AWS HPC Blog
Optimize your CAE/CFD workloads with Amazon FSx for Lustre Data Repository Association
HPC customers in automotive and manufacturing love Amazon FSx for Lustre because it combines a managed, easy-to-use service with the power of a high throughput parallel file system. Moreover, FSx for Lustre has a native integration with Amazon S3, our object storage service that is designed for durability and low cost. You can link your FSx for Lustre file system to data repositories in Amazon S3, allowing clients and applications to access S3 data as a POSIX-compliant filesystem. You can create the link when creating the file system or at any time after the file system has been created. A link between a directory on the file system and an S3 bucket or prefix is called a data repository association (DRA).
In this blog post we will explain how to use FSx for Lustre for your most demanding HPC jobs while saving your results to S3. We will explain also how to clean up your Lustre automatically and how to activate the S3 tiering to reduce your storage cost.
The storage requirements for CAE/CFD workloads
Computational Fluid Dynamics (CFD) and Computer-Aided Engineering (CAE) workloads are computationally intensive, requiring significant processing power and high performance storage systems. Running on hundreds, sometimes thousands of compute cores simultaneously, these simulations require storage systems that can handle massive parallel I/O operations. They typically involve the analysis of complex physical phenomena, such as fluid flow, heat transfer, and structural mechanics.
The data generated by these simulations can be enormous, often reaching terabytes or even petabytes in size, depending on the complexity of the problem and the resolution of the simulation. Applications like Ansys Fluent, Siemens StarCCM+, and LS-Dyna can generate datasets that require throughput of hundreds of gigabytes per second and low latency in the microsecond range to achieve optimal performance.
The input data for these simulations, such as geometry files, mesh data, and boundary conditions, need to be accessed and processed efficiently to ensure the simulations run smoothly. During the simulation process, large amounts of intermediate data are generated, which need to be stored and accessed quickly to avoid bottlenecks and maintain high performance. The storage system must be able to sustain high write throughput to keep up with the rate of data generation.
The output data, which includes simulation results, visualizations, and analysis, also need to be stored and accessed efficiently for further processing and reporting. The storage system must be able to provide high read throughput to enable rapid access to the results.
The I/O requirements for CAE/CFD workloads are typically characterized by high bandwidth, low latency, and the ability to handle large, sequential data transfers.
The performance of the storage system, including the storage media, file system, and storage network, plays a critical role in the overall performance of the CAE/CFD workflow. Slow storage performance can lead to significant delays in the simulation process, impacting productivity and delaying the time-to-solution.
High performance storage solutions, such as parallel file systems, and high speed storage networks, can help alleviate the I/O bottlenecks and ensure efficient execution of CAE/CFD workloads. These solutions can provide the necessary throughput and low latency to support the demands of these workloads.
The choice of storage media, such as solid-state drives (SSDs) or hard disk drives (HDDs), can have a significant impact on the overall storage performance and cost. SSDs, with their fast access times and high throughput, are often preferred for CAE/CFD workloads, as they can provide the necessary I/O performance to support the demands of these workloads.
Parallel file systems, such as Lustre or GPFS, can also be leveraged to distribute the I/O load across multiple storage nodes, providing higher aggregate bandwidth and improved scalability, which is crucial for handling the massive datasets generated by CAE/CFD applications.
What is Amazon FSx for Lustre DRA?
High performance computing (HPC) workloads in industries like automotive and manufacturing require fast, scalable, and highly available file storage to power complex simulations, models, and analytics.
Amazon FSx for Lustre is a fully managed service that provides high- performance, scalable file storage optimized for compute-intensive workloads. One key feature of Amazon FSx for Lustre that can greatly benefit these HPC use cases is Data Repository Association (DRA). The DRA feature in FSx for Lustre allows you to associate your Lustre file system with an Amazon S3 data repository, providing several key benefits:
- Access to Unlimited Capacity: Your Lustre file system can be configured with terabytes or petabytes of storage, while the underlying S3 storage scales without any effective limit.
- Fast Data Access: FSx for Lustre automatically stores the most recently accessed data from S3, allowing your HPC workloads to access data at high speeds.
- Data Durability: The data stored in your associated S3 bucket benefits from the high durability and reliability of the S3 storage platform.
For HPC workloads that require virtually unlimited storage capacity and fast data access, FSx for Lustre with DRA can be a game-changer.
Moreover, Amazon has recently announced a new Intelligent-Tiering storage class for FSx for Lustre that provides virtually unlimited scalability and the lowest-cost Lustre file storage in the cloud.
Finally, for customers using Elastic Fabric Adapter (EFA) for their HPC workloads, Amazon FSx for Lustre now supports EFA and NVIDIA GPUDirect Storage (GDS). With this feature, Amazon FSx for Lustre provides the fastest storage performance for GPU instances in the cloud, delivering up to 12x higher throughput per client instance (1200 Gbps) compared to previous FSx for Lustre systems (https://aws.amazon.com/blogs/aws/amazon-fsx-for-lustre-unlocks-full-network-bandwidth-and-gpu-performance/).
Use Cases for FSx for Lustre DRA in Automotive and Manufacturing
Automotive and manufacturing companies often run complex, data-intensive HPC workloads such as:
- Computational Fluid Dynamics (CFD) simulations for vehicle aerodynamics and engine design
- Finite Element Analysis (FEA) for product testing and structural modeling
- Machine learning and AI training on large datasets for predictive maintenance, quality control, and more
These workloads can generate massive amounts of data that need to be accessed and processed quickly. FSx for Lustre with DRA can provide the performance, scale, and resilience required to power these critical HPC applications. When large amounts of data are required, DRA will give you the best of both worlds: performance at an affordable price point.
How to Use FSx for Lustre DRA
Enabling the Data Repository Association (DRA) feature in Amazon FSx for Lustre is straightforward:
- When creating a new FSx for Lustre file system, select the “Data Repository Association” option. You can also add DRA later, once the file system is deployed.
- Specify the Amazon S3 bucket or prefix you want to associate with your Lustre file system. You can also configure import/export settings to meet your desired synchronization behavior between S3 and the file system.
- Configure the file system as you normally would, including settings like automatic backups, security, and data compression.
Once your FSx for Lustre file system with DRA is up and running, you can mount it on your HPC cluster just like any other Lustre file system and start accelerating your automotive and manufacturing workloads.
Managing the storage lifecycle
Since all your data are now automatically synchronized with S3, you can provision your FSx for Lustre file system for the performance you need rather than for the data volume you have.
In FSx for Lustre you can choose the amount of Throughput per unit of storage that you want for your file system.
Throughput per unit of storage is the amount of read and write throughput for each 1 tebibyte (TiB) of storage provisioned, in MB/s/TiB. You pay for the throughput that you provision. For example, for FSx for Lustre PERSISTENT_2 storage type, you can choose a throughput value of either 125, 250, 500, or 1,000 MB/s/TiB. Note that some AWS Regions may only offer PERSISTENT_1 storage type with different performance options, so be sure to check the available deployment types in your target region.
Suppose you need a persistent file system for compute-intensive workloads that process large volumes of data and require rapid access by multiple computing instances. These file systems are optimized for long-term storage and continuous workloads, especially those sensitive to changes in availability. Suppose you want to store 12 TB of data on a file system with a minimum throughput capacity of 250 MB/s/TiB. The system you are considering has a throughput capacity of 3000 MB/s and a metadata IOPS of 12000.
Here a brief summary of the required configuration parameters:
Deployment type: Persistent 2
Storage type: SSD
Throughput per unit of storage: 250 MB/s/TiB
Storage capacity: 12 TiB
Throughput capacity: 3000 MB/s
Metadata IOPS: 12000 IOPS
Now that you have sized your Lustre file system for your required throughput, you can automatically clean up data that are no longer needed. Amazon FSx for Lustre offers a feature called “release data repository task” that allows you to free up space for new files by releasing file data. When a file is released, its listing and metadata are retained, but the local copy of the file’s contents is removed. If a user or application accesses a released file, the data is automatically and transparently loaded back from the linked Amazon S3 bucket onto your file system. This feature also enables you to specify a duration, in days, after which any file that has not been accessed should be released. The duration is calculated by taking the difference between the release task creation time and the last time the file was accessed.
You can use Amazon EventBridge Scheduler to set up a recurring release data repository task, which allows you to release file data on a regular interval. This workflow is illustrated by the following diagram:
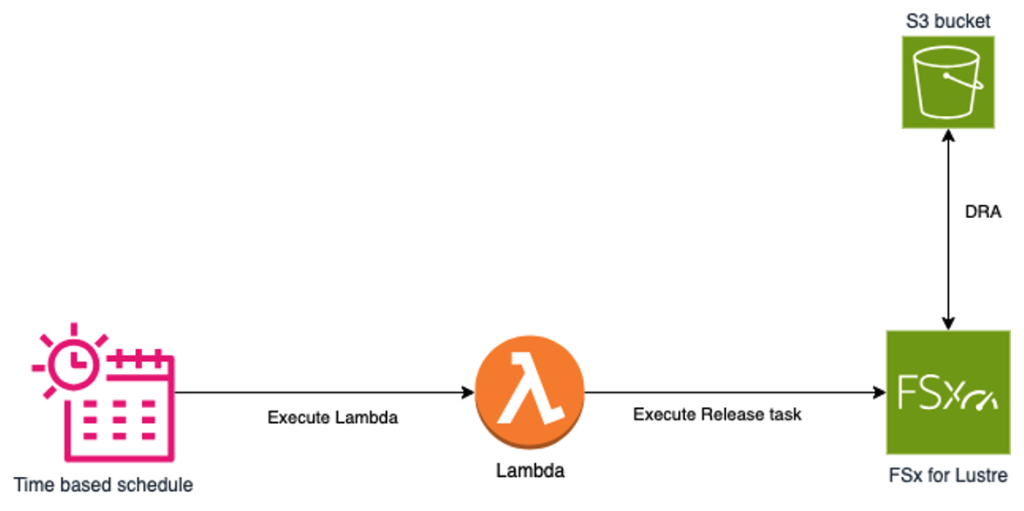
Figure 1. The EventBridge Scheduler periodically executes a AWS Lambda function that triggers the data Release task in the FSx for Lustre file system. Files are kept on Amazon S3 after the release.
The EventBridge time-based schedule executes the AWS Lambda function periodically, which in turn triggers the release data repository task. This automated process is helpful in reducing the space used of the file system, thereby avoiding the need to increase the file system’s size while being more cost conscientious.
The AWS HPC Recipes repository has a CloudFormation template you can use as an example for this workflow here:
Alternatively, you can set up a workflow to execute the release data repository task when the available space of the file system reaches a specific limit. This workflow is illustrated by the following diagram:
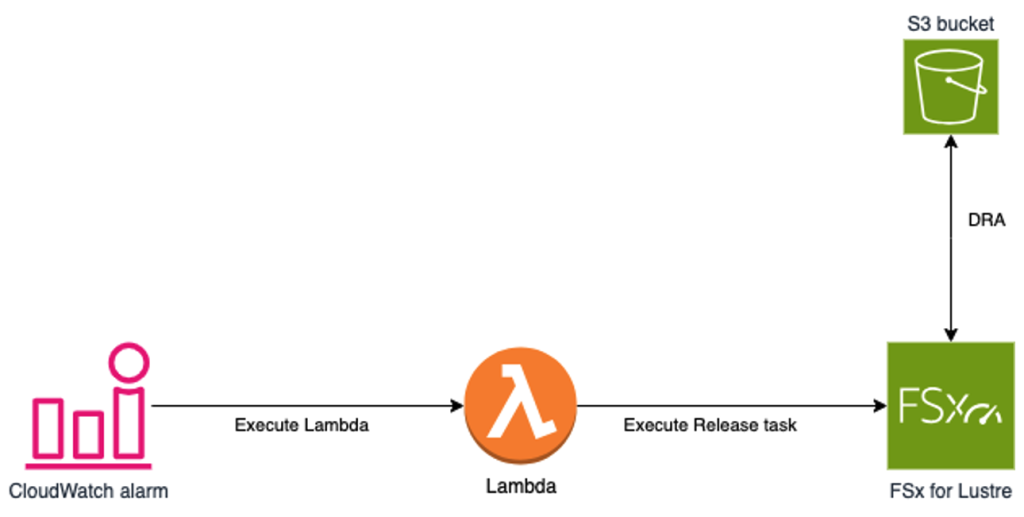
Figure 2. An Amazon CloudWatch alarm triggers a Lambda function when the free space in the Amazon Lustre file system drops below an administrator-defined threshold. The Lambda function then triggers the release task, removing files from the file system that have not been accessed for more than a month (or an administrator-defined amount of time). Files are kept on Amazon S3 after the release.
This can be achieved by integrating Amazon CloudWatch alarms with Amazon EventBridge, which offers various targets such as an AWS Lambda function. You can deploy a CloudWatch alarm that monitors the file system’s free space and triggers an EventBridge rule when the free space reaches a predefined threshold. The EventBridge rule can then automate the execution of the release data repository task to reclaim storage space. Furthermore, you can adjust the duration (in days) after which any file that has not been accessed is eligible for release, allowing you to optimize the file cleanup process and improve the overall efficiency of the storage management.
Here you can find a CloudFormation template you can use as an example for this workflow:
Some limitations to keep in mind are the following caveats if you are working with hundreds of millions of small (KBs) files:
- S3 use object prefixes to organize the storage objects into folders. Keep in mind that if you change a directory in Amazon FSx Lustre, the DRA will update the prefixes of all the files in S3 and this can take time if you are managing millions of objects on S3. As a best practice, you should limit the number of files to 100,000 per directory to maintain optimal performance.
- For the same reason, you need to allow more time when importing from S3 to Lustre millions of small files.
Finally, using these features will not completely prevent a file system from running out of space. When sizing your file system consider also that you can write new data (or restore old data from S3) to the file system faster than the file system can find and release old content. To mitigate this risk, you can use Lustre storage quotas or increase the file system size. Additionally, when capacity exceeds 80%, another Amazon CloudWatch alarm can send an email notification to the HPC administrators.
Conclusion
For HPC customers in the automotive and manufacturing industries, Amazon FSx for Lustre with the Data Repository Association feature can deliver the performance, scalability, and reliability required to power their most demanding workloads. By linking your Lustre file system to an Amazon S3 data repository, FSx for Lustre DRA enables virtually unlimited capacity, accelerated data access, and improved data durability – key requirements for compute-intensive simulations, models, and analytics. If your organization is looking to supercharge its HPC infrastructure, be sure to consider the benefits of Amazon FSx for Lustre with DRA. This solution offers cost-effective, high-performance file storage optimized for your HPC workloads in the cloud.