelligent-Tiering helps optimize storage costs without compromising data availability. The platform’s architecture automatically configures new buckets with Intelligent-Tiering, enabling a “set-and-forget” approach to storage cost optimization while ensuring that accessed data remains readily available for critical business operations.
To maintain effective oversight of the data lake’s growth and health, BBVA leverages S3 Inventory reports to gather detailed analytics about stored objects. These daily reports provide valuable insights into key metrics such as storage distribution across different zones (Raw, Main, Staging), object counts, size patterns, and storage class distribution. This information helps identify potential optimization opportunities, such as areas with high small-file fragmentation that could benefit from compaction processes, or datasets that might be candidates for archival. The platform’s operations team has developed automated dashboards using these inventory reports to track trends in data lake usage, enabling proactive capacity planning and cost optimization initiatives. For example, analyzing these metrics helped BBVA discover that a significant portion of their data lake comprised small files, prompting specific optimization efforts to enhance query performance and reduce costs.
Within the ADA platform, data quality assurance is supported by Hammurabi, an application that allows teams to define and enforce data quality rules. This tool performs comprehensive quality checks across different data layers, ensuring data integrity throughout its lifecycle. This validation framework is crucial for maintaining high data quality standards across BBVA’s global data lake, ensuring that subsequent analytics applications operate with reliable and consistent data.
Data processing architecture
The primary service used for data loading, processing, and analysis in this project is Amazon EMR. This service enables efficient execution of both batch and streaming workloads based on Spark, optimizing resource usage through EMR’s managed scaling, cluster auto-termination, and the use of instance fleets and spot instances. BBVA leverages all these features for efficient job processing. The choice of EMR on EC2 over EMR Serverless was primarily because of better cost-resource utilization for batch workloads, particularly by leveraging Spot instances for ‘Task’ nodes.
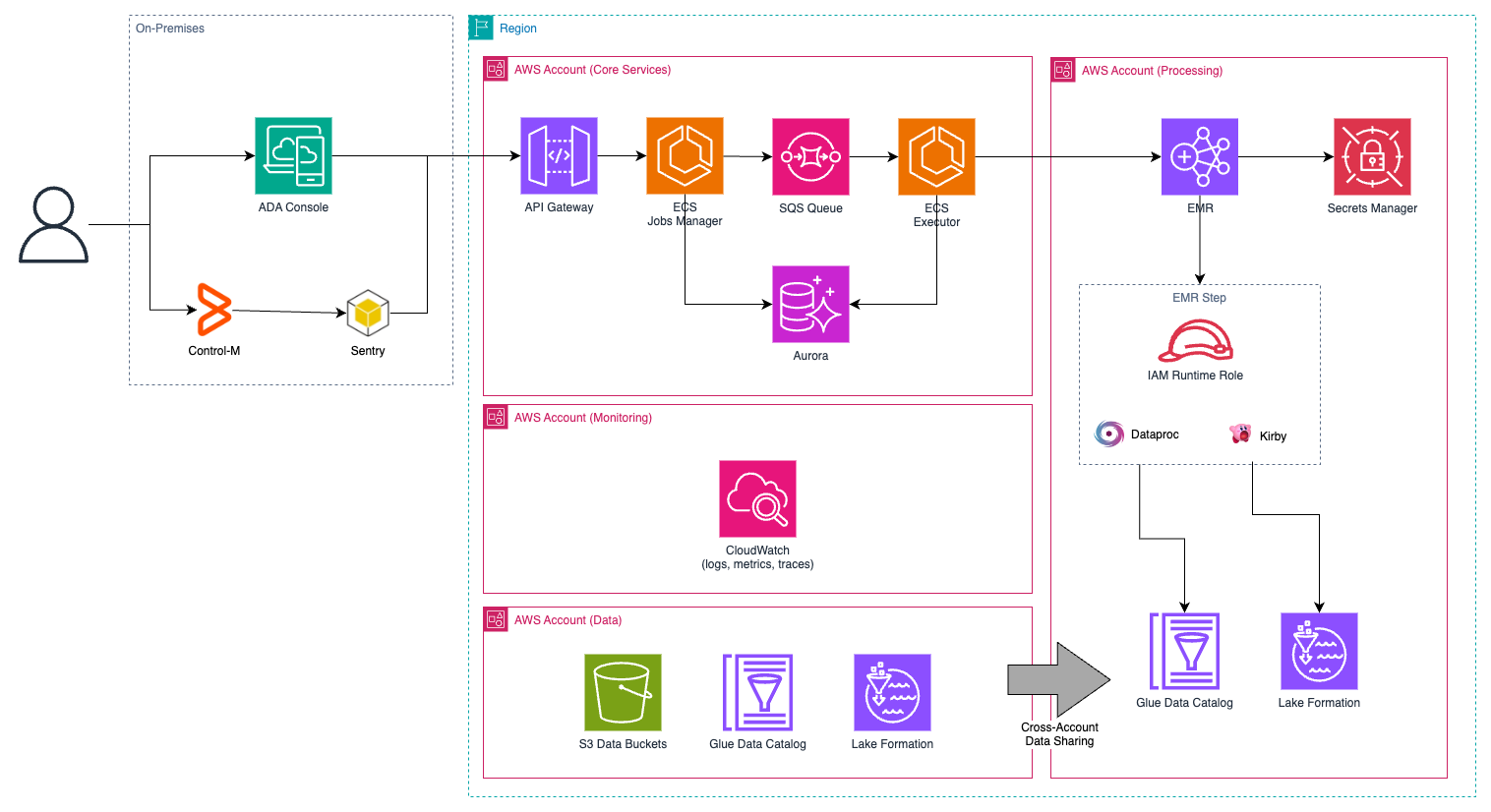
Image 4 – Job scheduler
Prior to the migration, BBVA had developed two frameworks to facilitate job creation for various teams:
- Dataproc SDK: a library that encapsulates Spark operations and offers some other utilities, simplifying data loading, transformation, and storage. It also enforces some security measures regarding tokenization and data structure validation.
- Kirby allows to define Spark jobs declaratively using a configuration file, eliminating the need to write Java, Scala, or Python code. Users define inputs, transformations (joins, conversions, column additions/deletions, etc.), and data destinations.
Given that a high percentage of BBVA’s jobs are based on these two frameworks, migrating jobs from on-premises to AWS was nearly transparent. The data lake backend, whether on-premises or in AWS, is transparent to the jobs. This functionality also allowed BBVA to validate the correct functioning of jobs in AWS by maintaining both environments for several months and comparing results to verify that job executions in different environments produced identical outcomes.
As a complement to EMR on EC2, the solution also provides support for running Spark jobs on AWS Glue using Glue Interactive Sessions for Sandbox users (explained in part 3 of this series). AWS Glue offers advantages for specific use cases, especially when quick experimentation is needed, as Interactive Sessions can be started more rapidly than EMR clusters. This makes it an excellent choice for data scientists and analysts who require fast access to computing resources for ad hoc analysis and development work, particularly in scenarios that don’t demand EMR’s full range of features such as complex cluster management or extensive node customization. The lightweight nature of Glue Interactive Sessions provides an efficient alternative for these focused use cases.
Batch jobs scheduling
BBVA uses a third-party scheduler as the orchestrator and scheduler for jobs. This component was not part of the migration proposal, as it serves other areas of the department and is integrated with many external systems that would be complex to migrate. Therefore, this scheduler has been integrated into the ADA platform.
At BBVA, users define the schedule of their jobs and their dependencies, configuring a complete workflow according to their needs. With the current corporate task scheduler versatility, the ADA team had to develop an intermediate component between that scheduler and the job management API deployed in AWS. This component receives requests from the scheduler, makes calls to the scheduler API in ADA, and returns the job execution status back so it can store the state and continue executing dependent jobs.
The custom job scheduler processes execution requests through an API Gateway in the core account, as detailed in part 5 of this series. These requests are stored in an internal Amazon RDS database, which the job scheduler continuously monitors to pick up and submit jobs to the appropriate EMR clusters.
The job scheduler developed by the ADA team allows for complete and agile management of both EMR clusters and the steps that run on them. This scheduler implements the following functionalities, among others:
- Creation and rotation of clusters
- Cluster termination
- Job execution and monitoring
- Job queue management
- Job concurrency within the same cluster
- Different cluster types (CPU optimized, memory optimized, GPU optimized, etc.) that users can choose when configuring their jobs
- Various sizes that users can configure in their jobs according to resource requirements, which translate into vCPUs and RAM established when launching the step
- Different clusters by country
- Job cost management based on size and execution time
As cost control is a primary project objective, BBVA maintains its on-premises model where each job configuration specifies its size. This translates into defined resource allocation, enabling BBVA to more effectively manage and control costs based on usage, and to attribute these costs to relevant teams or departments using the platform.
BBVA also uses spot instances in EMR clusters. Using this type of instance represents significant cost savings compared to on-demand instances and is especially recommended for workloads that can be resumed from the same point in case of interruption. This is possible in ADA’s case since spot instances have been chosen only for task nodes, which only perform data processing, while maintaining on-demand instances for primary and core nodes, where Spark drivers are configured to be located. This configuration ensures stability for essential cluster functions, as these nodes handle data storage and task coordination, making them sensitive to interruptions. If a spot instance task node is interrupted, the system automatically retries the task on another available node.
Conclusion
BBVA’s migration to AWS has resulted in a more scalable, flexible, and secure data platform. The ADA (Analytics, Data, AI) cloud platform has not only addressed the challenges of resource constraints and lengthy approval processes but has also paved the way for more innovative data-driven solutions. Main benefits of the migration include:
- Improved scalability: The cloud-based solution allows for dynamic resource scaling, optimizing costs and performance, and reducing batch execution time by leveraging AWS cloud-based resources to spin up or shut down processing clusters as needed, depending on the business requirements, eliminating on-premises limitations that existed in the past.
- Enhanced data governance: implementing AWS Glue Data Catalog and AWS Lake Formation has improved data cataloging and access management. With additional tools like S3 Inventory, BBVA has reduced storage costs by evaluating and optimizing data storage tiers. These services have helped to reduce the time required for data availability from weeks to minutes via automatic data cataloging and access management workflows available through the BBVA ADA console.
- Future-ready architecture: The new platform incorporates technological innovations such as real-time data processing and unstructured data management or additional processing engines such as EMR Serverless, EMR on EKS or Glue, unlocking the full potential of artificial intelligence in BBVA’s solutions.
This successful migration underscores BBVA’s commitment to technological innovation and positions the bank as a leader in democratizing the use of data. As BBVA continues to expand the ADA platform to other countries in which it operates, including Mexico, Colombia, Peru, and Argentina, it is well-positioned to drive digital transformation in global banking.