AWS Database Blog
How Aqua Security automates fast clone orchestration on Amazon Aurora at scale
This is a guest post by Semyon Mor, SRE Engineering Manager at Aqua Security and Daniel Vidal, Cloud Architect at Aqua Security, in partnership with AWS.
Aqua Security is a leading provider of cloud-based security solutions, trusted by global enterprises to secure their applications from development to production. As part of their mission to deliver fast, reliable security insights at scale, Aqua relies heavily on analytics-driven workloads – some of which involve long-running queries and query exports from their Amazon Aurora PostgreSQL-Compatible Edition clusters.
As a customer-centric organization, Aqua is committed to delivering innovative solutions that address the evolving security needs of its clients. Like many organizations, Aqua faces the challenge of efficiently exporting and analyzing large volumes of data to meet their business requirements. Specifically, Aqua needes to export query data at scale and share with their customers for continuous monitoring and security analysis. To enable this, they leveraged the aws_s3.query_export_to_s3 function along with AWS Step Functions to automate the export of query results from their Aurora PostgreSQL clusters to Amazon S3. (For a detailed walkthrough of this export process, see How Aqua Security exports query data from Amazon Aurora to deliver value to their customers at scale.)
While this solution addresses the data delivery need, it also introduces a new challenge when a long-running, complex export query on a replica attempts to read a data page that the writer has modified. If that page is waiting to be updated, but is also being accessed by the read query, an access conflict occurs which can result in replication lag and potentially in errors (see detailed explanation in the next section). To solve this, Aqua Security adopts fast cloning in Aurora PostgreSQL (also available in Aurora MySQL-Compatible), a feature that enables faster, lower-cost duplication of clusters compared to Aurora backup and restore. By offloading export workloads to cloned environments, Aqua ensured that performance and availability of their mission-critical systems remained uncompromised.
In this post, we explore how Aqua Security automates the use of fast clones to support read-heavy operations at scale, simplify their data workflows, and maintain operational efficiency.
The challenge: Managing long queries without impacting replication
Aqua initially tried offloading export queries from Aurora read replica which worked well for most queries, but some long-running complex queries encountered errors. Let’s explore why it may happen: Aurora uses a shared storage model, where replica nodes access the same underlying storage volume as the writer instance. A challenge arises when a long-running, complex query on a replica attempts to read a data page that the writer has modified. If that page is waiting to be updated, but is also being accessed by the read query, an access conflict occurs. This can result in replication lag.To maintain replication health, Aurora enforces the max_standby_streaming_delay parameter (defaults to 14 seconds, configurable up to 30 seconds), which controls how long the system will wait before terminating the conflicting query on the replica with: “ERROR: canceling statement due to conflict with recovery Detail: User query might have needed to see row versions that must be removed”.For environments like Aqua Security, where long-running reporting queries and query exports are common, this constraint means that certain queries might be abruptly canceled, leading to retries, or failed jobs. As their data workloads grew, Aqua needed a more scalable and predictable way to run read-heavy workloads without risking replication lag or query termination.
Solution overview
For use cases where query exports are required only occasionally, such as once a day, as in Aqua Security’s environment, and where strong consistency with the primary database is not essential, Aurora fast clones offer a practical and cost-effective solution. Because fast clones operate as independent Aurora clusters, they are completely isolated from the primary environment, meaning long-running export queries can run without risk of cancellation due to the max_standby_streaming_delay timeout. Fast clones also bring significant cost efficiency: because clones share the same underlying storage as the source cluster, there is no additional storage cost unless the data is modified. The only cost incurred is for the Aurora instances used to run the cloned cluster, billed at the standard pricing for the duration the clone is running. After the export process is complete, the cloned cluster can be safely stopped and deleted, stopping further compute charges.
To take full advantage of fast clones, Aqua Security developed an automated orchestration framework that dynamically manages the lifecycle of cloned databases. The system is built around three core principles:
- Automated cloning – When a long-running query or export job is triggered, a fast clone of the source database is created automatically
- Isolated execution – The workload runs against the clone, making sure that production replicas are unaffected by query locks, memory usage, or I/O overhead
- Automated cleanup – After the job is complete, the cloned cluster is deleted, freeing up resources and keeping the environment lean
The following diagram illustrates the solution architecture.
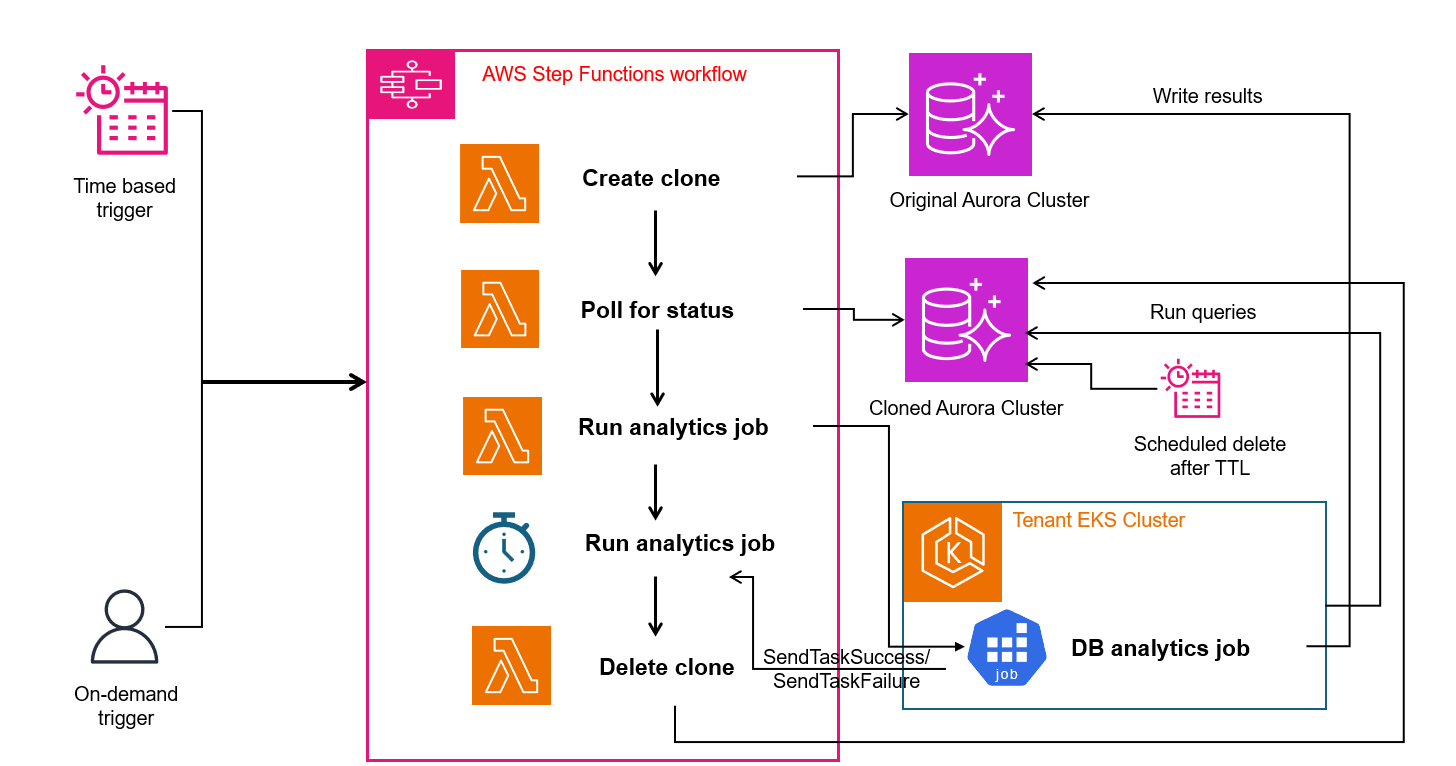
The architecture of Aqua’s solution consists of the following components:
- Job Scheduler:
- The scheduler triggers the workflow (AWS Step Functions) based on defined schedules (time-based) using Amazon EventBridge or can initiate workflows on-demand, providing flexibility based on operational needs.
- Orchestration Service
- Built using AWS SDK and Aurora APIs invoked via AWS Lambda functions
- Initiates Aurora clone creation using the CreateDBCluster and RestoreDBClusterToPointInTime operations. This enables fast provisioning of isolated database environments
- Manages configuration of the cloned Aurora cluster by setting up specific endpoint access, applying appropriate security groups, and database parameters. These configurations ensure that the clones are secure, performant, and tailored specifically for analytics workloads
- Monitors clone status continuously (polling) until the clone becomes available and ready to serve analytic queries
- Automatically deletes the cloned Aurora instance after analytics processing is completed or after a predefined Time-to-Live (TTL) to optimize resource utilization and control costs effectively
- Integration with Aqua’s internal tooling:
- Routes analytic queries directly to the endpoints of the cloned Aurora databases, isolating heavy, read-intensive workloads from the primary production database.
- Communicates job execution results back to the orchestration layer using defined callbacks (SendTaskSuccess or SendTaskFailure), enabling robust monitoring, logging, and response handling
- Ensures that analytics jobs read data exclusively from the cloned Aurora instance, while results and analytics outputs are written back to the main Aurora cluster, maintaining data integrity and consistency
This approach allowed Aqua to decouple long-running reads from their production stack, improving both stability and scalability in a cost-effective manner.
Results and business impact
By adopting fast clone orchestration on Aurora PostgreSQL, Aqua Security achieved several significant outcomes:
- Improved reliability – Long-running reporting queries and export jobs no longer fail by running against an Aurora clone without impacting production
- Scalability – The system scales with Aqua’s workload demands, supporting one-time exports, complex reports, and developer testing without affecting production systems. Aqua Security runs approximately 280 daily clones
- Cost effectiveness – Aurora clones are cost-effective because they share the same underlying storage as the source cluster, incurring additional storage costs only for data changes, and for compute resources only while the clone is running. The total monthly expense was around $2,100, which translates to roughly $7.50 per database
Conclusion
Aqua Security’s use of Aurora fast clone orchestration demonstrates the power of Aurora’s storage architecture for solving real-world operational challenges. By automating the creation and teardown of cloned databases, Aqua has built a flexible and cost-efficient platform to support their most demanding data workloads—all without compromising availability or performance.
If you’re running complex reporting queries on Aurora and want to avoid impacting your primary production workloads, consider using Aurora fast clones, and take inspiration from Aqua Security’s approach to orchestration.
To learn more about Aqua Security, visit aquasec.com.