AWS Database Blog
Transform uncompressed Amazon DocumentDB data into compressed collections using AWS DMS
In this post, we discuss handling large collections that are approaching 32 TiB for Amazon DocumentDB (with MongoDB compatibility). The maximum collection size for Amazon DocumentDB is capped at 32 TiB. We demonstrate solutions for transitioning from uncompressed to compressed collections using AWS Database Migration Service (AWS DMS). This migration not only accommodates larger uncompressed data volumes, but also significantly reduces storage, compute costs associated with Amazon DocumentDB and improves performance.
AWS DMS provides a streamlined approach for this migration, providing minimal downtime and data integrity throughout the process. This strategy is particularly beneficial for organizations dealing with rapidly growing Amazon DocumentDB collections, helping them maintain optimal performance as data volumes expand.
Solution overview
The following diagram illustrates this process of migrating the uncompressed collection to a compressed format.
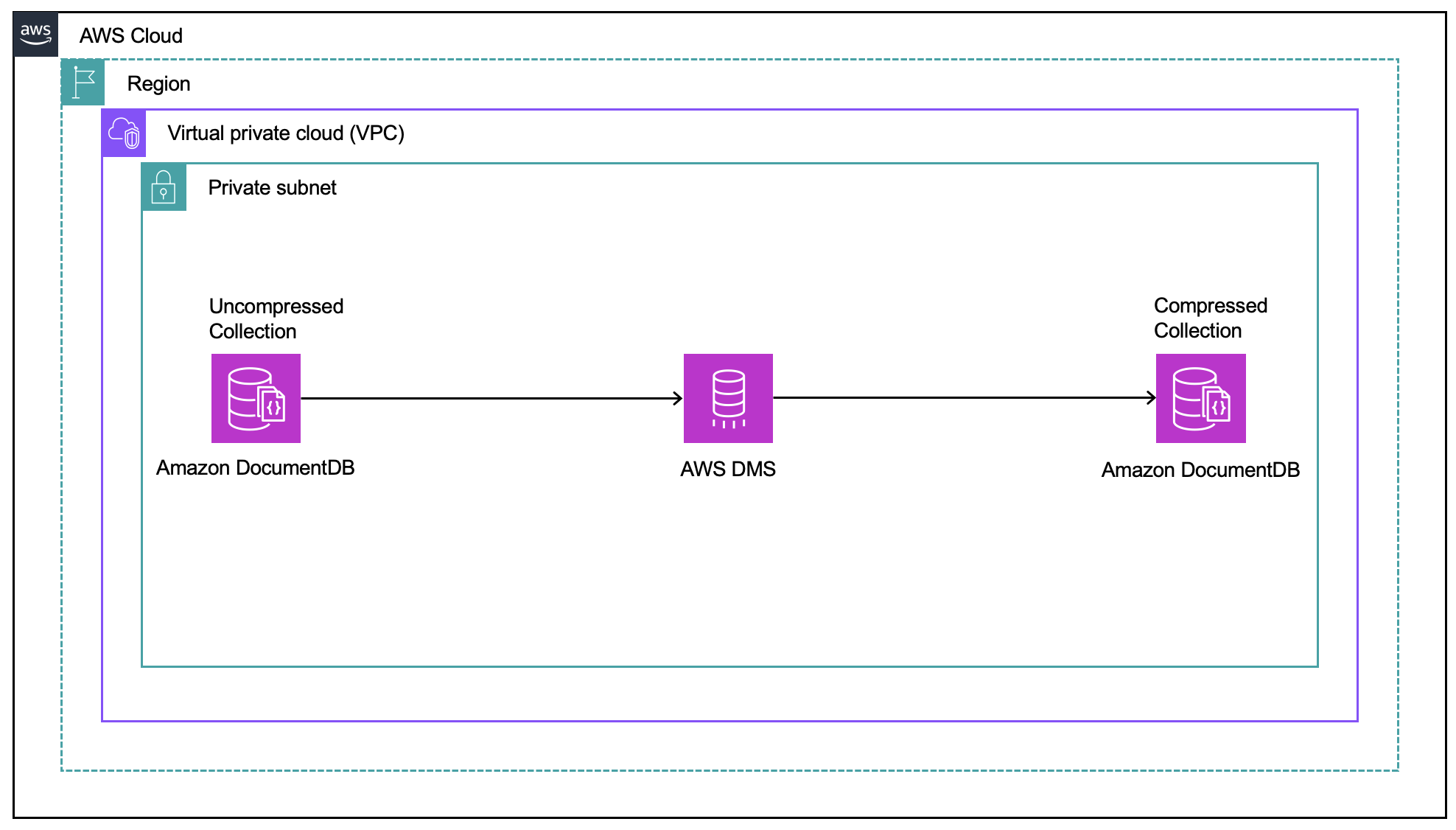
For this post, we create an AWS DMS task using full load and change data capture (CDC) to migrate data from an uncompressed collection in an Amazon DocumentDB cluster to a compressed collection in another Amazon DocumentDB cluster.
Prior to your migration, make sure that the parameter setting default_collection_compression, which is set to disabled, is enabled on the target Amazon DocumentDB cluster. With this setting, newly created collections on the cluster will have compression enabled. Alternatively, you can enable compression for a specific collection. For a deep dive into compression on Amazon DocumentDB clusters, refer to Unlock cost savings using compression with Amazon DocumentDB.
With this approach, the application can remain connected to the Amazon DocumentDB cluster with an uncompressed collection and then switch over to the new Amazon DocumentDB cluster with compression enabled when the migration is complete.
Prerequisites
To follow along with this post, you should have familiarity with AWS DMS and Amazon DocumentDB.
Compressed compared to uncompressed collections
To explain the differences between compressed and uncompressed collections, we carried out tests on two db.r6g.4xlarge instance classes: one with compression disabled and the other with compression enabled. We loaded 25 million documents (approximately 215 KB each) with three secondary indexes and executed update-only workloads at 120 updates per second for 24 hours. We observed the following results:
- Compressed storage reduced document size from approximately 215 KB to 15,662 B (a 13.7-fold reduction)
- The uncompressed cluster showed higher CPU utilization (30–55%) compared to the compressed cluster (6–17%)
- Garbage collection was more efficient in a compressed setup (38 seconds on average) compared to uncompressed (40 minutes)
- The write-heavy workload (500 updates per second) test showed that the uncompressed cluster couldn’t maintain performance
- Compressed storage demonstrated better I/O performance with fewer active sessions
- Storage growth was significantly lower in the compressed setup (12–20 GB) compared to uncompressed (1.3–3.2TB)
Amazon DocumentDB supports document compression starting with version 5.0. We recommend carrying out a similar exercise to determine if compression is the right fit for your workload.
Customer case study
In this use case, a customer was approaching the maximum collection size of their collection in an Amazon DocumentDB cluster. The average document size was 200 KB, and the collection was seeing an update rate of 100 documents per second. They faced the following challenges:
- Applying document compression to existing collections – This approach would only compress documents that were inserted or updated after compression was turned on. Because the firm already had an existing collection, one strategy could be to issue dummy updates (to a new field that is not used by the application) that affect documents that existed prior to compression being turned on, at a controlled slow rate. However, this approach wasn’t feasible because it would lead to additional load on the cluster to read and update every document. The rate of changes was high and causing garbage collection to run frequently. Using this approach on that cluster would add even more load and affect normal operational workload.
- Export and import downtime – Exporting a collection is a viable option, but it requires downtime to maintain a consistent state across all nodes in the cluster. Because the collection size was large, the time spent during the export and import process could influence the downtime. For this customer case study, this would take around 14 hours according to tests.
To achieve compression and reduce downtime, the customer migrated the data using AWS DMS. During the tests, they encountered the following challenges:
- With its default settings, the AWS DMS task took around 96 hours to complete the full load. To make sure the change stream events were retained during CDC, we had to set the change_stream_log_retention_duration to 7 days (
604800). - The ongoing changes while the task was running were consuming the underlying storage of the AWS DMS replication instance. As a result, the Amazon CloudWatch metric FreeStorageSpace of the AWS DMS replication instance dropped from 200 GB to 20 GB.
- Interruptions in the AWS DMS task to allow processing of changes were accumulating in the underlying storage of the AWS DMS replication instance, as evidenced by the following log message:
Proposed changes on AWS DMS to optimize migration
To optimize the full load, we made the following changes:
- Used auto segmentation for optimizing full load. Alternatively, you can use the AWS DMS segment analyzer to define the ranges for the parallel load.
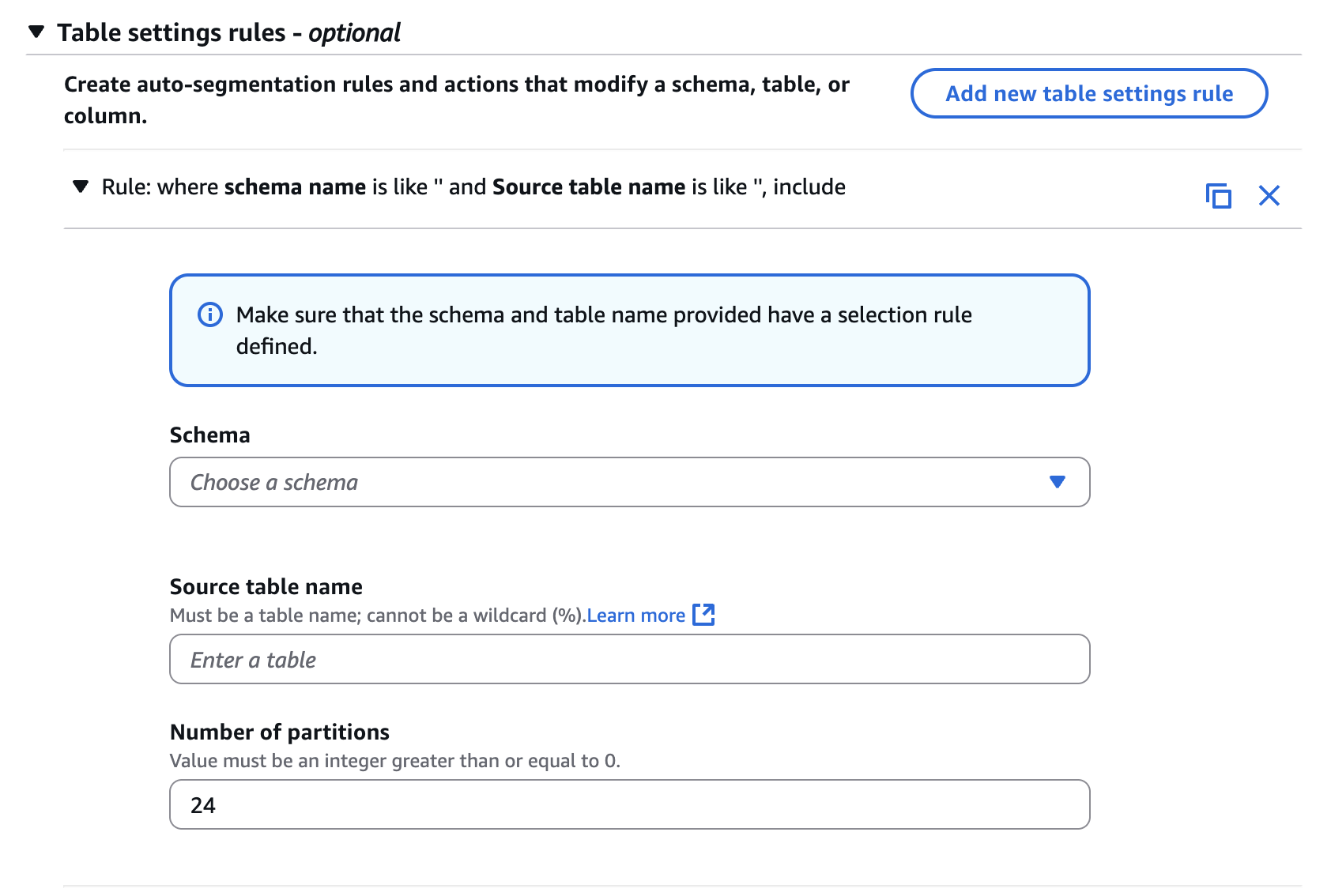
- Increased MaxFullloadSubTasks from the default 8 to 24. This should be adjusted in relation to the number of partitions in the AWS DMS table settings, with the optimum value determined based on the number of vCPUs available in the source. Additionally, you must consider the available network bandwidth between the instances. The following screenshot shows how you can define the partitions on the AWS DMS console in the Table settings while creating the DMS task.
- Increased the underlying storage of the AWS DMS replication instance to 2 TiB. This was done because the cached changes were generating more than 800 GB of swap files due to heavy transactions in the source Amazon DocumentDB Cluster during the full load period.
- Changed the memory-related AWS DMS setting
MemoryLimitTotalto 20 GB andMemoryKeepTimeto 30 minutes to retain the changes in the memory for a longer duration and avoid frequent swapping to the underlying storage of the AWS DMS replication instance. See the following code:
After implementing the necessary configuration changes, the customer successfully migrated their data into the compressed Amazon DocumentDB collection. The initial data transfer was completed in approximately 12 hours, with no impact on ongoing operations. The transition to the new system occurred smoothly and without disruption.
Conclusion
In this post, we discussed compression in Amazon DocumentDB clusters and some of the challenges you might face with an uncompressed collection as it approaches the maximum collection size. We also shared how we addressed the challenges while migrating data from an uncompressed collection to a compressed collection. If you have any feedback or questions, please leave them in the comments section.