AWS for Industries
How to Implement MLOps for Industry 4.0
As automotive manufacturers look to optimize efficiency while maintaining product quality, we increasingly see companies turning to solutions based in artificial intelligence (AI) for process automation and optimization.
The ultimate objective of such endeavors is to replace current labor-intensive and error-prone activities that require skilled operators—such as quality control, asset maintenance, and process optimization, among others—with automated, AI-based assistance. These solutions can reduce time required by such operators on these tasks, while introducing stable processes that can be seamlessly replicated across production lines, divisions, and plants.
While such solutions have shown that they can deliver desired business outcomes when implemented well, they shift challenges from enterprise operational technology (OT) to enterprise information technology (IT) organizations. The latter are increasingly responsible for AI assistants in a heterogeneous, constantly evolving, and globally distributed manufacturing environment.
Achieving cost optimizations in the management of such assets requires lean, high-performance IT teams.
In this blog post, we will provide prescriptive guidelines and a reference architecture for a hybrid (on-premises/cloud) machine learning operations (MLOps) pipeline (the “Solution”) that addresses the aforementioned technical challenges while also breaking down organizational barriers.
This blog post is organized in six sections describing the Solution’s core components
1. High-level solution architecture
The following high-level diagram presents the recommended infrastructure for managing an MLOps pipeline in a typical automotive-manufacturing hybrid infrastructure.
This solution uses AWS cloud services to bring compute scalability and cost savings (through a pay-as-you-go model) to the training and managing of ML models while meeting the low latency required for ML inferences not to adversely affect operation cycle times.

Figure 1. A solution for managing an MLOPs pipeline in a hybrid automotive manufacturing infrastructure
2. Adopt a Unified Namespace
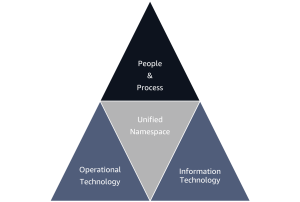
A Unified Namespace (UNS) serves as the foundation for rapid deployment and flexible integration of MLOps solutions across manufacturing environments. By implementing a standardized publish/subscribe messaging fabric, UNS creates a single source of truth that decouples data producers from consumers, facilitating seamless integration of both legacy systems and new AI/ML applications. Instead of building point-to-point integrations for each new use case—which creates technical debt and increases maintenance complexity—UNS facilitates an arrangement in which assets publish data just once while multiple applications may subscribe as needed. That architectural pattern is crucial for MLOps pipelines, as it provides several key benefits:
- It facilitates consistent data collection and contextualization across different plants and production lines, helping make sure that ML models are trained and deployed using standardized data formats regardless of underlying equipment or systems.
- The asynchronous nature of UNS facilitates near real-time data streaming with millisecond-level latency, empowering ML models to operate within production-cycle time constraints while maintaining the ability to collect and store training data in the cloud.
- By implementing open standards like MQTT and Sparkplug B, UNS creates a vendor-neutral data layer that can integrate both modern and legacy systems without requiring extensive modifications to existing infrastructure. That is especially valuable in manufacturing environments where equipment life cycles can span decades and replacing systems may be cost-prohibitive.
- It supports horizontal scalability through a governed topic taxonomy that can be replicated across facilities, empowering organizations to rapidly deploy ML models to new production lines or plants while maintaining consistent data structures and quality.
The combination of these capabilities makes UNS an essential tool for organizations looking to scale their MLOps initiatives beyond pilot projects and into production-wide use. By providing a standardized data foundation that bridges OT and IT systems, UNS helps reduce dependencies between teams by breaking down data silos and accelerating implementation of AI-driven manufacturing solutions.
3. Define, enforce, and monitor AsyncAPIs
In modern industrial operations, AsyncAPI has emerged as a critical specification for defining and documenting asynchronous applications in a machine-readable format. This open-source initiative aims to simplify working with event-driven architectures (EDAs) and make them as straightforward to implement as traditional REST APIs.
The proposed edge Solution, described in the following section, leverages AsyncAPI specifications to standardize data communication across manufacturing environments. By implementing a multithreaded MQTT-based system, it facilitates the use of configurable dispatchers and processors that dynamically adapt to varying workloads while maintaining data consistency. A critical component of this approach is the integrated payload validator, which helps protects data integrity across all manufacturing sites.
The payload validator examines messages in near-real time against predefined AsyncAPI specifications, storing validation results in cloud-based instances on Amazon Relational Database Service (Amazon RDS), a simple-to-manage relational database service optimized for total cost of ownership. A React-based web application provides comprehensive visibility into compliance statuses, empowering organizations to monitor and improve their standardization efforts.
By adopting AsyncAPI, manufacturers can create a more flexible and scalable data processing layer that supports them in rapidly adapting to new data integration requirements between systems and tools while maintaining consistent communication standards across diverse industrial environments.
4. Implement a flexible and scalable on-premises layer for data processing and ingestion
Modern industrial operations generate unprecedented amounts of data from diverse sources, including IoT sensors, manufacturing equipment, and control systems. Processing this data effectively requires an edge-computing architecture that can accommodate high-frequency data ingestion from multiple sources while maintaining data quality. The system must support near-real-time data validation and monitoring to promote accuracy and reliability. Additionally, it needs to provide low-latency model inference capabilities and flexibility for deploying new models without service interruption. Those requirements must be met while supporting scalable processing across distributed edge locations so that firms can handle growing data volumes and evolving business needs.
A sample edge reference architecture is depicted in the figure below. This integrates several critical components such that they work in harmony. At its core, the data ingestion layer implements a multithreaded MQTT-based system capable of processing high-volume data streams from UNS brokers. The system uses configurable dispatchers and processors that dynamically adapt to varying workloads, facilitating efficient parallel processing while maintaining data consistency. The architecture provides a foundation for handling the diverse data requirements of modern manufacturing operations.
 Figure 2. An edge solution that harmoniously integrates different components
Figure 2. An edge solution that harmoniously integrates different components
A critical feature of this system component, is an integrated payload validator, which plays an important role in scaling Industry 4.0 initiatives across multiple facilities. Using AsyncAPI specifications as a standard document format, the validator helps facilitates data consistency across manufacturing sites. The validator examines messages in near-real time against predefined AsyncAPI specifications, storing validation results in cloud-based timeseries or blob storage. A React-based web application provides visibility into compliance statuses across facilities, helping organizations monitor and improve their standardization efforts systematically.
For model deployment and inference, the architecture uses Kubernetes for container orchestration. That approach provides for dynamic scaling of inference end points in order to meet varying demand levels. With standardized data flowing through the system, organizations can easily deploy and update ML models across their facilities. The Kubernetes-based infrastructure facilitates near-zero-downtime updates and efficient resource allocation for inference workloads, allowing continuous operation even during system updates.
5. Adopt a Lakehouse architecture as the cloud main-data storage layer
An architecture that uses Amazon SageMaker Lakehouse—which unifies all of an organization’s data across Amazon Simple Storage Service (Amazon S3) data lakes—combines the best elements of data lakes and data warehouses to provide a unified platform that supports the diverse data access patterns required by MLOps workflows in manufacturing environments. By implementing a Lakehouse on AWS, organizations can maintain raw data in cost-effective Amazon S3 storage while facilitating high-performance Structured Query Language (SQL) access to data. Data scientists can perform data discovery and analytics using flexible interfaces like the SQL editor within Amazon Athena, through dashboards in Amazon QuickSight. This architecture is particularly crucial for manufacturing MLOps as it helps addresses several key requirements:
- First, it provides a single source of truth for ML processes—such as training, validation and testing, data analytics, and report production—all implemented across the same data, facilitating consistent model development and production deployments and reports.
- Second, it facilitates efficient storage-tiering through Amazon S3 life cycle policies, empowering organizations to automatically move historical training data to cost-effective storage classes while keeping frequently accessed training and inference data readily available. This is especially important for keeping the platform cost-effective, as the volume of data managed in industrial scenarios can easily grow into terabytes of data per month when solutions scale to different manufacturing processes, areas, and plants.
- Third, the architecture supports both batch and streaming ingestion patterns through services like Amazon Managed Streaming for Apache Kafka (Amazon MSK)—a service for securely streaming data with a fully managed, highly available Apache Kafka service—and Amazon S3, which are essential for handling near real-time sensor, alarm, and inference events that need to be processed in milliseconds.
- Fourth, it provides robust data governance and security through AWS Lake Formation, a service for centrally governing, securing, and sharing data for analytics and ML, facilitating fine-grained access controls and audit capabilities critical for maintaining the right level of data access in a global solution, in which different type of users from around the world consume the same data sources, a common scenario in manufacturing environments.
The Lakehouse model also helps facilitates seamless integration with analytics services like Amazon Athena for ad-hoc analysis and Amazon SageMaker, which brings together widely used AWS ML and analytics capabilities, for model development while supporting open-source formats like Apache Parquet that optimize query performance and reduce storage costs.
By adopting a Lakehouse architecture, organizations can create a scalable, flexible foundation that supports both current MLOps needs and future extensibility as manufacturing processes evolve and new use cases emerge.
The Lakehouse architecture also creates a seamless data experience for data scientists. Instead of wrestling with disparate data sources and complex extract, transform, load processes, data scientists can focus on what matters most—deriving insights and building effective models. One advantage of this architecture for data scientists is unified data access, which allows data scientists to use familiar tools like the Amazon Athena SQL editor or Amazon SageMaker notebooks to query manufacturing data without worrying about its physical location or storage format. The combination of Amazon S3 storage and AWS Glue—a serverless service that makes data integration simpler, faster, and cheaper—along with the AWS Glue Data Catalog creates a seamless experience in which data appears as organized tables rather than disconnected files. By standardizing on open formats like Apache Parquet, the proposed Solution empowers data scientists to work with optimized datasets that facilitate fast queries and efficient model training. When exploring new hypotheses, data scientists can spin up ad-hoc analyses using Amazon Athena or Amazon QuickSight without waiting for IT to provision specialized infrastructure.
For ML development, Amazon SageMaker Pipelines—a serverless workflow orchestration service purpose-built for MLOps and LLMOps automation—becomes the centerpiece of our MLOps strategy, offering the data scientist a structured yet flexible approach to model development. We can focus on model experimentation while Amazon SageMaker automatically tracks code versions, input datasets, hyperparameters, and model metrics. This arrangement helps empower data scientists to write custom code for standard ML tasks such as data transformation, feature engineering, and preprocessing.
Take the example of welding-anomaly detection. The data scientist can concentrate on crafting an autoencoder architecture and optimizing its performance rather than managing training infrastructure. With the architecture described above, the data scientist can easily scale the entire ML pipeline—preprocessing, training, and evaluation—using millions of data points without running into compute infrastructure issues. For the data scientist, the following steps become seamless:
- Reading training, validation, and test datasets
- Building and training the autoencoder model
- Analyzing the reconstruction error distribution to establish anomaly thresholds
This streamlined approach empowers data scientists to iterate rapidly on model architecture, feature selection, and threshold optimization—the core technical challenges of anomaly detection—without getting bogged down in operational details.
6. Automate, automate, automate
In the globally distributed landscape of automotive manufacturing, automation is not just beneficial for IT teams —it’s essential. Small IT teams in automotive manufacturing enterprises face the daunting challenge of managing AI solutions across multiple plants, divisions, and geographies, often spanning different time zones and operating environments. Without robust automation, such teams would be overwhelmed by the sheer volume of operational tasks required to maintain model performance and system reliability.
MLOps automation can be a force multiplier, empowering small teams to achieve what would otherwise require significantly larger staffing. By automating model training, validation, deployment, and monitoring processes, organizations can eliminate repetitive manual tasks and help reduce human error. That is particularly important when managing dozens or hundreds of models across various production lines and facilities.
The proposed Solution in this blogpost uses infrastructure-as-code principles and continuous integration and continuous delivery (CI/CD) pipelines to automate the entire MLOps life cycle. Code changes trigger automated testing, model retraining, and validation before seamless deployment to production environments. Automated canary deployments and rollback mechanisms help make sure that new models are safely introduced without disrupting operations.
Monitoring automation provides early detection of model drift and performance degradation, triggering alerts or automatic retraining when necessary. Such a proactive approach maintains model accuracy without requiring constant human supervision.
Through comprehensive automation, automotive manufacturers can achieve consistent model performance across global operations while maintaining the lean IT staffing essential for cost-effective digital transformation.
Conclusion
The implementation of AI-based solutions in automotive manufacturing presents both significant opportunities and significant challenges for OT and IT teams. The proposed hybrid architecture and MLOps pipeline that we’ve detailed in this blog post offers a robust framework that helps bridge the gap between operational requirements and IT capabilities while addressing key industry concerns:
- Operational efficiency: By using cloud resources for training and management while maintaining on-premises inference capabilities, organizations can optimize their AI deployments without compromising production-cycle times.
- Cost management: The proposed architecture helps facilitate more efficient resource utilization by IT teams, empowering them to maintain multiple AI solutions across global operations, thereby helping them achieve the intended cost reductions.
- Quality and reliability: The standardized MLOps pipeline provides for consistent model performance and more reliable deployments across different production environments, helping maintain the high-quality standards essential in automotive manufacturing.
- Scalability: The hybrid approach provides the flexibility to scale AI solutions across multiple plants and production lines while maintaining centralized control and governance.
As the automotive manufacturing industry continues to evolve, solutions like the proposed Solution in this blogpost provide a foundation that organizations can build upon to meet their specific needs. The Solution not only addresses current challenges in AI deployment, but can also help manufacturers more readily adopt future AI innovations while maintaining operational excellence.