AWS Database Blog
Optimize and troubleshoot database performance in Amazon Aurora PostgreSQL by analyzing execution plans using CloudWatch Database Insights
Amazon Web Services (AWS) offers a comprehensive suite of monitoring tools to increase visibility of performance and events for Amazon Relational Database Service (Amazon RDS) and Amazon Aurora databases. In this post, we demonstrate how you can use Amazon CloudWatch Database Insights to analyze your SQL execution plan to troubleshoot and optimize your SQL query performance in an Aurora PostgreSQL cluster.
PostgreSQL query optimizer and query access plans
The PostgreSQL query optimizer is a core component of the database engine and is responsible for determining the most efficient way to execute SQL queries. When a query is submitted, PostgreSQL doesn’t execute it directly, instead it generates multiple possible execution strategies and selects the optimal one based on cost estimation.
A query access plan is the step-by-step execution strategy chosen by the optimizer. It details how PostgreSQL will retrieve and process data, using techniques such as sequential scans, index scans, joins, and sorting operations. You can analyze query plans using the EXPLAIN command with options to understand execution paths.
Understanding the PostgreSQL query optimizer and query access plan is important for developers and database administrators to optimize database performance and optimize resource usage effectively. To learn more, see How PostgreSQL processes queries and how to analyze them.
Solution overview
In December 2024, AWS introduced CloudWatch Database Insights, a comprehensive database monitoring solution that supports Aurora (both PostgreSQL and MySQL variants) and Amazon RDS engines, including PostgreSQL, MySQL, MariaDB, SQL Server, and Oracle. This observability tool is specifically designed to help DevOps engineers, developers, and DBAs quickly identify and resolve database performance issues. By providing a unified view across database fleets, Cloudwatch Database Insights streamlines troubleshooting workflows and improves operational efficiency.
CloudWatch Database Insights has an Advanced mode and a Standard mode. The tool to analyze Aurora PostgreSQL execution plans is only available in Advanced mode. In the following sections, we show you how to enable the SQL execution plan analysis feature in your Aurora PostgreSQL clusters. We also guide you through troubleshooting query performance issues caused by plan changes and help you optimize query performance based on the query plan.
For this post, we use a typical e-commerce application schema that contains customer information, a product catalog, order details, and order line items. These elements are represented by corresponding tables – customers, products, orders, and order_items – which makes up the online retail database.
In the next sections, we show how you can analyze SQL execution plans for Aurora PostgreSQL-Compatible edition in CloudWatch Database Insights.
Prerequisites
To follow along with this post, some additional configuration is required. Refer the prerequisites in Analyzing execution plans with CloudWatch Database Insights for detailed information.
Analyze SQL execution plans
Let’s look at an example of a typical query executed against this application and how we can analyze the execution plans through CloudWatch Database Insights.
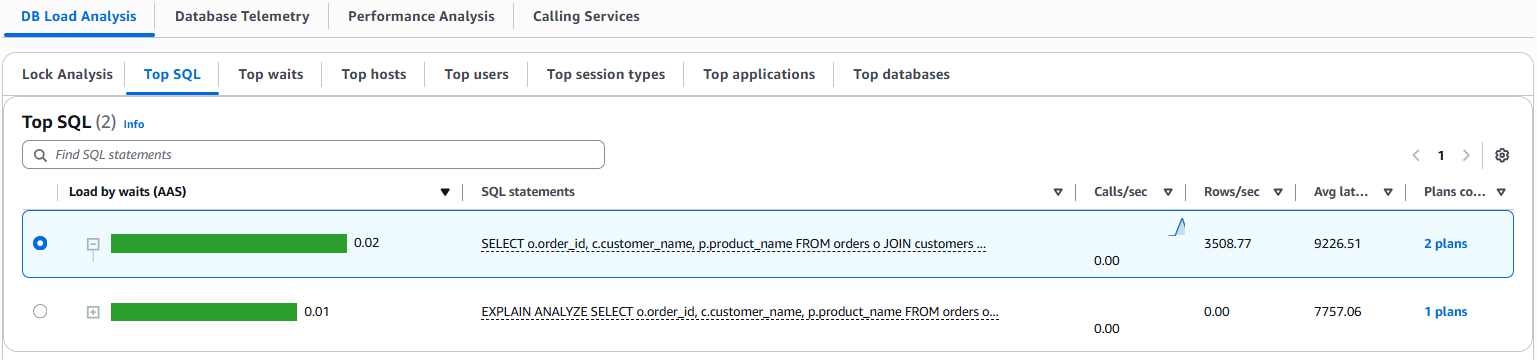
We begin our investigation by accessing CloudWatch Database Insights through the CloudWatch console. After navigating to Database Views, we locate our Aurora PostgreSQL DB instance and examine its performance metrics on the Top SQL tab.
The Plans Count column in the Top SQL table indicates the number of collected plans for each digest query. If needed, you can choose the settings icon to customize column visibility and ordering in the Top SQL table.
We then focus on the specific SQL statement executed by our e-commerce application. By selecting the digest query and reviewing its details on the SQL text tab, we can see the exact SQL statement being run. The Plans tab provide us with a detailed view of the query execution plans.
For comparative analysis, up to two plans can be selected simultaneously, as shown in the following screenshot.

Our side-by-side comparison of the two executions reveal a crucial difference: one plan used a sequential scan approach, whereas the other employed an index scan. This difference in access path selection provided valuable insights into query performance variations and resource utilization patterns.

Second Execution plan 616519750:
Compare execution plans to troubleshoot performance degradation
When investigating SQL query performance degradation issues, DBAs and DBEs often rely on analyzing query execution plans. They look for changes in execution behavior that could impact performance, such as dropped indexes, inefficient join strategies, or suboptimal query patterns. However, manually comparing complex, nested execution plans across different time periods can be tedious and error-prone.For example, consider the following statement executed by our sample application. It retrieves order details along with associated customer and product information for orders placed after a specific date:
To simulate a real-world scenario of accidental index deletion, we dropped some indexes on the orders and order_items tables, particularly those involved in join conditions, and updated the table statistics. These changes resulted in a suboptimal execution plan, causing the query to slow down dramatically and negatively impact overall application performance.
You can use CloudWatch Database Insights to compare execution plans for the same SQL statement over time. This simplifies troubleshooting by highlighting changes that might have led to performance degradation and helping teams quickly diagnose and resolve performance issues.The following screenshot shows the SQL query and its execution plan information from CloudWatch Database Insights. You can also copy or download the execution plans.
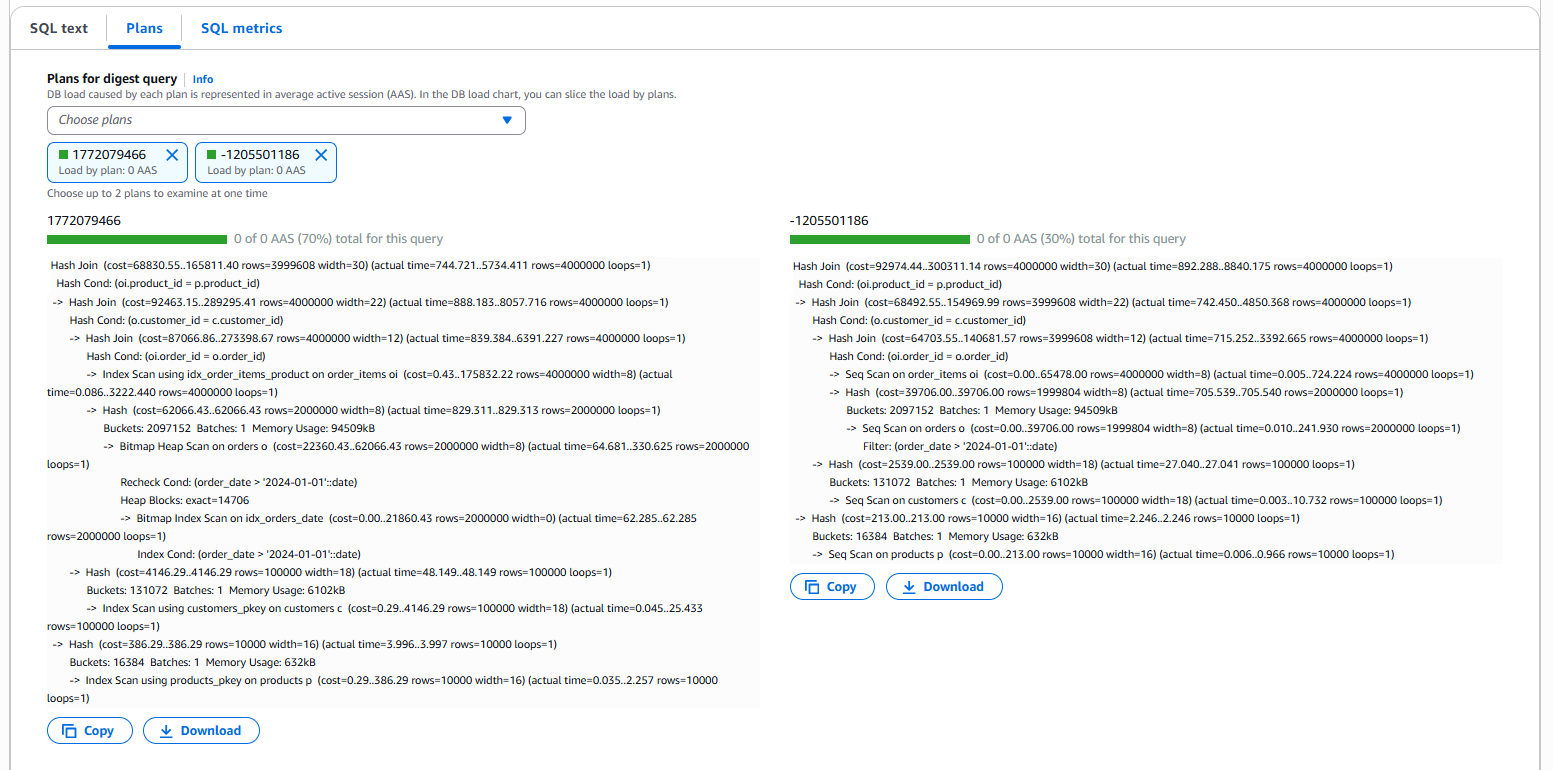
Following are the detail of execution plans as seen in above screenshots.
First Execution plan 1772079466
Second Execution plan -1205501186
As seen in the execution plan details, there are significant differences between the two recorded execution plans for the same query, each with a direct impact on performance. The query execution plan on the lower left represents the original state, where appropriate indexes are in place, resulting in index scans on tables involved and a total query cost of 165811.40. In contrast, the execution plan on the lower right reflects the state after those indexes were accidentally dropped, leading to sequential scans on tables involved and a much higher total cost of 300311.14. This increase in cost clearly explains the performance degradation experienced after maintenance where the indexes got accidentally dropped.
Using the side-by-side execution plan comparison feature in CloudWatch Database Insights to determine the root cause of the performance degradation was simplified by automating what would typically require manual query plan extraction and comparison.
Analyze execution plans to optimize query performance
Analyzing a SQL query execution plan provides deep insights into how the database engine processes a query. By examining key elements such as join types, scan methods, Sorting techniques, estimated and actual row counts, and operator costs, you can identify inefficiencies and performance bottlenecks. These details help identify issues such as missing indexes, suboptimal join orders, outdated statistics, and misconfigured database parameters. You can then use this information to fine-tune queries and optimize performance.
For this example, consider the following statement executed by our e-commerce application that summarizes customer spending per order date, sorted from highest to lowest total amount spent. Database monitoring has identified degraded query execution times as the cause of the application slowdown and overall performance bottlenecks. We’ll demonstrate how to optimize query performance using CloudWatch Database Insights. As part of this process, we use EXPLAIN ANALYZE to examine the actual execution plan and identify opportunities for improvement.
The following screenshot shows the query execution plan in CloudWatch Database Insights.
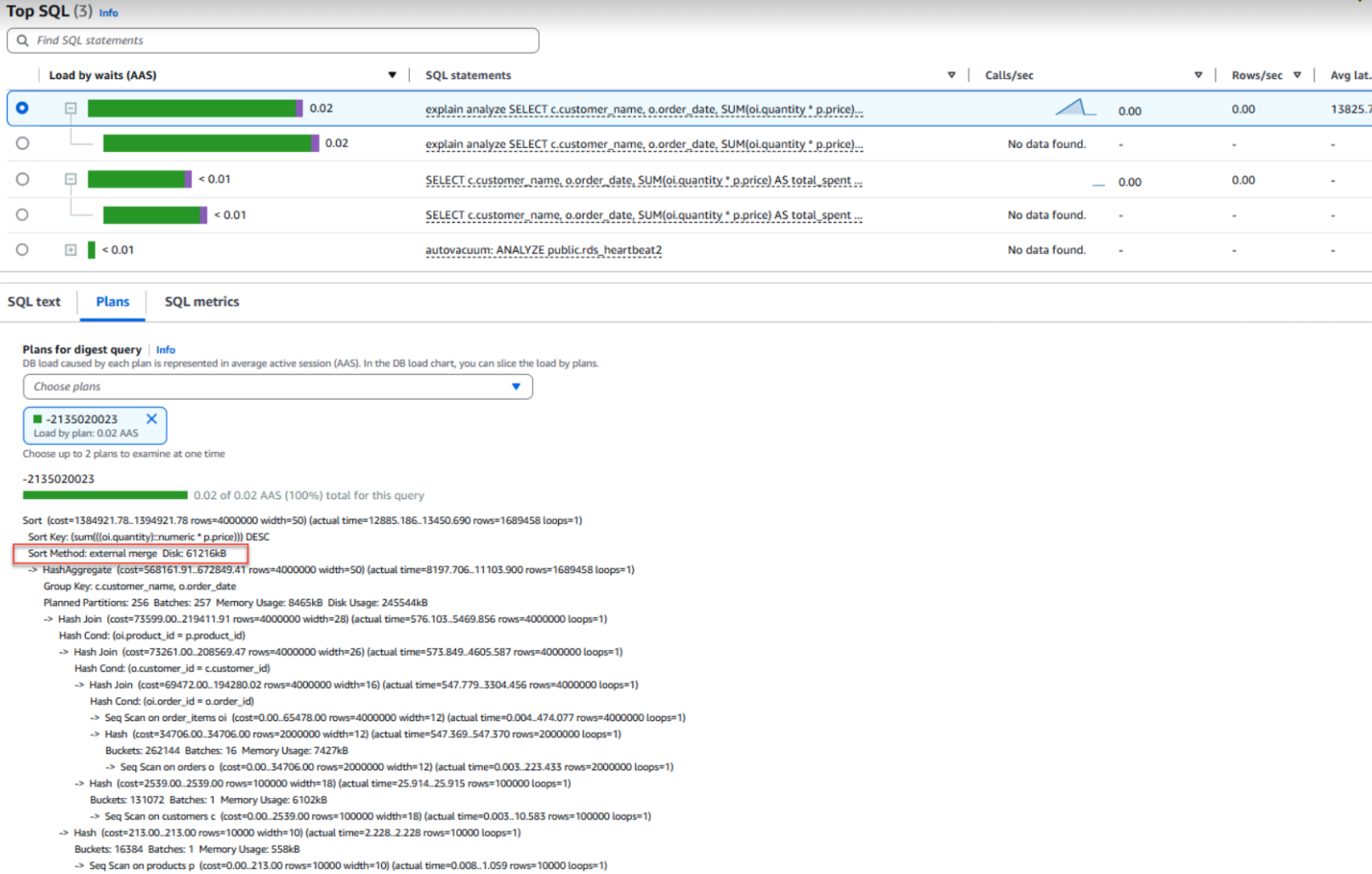
Here is the detail of execution plan as seen in above screenshot.
Execution plan -2135020023
From the query execution plan, we notice a relevant clue: Sort Method: external merge Disk: 61216kB. This is a significant finding in our investigation. It indicates the database had to resort to disk-based sorting instead of keeping everything in memory. This external disk usage strongly suggests a performance bottleneck with the SQL statement.
Digging deeper into PostgreSQL’s parameter group configuration, we found that sorting operations are controlled by the work_mem parameter, currently set to its default value of 4 MB. While this setting was sufficient when our dataset was smaller, recent data growth has pushed memory requirements well beyond this limit. Our investigation shows that the query now requires approximately 61 MB of memory for sorting operations. With only 4 MB of work_mem available, PostgreSQL is forced to spill sort operations to disk, resulting in high I/O costs and significant performance degradation.
Based on our investigation, we can now optimize performance by increasing work_mem at the session or query level to 256 MB before executing the query. This allows Aurora PostgreSQL to use faster in-memory sort methods like quicksort instead of costly disk-based sorting. See the following code:
For more information on this topic, see Tune sorting operations in PostgreSQL with work_mem.
The following screenshot shows the sort operation is now happening in the main memory of the database rather than the disk.
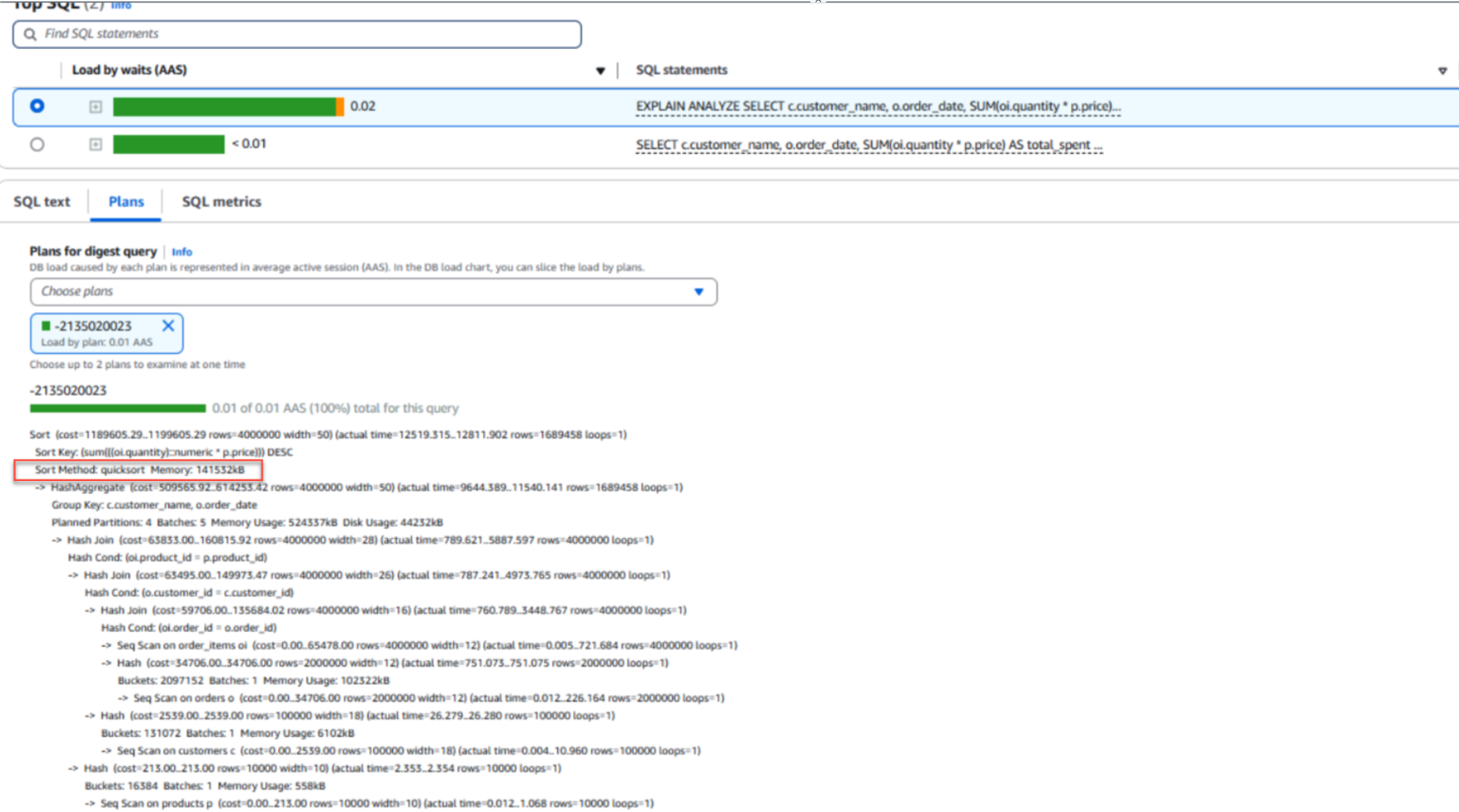
Here is the detail of execution plan as seen in above screenshot.
Execution plan -2135020023
Using CloudWatch Database Insights simplified the optimization process by providing clear visualization of query execution patterns, which helped us identify the work_mem parameter as the root cause.
Conclusion
In this post, we showed how to use CloudWatch Database Insights for Aurora PostgreSQL to analyze execution plan changes and resource constraints that impact database performance, without extensive manual investigation. In our example scenarios, we identified a sudden spike in query latency caused by a dropped index that changed the query’s access path, and diagnosed a performance bottleneck from disk-based sorting operations and resolved it by increasing the work_mem parameter.
Get started with CloudWatch Database Insights.