AWS Database Blog
Optimize Amazon RDS Multi-AZ backups with incremental snapshots
Amazon Relational Database Service (Amazon RDS) empowers organizations to efficiently manage and scale their databases while maintaining reliable backup strategies. As your business grows and your databases expand into the terabyte range, optimizing your backup strategy becomes increasingly important for maintaining operational excellence. Modern backup solutions that implement incremental backups where possible, offer an elegant way to protect your valuable data while minimizing maintenance windows and ensuring consistent application performance. This is especially beneficial for organizations managing large-scale databases where traditional full backups could take several hours to complete.
In this post, we discuss the aspects of maximizing the use of incremental backups in Amazon RDS, leading to backup times remaining steady even while the database grows. This post applies to available Amazon RDS database engines except Amazon Aurora, since the storage layer on Aurora doesn’t use Amazon Elastic Block Store (Amazon EBS). For more information on handling backups on Aurora, refer to Streamlining Point-in-Time Recovery (PITR) for Amazon Aurora with AWS Backup or Using AWS Backup to protect Amazon Aurora databases. This post applies to databases in both Single-Availability Zone (AZ) and Multi-AZ configurations. For Single-AZ setups, you can disregard the failover monitoring instructions between zones.
We start this post with understanding Amazon RDS capabilities and then dive into the backup strategy.
Understanding Amazon RDS
Amazon RDS is a managed database service that simplifies database administration for multiple popular database engines. Its Multi-AZ deployment option enhances availability by maintaining a synchronous standby replica in a different Availability Zone, enabling automatic failover within minutes with zero data loss. RDS’s comprehensive backup strategy combines automated storage-layer backups and transaction logs, ensuring consistent and reliable database backups while maintaining optimal performance. These automated backup capabilities work seamlessly with Multi-AZ deployments, providing a robust foundation for your mission-critical applications.The following diagram illustrates Amazon RDS Multi-AZ deployments.
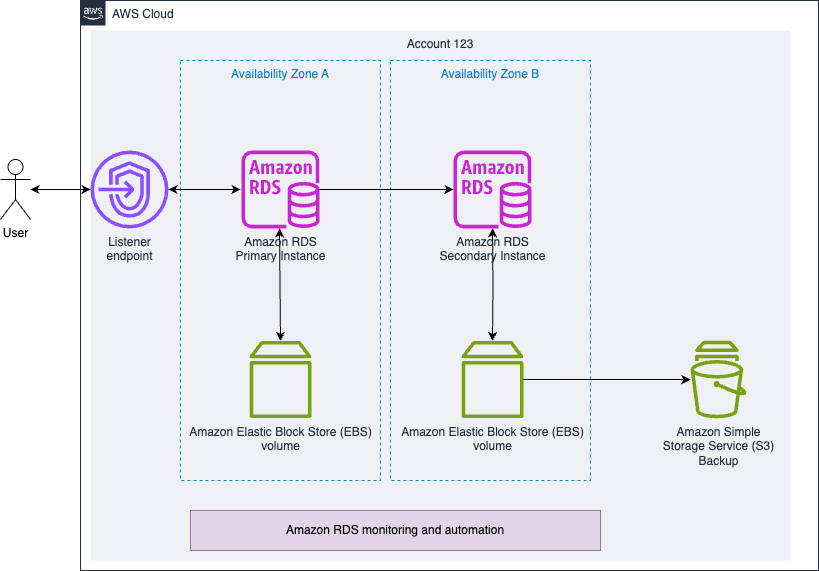
Figure 1: Amazon RDS Multi-AZ deployment with primary instance in Availability Zone A
As demonstrated in Figure 1, in a Multi-AZ setup for MariaDB, MySQL, Oracle, and PostgreSQL, automated backups are taken from the EBS volume of the standby instance on the storage level rather than the primary instance, minimizing latency spikes during system backups and the I/O activity is not suspended on your primary during backup for Multi-AZ deployments.
Besides automated backups, which provide point-in-time recovery (PITR) abilities, you have the possibility to create snapshots manually. These manual snapshots are not automatically deleted like the automated backups and can be retained indefinitely. They can be copied to different AWS Regions or shared with other accounts. They can also be exported to Amazon Simple Storage Service (S3), though this extracts the data from the snapshot and stores it in an Amazon S3 bucket (this is a data only export). The data is stored in compressed Apache Parquet format.
Using incremental snapshots
Amazon RDS incremental snapshots significantly enhance backup efficiency by capturing only the data blocks that have changed since the last snapshot, reducing backup windows from hours to minutes even for large databases. This approach optimizes storage costs and infrastructure resources by eliminating the need to store duplicate data blocks across multiple full backups, while maintaining the same level of data protection.To optimize the backup window and mechanism, we want to maximize the use of incremental snapshots. Although Amazon RDS handles the underlying mechanics automatically, optimizing this feature greatly improves backup efficiency. After the initial full snapshot, you want subsequent snapshots to only capture the blocks that have changed since the last snapshot (incremental snapshot).
The post Accelerate cross-account Amazon RDS refreshes with incremental snapshots mentions the steps to use incremental backups after the first full backup, which you can check out for your Single-AZ setup and also as an introduction to this post. We’re moving from automatic backups to manual snapshots for greater flexibility in sharing and copying. If you’re currently using automatic backups and want to adopt this new approach, you can convert your existing backup into a manual snapshot first. Simply create a copy of your automatic backup – this copy will function as a standalone snapshot and can be managed using the new process we’re describing.
The previously mentioned post introduced the following decision tree for incremental backups.

Figure 2: Amazon RDS internal workflow for incremental or full backup copies for Single AZ deployments
The decision tree shown in Figure 2 consists of the following steps:
- The RDS DB instance RDS-1 is encrypted with AWS Key Management Service (AWS KMS) key KMS-Key-1.
- KMS-Key-1 is used to encrypt the automatic backup of RDS-1.
- Amazon RDS creates a copy of the automated backup.
- The workflow verifies the existence of a previous copy.
- If a previous copy exists, the automation verifies whether the previous copy is using the same KMS key:
- If the previous copy is using the same KMS key, an incremental copy is performed.
- If the previous copy uses a different KMS key, a full copy is performed.
- If the previous copy doesn’t exist, the copy is a full copy regardless of whether the KMS key is the same or not.
In this post, we explore this logic for a Multi-AZ setup and will build our snapshot retention logic to leverage subsequent incremental snapshots where possible. We are concentrating on manual snapshots, because they provide comprehensive control over scheduling and retention management. The decision tree works as follows.
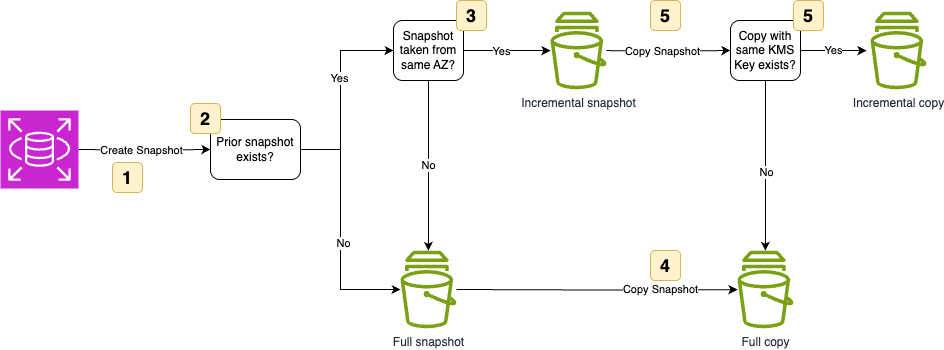
Figure 3: Amazon RDS internal workflow for incremental or full snapshot copies for Multi-AZ deployments
The steps shown in Figure 3 are as follows:
- Amazon RDS creates a snapshot.
- If there is no prior snapshot, the snapshot will be full.
- RDS determines if an existing snapshot was taken from the same Availability Zone as this new snapshot. If no snapshot exists for the same Availability Zone, then this snapshot will be a full one. Otherwise, it is an incremental snapshot.
- You can copy the full snapshot, the copy will be full as well.
- If you copy an incremental snapshot, RDS checks if there is already a copy that was encrypted with the same KMS key within the same Availability Zone. If not (you are re-encrypting with a different key), then the copy will be a full copy. Otherwise, you get an incremental copy of the snapshot.
This means for snapshots and their copies, the following must apply so that all snapshots after the initial full one are indeed incremental (also including the guidelines from the documentation):
- Maintain at least one manual database snapshot per Availability Zone.
- Before deleting a snapshot, ensure a newer one exists in the same Availability Zone.
- Use automation to add the Availability Zone ID to snapshot names for easy tracking.
- For each Availability Zone and KMS customer managed key (CMK), keep at least one database snapshot copy. Before deleting a snapshot copy, verify a newer copy exists in the same Availability Zone with the same CMK encryption.
- For cross-account snapshot copies to be incremental:
- The most recent snapshot copy of the same source DB instance must exist in the destination account.
- All snapshot copies in the destination account must be either unencrypted or encrypted with the same KMS key.
- For Multi-AZ instances, no failover should have occurred since the last snapshot was taken.
- Note that automatic backup retention is governed by backup settings, not manual control.
The following diagram illustrates our RDS Multi-AZ deployment, first with snapshots in Availability Zone A.
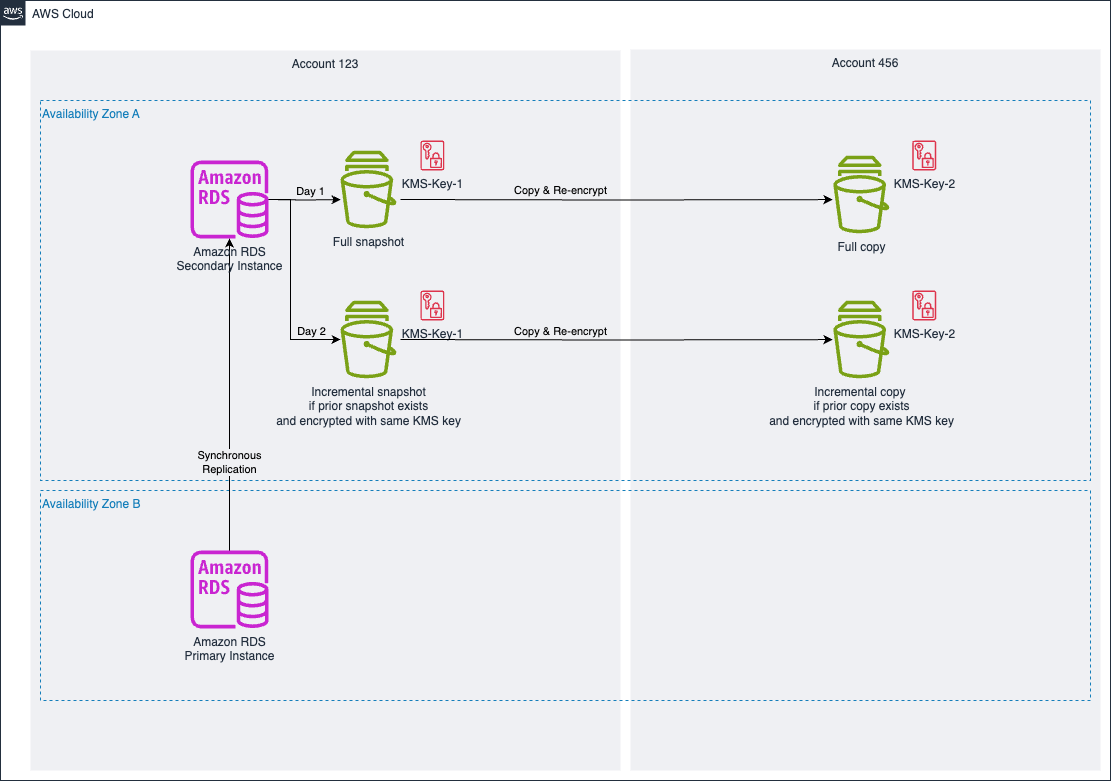
Figure 4: Amazon RDS Multi-AZ deployment with primary instance in Availability Zone B
The Amazon RDS deployment has the primary instance in Availability Zone B and the secondary instance in Availability Zone A, as shown in Figure 4. As discussed earlier, snapshots are taken from the secondary instance. The full snapshot and all its copies (re-encrypted or not) are full. On the second day and all following days, the snapshots are incremental if the previous snapshot and copy with the same KMS key still exists. You should keep a full prior chain of snapshots and copies until the next run is complete, as for each step of the process you need a prior snapshot existing to make sure the next snapshot is also incremental.
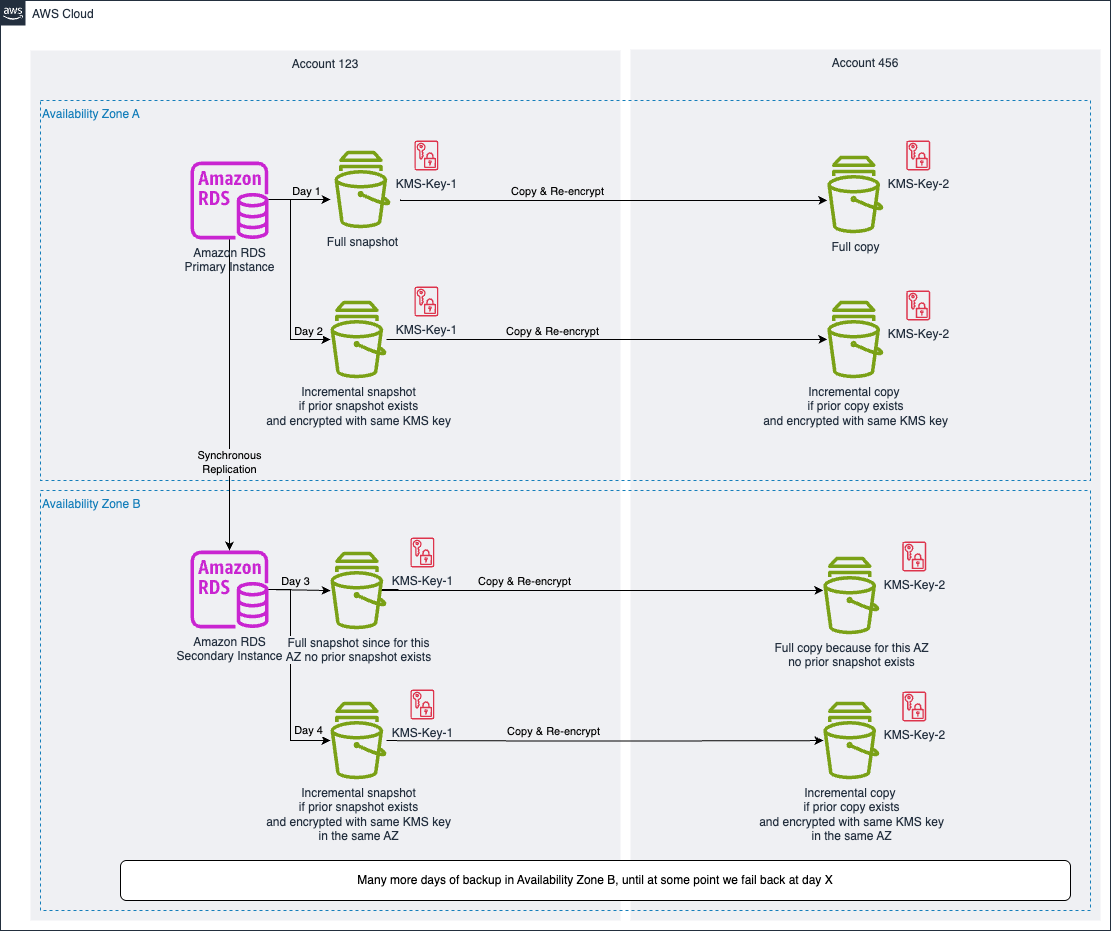
Figure 5: Amazon RDS Multi-AZ deployment with primary instance in Availability Zone A after failover
Figure 5 visualizes the failover of the database prior to the snapshots on day 3, which changes the primary instance to be in Availability Zone A and the secondary instance to be in Availability Zone B. Now the snapshots are taken from Availability Zone B. As for this Availability Zone, on day 3 if there are no snapshots in the same Availability Zone, the first snapshot and copy will be full. On day 4, if we retain the full chain of snapshots and copies from Availability Zone B (in this case of day 3), the snapshots and copies will be incremental. Therefore, you should also keep the last full chain of snapshots and copies in each Availability Zone.
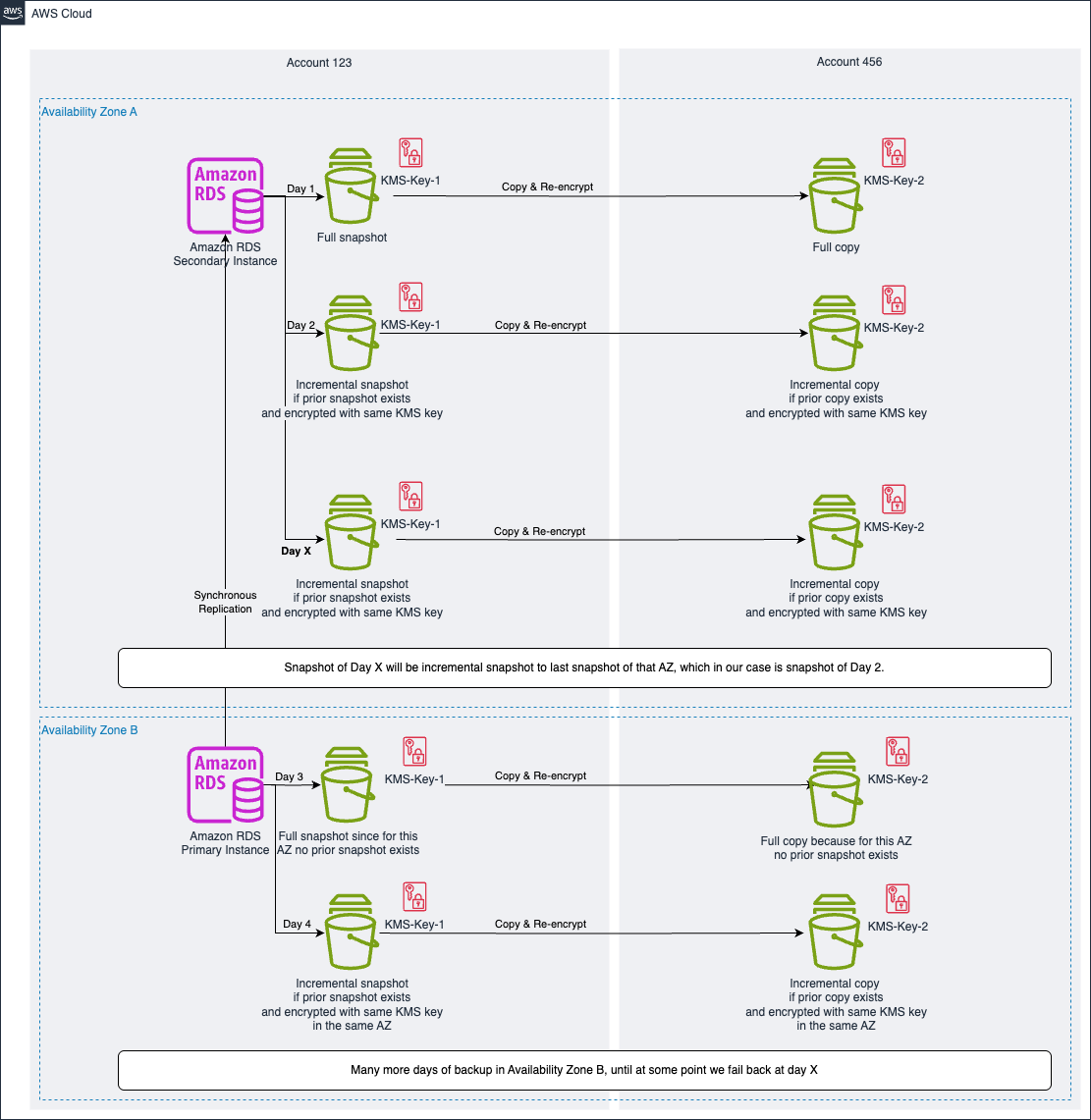
Figure 6: Amazon RDS Multi-AZ deployment with primary instance in Availability Zone B after failback
After we fail back the database, because we kept snapshots in Availability Zone A, we are now creating incremental snapshots and copies as also shown in Figure 6. Those will be incremental to the last existing snapshot or copy in that one Availability Zone, so to the snapshot and copies of day 2 with this example, accumulating in the first incremental snapshot the block changes since the last snapshot on day 2. The duration of creating the new incremental snapshot depends heavily on the amount of data changed since the last snapshot – if multiple TB of data changed since your last snapshot, this will heavily impact the creation time. In the next section we will dive into optimization considerations.
Optimizing for cost and performance
The current option to always build on a full snapshot prior to the next incremental one is to always retain a snapshot per Availability Zone and per encryption key. An optimization for this could be to always immediately fail back when you failed over to a different Availability Zone, which would make sure the snapshot is always taken in the same Availability Zone and alleviates the need to retain the snapshot for multiple Availability Zones. To automate this, you can subscribe to the DB instance events and initiate the fallback using Amazon Simple Notification Service (Amazon SNS) in combination with AWS Lambda.
A recommendation for the Multi-AZ setup is to take the snapshot from a read replica in a predefined Availability Zone instead of the primary or secondary instance, because this will use the prior saved snapshots in the Availability Zone where the read replica runs and you don’t need to have your snapshots retained per AZ. This feature is supported for available Amazon RDS engines except for SQL Server.
Manual snapshots add to your backup storage costs. Make sure to clean up unneeded manual snapshots. A particular use case is when snapshots are created for a database that was deleted, creating orphaned snapshots. These snapshots together with their cross-account, cross-Region copies can be deleted to save costs.
Optimizing for faster restore in the same region and same account
Long database restoration periods primarily occur due to extended database recovery processes. When Amazon RDS restores a database to a point in time, it restores the snapshot and then applies the transaction logs necessary to reach the required point in time. In the case of manual snapshot restores, Amazon RDS only restores the snapshot to a newly created instance without applying transaction logs. The time needed for database recovery depends on the workload intensity of your instance during and after snapshot creation.
To reduce the restoration time and the amount of transaction logs applied during recovery, you can implement a backup strategy to take frequent manual snapshots, for example every 2–3 hours – for more details how to automate this check out AWS Lambda function for Automated Manual RDS Snapshots. Having intermediate manual snapshots can reduce the number of transaction logs to be applied, thereby reducing the total amount of time needed for database restore.
You can use manual snapshots as a backup mechanism when applying big changes to an existing database, like patching, upgrading, or long-running application deployments. You can run a manual snapshot just before the event, and use a PITR restore in case of failure, with minimal effort and a low number of transaction logs to be applied.
Conclusion
By implementing an incremental snapshot strategy in your Amazon RDS Multi-AZ deployment, you can achieve significantly faster snapshot times and optimize costs while maintaining robust disaster recovery capabilities. This approach addresses the fundamental challenges of backing up large databases while providing the flexibility needed for enterprise operations.Although specific snapshot completion times aren’t guaranteed, an incremental approach consistently provides better performance than traditional full snapshots. Regular testing and monitoring of your backup strategy makes sure it continues to meet your organization’s recovery objectives while optimizing resource usage.
For more detailed information about the underlying strategies, refer to our documentation on backup strategies and stay current with AWS database service updates and best practices.