AWS Database Blog
Stream Amazon DynamoDB table data to Amazon S3 Tables for analytics
Organizations using Amazon DynamoDB for transactional workloads often need to perform complex analytics on their data. Although DynamoDB excels at handling high-volume transactional workloads, many organizations maintain separate analytical stores to run complex queries and generate insights without impacting their transactional database performance.
In this post, we demonstrate how to stream data from DynamoDB to Amazon S3 Tables to enable powerful analytics capabilities on your operational data. The demonstrated streaming pattern is ideal for organizations that require fine grained control over data transformations within sensitive environments. It is particularly valuable for teams building data lakes who want a managed solution that works with the Apache Iceberg format and integrates with AWS analytics services without operational overhead.
Storing tabular data in Amazon S3
S3 Tables, announced at AWS re:Invent 2024, deliver the first cloud object store with native Iceberg support, designed to streamline tabular data storage at scale. Tabular data represents data in columns and rows, as in a database table. The data in S3 Tables is stored in a new bucket type, a table bucket, which stores tables as Amazon S3 resources. Table buckets support storing tables in Iceberg format, and you can query your tables by using standard SQL statements using query engines such as Amazon Athena, Apache Spark, and Amazon Redshift. You can automatically integrate your Amazon S3 table buckets with AWS analytics services to discover and access your table data through the AWS Glue Data Catalog. With this integration, you can work with your tables by using analytics services such as Athena, Amazon Redshift, and Amazon QuickSight. For more information about how the integration works, see Using Amazon S3 Tables with AWS analytics services.
S3 Tables provide built-in table management capabilities, metadata tracking, schema evolution, and table data organization automatically. Continual table optimization automatically scans and rewrites table data in the background, achieving query performance as much as three times faster compared to unmanaged Iceberg tables. These performance optimizations will continue to improve over time. Additionally, S3 Tables include optimizations specific to Iceberg workloads that deliver up to 10 times higher transactions per second compared to Iceberg tables stored in general purpose Amazon S3 buckets. Iceberg has become the most popular way to manage Parquet files, with many of AWS customers using Iceberg to query across billions of files containing petabytes or even exabytes of data. Some key benefits include:
- Support for ACID transactions and time-travel queries
- Schema evolution capabilities
- Optimized query performance through partitioning and columnar storage
- Native integration with popular analytics engines, such as Apache Spark
- Continuous maintenance for compaction, snapshot management, and unreferenced file removal
Solution overview
Change data capture is the process of capturing changes to data from a database and publishing them to an event stream, making the changes available for other systems to consume. Amazon DynamoDB change data capture offers a mechanism for capturing, processing, and reacting to data changes in near real time. The change data capture stream of data records enables applications to process and respond to data modifications in a DynamoDB table. DynamoDB offers two streaming models for change data capture: Amazon DynamoDB Streams and Amazon Kinesis Data Streams for DynamoDB. This solution demonstrates the two implementation patterns for streaming data from DynamoDB to S3 Tables by using fully managed AWS services.
Pattern 1: Using DynamoDB Streams (recommended for most use cases)
As shown in the following diagram, this pattern uses the DynamoDB native change data capture capability to stream table changes through an AWS Lambda function that processes and forwards events to Amazon Data Firehose for delivery to S3 Tables. Amazon DynamoDB Streams provides 24-hour retention and is ideal when you need near real-time data replication without managing additional streaming infrastructure.
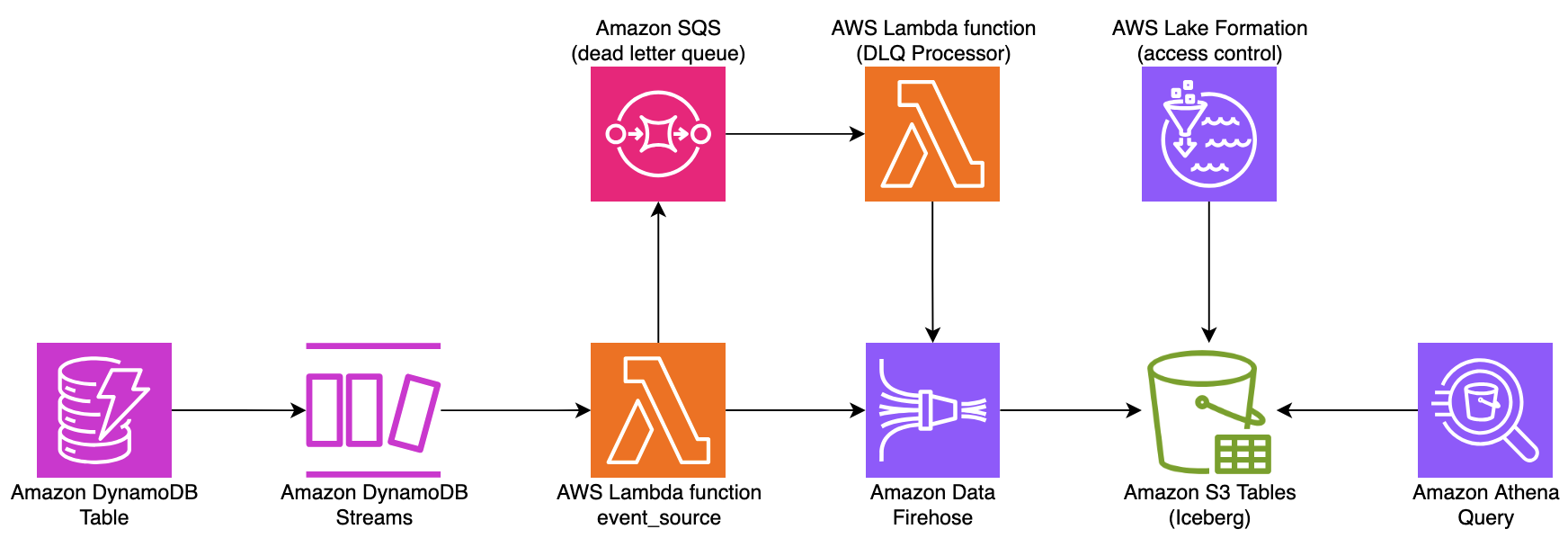
This architecture implements a dead-letter queue (DLQ) using Amazon SQS to capture and manage failed DynamoDB stream events processed by Lambda functions. A dedicated DLQ processor Lambda implements controlled retries with backoff strategies, ensuring that failed events are preserved and automatically recovered.
Pattern 2: Using Amazon Kinesis Data Streams
This pattern integrates DynamoDB with Amazon Kinesis Data Streams when you need extended data retention (up to 365 days) or support for a higher number of stream consumers with fan-out architecture. Kinesis Data Streams also provides native integration with other AWS analytics services through Data Firehose.
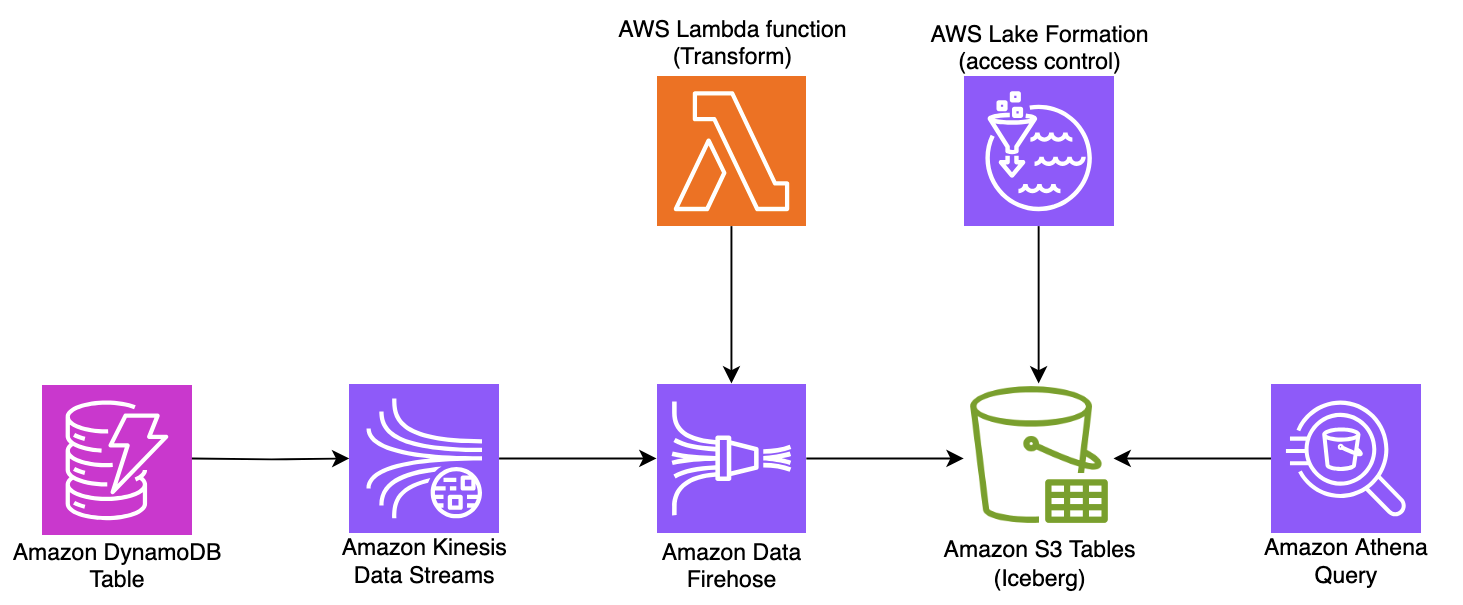
In the Pattern 2 architecture shown in the preceding diagram, error handling can be incorporated at multiple stages of the pipeline. At the Kinesis level, you can configure retention periods (7–365 days) to enable data replay and implement Amazon CloudWatch alarms for monitoring stream health. At the Lambda transformation layer, you can implement a DLQ with structured error logging and sequence number tracking to ensure exactly-once processing. At the Firehose level, you can implement comprehensive error handling through Amazon S3 backup settings for failed records with descriptive error prefixes, configurable retry options, and CloudWatch logging for delivery failures. This multi-layered approach ensures data reliability by capturing failures at each stage, providing both automated recovery paths for transient issues and preservation mechanisms for records requiring manual intervention.
Key components of the architecture
The solution architectures consist of the following components:
- Athena – Serverless interactive query service
- Amazon Data Firehose – Handles data delivery to S3 Tables
- DynamoDB – Source transactional database
- DynamoDB Streams or Kinesis Data Streams – Change data capture and streaming
- AWS Lake Formation – Centralized access control
- Lambda – Processes stream records and invokes Data Firehose
- S3 Tables – Analytical data store using the Iceberg format
To decide between DynamoDB Streams and Kinesis Data Streams for DynamoDB, see Streaming options for change data capture, which summarises their properties in a table. You can use both patterns to maintain near real-time copies of your DynamoDB data in S3 Tables so that you can use the power of the Iceberg table format for analytics while providing a fully managed solution that alleviates operational overhead. You can integrate Amazon S3 table buckets with Amazon SageMaker Lakehouse to integrate with AWS analytics services such as Athena, Amazon Redshift, Amazon EMR, QuickSight, and Firehose.
Production data lake architectures typically implement a multilayer approach (raw, cleansed, and curated) rather than loading directly into presentation tables. A cost-effective strategy uses standard Parquet files in the raw/staging layer and reserves Iceberg tables for the presentation layer where features such as time travel, schema evolution, and ACID transactions provide the most value. This tiered approach balances storage costs with query performance, allowing you to optimize retention policies and partitioning strategies across layers while maintaining data governance and accessibility.
Prerequisites
To follow along with the steps in this post, you need the following resources.:
- An AWS account with AWS Identity and Access Management (IAM) permissions to create resources with the following services:
- Firehose
- DynamoDB
- Kinesis Data Streams
- Lambda
- Lake Formation
- S3 Tables
- An integrated development environment (IDE) such as Visual Studio Code
- Python installed with the Boto3 library on your IDE
- The AWS Cloud Development Kit (AWS CDK) installed on your IDE
Clone the repository
Now that you have the prerequisites in place, you can begin implementing the solution. You start by getting the code and configuring it for your environment. Clone the sample Python project from the AWS Samples repository, and follow the development environment setup instructions in the README file:
Update the AWS CDK context
Review the default values in cdk.context.json and align them with your specific requirements:
The stream_type property determines which streaming architecture to deploy:
- kinesis – Uses Kinesis Data Streams with a Lambda processor for data transformation
- dynamodb – Uses DynamoDB Streams with a Lambda function to forward events to the Firehose delivery stream
Deploy the pipeline resources
Now that you have cloned the repository and updated the AWS CDK context, you are ready to start with the PipelineStack, which creates a configurable data-ingestion pipeline for DynamoDB. It provisions infrastructure based on a stream_type parameter, supporting two distinct architectures: a DynamoDB Streams approach suitable for most workloads, or a Kinesis Data Streams integration with DynamoDB for high-throughput scenarios. The stack creates a DynamoDB table to store transactional data and provisions the necessary Lambda functions to interact with S3 Tables. By using AWS CloudFormation custom resources, it automates the creation and management of S3 Tables, enabling seamless integration with AWS analytics services.
Provision the pipeline resources by using the following AWS CDK command:
Deploy Lake Formation permissions
After the PipelineStack is deployed, use the LakeFormationStack to set up and establish comprehensive data governance for the transactional data lake by using Lake Formation. S3 Tables requires Iceberg catalog service to manage table metadata and integrates natively with AWS Glue Data Catalog to serve this purpose. Though traditional Apache Iceberg deployments might use a Hive metastore or require setting up a separate REST catalog service, S3 Tables simplifies this architecture by using Data Catalog as the metadata repository. This integration is further enhanced by Lake Formation, which provides fine-grained access controls and governance capabilities across your data lake.
The stack creates the following:
- Metadata integration: Creates resource links between Data Catalog and S3 Tables Catalog, functioning similarly to how the Hive metastore connects to underlying data but with services native to AWS.
- Lake Formation administration: Sets up Lake Formation administrators, and delegates appropriate permissions at catalog, database, and table levels.
- Cross-catalog access: Sets up connections between the standard Glue data catalog and Amazon S3 Tables Catalog, similar to how Iceberg REST catalogs provide metadata services but using federation native to AWS.
- IAM roles and permissions: Configures the Firehose service role with precise permissions to read from streams and write to S3 Tables.
This stack eliminates the need to manually configure Lake Formation permissions through the console, providing a complete infrastructure-as-code approach to data governance. Deploy the stack by using the following command:
Deploy the Firehose delivery stream
After configuring the Lake Formation permissions and Firehose service role with IAM permissions, deploy the FirehoseStack to create a Firehose delivery stream that connects data sources to S3 Tables. Based on the stream_type parameter, the FirehoseStack can ingest data from either Kinesis Data Streams or direct API calls from a Lamda function. The stack configures the Firehose delivery stream with Iceberg as the destination format, enabling efficient data storage and querying. It sets up proper buffering, error handling, and Amazon CloudWatch logging for monitoring. When using DynamoDB Streams, the stack also updates Lambda function environment variables to connect the pipeline components. This stack simplifies the complex task of configuring Firehose for S3 Tables integration, making real-time data delivery to the data lake straightforward. Deploy the FirehoseStack to create a delivery stream by using the following command:
Stream data from DynamoDB to S3 Tables
After you deploy the resources of the pipeline, you can insert sample data items into the DynamoDB table by using the following script:
This script generates synthetic transaction data and inserts it into the DynamoDB table. Each transaction includes details such as transaction ID, timestamp, amount, and risk indicators. After the transaction data is inserted, the change data capture stream triggers the configured data pipeline. If you’re using DynamoDB Streams, the Lambda function processes change data capture events and forwards them to Firehose. If you’re using Kinesis Data Streams, the data flows directly from DynamoDB to Kinesis Data Streams and then to Firehose. Firehose then delivers this data to S3 Tables in Iceberg format, making it immediately available for analytics.
Run analytics on S3 Tables
After deployment of the CDK stacks and generating synthetic transaction data, you can immediately query your data by using Amazon Athena without additional setup. Athena provides a serverless SQL interface that supports formats such as CSV, JSON, and optimized Parquet files. Although Athena is the recommended query engine for its simplicity and integration with AWS services, the solution’s use of open table formats and the Glue Data Catalog means you can also connect self-managed query engines such as Trino, Presto, or Spark when specific customization is needed. You can write your SQL queries through the Athena console or API to extract insights from your data, using the full power of serverless analytics.
Using the Athena CLI
You can use Athena CLI commands to query and validate the data streamed from S3 Tables (transactions). Remember to replace the work-group value in the following command with the name in your setup. Also make sure the workgroup has already set up an output location (an Amazon S3 bucket). Alternatively, you can provide the output location as part of the following query and make sure the user has permission to write to the Amazon S3 bucket.
Note the QueryExecutionId from the output of the preceding query and run the following query to review the content of the query:
Using the Athena console
If you have access to the Athena console, you can run any of your analytics queries after choosing the appropriate data source, catalog, and database. In this example, it would be the following:
- Data source:
AwsDataCatalog - Catalog:
s3tablescatalog/streamtablebucket - Database:
analytics
Here is a snapshot of running an analytics query using the Athena query editor with results read from the S3 Table bucket.
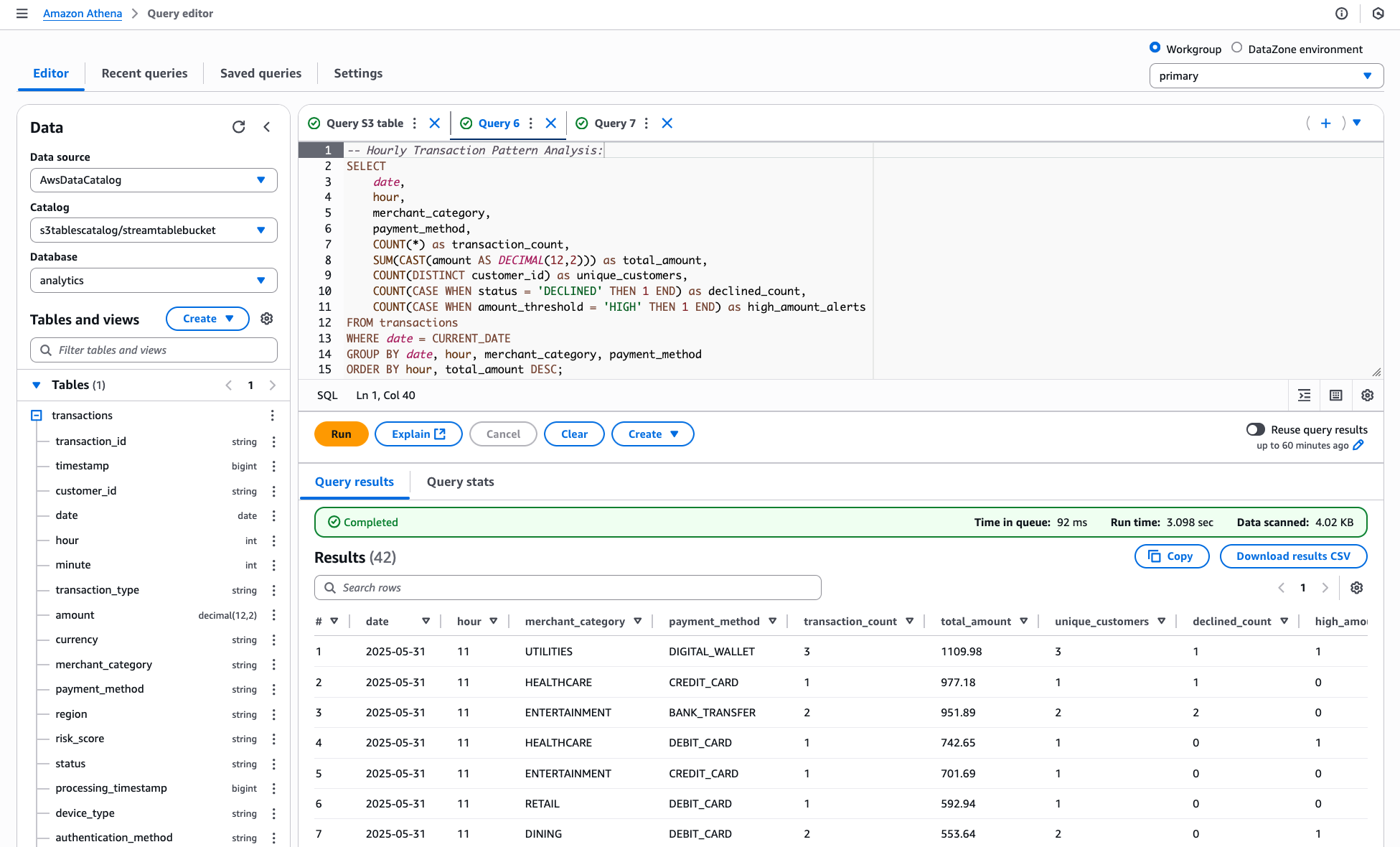
The following are two examples of analytics queries you can run against the sample financial transactions data:
Now you can run your analytics queries against your S3 Tables as your transactional data lake.
S3 Tables maintenance configuration
Configuring S3 Tables maintenance is essential for optimizing performance and controlling costs for your transactional table workload. Proper maintenance settings help manage file compaction and data retention, and optimize read/write operations. To configure maintenance for S3 Tables, use the S3 Tables API or the AWS Management Console to set up automated optimization tasks.
For example, the following python script can be used to configure the compaction thresholds and snapshot retention periods:
Clean up
Delete the resources you created to avoid unexpected costs:
Conclusion
This post’s solution demonstrates how to integrate DynamoDB with S3 Tables to enable analytical capabilities through controlled data transformations. The serverless architecture minimizes operational overhead while providing the benefits of Iceberg’s table format for analytics workloads. This solution is suitable when you need a data lake architecture with open table formats and you want managed Iceberg tables without maintenance.
For analytical use cases, also evaluate AWS services such as the Amazon Redshift zero-ETL integration or Amazon OpenSearch Service.