AWS Database Blog
Implement a rollback strategy for Amazon Aurora PostgreSQL upgrades using Amazon RDS Blue/Green deployments
Amazon Aurora PostgreSQL-Compatible Edition is a fully managed relational database engine designed for high performance and availability. It supports managed blue/green deployments to help reduce downtime and minimize risk during updates. Blue/green deployments create a fully managed staging environment using logical replication, allowing you to deploy and test production changes safely. The blue environment represents the current production database, while the green environment includes the necessary updates or changes without requiring modifications to your application endpoint. This approach minimizes risk and downtime associated with updates such as engine version upgrades or system patches. Once validated, you can seamlessly promote the green environment to production, keeping your application endpoint unchanged.
Even with thorough planning and testing in non-production environments, unexpected issues can emerge after a version upgrade. For example, a new schema change might work perfectly in staging but cause errors in production due to differences in real-world data patterns or untested application queries that weren’t exercised during testing. Performance drops can also occur because of real-world traffic and workloads. In these cases, having a rollback plan is essential to quickly restore service stability. While the managed Blue/Green deployment feature doesn’t currently include built-in rollback functionality, you can implement alternative solutions for version management.
In this post, we show how you can manually set up a rollback cluster using self-managed logical replication to maintain synchronization with the newer version after an Amazon RDS Blue/Green deployment switchover. The rollback cluster serves as a backup option if you need to revert to the original version.
Solution overview
The following diagram shows the high-level workflow of this solution.
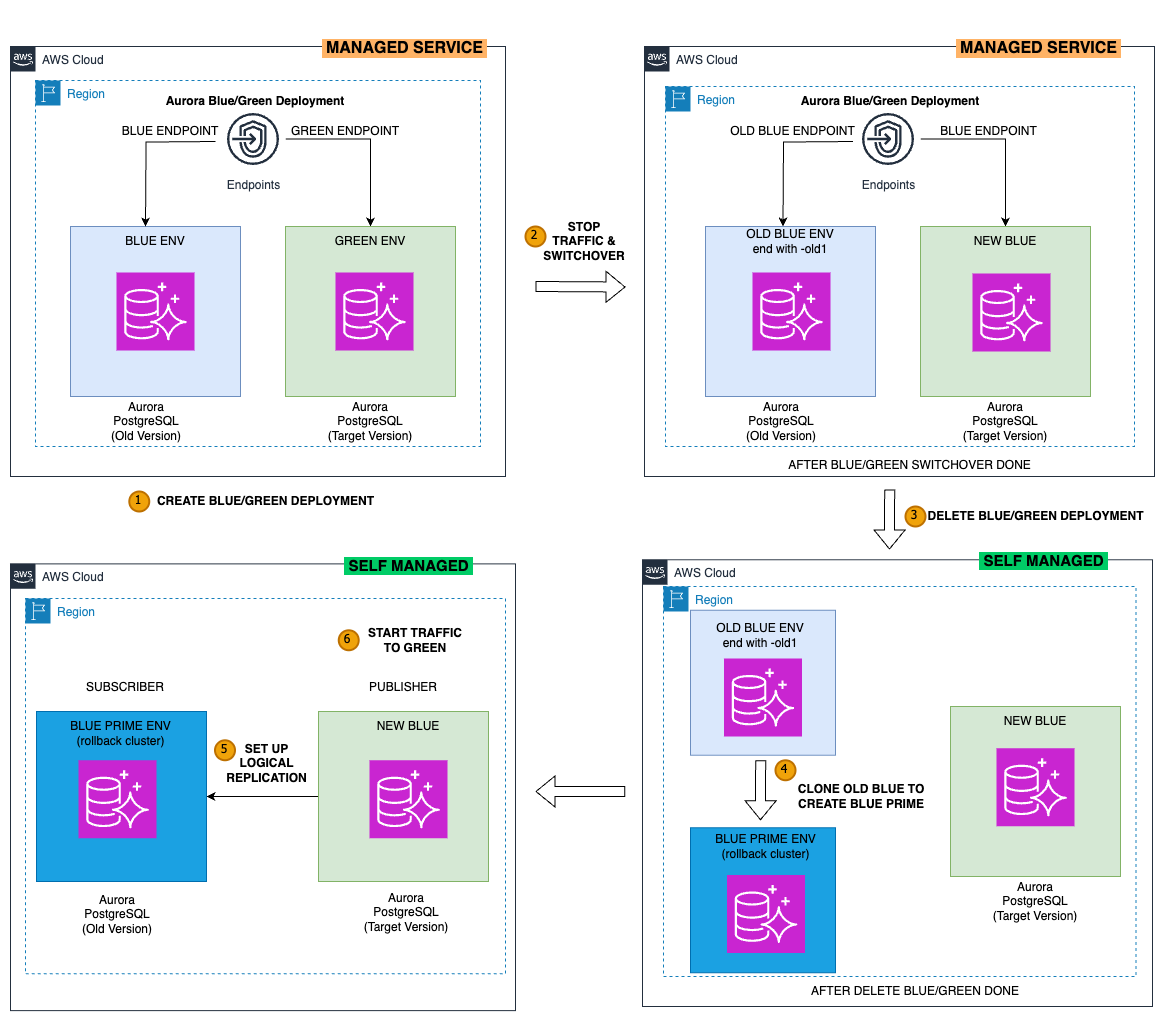
Before switchover, you have two clusters:
- Blue cluster – The existing production database cluster
- Green cluster – The mirrored and synchronized staging environment from the blue cluster
After switchover, you have three clusters:
- Old blue cluster – Your original production cluster (previously the blue cluster)
- New blue cluster – The new version of your production cluster, where your workload will run (previously the green cluster)
- Blue prime (rollback) cluster – A clone of the old blue cluster and synchronized with the new blue cluster data (will be used as a rollback cluster)
The workflow steps are as follows:
- Create a blue/green deployment
- Stop traffic on blue cluster and perform switchover to green cluster
- Delete the blue/green deployment
- Clone the old blue cluster to create the blue prime (rollback) cluster
- Set up logical replication from the new blue cluster to the blue prime (rollback) cluster
- Start traffic to the new blue cluster
For this post, we simulate an Amazon Aurora PostgreSQL-Compatible Edition major version upgrade from version 15.10 to 16.6.
Limitations
- Aurora managed Blue/Green deployment does not replicate DDL, sequence, refresh materialize views, create or modify large objects, or update and delete data on a table without a primary key. For more details, see Limitations and considerations for blue/green deployments.
- While Aurora managed Blue/Green deployments automatically manage the primary cluster endpoint after switchover, you must handle endpoint changes at the application or DNS level if rollback to a previous version is required.
- Setting up the rollback cluster incurs additional downtime.
Prerequisites
You need the following components to implement the solution:
- Support for Blue/Green deployments – Verify that your existing Aurora cluster version supports Blue/Green deployments. For more information, refer to Using Amazon RDS Blue/Green Deployments for database updates and New – Fully managed Blue/Green Deployment in Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL.
- Enable logical replication on the source database cluster (Aurora PostgreSQL v15, in this post).
- Perform a one-time in-place minor version upgrade to a version that supports Blue/Green deployments if required.
- AWS CLI.
Note: Enabling the logical replication parameter requires a reboot of the writer instance. For more information, see Using logical replication with Aurora PostgreSQL DB clusters
- A cluster parameter group for the new version database: Since we will be setting up logically replication from newer version to the older version, we need to make sure the new version (Aurora PostgreSQL 16) has logical replication enabled. The following AWS CLI commands will create cluster parameter group and enable logical replication parameter.
- Understand the Aurora cloning feature, see Cloning a volume for an Amazon Aurora DB cluster.
Create a Blue/Green deployment
Amazon RDS Blue/Green deployment is managed by AWS. Behind the scenes, it creates and mirrors resources from the Blue environment to the Green environment and replicates DML changes from the Blue environment to the Green environment using native logical replication.
You can use the AWS Command Line Interface (AWS CLI) to create a RDS blue/green deployment using the following command, where the source is the Amazon Resource Name (ARN) of the source production database. The following RDS Console screenshot shows existing cluster with logical replication enabled (Blue cluster).

Use the following command to create a Blue/Green deployment with a Green cluster on Amazon Aurora PostgreSQL version 16. The Green cluster must be attached to an appropriate parameter group with logical replication previously created.
Once all instances are available, you have a blue/green deployment with both the blue and green cluster attached.
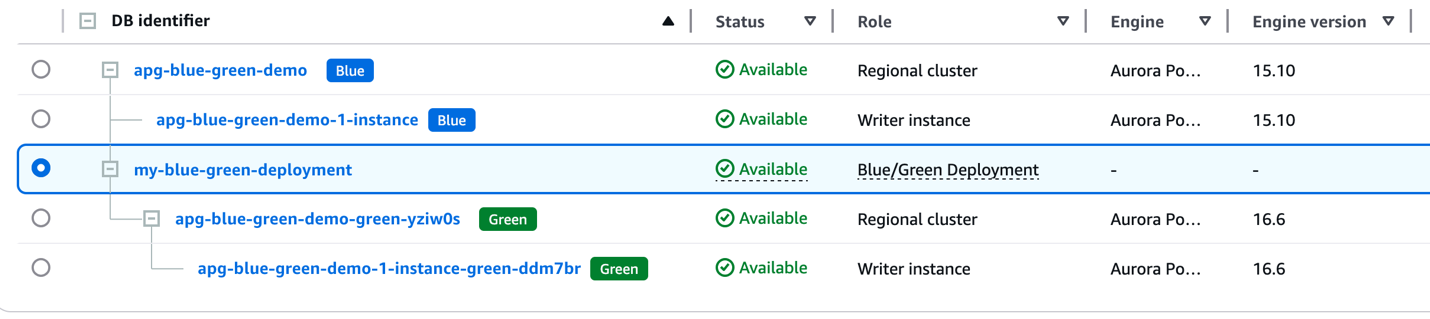
Stop traffic and perform the switchover
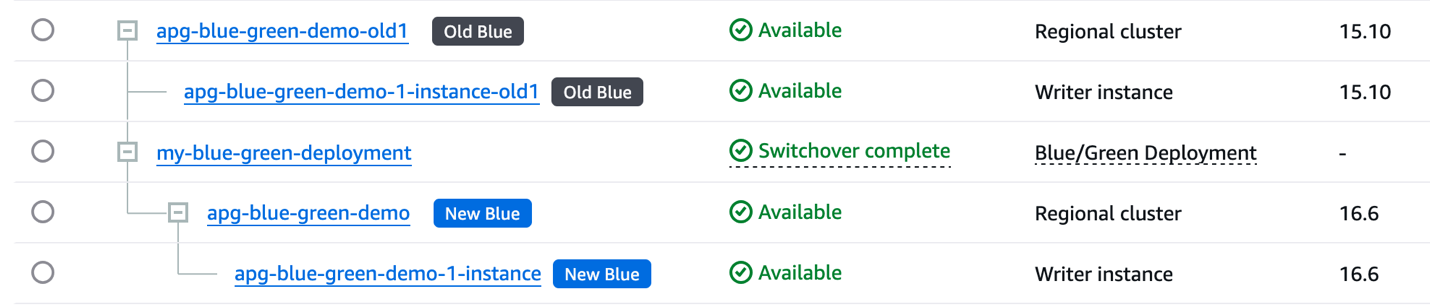
To promote the green cluster, you must initiate a switchover action. Before the switchover is initiated, stop the database traffic on blue cluster to ensure data consistency during blue prime creation. You can use VPC Security Groups to block inbound and outbound database traffic. After the switchover is complete, verify the updated labels on your RDS blue/green deployment.
Delete the blue/green deployment
Before you configure the Blue Prime (rollback) cluster, you must delete the Blue/Green deployment. Deleting the RDS Blue/Green deployment releases the clusters from the managed environment and cleans up objects such as replication slots, publications, subscriptions, and logical replication components generated by Amazon RDS Blue/Green deployment.
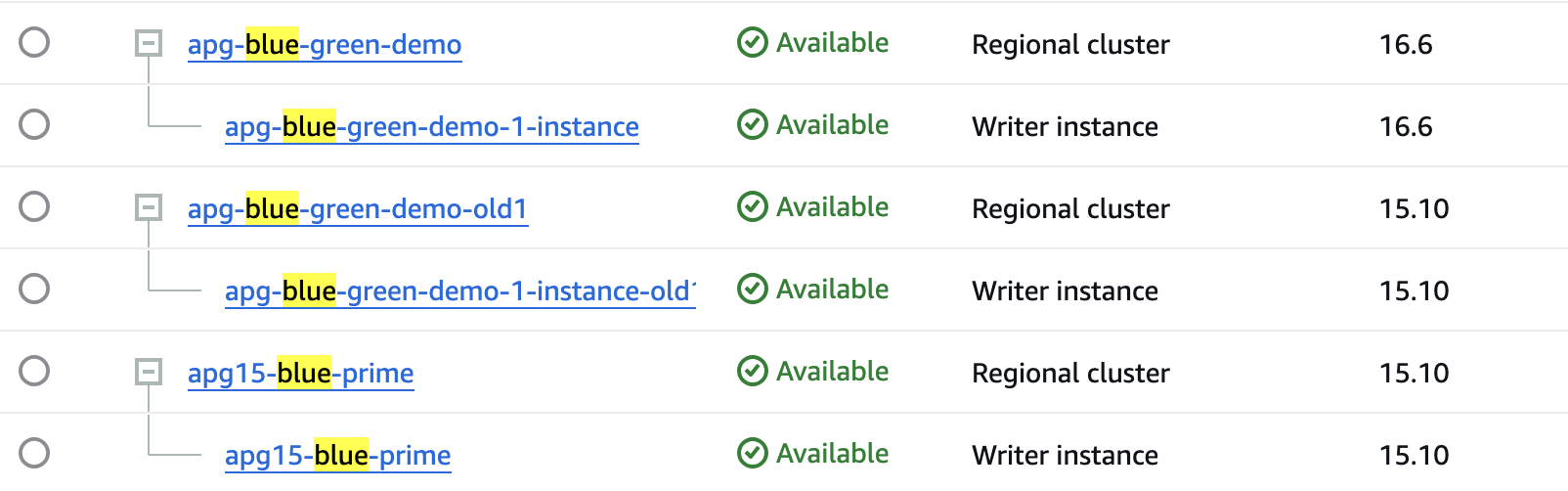
As shown in the following screenshot, now we have two independent cluster, apg-blue-green-demo (v16.6) and apg-blue-green-demo-old1 (v15.10)
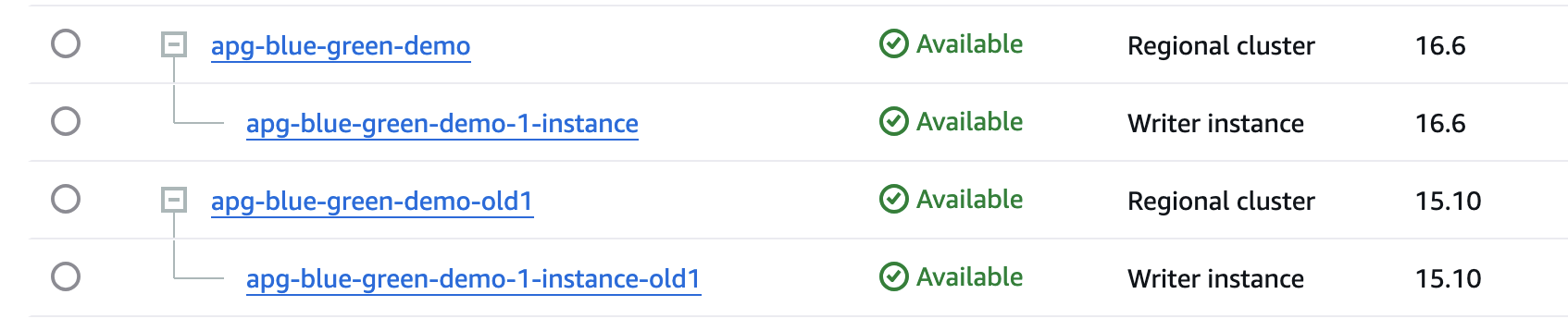
Clone the Old Blue to create the Blue Prime (rollback) cluster
You may need to retain the Old Blue (original) cluster for compliance and auditing purposes. To set up a rollback cluster:
- Clone the Old Blue cluster to create a self-managed Blue Prime (rollback) cluster
- Once available, verify cluster and data accessibility by running simple read-only queries on the cloned cluster
- Document the Blue Prime (rollback) cluster endpoint for potential DNS or application endpoint updates if rolling back becomes necessary
As shown in the following screenshot, we have created a new restored cluster ‘apg15-blue-prime’, which will serve as our rollback target.
Set up the Blue Prime (rollback) cluster
After completing the Blue Prime clone, configure self-managed logical replication from the new Blue cluster (publisher) to the Blue Prime cluster (subscriber). Ensure that no write activities and schema changes are permitted to prevent data synchronization issues.
- On the new Blue cluster (publisher), connect to the database using the cluster endpoint and create a new publication:
Important: Ensure each table has a replication identity (such as a primary key or unique key). If you have multiple databases in the same cluster, repeat the following steps for each database in the newly promoted production cluster (new Blue).
- On the new Blue cluster (publisher), connect to the cluster endpoint and use the following command to create a replication slot using the ‘pgoutput’ plugin:
- On the Blue Prime cluster (subscriber), use the following command to create a new subscription without copying data or creating a new slot:
The code requires the following parameters:
- subscription_name – The name of the subscription.
- admin_user_name – The name of an administrative user with rds_superuser permissions.
- admin_user_password – The password associated with the administrative user.
- source_instance_URL – The URL of the publication server instance.
- database – The database that the subscription server will connect with.
- publication_name – The name of the publication server.
- replication_slot_name – The name of the replication slot you create on step 2.
Important: You need to repeat this activity for every publication (step 1) on the blue prime cluster.
- On the Blue Prime cluster, use the following command to enable the subscription:
Important: You need to repeat this activity for every subscription on the blue prime cluster.
After completing the logical replication setup and verifying data flow from the new Blue to the Blue Prime cluster, you can resume traffic to the new Blue cluster using the existing cluster endpoint. Amazon RDS managed Blue/Green deployment automatically handles DNS changes, allowing your application to use the same endpoint.
Rollback to the Blue Prime cluster
If you need to rollback to the Blue Prime cluster (original version), follow these steps:
- Halt application traffic to maintain data integrity during the transition (You can use Amazon Aurora VPC Security Groups to block incoming traffic)
- Update your application or DNS records to point to the Blue Prime cluster endpoint
- Drop the subscription on the Blue Prime cluster
- If applicable, manually update sequence values
This switch is not automatic because the Blue Prime cluster is no longer under managed service. We recommend creating a runbook or automation script for rollback activities to minimize errors during execution.
While this strategy provides a rollback option, it involves additional downtime when setting up the Blue Prime cluster. This is a trade-off to consider when implementing this approach, it is recommended to thoroughly test in your staging before going to production.
Clean up
For the production environment, you should maintain the new blue prime cluster while validating that all applications have transitioned successfully. Keeping both environments up simultaneously guarantees you can rollback if anything functions inconsistently or unexpectedly in the new infrastructure. You can back up the old blue cluster for compliance purposes and then delete the cluster to reduce costs. You will be charged for all clusters until they’re deleted.
If you created these resources for testing purposes, you should delete all the clusters (blue, green, and blue prime) to avoid additional charges. Complete the following steps to clean up your database cluster:
- Delete each read replica instance, if any.
- Delete the primary instance.
- Delete the database cluster.
Conclusion
In this post, we showed readers how to create a rollback strategy when working with Amazon RDS blue/green deployment to perform database version upgrades. We configured logical replication as a rollback strategy for added safety. Blue/green deployment handles many complex tasks automatically, like creating a mirrored and synchronized database staging version, performing guardrail checks, conducting switchover, and automating the DNS changes. However, having production database changes might involve risk like application incompatibility. Configuring a rollback cluster gives you an extra safe to quickly fall back if anything breaks post-upgrade. You can revert to the old production version until the issues get addressed.
Before switching production workloads, thoroughly test applications against the new database version under production-level load. Make sure your applications are fully compatible and performance remains stable. This greatly reduces the chances of application problems or degradation after blue/green deployment switchover. You can start exploring how the RDS managed blue/green deployment work and its feature before implementing this rollback strategy.