AWS for Industries
Integral Ad Science scales over 100 M documents with Amazon OpenSearch Service
With explosive growth in content volume across social media platforms and the imperative for real-time machine learning (ML) model training, Integral Ad Science (IAS) required a solution. It needed to be capable of facilitating ongoing content classifier development, mitigating manual annotation delays, and maximizing processing throughput during peak demands.
IAS stands as a global leader in digital media measurement and optimization, committed to setting the standard for trust and transparency in digital media quality. Their data-driven technologies deliver actionable real-time insights and comprehensive, enriched data, ensuring advertisements reach genuine audiences in secure and suitable environments.
We will delve into how IAS harnesses Amazon OpenSearch Service and constructed a robust, scalable Software-as-a-Service with machine learning platform. Their platform processes over 100 million documents daily, while achieving a 40-55% boost in performance for complex search operations compared to the project’s inception.
Challenges
Traditionally, data science teams grapple with protracted manual and semi-automated annotation workflows, extending days or weeks. The aim was to create a unified ML platform that empowers self-service workflows, organization-wide, for data scientists and engineers, while adhering to performance and compliance mandates.
Critical requirements included:
- Processing high-dimensional vector embeddings for similarity search
- Enabling real-time indexing and querying
- Supporting the automated retraining of hundreds of ML classifiers
Vector database evaluation
There was an extensive evaluation process of vector database solutions using a custom benchmarking framework built with Apache Spark™ and run on the Databricks platform.
The team evaluated multiple solutions across several critical performance dimensions including:
- Similarity search queries every second
- Bulk record writing throughput
- Bulk record reading throughput
- Native Spark integration capabilities
OpenSearch Service was chosen for its superior performance, cost-effectiveness, Amazon Web Services (AWS) integration, and strong community backing.
Various other approaches were considered, including traditional databases with custom vector indexing, specialized vector database services, and open-source solutions. Other solutions did have their strengths, but did not fully meet the unique requirements of cost efficiency and throughput, while providing the comprehensive ML experience the teams required.
Solution overview
After an extensive evaluation review, IAS elected Amazon OpenSearch Service and Amazon Managed Streaming for Apache Kafka (Amazon MSK) as the strategic foundation. The architecture supports both real-time processing and historical analytics across hot and cold storage tiers. Vectors and metadata stream through Amazon MSK for reliable and scalable ingestion. Spark-based consumer processing micro batches are sent to Amazon OpenSearch Service for real-time vector search (the Hot Layer) and Delta tables on Databricks for long-term analytics (the Cold Layer).
The following diagram illustrates the solution architecture.
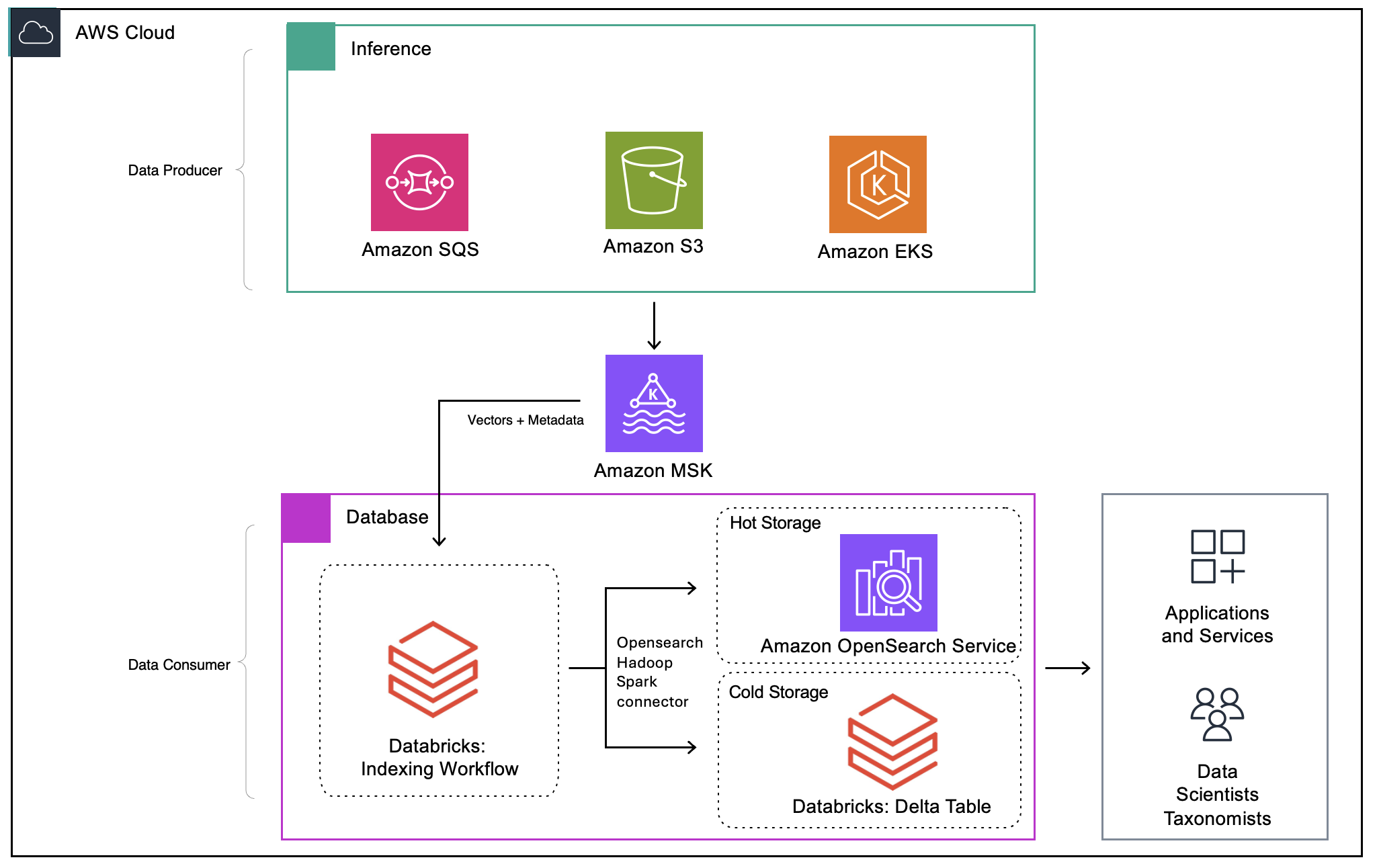
Figure 1. The solution architecture
The vector search capabilities of OpenSearch Service, along with a rich set of filtering API’s, are now available to data scientists, knowledge workers, and developers through notebooks, custom applications, and workbench and portal types of GUI’s.
Solution optimizations
The OpenSearch Service cluster configuration underwent several optimization phases to achieve target performance, with instrumental support from the AWS team helping overcome initial performance bottlenecks and configuration challenges. The team migrated from AWS Graviton3 processors r6g to r7g instances, upgraded from OpenSearch Service version 2.13 to 2.19, and enabled the Concurrent Segment Search feature.
The index mapping of OpenSearch Service was optimized to support high-dimensional vector embeddings with efficient k-Nearest Neighbor (k-NN) search capabilities. This involved configuring 1,024 dimensional vector fields using the Hierarchical Navigable Small Worlds (HNSW) algorithm with inner-product similarity, alongside appropriate metadata field mappings for filtering operations. The vector fields also optimized parameter settings for construction and search performance. IAS was able to achieve cost reductions by leveraging the Scalar Quantization feature in OpenSearch Service.
Performance optimizations included efficient k-NN filtering, shard optimization with tuned shard count and sizing, and memory management through adjusted Java Virtual Machine (JVM) heap settings and enabled Concurrent Segment Search. These optimizations contributed to performance improvements ranging 40-55% for regular searches. Some complex filtered operations showed improvements up to 80%, and the most dramatic gains in complex filtered searches improved from over 20 minutes to under one minute.
Looking ahead, IAS is evaluating migration to OpenSearch Service 3.0, which promises additional performance improvements. These could include up to 20% aggregate performance gains, significant reductions in high-cardinality aggregation latency, and enhanced vector database capabilities with potential GPU acceleration support.
Indexing optimizations
The data ingestion pipeline leverages Amazon MSK as the central streaming backbone, configured with 10 partitions and a replication factor of three for high availability. The pipeline processes data through several stages to confirm reliable, high-throughput document processing. A continuously running Spark job consumes Kafka topics, optimizing throughput and latency. Micro batches write simultaneously to both the OpenSearch Service and Delta tables, maintaining consistency across storage layers.
Through this architectural change IAS can safely index high-volume document streams into OpenSearch Service without overfeeding the cluster, providing better throttling control over the indexing process.
Significant indexing performance improvements were realized by integrating the OpenSearch Service-Hadoop Spark Connector, allowing k-NN filtering capabilities and enhancing processing volumes. Parallelization of writes to Hot and Cold Layers further boosted vector document indexing performance from 60 M to over 100 M documents daily.
IAS contributed a pull request to the OpenSearch Service-Hadoop connector to enable k-NN filtering capabilities, demonstrating the collaborative nature of OpenSearch Service and verifying the solution met their specific industry technical requirements. This integration was essential for achieving the target processing volumes while maintaining system stability.
Benefits
The solution provides scalable Software-as-a-Service with machine learning capabilities to IAS data scientists, engineers, and knowledge workers. Internal users can train and deploy classifiers with their choice of tools, while maintaining high performance at massive scale. The approach of using Amazon OpenSearch Service for vector search reduces the infrastructure complexity and manual processes required.
The solution provides the following additional benefits:
- Enables continuous classifier retraining based on new data arrivals
- Significantly reduces annotation cycle times from days or weeks to just a few hours
- Scales efficiently to handle over 100 million documents daily with spiky traffic patterns
- Supports multi-tenancy across different teams and business units
- Maintains data retention compliance with high index churn
- Reduces time to deploy new ML models and experiments for data science teams
It’s also important to note the flexible nature of the adopted architecture. The IAS vector database stack’s flexible configuration allows for quick adaptation to new use-cases. Using AWS Cloud Development Kit (AWS CDK), IAS is able to replicate the solution across teams, while maintaining a consistent cost attribution for team-by-team budgeting considerations.
Conclusion
When IAS started this journey, the company was looking for a scalable solution that would enable vector database capabilities while meeting stringent performance and cost requirements. Amazon OpenSearch Service provided IAS with the functionality needed to deliver on this promise for its data science teams. With vector search optimization and architectural improvements (including Amazon Managed Streaming for Apache Kafka integration), IAS achieved substantial performance gains, while maintaining cost efficiency.
IAS continues to expand the platform across multiple business units, with plans to support much larger numbers of classifiers as the Software-as-a-Service with machine learning solution scales. More use-cases are likely to be added to the pipeline as well.
Contact an AWS Representative to know how we can help accelerate your business.