AWS Database Blog
How Global Payments Inc. improved their tail latency using request hedging with Amazon DynamoDB
This is a guest post by Krishna Chaitanya Sarvepalli, Senior Director of Product Engineering at Global Payments Inc., in partnership with AWS.
Amazon DynamoDB delivers consistent single-digit millisecond performance at any scale, making it ideal for mission-critical workloads. However, as with any distributed system, a small percentage of requests may experience significantly longer response times than the average. This phenomenon, known as tail latency, refers to these slower outliers that can be seen by looking at metrics such as the 99th or 99.9th percentile of response times. For latency-sensitive applications like financial systems, these occasional delays can present significant challenges, even if relatively rare, because when processing billions of transactions there may still be millions of impacted transactions.
In this post, we explore how Global Payments Inc. (GPN) reduced their tail latency by 30% using request hedging. We review the technical details and challenges they faced, providing insights into how you can optimize your own latency-sensitive applications. In a next post we’ll share detailed implementation examples.
The GPN use case
As illustrated in Figure 1, GPN developed a cloud-based, DynamoDB-powered credit card authorization platform that is designed to process 100’s of millions of transactions daily, with the capacity to handle 5,000 Transactions Per Second (TPS) at peak load. When a customer uses their credit card at checkout—whether by tapping, inserting, or swiping—the authorization process orchestrates a complex series of operations to verify and approve the payment.
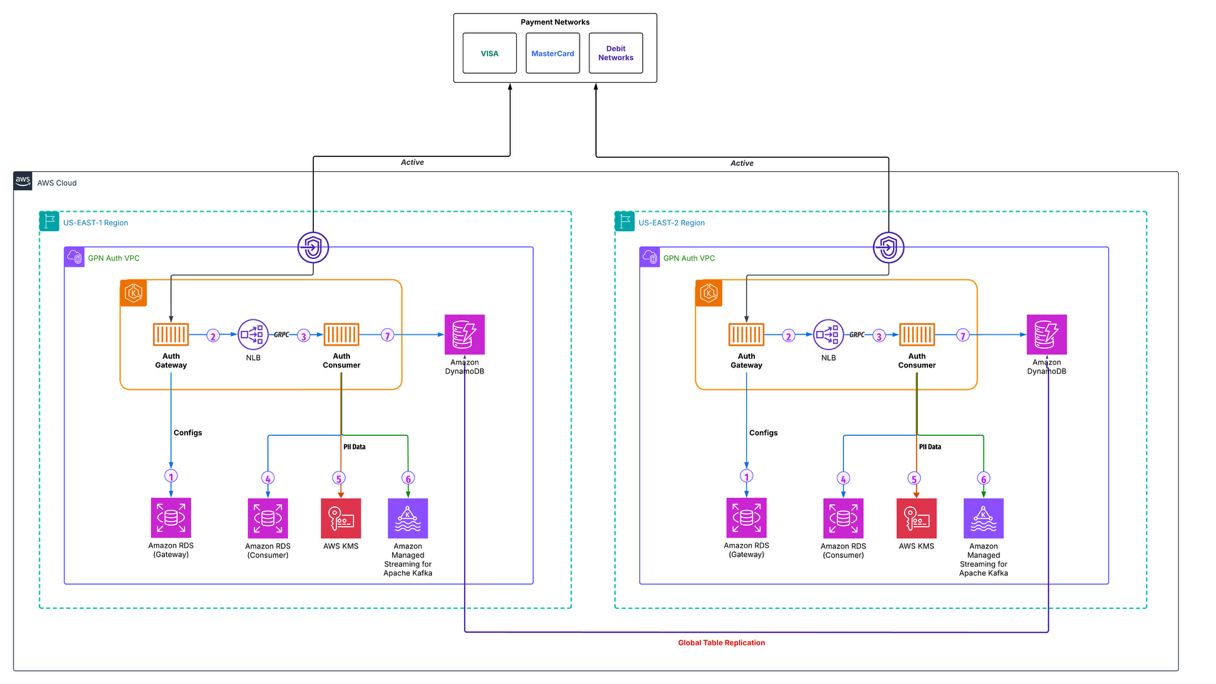
Figure 1. GPN’s Credit card authorization simplified architecture.
During performance testing of their new cloud-based Authorization platform, GPN encountered challenges with tail latencies. While the platform met its Service Level Agreements (SLAs) for transactions up to the 95th percentile, it showed higher latencies in the 99th and 99.9th percentiles. With the system designed to handle 5,000 TPS, this meant that 50 transactions per second—or millions of daily transactions—at the 99th percentile could potentially experience higher latencies. These numbers made it clear that latency optimization wasn’t merely about addressing extreme outliers, but about enhancing the experience for a substantial portion of GPN’s global customer base.
After extensive analysis and working with AWS, GPN implemented request hedging to address these challenges. This solution automatically initiates a second request to DynamoDB when the initial request exceeds some threshold response time. By using whichever response arrives first, this approach statistically achieves faster overall tail latency response times. GPN’s testing demonstrated significant improvements, achieving a 30% reduction in latency as measured at the 99th percentile.
Request Hedging
When making requests between components in a distributed system, two scenarios can occur. In the normal scenario (illustrated in Figure 2), a request travels through the network to the target service and returns a response within the system’s defined Service Level Agreement (SLA). This represents the expected behavior for most requests.
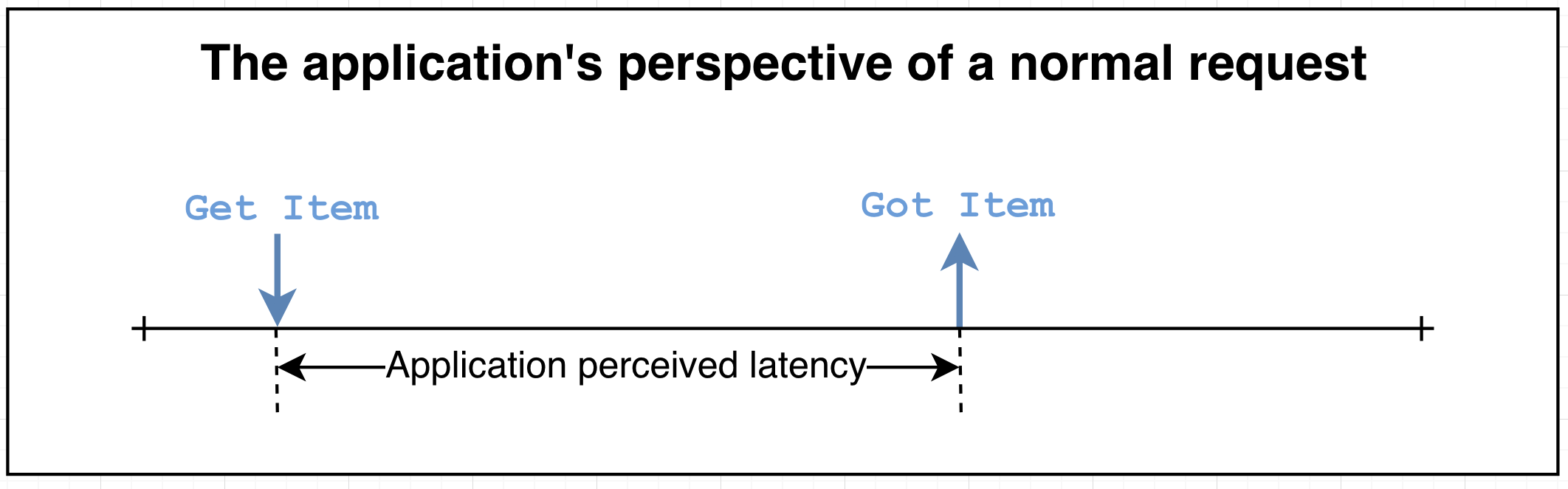
Figure 2. Normal scenario
However, in complex distributed systems, some requests may take longer than expected, exceeding the SLA. Because these delays are often due to things such as networking issues, a second request made around the same time is likely to have lower latency. As shown in Figure 3, when an initial request exceeds a specified time threshold (Delta), the system can send a duplicate request. Whichever response arrives first is used.
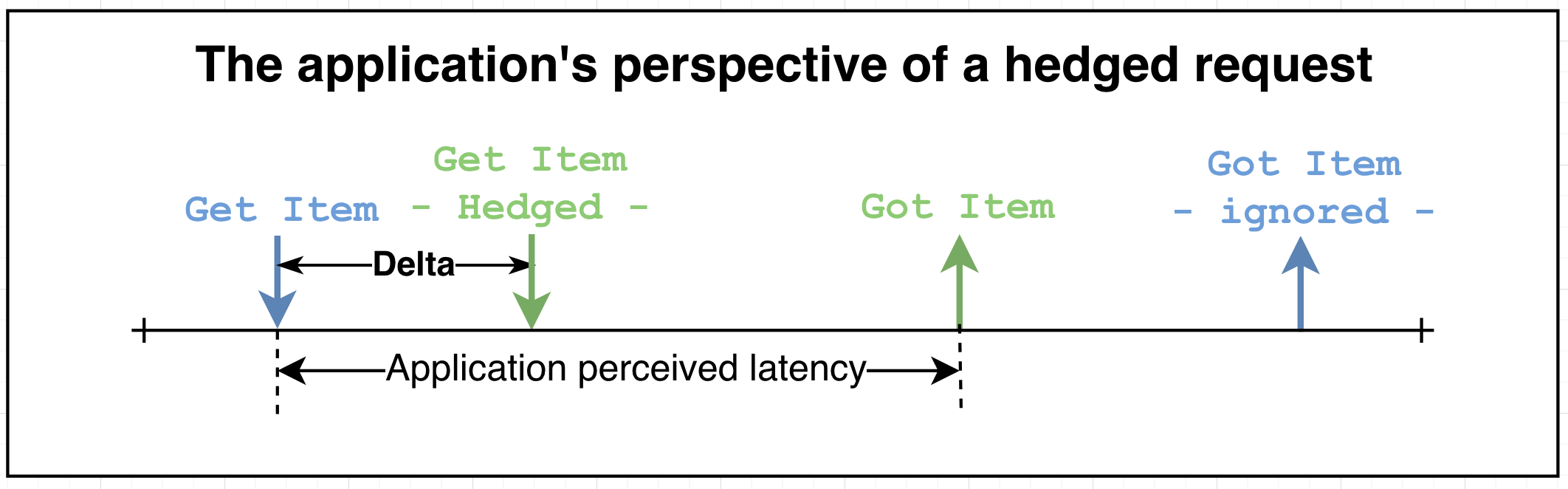
Figure 3. Application hedged request scenario
A key aspect of this approach is that both the original and duplicate requests remain active and are monitored simultaneously. Instead of canceling the initial request when launching the duplicate, both compete to provide the fastest response. A key configuration parameter is the delta value—the waiting period before sending the duplicate request.
Request hedging works best for non-transactional reads, idempotent writes, or writes that can be made idempotent. In GPN’s use case, credit card authorizations involve reading balances and activity records for validation, where hedging is effectively applied. However, subsequent balance and activity updates are processed without hedging to maintain transactional integrity.
Performance Testing and Analysis
We conducted extensive performance testing in a simulated environment to understand how the delta value (waiting period) affects tail latency performance. Using AWS SDK for Java client-side metrics, we measured how different configurations impacted both performance and resource utilization, focusing on tail latency improvements and request duplication rates.
To establish our baseline measurements, we began with a 5-minute warm-up period executing GetItem operations. We then conducted a controlled run without hedging to determine the initial latency percentile values for our test workload. These baseline values were used as delta value configurations in our subsequent hedging tests. To maintain accuracy, we recalculated the delta delay every 10 seconds using the cumulative measurements from the start of the testing (excluding warm-up).
Like GPN’s implementation, we specifically focused on the GetItem operation. This is an important nuance, particularly when your application uses both GetItem and Query operations. GetItem operations, which retrieve single items, typically have lower latency compared to Query operations that fetch multiple items such as 100 records or Scan operations that retrieve entire pages of data. Each API operation type has its own distinct latency profile, which can be monitored through Amazon CloudWatch metrics.
Figure 4 illustrates how different delta value configurations impact response times. The x-axis represents various hedging strategies, ranging from “No hedging” (sending only one request) to increasingly aggressive approaches where a second request is sent after specific latency percentiles have elapsed (p90, p80, p70, p60, or p50). The y-axis tracks three latency metrics: P50 latency (median response time, shown in purple dots), P95 latency (shown in blue squares), and P99 latency (shown in teal stars). The median latency (P50) remains relatively stable across all configurations, showing minimal variation across the hedging strategies. However, the P99 latency demonstrates significant improvement when hedging is implemented, dropping from 9.5ms with no hedging to around 6.7-7.3ms with various hedging strategies. This indicates that while hedging has little effect on typical requests, it substantially reduces latency for the slowest 1% of requests.
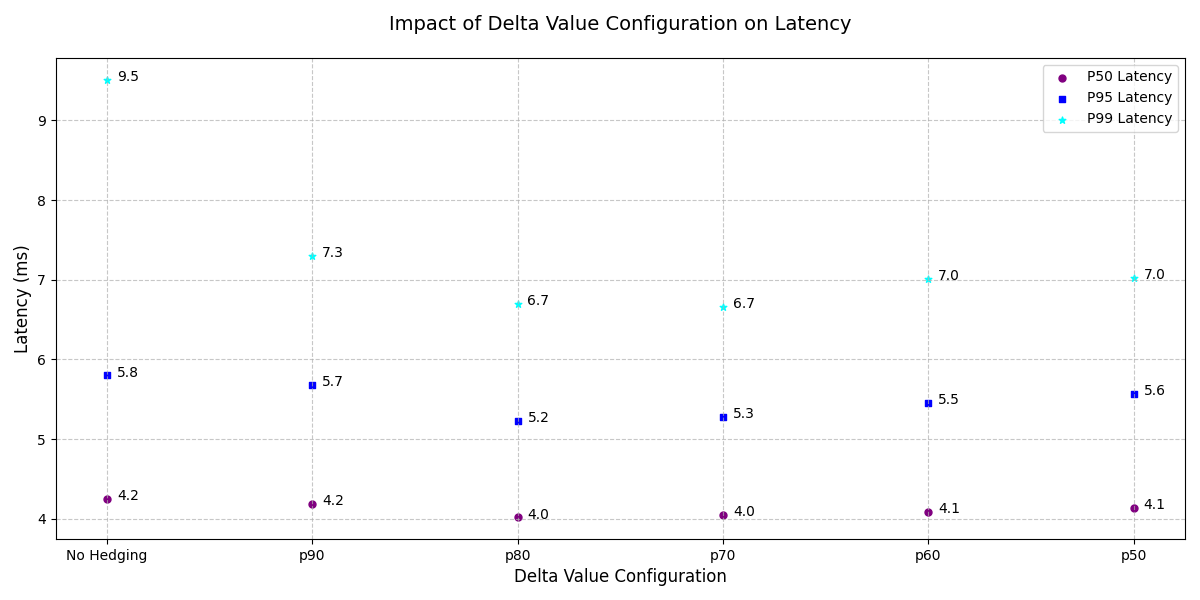
Figure 4. The impact of delta value configuration on Tail latency.
Logically, setting delta to the P50 latency value would result in approximately 50% Duplicate Request Rate (DRR), while setting it to P90 would result in about 10% DRR. However, in practice with low latencies, the actual DRR tends to be lower than these theoretical values. This is because the Java implementation uses a minimum wait time approach—the system will wait at least for the delta period (and potentially longer) before sending a hedged request, rather than executing exactly at the specified time. This behavior results in fewer hedged calls than the theoretical model would predict. Figure 5 shows the measured uplift in request counts.
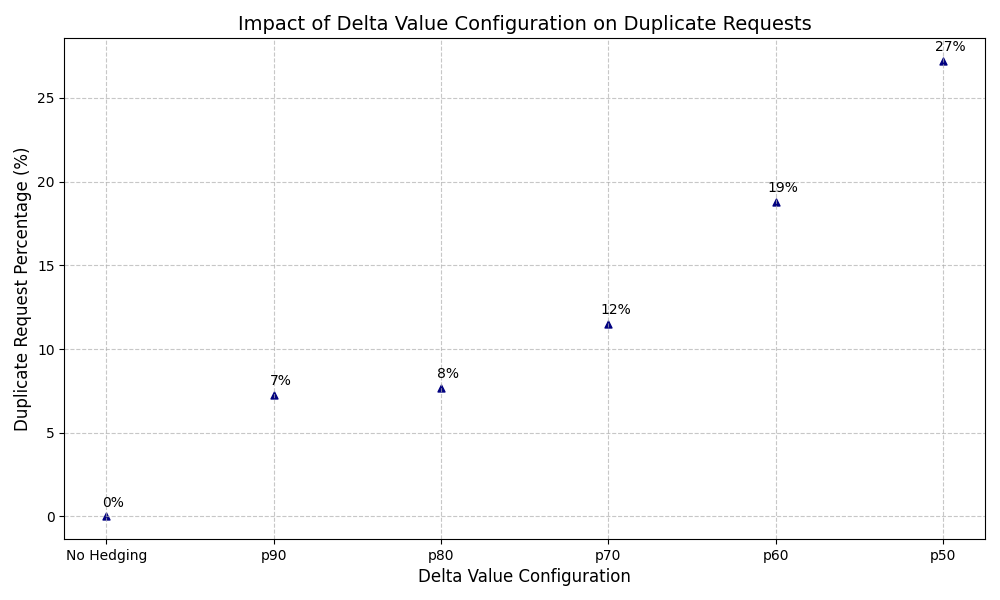
Figure 5. The impact of delta value configuration on duplicate request rates.
The data revealed two key relationships:
First, Latency Impact (Figure 4): Without hedging, requests at the 99th percentile took 9.5 milliseconds. As we reduced wait times (lower delta values), latencies improved significantly. When hedging at the 80th percentile, these requests dropped to 6.7 milliseconds—a 29% improvement.
Second, Request Duplication (Figure 5): Shorter wait times led to increased duplicate request rates. At the 80th percentile, only 8% of requests were duplicated. However, this rate increased significantly to 27% when using the 50th percentile as the delta value.
Optimizing the Delta Value: Balancing Latency and Cost
The delta value—the waiting period before sending a hedged request (shown in Figure 3)—is a configuration parameter that requires careful tuning. Determining the optimal delta value requires balancing two competing factors: latency reduction and operational costs.
| Delta Value configuration | Latency improvement @ p99 | Duplicate Request Rate (%) |
| P90 | 23% | 7% |
| P80 | 29% | 8% |
| P70 | 29% | 12% |
| P60 | 26% | 19% |
| P50 | 26% | 27% |
Table 1: Latency Improvement Compared to Duplicate Request Rates by Delta Value Configuration
Table 1 compares latency improvements at the 99th percentile against the rate of duplicate requests for different delta value configurations. As observed in the data, after a certain delta value (P80 in this case), the benefits slow down and even decrease, whereas duplicate request rates increase substantially. For example, moving from P80 to P50 yields no additional latency improvement (in fact, decreases by 3%) while increasing the duplicate request rate from 8% to 27%. Our testing identified the delta value configuration at 80th percentile of the non-hedged response time as an effective balance point, delivering: 29% latency improvement at 8% duplicate request rate for the test workload used.
These findings demonstrate how selecting the appropriate delta value can improve tail latency while maintaining reasonable operational costs.
Comparing SDK Retry Behavior and Request Hedging
Request hedging differs significantly from DynamoDB SDK’s retry behavior. The SDK’s default implementation uses a simple retry strategy with built-in timeout settings, only retrying requests when timeouts occur. While straightforward, these default timeouts may not meet low-latency requirements.
Lowering the socket timeout isn’t recommended as it can introduce unnecessary errors during possible overall high-latency periods, causing premature connection closures before DynamoDB responds. Request hedging offers a more sophisticated approach by proactively managing latency rather than just handling failures. In the case of retry behavior, when a timeout occurs, the request is discarded and a new request is made, while in request hedging, the second request is made while the first request is in flight and both requests are monitored as explained before.
For most of the use cases, the retry behavior provided by the DynamoDB SDK is sufficient without the need for complex client-side retry customization.
Implementation Considerations
Request hedging offers significant latency improvements but requires careful consideration of several trade-offs. Implementing this approach increases both request volume and system load, which directly impacts operational costs. Additionally, the added complexity in your application architecture needs to be weighed against the expected performance benefits.
Request hedging can be implemented at different layers of the architecture with different benefits and implications. Hedging at the AWS SDK level, which is used in this post, addresses network-related latency for specific AWS service requests. This approach is particularly attractive because it’s relatively straightforward to implement, and it allows for precise control, such as hedging at the p80 latency to optimize cost-efficiency.
Request hedging can be implemented earlier in the calling stack. For example, sending two parallel requests across two different containers placed in different Availability Zones (AZs) can maximize heterogeneity and ensure that localized issues—such as a slow container or AZ-specific problems—don’t impact overall performance and application resiliency. However, this approach will result in a significant cost increase due to increased resource consumption for duplicate requests.
As our performance tests demonstrated, determining the optimal delta value requires balancing latency improvement against the rate of duplicate requests. This balance is easier to strike with SDK-level hedging, but the trade-offs between different implementation approaches should be carefully considered based on your specific use case and performance requirements.
Consider request hedging when:
- Your application has strict low-latency requirements, even for tail latencies
- You’re running a high-throughput system where tail latency improvements impact many transactions
- Your workload experiences frequent, short-lived latency spikes
- You can tolerate the additional complexity and potential increase in request volume
Stick with standard SDK retry behavior when:
- Your application can tolerate occasional higher tail latencies
- You’re operating at lower throughput where the impact of tail latency is less significant
- Your main concern is handling occasional timeouts or errors, rather than optimizing tail response times
- You want to minimize implementation complexity and additional resource usage
Always conduct proper testing in your specific environment to quantify the benefits before implementing request hedging.
Best Practices for Implementation
Before implementing request hedging, conduct comprehensive testing in your specific environment to understand the actual benefits and overhead. Continuously monitor and adjust your implementation to maintain the balance between performance improvements and operational costs. Invest time in carefully tuning timeout and delta values based on your workload characteristics. Additionally, assess your team’s ability to manage the added complexity that request hedging introduces. By considering these factors and following these best practices, you can implement request hedging in a way that effectively meets your performance goals while maintaining operational efficiency.
Conclusion
Through request hedging, Global Payments Inc. successfully addressed tail latency challenges in their high-throughput DynamoDB applications, achieving a 30% reduction in p99 latency. Their implementation demonstrates that effective tail latency management requires careful selection of architectural implementation level, strategic tuning of delta values based on workload patterns, and regular monitoring to balance performance gains with operational costs.
While this post focused on read operations where request hedging is most straightforward, you can also apply this technique to write operations. For idempotent writes, use conditional expressions to prevent duplicates. For ordered writes, implement timestamp-based hedging. Note that write operations require additional consideration for race conditions and data consistency.
To learn more about implementing request hedging in your environment:
- Consider implementing request hedging if your application matches the criteria discussed in this post
- Watch for Part 2 of this series, where we’ll provide detailed implementation examples in Java and Python
- For overall optimization following best practices, use the Amazon DynamoDB Developer Guide and the DynamoDB Well-Architected Lens
We encourage you to share your experience with request hedging in the comments section.