AWS Database Blog
Supercharging AWS database development with AWS MCP servers
Model Context Protocol (MCP) is transforming how AI systems interact with data and tools, enabling them to easily work with databases, APIs, file systems, and specialized business applications. You’re probably wondering why everyone is talking about MCP servers and how do they relate to your databases. In fact, even our customers are asking us how they can integrate their existing systems with AI models to supplement everyday tasks with AI-assisted tools that understand context and suggest improvements.
At Amazon Web Services (AWS), we constantly seek ways to help developers build more quickly, intuitively, and productively in the cloud. Amazon Aurora, Amazon DynamoDB, and Amazon ElastiCache are popular choices for developers powering critical workloads, including global commerce platforms, financial systems, and real-time analytics applications. With the advent of AI, how developers interact with these services is evolving. To enhance productivity, developers are supplementing everyday tasks with AI-assisted tools that understand context, suggest improvements, and help reason through system configurations. MCP is at the helm of this revolution, rapidly transforming how developers integrate AI assistants into their development pipelines. In this post, we explore the core concepts behind MCP and demonstrate how new AWS MCP servers can accelerate your database development through natural language prompts.
Traditional development challenges
In a typical development environment, developers can spend hours writing boilerplate queries and switching between development tools and database interfaces (such as psql or mysql client) to inspect schemas and data. Such frequent context switching forces developers to repeatedly reacquaint themselves with different schemas, syntaxes, paradigms, and best practices, slowing development and increasing the risk of errors.
These challenges magnify when applications rely on a combination of relational, nonrelational, and cache database technologies. Within the relational world alone, developers must navigate subtle but breaking differences between SQL dialects. For example, a valid PostgreSQL query can fail in MySQL and the opposite can also happen. Developers must maintain multiple mental models simultaneously, constantly translating between dialects. The cognitive burden amplifies further when switching between relational and nonrelational databases. Each transition demands not just different syntax, but fundamentally different approaches to data modeling, query optimization, and application architecture. Traditional development tools weren’t designed for this reality of constant context-switching across diverse database ecosystems.
Introducing MCP servers for AWS databases
The approach AWS is taking focuses on secure, protocol-based access to structured metadata, designed to work in your local development environments and collaborative settings. To support this, we’ve made available open source MCP servers for several database services. This post focuses on the following database services:
- Amazon Aurora – MCP server for Aurora PostgreSQL, MCP server for Aurora MySQL, and MCP server for Aurora DSQL
- DynamoDB – MCP server for DynamoDB
- ElastiCache – Valkey and Memcached
Additionally, we’ve created the following open source MCP servers:
- Amazon Neptune – Neptune MCP server
- Amazon DocumentDB – DocumentDB MCP server
- Amazon Timestream – Timestream for InfluxDB MCP server
- Amazon Keyspaces (for Apache Cassandra) – Keyspaces MCP server
- Amazon MemoryDB – MemoryDB Valkey MCP server
What is MCP?
MCP is an open protocol that standardizes connecting AI assistants to the external world, including content repositories, data sources, business tools, and development environments. At its core, MCP follows a client-server architecture where a host application can connect to multiple servers. An MCP architecture has the following components:
- MCP hosts and clients – AI-powered applications such as Amazon Q command line interface (CLI), Cursor, or Claude Desktop that need access to external data or tools.
- MCP servers – Lightweight servers that expose specific functionalities through tools, connecting to local or remote data sources.
- Data sources – Databases, files, or services that contain the information your AI assistants need.
The following diagram explains how MCP enables large language model (LLM) agents to access and perform tasks on the structured data stored in databases.
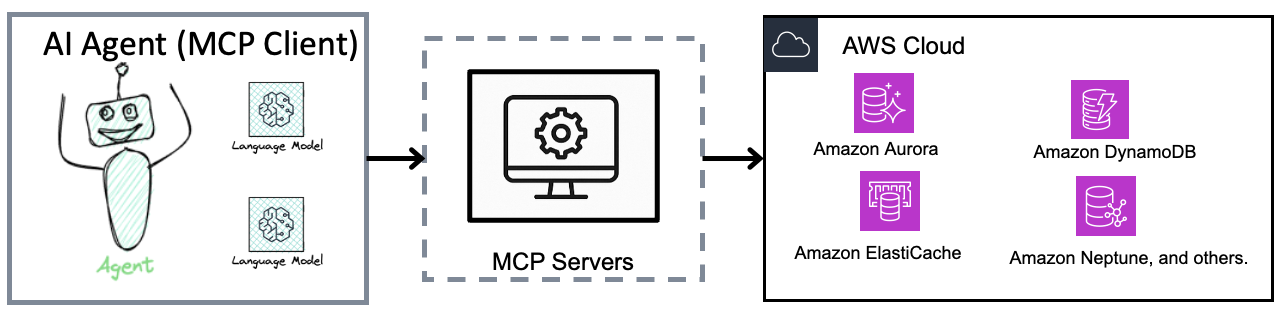
Each AWS database MCP server implements the same protocol while handling database specific connections through appropriate mechanisms. This eliminates the need for developers to build custom integrations for each database when connecting AI tools. By standardizing how AI assistant tools access metadata across database services, MCP enables intelligent suggestions, context-aware query assistance, and real-time understanding of database structure.
Next, we explore some common MCP use cases.
Accelerating database development with MCP servers
Development often begins with fundamental questions: What am I building, and what tools should I use? Database MCP servers address these questions by bringing database context directly into development environments. These servers expose a curated set of tools that agents can discover and use to accomplish specific tasks. For example, the Aurora DSQL MCP server provides three essential tools: get_schema, readonly_query, and transact. During development, the AI agent invokes the LLM to select the appropriate tool. A typical workflow might begin with get_schema to discover available tables, continue with readonly_query to examine table structures, and conclude with transact to insert rows into the relevant tables.
Enabling the AI assistant with such contextual awareness helps developers answer important questions that traditionally slow down development:
- How are tables related?
- Which keys drive specific access patterns?
- What data is available for implementing a particular feature or building analytic dashboards?
By exposing structured metadata from AWS databases, database MCP servers support workflows that enhance development speed, safety, and visibility. They empower AI agents to reason about schemas, access patterns, and recent changes in real time. Next, we explore the common patterns that emerge when using MCP in database development workflows.
Schema-driven feature development
After determining the appropriate application design and data model, developers can use integrated development environment (IDE) integrations with MCP servers to access real-time schema details and relationships. They can then continue confidently evolving the data model through natural language interactions with the AI Assistant. For example, developers can add a table to Aurora and clearly understand how it connects to existing foreign keys. They can update a DynamoDB attribute structure based on new requirements while comprehending its impact on query patterns. Additionally, they can explore how cached data is stored and used in ElastiCache.
The following video demonstration showcases how developers can use Amazon Q CLI with Cursor to find tables, understand the database schema, and generate create, read, update, and delete (CRUD) APIs in an Amazon Aurora PostgreSQL-Compatible Edition database in minutes using natural language prompts. This video is focused on Aurora, but the same concepts apply to other databases, including Amazon Aurora MySQL-Compatible Edition.
Exploring data to power business insight
Modern applications do more than store data. They reason about it. Using MCP server capabilities, you can build robust dashboards in minutes. MCP automatically handles data contextualization, relationship mapping, and visualization recommendations. The following demo uses Aurora DSQL MCP server to build a dashboard for an ecommerce database on Aurora DSQL.
Automated test code generation aligned with your database schemas
Test coverage is only as useful as its accuracy. Using agents with MCP servers, developers can generate tests based on live metadata and query patterns, streamlining various testing activities. For example, using the AI assistant, developers can inspect the current Aurora schema and create specific tests to validate constraints and relationships. For DynamoDB, they can generate tests based on a table’s access patterns and indexes. Similarly, with ElastiCache, they can build tests to simulate specific Time To Live (TTL) configurations and fallback scenarios.With the context of each database available to the AI assistant, these tests are precise and purpose-built to validate your database’s live metadata and query patterns. By following this approach, developers can spend less time writing and maintaining tests, speeding up delivery without compromising confidence in application behavior.The following video demonstration walks through how MCP servers support AI-assisted test generation, ensuring that test logic stays aligned with the current structure of the system.
Monitor and troubleshoot issues
For operations engineers working with complex database systems in production, MCP offers a powerful tool for systemic troubleshooting. When faced with database performance issues or anomalies, an operations engineer can use an AI-assisted workflow directly from their preferred tools to obtain real-time insights. This aids in troubleshooting issues such as high memory usage, slow queries, and other potential problems before they become critical.
A companion demo illustrates how operations teams can use an AI-assisted workflow to interact with an Amazon ElastiCache Valkey cache. This workflow retrieves information such as used memory, peak memory, number of clients connected, status of replications, and more. Although this information can be lengthy and difficult for humans to parse quickly, an AI agent can efficiently summarize the data and highlight the most relevant results that may be causing performance issues.
Getting started
The MCP servers for Aurora, DynamoDB, and ElastiCache are available as an open source project maintained by AWS Labs. You’ll run these servers in a Docker container locally on the client running the AI assistant. You’ll need to follow the steps in the prerequisites section before you can start using MCP servers.
Prerequisites
Before using MCP servers, follow these prerequisite steps:
- Ensure Docker is installed on your development environment. For instructions to install Docker, visit Docker Desktop download
- Invoke the following commands in your shell based on the database service(s) you use:
Database service Directory Aurora DSQL aurora-dsql-mcp-serverAurora MySQL mysql-mcp-serverAurora PostgreSQL postgres-mcp-serverDynamoDB dynamodb-mcp-serverElastiCache (Valkey) valkey-mcp-serverElastiCache (memcached) memcached-mcp-serverAmazon Neptune amazon-neptune-mcp-serverAmazon Timestream timestream-for-influxdb-mcp-serverAmazon DocumentDB aws-documentdb-mcp-serverAmazon Keyspaces amazon-keyspaces-mcp-server - Add the MCP server to your client application’s configuration file. The configuration depends upon the database service and specific client applications, as demonstrated in the following sections.
After you fulfill the prerequisites, you’re ready to use your preferred IDE and generative AI tools. We explore a few common IDE and tools in the next sections.
Amazon Q CLI with Cursor
To use Amazon Q CLI with Cursor, follow these steps:
- Ensure Cursor is installed on your machine. For instructions, visit Installation.
- Ensure Amazon Q CLI and the Amazon Q Developer extension are installed for Cursor. For more information on how to install these tools, refer to Installing the Amazon Q Developer extension or plugin in your IDE and Installing Amazon Q for command line.
- We use the following example workspace configuration to demonstrate MCP servers in containers for Amazon Q CLI based on the database service. You can also use the global configuration as specified in the MCP configuration section in our documentation.
- Here are sample configurations for
mcp.jsonfile that you can use depending on the MCP server you choose.
For Aurora MySQL and Aurora PostgreSQL:For Aurora DSQL:
For DynamoDB:
For ElastiCache:
Amazon Q CLI with Visual Studio Code (VS Code)
To use MCP servers with Amazon Q CLI with VS Code, follow these steps:
- Ensure VS Code is installed on your machine. Refer to Setting up Visual Studio Code to learn more.
- Ensure Amazon Q CLI and Amazon Q Developer extension are installed for VS Code. To learn more, refer to Installing the Amazon Q Developer extension or plugin in your IDE and Installing Amazon Q for the command line.
- Use the example workspace configuration for Amazon Q CLI based on the database service as explained in the Amazon Q CLI with Cursor section, or you can use the global configuration as specified in the MCP configuration section in our documentation.
- The rest of the configuration is identical to Amazon Q CLI with Cursor as discussed previously.
Claude Desktop
To use MCP servers with Claude Desktop, follow these steps:
- Ensure Claude Desktop is installed and running on your machine. Refer to Installing Claude for Desktop to learn more.
- Open Claude Desktop and choose Settings then choose Edit Config.
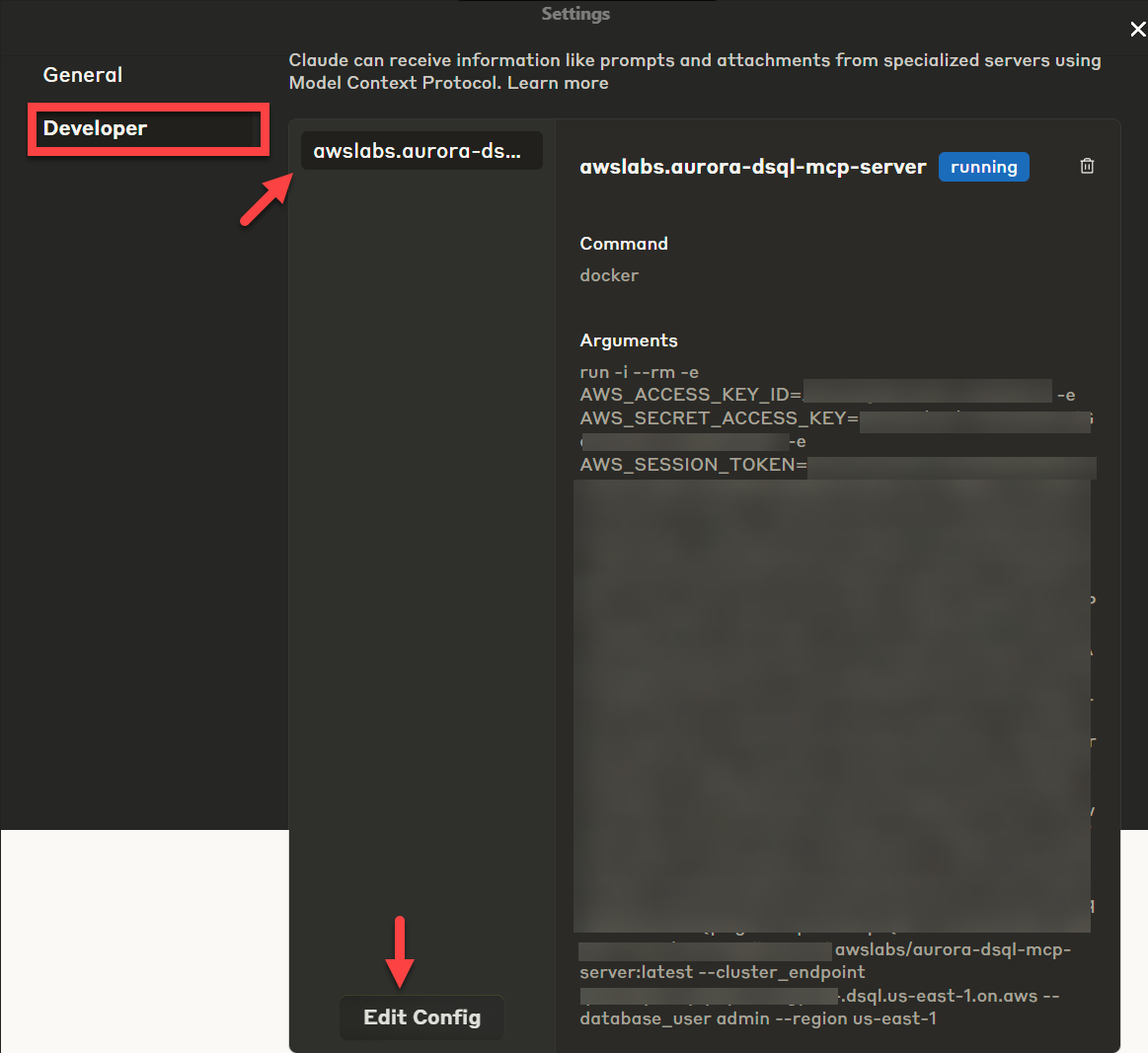
- Select claude_desktop_config.json. The content of
claude_desktop_config.jsonis identical tomcp.jsonfile as described in the Amazon Q CLI with Cursor section.
Where we’re headed
The availability of MCP servers reflects a broader shift in how we support builders. The goal is to bring AWS databases into the tools where development starts. That includes local environments, collaborative editors, and AI-assisted workflows.
MCP servers are open source and ready to use. You can find the code, documentation, and setup instructions in the AWS Labs GitHub repository. Start integrating them into your workflows and bring the full context of AWS databases into your development environment.
Conclusion
In this post, we explored how to configure and use the newly released MCP servers for AWS database services, namely Aurora PostgreSQL and Aurora MySQL, Aurora DSQ, DynamoDB, DocumentDB, Keyspaces, Elasticache (Valkey, Memcached), and Neptune. We also looked at a few common patterns where MCP servers can be used to accelerate your development cycle.
Start using MCP servers today to integrate your AI applications and agents with your data sources and services. All these MCP servers are open source, and we welcome both your contributions and feedback about this newly unlocked functionality. We look forward to incorporating your feedback and further enhancing the capabilities of these MCP servers to introduce new ways for both humans and AI models to interact with your business data.